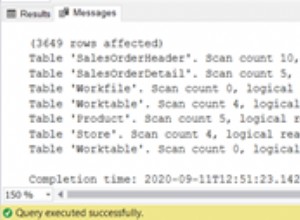
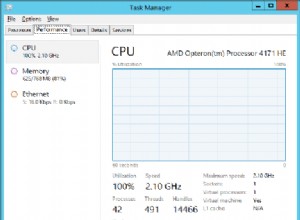
SELECT a, b, c
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY a ORDER BY b, c) rn
FROM mytable
) q
WHERE rn = 1
ORDER BY
a
oder
SELECT mi.*
FROM (
SELECT DISTINCT a
FROM mytable
) md
CROSS APPLY
(
SELECT TOP 1 *
FROM mytable mi
WHERE mi.a = md.a
ORDER BY
b, c
) mi
ORDER BY
a
Erstellen Sie einen zusammengesetzten Index für (a, b, c) damit die Abfragen schneller funktionieren.
Welche effizienter ist, hängt von Ihrer Datenverteilung ab.
Wenn Sie wenige eindeutige Werte von a haben aber jede Menge Datensätze in jedem a , die zweite Abfrage wäre besser.
Sie könnten es noch weiter verbessern, indem Sie eine indizierte Ansicht erstellen:
CREATE VIEW v_mytable_da
WITH SCHEMABINDING
AS
SELECT a, COUNT_BIG(*) cnt
FROM dbo.mytable
GROUP BY
a
GO
CREATE UNIQUE CLUSTERED INDEX
pk_vmytableda_a
ON v_mytable_da (a)
GO
SELECT mi.*
FROM v_mytable_da md
CROSS APPLY
(
SELECT TOP 1 *
FROM mytable mi
WHERE mi.a = md.a
ORDER BY
b, c
) mi
ORDER BY
a