Falls Sie es noch nicht gesehen haben, wir haben gerade ClusterControl 1.7.5 mit wesentlichen Verbesserungen und neuen nützlichen Funktionen veröffentlicht. Einige der Funktionen umfassen Cluster Wide Maintenance, Unterstützung für Version CentOS 8 und Debian 10, PostgreSQL 12-Unterstützung, Unterstützung für MongoDB 4.2 und Percona MongoDB v4.0 sowie den neuen MySQL Freeze Frame.
Warte, aber was ist ein MySQL Freeze Frame? Ist das etwas Neues für MySQL?
Nun, es ist nichts Neues innerhalb des MySQL-Kernels selbst. Es ist eine neue Funktion, die wir zu ClusterControl 1.7.5 hinzugefügt haben und die spezifisch für MySQL-Datenbanken ist. Der MySQL Freeze Frame in ClusterControl 1.7.5 deckt die folgenden Dinge ab:
- Momentaufnahme des MySQL-Status vor Cluster-Ausfall.
- Snapshot der MySQL-Prozessliste vor dem Ausfall des Clusters (demnächst verfügbar).
- Untersuchen Sie Clustervorfälle in Betriebsberichten oder über das s9s-Befehlszeilentool.
Dies sind wertvolle Informationen, die Ihnen helfen können, Fehler aufzuspüren und Ihre MySQL/MariaDB-Cluster zu reparieren, wenn die Dinge schief gehen. In Zukunft planen wir, auch Snapshots der SHOW ENGINE InnoDB-Statuswerte einzubeziehen. Bleiben Sie also bitte auf dem Laufenden über unsere zukünftigen Veröffentlichungen.
Beachten Sie, dass sich diese Funktion noch im Beta-Stadium befindet, wir gehen davon aus, dass wir weitere Datensätze sammeln werden, während wir mit unseren Benutzern arbeiten. In diesem Blog zeigen wir Ihnen, wie Sie diese Funktion nutzen können, insbesondere wenn Sie weitere Informationen zur Diagnose Ihres MySQL/MariaDB-Clusters benötigen.
ClusterControl zur Behandlung von Clusterfehlern
Bei Clusterfehlern unternimmt ClusterControl nichts, es sei denn, die automatische Wiederherstellung (Cluster/Knoten) ist wie unten aktiviert:

Nach der Aktivierung versucht ClusterControl, einen Knoten wiederherzustellen oder den Cluster wiederherzustellen Heraufbringen der gesamten Cluster-Topologie.
Für MySQL muss zum Beispiel bei einer Master-Slave-Replikation immer mindestens ein Master am Leben sein, unabhängig von der Anzahl verfügbarer Slaves. ClusterControl versucht, die Topologie mindestens einmal für Replikations-Cluster zu korrigieren, bietet jedoch mehr Wiederholungsversuche für Multi-Master-Replikation wie NDB-Cluster und Galera-Cluster. Die Knotenwiederherstellung versucht, einen fehlerhaften Datenbankknoten wiederherzustellen, z. wenn der Prozess beendet wurde (abnormales Herunterfahren) oder der Prozess einen OOM (Out-of-Memory) erlitt. ClusterControl stellt über SSH eine Verbindung zum Knoten her und versucht, MySQL aufzurufen. Wir haben bereits darüber gebloggt, wie ClusterControl automatische Datenbankwiederherstellung und Failover durchführt, also besuchen Sie bitte diesen Artikel, um mehr über das Schema für die automatische Wiederherstellung von ClusterControl zu erfahren.
In der vorherigen Version von ClusterControl <1.7.5 lösten diese Wiederherstellungsversuche Alarme aus. Aber eine Sache, die unsere Kunden vermissten, war ein vollständigerer Vorfallbericht mit Zustandsinformationen kurz vor dem Ausfall des Clusters. Bis wir diesen Mangel erkannt und diese Funktion in ClusterControl 1.7.5 hinzugefügt haben. Wir haben es den "MySQL Freeze Frame" genannt. Der MySQL Freeze Frame bietet zum jetzigen Zeitpunkt eine kurze Zusammenfassung von Vorfällen, die kurz vor dem Absturz zu Cluster-Statusänderungen führten. Am wichtigsten ist, dass am Ende des Berichts die Liste der Hosts und ihrer MySQL Global Status-Variablen und -Werte enthalten sind.
Wie unterscheidet sich MySQL Freeze Frame von der automatischen Wiederherstellung?
Der MySQL Freeze Frame ist nicht Teil der automatischen Wiederherstellung von ClusterControl. Unabhängig davon, ob die automatische Wiederherstellung deaktiviert oder aktiviert ist, wird der MySQL Freeze Frame immer seine Arbeit erledigen, solange ein Cluster- oder Knotenfehler erkannt wurde.
Wie funktioniert MySQL Freeze Frame?
In ClusterControl gibt es bestimmte Zustände, die wir als verschiedene Arten von Cluster-Status klassifizieren. MySQL Freeze Frame generiert einen Vorfallbericht, wenn diese beiden Zustände ausgelöst werden:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
In ClusterControl ist ein CLUSTER_DEGRADED, wenn Sie in einen Cluster schreiben können, aber ein oder mehrere Knoten ausgefallen sind. In diesem Fall erstellt ClusterControl den Vorfallbericht.
Bei CLUSTER_FAILURE, obwohl sich die Nomenklatur von selbst erklärt, ist dies der Zustand, in dem Ihr Cluster ausfällt und keine Lese- oder Schreibvorgänge mehr verarbeiten kann. Dann ist das ein CLUSTER_FAILURE-Zustand. Unabhängig davon, ob ein automatischer Wiederherstellungsprozess versucht, das Problem zu beheben, oder ob er deaktiviert ist, generiert ClusterControl den Vorfallbericht.
Wie aktivieren Sie MySQL Freeze Frame?
Der MySQL Freeze Frame von ClusterControl ist standardmäßig aktiviert und generiert nur dann einen Vorfallbericht, wenn die Zustände CLUSTER_DEGRADED oder CLUSTER_FAILURE ausgelöst oder angetroffen werden. Es besteht also keine Notwendigkeit auf Benutzerseite, ClusterControl-Konfigurationseinstellungen vorzunehmen, ClusterControl erledigt dies automatisch für Sie.
Auffinden des MySQL Freeze Frame-Vorfallberichts
Zum jetzigen Zeitpunkt gibt es 4 Möglichkeiten, wie Sie den Vorfallbericht finden können. Diese finden Sie in den folgenden Abschnitten unten.
Verwendung der Registerkarte "Betriebsberichte"
Die Betriebsberichte aus früheren Versionen werden nur verwendet, um die Betriebsberichte zu erstellen, zu planen oder aufzulisten, die von Benutzern generiert wurden. Seit Version 1.7.5 haben wir den von unserer MySQL Freeze Frame-Funktion generierten Vorfallbericht aufgenommen. Siehe das Beispiel unten:
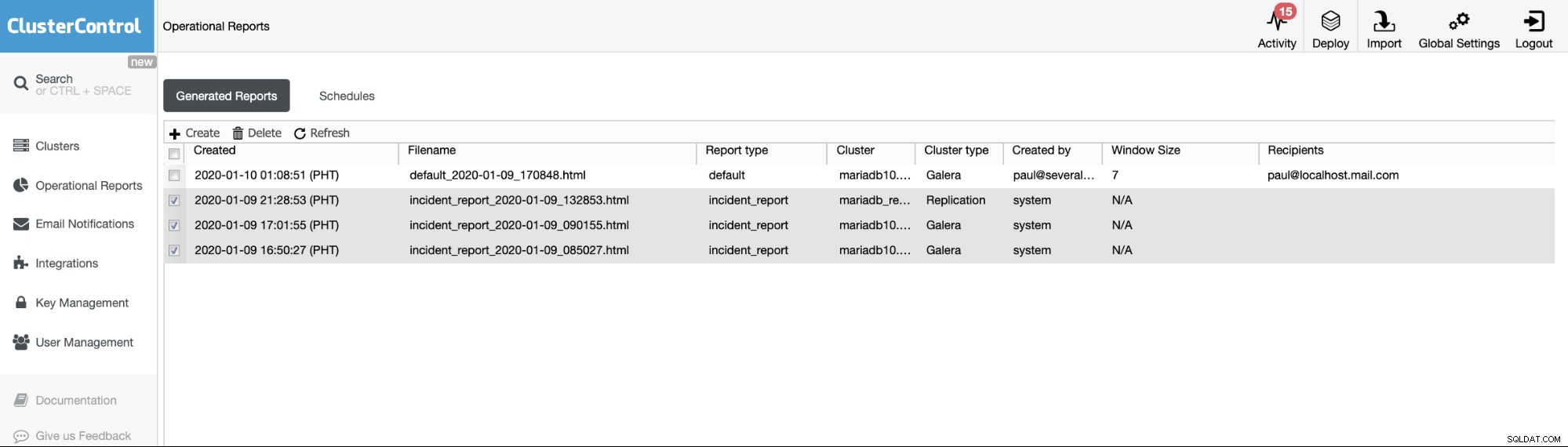
Die überprüften Elemente oder Elemente mit Berichtstyp ==Vorfallbericht sind der Vorfall Berichte, die von der MySQL Freeze Frame-Funktion in ClusterControl generiert werden.
Fehlerberichte verwenden
Indem Sie den Cluster auswählen und einen Fehlerbericht erstellen, d. h. diesen Prozess durchlaufen:
Verwenden der s9s CLI-Befehlszeile
Ein generierter Vorfallbericht enthält Anweisungen oder Hinweise, wie Sie diesen mit dem s9s-CLI-Befehl verwenden können. Unten sehen Sie, was im Vorfallbericht gezeigt wird:
Hinweis! Mit dem s9s-CLI-Tool können Sie Daten in diesem Bericht einfach abrufen, z. B.:
s9s report --list --long
s9s report --cat --report-id=NWenn Sie also einen Fehlerbericht lokalisieren und generieren möchten, können Sie diesen Ansatz verwenden:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportWenn ich die wsrep_*-Variablen auf einem bestimmten Host grepen möchte, kann ich Folgendes tun:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Manuelle Suche über den Systemdateipfad
ClusterControl generiert diese Vorfallberichte auf dem Host, auf dem ClusterControl ausgeführt wird. ClusterControl erstellt ein Verzeichnis in /home/
Gibt es irgendwelche Gefahren oder Vorbehalte bei der Verwendung von MySQL Freeze Frame?
ClusterControl ändert oder modifiziert nichts in Ihren MySQL-Knoten oder -Clustern. MySQL Freeze Frame liest nur SHOW GLOBAL STATUS (ab diesem Zeitpunkt) in bestimmten Intervallen, um Datensätze zu speichern, da wir den Zustand eines MySQL-Knotens oder -Clusters nicht vorhersagen können, wenn er abstürzen oder Hardware- oder Festplattenprobleme haben kann. Es ist nicht möglich, dies vorherzusagen, daher speichern wir die Werte und können daher einen Vorfallbericht erstellen, falls ein bestimmter Knoten ausfällt. In diesem Fall ist die Gefahr, dies zu haben, nahezu null. Es kann theoretisch eine Reihe von Client-Anfragen zu den Servern hinzufügen, falls einige Sperren in MySQL gehalten werden, aber wir haben es noch nicht bemerkt. Die Testreihe zeigt dies nicht, also würden wir uns freuen, wenn Sie es zulassen könnten uns informieren oder ein Support-Ticket einreichen, falls Probleme auftreten.
Es gibt bestimmte Situationen, in denen ein Vorfallbericht möglicherweise keine globalen Statusvariablen sammeln kann, wenn ein Netzwerkproblem das Problem war, bevor ClusterControl einen bestimmten Frame zum Sammeln von Daten einfrierte. Das ist völlig vertretbar, da ClusterControl auf keinen Fall Daten für weitere Diagnosen sammeln kann, da es überhaupt keine Verbindung zum Knoten gibt.
Zu guter Letzt fragen Sie sich vielleicht, warum nicht alle Variablen im Abschnitt GLOBAL STATUS angezeigt werden? Für die Zwischenzeit setzen wir einen Filter, bei dem leere oder 0-Werte im Vorfallbericht ausgeschlossen werden. Der Grund ist, dass wir Speicherplatz sparen wollen. Sobald diese Vorfallberichte nicht mehr benötigt werden, können Sie sie über die Registerkarte „Betriebsberichte“ löschen.
Testen der MySQL Freeze Frame-Funktion
Wir glauben, dass Sie gespannt darauf sind, dieses auszuprobieren und zu sehen, wie es funktioniert. Stellen Sie jedoch bitte sicher, dass Sie dies nicht in einer Live- oder Produktionsumgebung ausführen oder testen. Wir werden 2 Phasen des Szenarios in MySQL/MariaDB abdecken, eine für die Master-Slave-Einrichtung und eine für die Einrichtung vom Galera-Typ.
Master-Slave-Setup-Testszenario
In einem Master-Slave-Setup ist es einfach und unkompliziert auszuprobieren.
Schritt Eins
Stellen Sie sicher, dass Sie die automatischen Wiederherstellungsmodi (Cluster und Knoten) deaktiviert haben, wie unten:

also wird es nicht versuchen oder versuchen, das Testszenario zu reparieren.
Schritt Zwei
Gehen Sie zu Ihrem Master-Knoten und versuchen Sie, ihn auf schreibgeschützt einzustellen:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Schritt Drei
Dieses Mal wurde ein Alarm ausgelöst und so ein Vorfallbericht generiert. Sehen Sie unten, wie mein Cluster aussieht:

und der Alarm wurde ausgelöst:

und der Vorfallbericht wurde erstellt:

Galera-Cluster-Setup-Testszenario
Für eine Galera-basierte Einrichtung müssen wir sicherstellen, dass der Cluster nicht mehr verfügbar ist, d. h. ein Cluster-weiter Ausfall. Im Gegensatz zum Master-Slave-Test können Sie die automatische Wiederherstellung aktiviert lassen, da wir mit Netzwerkschnittstellen herumspielen.
Hinweis:Stellen Sie für dieses Setup sicher, dass Sie mehrere Schnittstellen haben, wenn Sie die Knoten in einer Remoteinstanz testen, da Sie die Schnittstelle nicht hochfahren können, wenn Sie die Schnittstelle, mit der Sie verbunden sind, herunterfahren.
Schritt Eins
Erstellen Sie einen 3-Knoten-Galera-Cluster (z. B. mit vagrant)
Schritt Zwei
Geben Sie den Befehl (wie unten) aus, um ein Netzwerkproblem zu simulieren, und führen Sie dies mit allen Knoten durch
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Schritt Drei
Nun, es hat meinen Cluster heruntergefahren und hat diesen Zustand:

hat einen Alarm ausgelöst,

und generiert einen Vorfallbericht:

Für einen Beispielvorfallbericht können Sie diese Rohdatei verwenden und speichern als html.
Es ist ganz einfach, es zu versuchen, aber bitte tun Sie dies nur in einer Nicht-Live- und Nicht-Prod-Umgebung.
Fazit
MySQL Freeze Frame in ClusterControl kann bei der Diagnose von Abstürzen hilfreich sein. Bei der Fehlerbehebung benötigen Sie eine Fülle von Informationen, um die Ursache zu ermitteln, und genau das bietet MySQL Freeze Frame.