Sind Sie jemals auf eine Situation gestoßen, in der Sie den Zustand einer Entität verwalten müssen, die sich im Laufe der Zeit ändert? Es gibt viele Beispiele da draußen. Beginnen wir mit einem einfachen:Kundendatensätze zusammenführen.
Angenommen, wir führen Kundenlisten aus zwei verschiedenen Quellen zusammen. Es könnte einer der folgenden Zustände auftreten:Duplikate identifiziert – das System hat zwei potenziell doppelte Entitäten gefunden; Bestätigte Duplikate – ein Benutzer validiert, dass die beiden Entitäten tatsächlich Duplikate sind; oder Bestätigt eindeutig – Der Benutzer entscheidet, dass die beiden Entitäten eindeutig sind. In jeder dieser Situationen muss der Benutzer nur eine Ja-Nein-Entscheidung treffen.
Aber was ist mit komplexeren Situationen? Gibt es eine Möglichkeit, den tatsächlichen Workflow zwischen den Zuständen zu definieren? Lesen Sie weiter…
Wie leicht etwas schief gehen kann
Viele Unternehmen müssen Bewerbungen verwalten. In einem einfachen Modell könnten Sie eine Tabelle namens JOB_APPLICATION , und Sie könnten den Status der Anwendung mithilfe einer Referenzdatentabelle verfolgen, die Werte wie die folgenden enthält:
| Bewerbungsstatus |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Diese Werte können jederzeit in beliebiger Reihenfolge ausgewählt werden. Es verlässt sich darauf, dass die Endbenutzer sicherstellen, dass in jeder Phase eine logische und korrekte Auswahl getroffen wird. Nichts verbietet eine unlogische Abfolge von Zuständen.
Nehmen wir zum Beispiel an, dass ein Antrag abgelehnt wurde. Der aktuelle Status wäre offensichtlich APPLICATION_REJECTED . Auf Anwendungsebene kann nichts unternommen werden, um zu verhindern, dass ein unerfahrener Benutzer anschließend INVITED_TO_INTERVIEW auswählt oder ein anderer unlogischer Zustand.
Was benötigt wird, ist etwas, das den Benutzer bei der Auswahl des nächsten logischen Zustands anleitet, etwas, das einen logischen Arbeitsablauf definiert .
Und was ist, wenn Sie unterschiedliche Anforderungen für verschiedene Arten von Bewerbungen haben? Bei einigen Stellen kann es beispielsweise erforderlich sein, dass der Bewerber einen Eignungstest ablegt. Natürlich können Sie der Liste weitere Werte hinzufügen, um diese abzudecken, aber das aktuelle Design hindert den Endbenutzer nicht daran, eine falsche Auswahl für den betreffenden Anwendungstyp zu treffen. Die Realität ist, dass es unterschiedliche Arbeitsabläufe gibt für verschiedene Kontexte .
Ein weiterer Punkt zum Nachdenken:Sind die aufgelisteten Optionen wirklich alle Zustände? ? Oder sind einige tatsächlich Ergebnisse ? Beispielsweise kann das Stellenangebot vom Bewerber angenommen oder abgelehnt werden. Daher JOB_OFFER_MADE hat wirklich zwei Ergebnisse:JOB_OFFER_ACCEPTED und JOB_OFFER_DECLINED .
Eine andere Folge könnte sein, dass ein Stellenangebot zurückgezogen wird. Möglicherweise möchten Sie den Grund für den Rückzug mithilfe eines Qualifizierers aufzeichnen. Wenn Sie diese Gründe einfach zur obigen Liste hinzufügen, führt nichts den Endbenutzer dazu, eine logische Auswahl zu treffen.
Je komplexer also die Zustände, Ergebnisse und Qualifizierer werden, desto mehr müssen Sie den Arbeitsablauf definieren eines Prozesses .
Prozesse, Zustände und Ergebnisse organisieren
Es ist wichtig zu verstehen, was mit Ihren Daten passiert, bevor Sie versuchen, sie zu modellieren. Vielleicht denken Sie zunächst, dass es hier eine strikte Hierarchie von Typen gibt:
Wenn wir uns das obige Beispiel genauer ansehen, sehen wir, dass der INVITED_TO_INTERVIEW und der JOB_OFFER_MADE Staaten teilen die gleichen möglichen Ergebnisse, nämlich ACCEPTED und DECLINED . Dies sagt uns, dass es eine viele-zu-viele-Beziehung gibt zwischen Zuständen und Ergebnissen. Dies gilt häufig für andere Bundesstaaten, Ergebnisse und Qualifikationsmerkmale.
Auf konzeptioneller Ebene passiert also Folgendes mit unseren Metadaten:
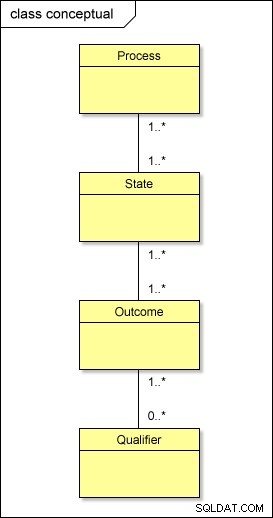
Wenn Sie dieses Modell mit dem Standardansatz in die physikalische Welt übertragen würden, hätten Sie Tabellen namens PROCESS , STATE , OUTCOME und QUALIFIER; Sie müssten auch Zwischentabellen haben dazwischen – PROCESS_STATE , STATE_OUTCOME und OUTCOME_QUALIFIER – um die Viele-zu-Viele-Beziehungen aufzulösen . Dies erschwert das Design.
Während die logische Ebenenhierarchie (Prozess → Zustand → Ergebnis → Qualifizierer) beibehalten werden muss, gibt es eine einfachere Möglichkeit, unsere Metadaten physisch zu organisieren.
Das Workflow-Muster
Das folgende Diagramm definiert die Hauptkomponenten eines Workflow-Datenbankmodells:
Die gelben Tabellen auf der linken Seite enthalten Workflow-Metadaten und die blauen Tabellen auf der rechten Seite Geschäftsdaten.
Als Erstes ist darauf hinzuweisen, dass jede Entität verwaltet werden kann ohne dass größere Änderungen an diesem Modell erforderlich sind. Der YOUR_ENTITIY_TO_MANAGE Tabelle ist die unter Workflow-Management. In unserem Beispiel wäre dies der JOB_APPLICATION Tisch.
Als nächstes müssen wir einfach die wf_state_type_process_id hinzufügen Spalte zu einer beliebigen Tabelle, die wir verwalten möchten. Diese Spalte zeigt auf den eigentlichen Workflow Prozess zur Verwaltung der Entität verwendet werden. Dies ist nicht unbedingt eine Fremdschlüsselspalte, aber sie ermöglicht uns die schnelle Abfrage von WORKFLOW_STATE_TYPE für den richtigen Ablauf. Die Tabelle, die den Statusverlauf enthält ist MANAGED_ENTITY_STATE . Auch hier würden Sie Ihren eigenen spezifischen Tabellennamen wählen und ihn für Ihre eigenen Anforderungen ändern.
Die Metadaten
Die verschiedenen Arbeitsablaufebenen werden in WORKFLOW_LEVEL_TYPE . Diese Tabelle enthält Folgendes:
| Geben Sie den Schlüssel ein | Beschreibung |
|---|---|
| PROZESS | Workflow-Prozess auf hoher Ebene. |
| STAAT | Ein Zustand im Prozess. |
| ERGEBNIS | Wie ein Zustand endet, sein Ergebnis. |
| QUALIFIKATOR | Ein optionaler, detaillierterer Qualifizierer für ein Ergebnis. |
WORKFLOW_STATE_TYPE und WORKFLOW_STATE_HIERARCHY bilden eine klassische Stücklistenstruktur . Diese Struktur, die eine tatsächliche Fertigungsstückliste sehr beschreibt, ist in der Datenmodellierung weit verbreitet. Es kann Hierarchien definieren oder auf viele rekursive Situationen angewendet werden. Wir werden es hier verwenden, um unsere logische Hierarchie von Prozessen, Zuständen, Ergebnissen und optionalen Qualifizierern zu definieren.
Bevor wir eine Hierarchie definieren können, müssen wir die einzelnen Komponenten definieren. Das sind unsere Grundbausteine. Ich werde diese nur mit TYPE_KEY referenzieren (was einzigartig ist) der Kürze halber. Für unser Beispiel haben wir:
| Workflow-Level-Typ | Workflow-Statustyp.Typschlüssel |
|---|---|
| ERGEBNIS | BESTANDEN |
| ERGEBNIS | FEHLER |
| ERGEBNIS | AKZEPTIERT |
| ERGEBNIS | ABGELEHNT |
| ERGEBNIS | CANDIDATE_CANCELLED |
| ERGEBNIS | EMPLOYER_CANCELLED |
| ERGEBNIS | ABGELEHNT |
| ERGEBNIS | EMPLOYER_WITHDRAWN |
| ERGEBNIS | NO_SHOW |
| ERGEBNIS | ANGESTELLT |
| ERGEBNIS | NOT_HIRED |
| STAAT | APPLICATION_RECEIVED |
| STAAT | APPLICATION_REVIEW |
| STAAT | INVITED_TO_INTERVIEW |
| STAAT | INTERVIEW |
| STAAT | TEST_APTITUDE |
| STAAT | SEEK_REFERENCES |
| STAAT | MAKE_OFFER |
| STAAT | APPLICATION_CLOSED |
| PROZESS | STANDARD_JOB_APPLICATION |
| PROZESS | TECHNICAL_JOB_APPLICATION |
Jetzt können wir damit beginnen, unsere Hierarchie zu definieren. Hier nehmen wir unsere Bausteine und definieren unsere Struktur. Für jeden Zustand definieren wir die möglichen Ergebnisse. Tatsächlich ist es eine Regel dieses Workflow-Systems, dass jeder Status beenden muss mit einem Ergebnis:
| Übergeordneter Typ – STAATEN | Kindtyp – ERGEBNISSE |
|---|---|
| APPLICATION_RECEIVED | AKZEPTIERT |
| APPLICATION_RECEIVED | ABGELEHNT |
| APPLICATION_REVIEW | BESTANDEN |
| APPLICATION_REVIEW | FEHLER |
| INVITED_TO_INTERVIEW | AKZEPTIERT |
| INVITED_TO_INTERVIEW | ABGELEHNT |
| INTERVIEW | BESTANDEN |
| INTERVIEW | FEHLER |
| INTERVIEW | CANDIDATE_CANCELLED |
| INTERVIEW | NO_SHOW |
| MAKE_OFFER | AKZEPTIERT |
| MAKE_OFFER | ABGELEHNT |
| SEEK_REFERENCES | BESTANDEN |
| SEEK_REFERENCES | FEHLER |
| APPLICATION_CLOSED | ANGESTELLT |
| APPLICATION_CLOSED | NOT_HIRED |
| TEST_APTITUDE | BESTANDEN |
| TEST_APTITUDE | FEHLER |
Unsere Prozesse sind einfach eine Reihe von Zuständen, die jeweils für einen bestimmten Zeitraum bestehen. In der folgenden Tabelle werden sie in einer logischen Reihenfolge dargestellt, aber dies definiert nicht die tatsächliche Reihenfolge der Verarbeitung.
| Übergeordneter Typ – PROZESSE | Kindtyp – STAATEN |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APPLICATION_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | INTERVIEW |
| STANDARD_JOB_APPLICATION | MAKE_OFFER |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_RECEIVED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_REVIEW |
| TECHNICAL_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| TECHNICAL_JOB_APPLICATION | TEST_APTITUDE |
| TECHNICAL_JOB_APPLICATION | INTERVIEW |
| TECHNICAL_JOB_APPLICATION | MAKE_OFFER |
| TECHNICAL_JOB_APPLICATION | SEEK_REFERENCES |
| TECHNICAL_JOB_APPLICATION | APPLICATION_CLOSED |
Es gibt einen wichtigen Punkt in Bezug auf eine Stücklistenhierarchie. So wie eine physische Stückliste Baugruppen und Unterbaugruppen bis hin zu den kleinsten Komponenten definiert, haben wir eine ähnliche Anordnung in unserer Hierarchie. Das bedeutet, dass wir „Baugruppen“ und „Unterbaugruppen“ wiederverwenden können.
Als Beispiel:Sowohl die STANDARD_JOB_APPLICATION und TECHNICAL_JOB_APPLICATION Prozesse haben das INTERVIEW Zustand . Im Gegenzug das INTERVIEW Zustand hat den PASSED , FAILED , CANDIDATE_CANCELLED , und NO_SHOW Ergebnisse dafür definiert.
Wenn Sie einen Zustand in einem Prozess verwenden, erhalten Sie automatisch seine untergeordneten Ergebnisse, da es sich bereits um eine Assembly handelt. Das bedeutet, dass für beide Bewerbungsarten beim INTERVIEW die gleichen Ergebnisse vorliegen Bühne. Wenn Sie unterschiedliche Interviewergebnisse für verschiedene Arten von Bewerbungen wünschen, müssen Sie beispielsweise TECHNICAL_INTERVIEW definieren und STANDARD_INTERVIEW gibt an, dass jeder seine eigenen spezifischen Ergebnisse hat.
In diesem Beispiel besteht der einzige Unterschied zwischen den beiden Arten von Bewerbungen darin, dass eine technische Bewerbung einen Eignungstest beinhaltet.
Bevor Sie gehen
Teil 1 dieses zweiteiligen Artikels hat das Workflow-Datenbankmuster eingeführt. Es hat gezeigt, wie Sie es integrieren können, um den Lebenszyklus einer beliebigen Entität in Ihrer Datenbank zu verwalten.
Teil 2 zeigt Ihnen, wie Sie den eigentlichen Arbeitsablauf definieren Verwendung zusätzlicher Konfigurationstabellen. Hier werden dem Benutzer zulässige nächste Schritte präsentiert. Wir werden auch eine Technik demonstrieren, um die strikte Wiederverwendung von „Baugruppen“ und „Unterbaugruppen“ in Stücklisten zu umgehen.