[ Teil 1 | Teil 2 | Teil 3 | Teil 4 ]
Im Laufe der Jahre wurde viel über das Verständnis und die Optimierung von SELECT geschrieben Abfragen, sondern weniger über Datenmodifikation. Diese Reihe von Beiträgen befasst sich mit einem Problem, das spezifisch für INSERT ist , UPDATE , DELETE und MERGE Abfragen – das Halloween-Problem.
Der Ausdruck „Halloween-Problem“ wurde ursprünglich in Bezug auf ein SQL-UPDATE geprägt Abfrage, die jedem Mitarbeiter, der weniger als 25.000 US-Dollar verdient, eine Gehaltserhöhung von 10 % gewähren sollte. Das Problem bestand darin, dass die Abfrage immer wieder 10 % Erhöhungen bis alle ergab mindestens 25.000 Dollar verdient. Wir werden später in dieser Serie sehen, dass das zugrunde liegende Problem auch für INSERT gilt , DELETE und MERGE Abfragen, aber für diesen ersten Eintrag ist es hilfreich, das UPDATE zu untersuchen Problem im Detail.
Hintergrund
Die SQL-Sprache bietet Benutzern die Möglichkeit, Datenbankänderungen mit einem UPDATE anzugeben -Anweisung, aber die Syntax sagt nichts über wie aus die Datenbank-Engine sollte die Änderungen durchführen. Andererseits legt der SQL-Standard fest, dass das Ergebnis eines UPDATE muss genauso sein, als ob es in drei getrennten und sich nicht überschneidenden Phasen ausgeführt worden wäre:
- Eine schreibgeschützte Suche ermittelt die zu ändernden Datensätze und die neuen Spaltenwerte
- Änderungen werden auf die betroffenen Datensätze angewendet
- Datenbankkonsistenzbeschränkungen werden überprüft
Die buchstäbliche Implementierung dieser drei Phasen in einer Datenbank-Engine würde zu korrekten Ergebnissen führen, aber die Leistung ist möglicherweise nicht sehr gut. Die Zwischenergebnisse in jeder Phase erfordern Systemspeicher, wodurch die Anzahl der Abfragen reduziert wird, die das System gleichzeitig ausführen kann. Der erforderliche Arbeitsspeicher kann auch den verfügbaren übersteigen, sodass zumindest ein Teil des Aktualisierungssatzes in den Plattenspeicher geschrieben und später wieder zurückgelesen werden muss. Zu guter Letzt muss bei diesem Ausführungsmodell jede Zeile in der Tabelle mehrmals berührt werden.
Eine alternative Strategie besteht darin, das UPDATE zu verarbeiten eine Reihe auf einmal. Dies hat den Vorteil, dass jede Zeile nur einmal berührt wird, und erfordert im Allgemeinen keinen Speicher zum Speichern (obwohl einige Operationen, wie eine vollständige Sortierung, den vollständigen Eingabesatz verarbeiten müssen, bevor die erste Ausgabezeile erzeugt wird). Dieses iterative Modell wird von der Abfrageausführungs-Engine von SQL Server verwendet.
Die Herausforderung für den Abfrageoptimierer besteht darin, einen iterativen (Zeile für Zeile) Ausführungsplan zu finden, der das UPDATE erfüllt Semantik, die vom SQL-Standard gefordert wird, während die Leistungs- und Nebenläufigkeitsvorteile der Pipeline-Ausführung beibehalten werden.
Verarbeitung aktualisieren
Um das ursprüngliche Problem zu veranschaulichen, werden wir eine Gehaltserhöhung von 10 % auf jeden Mitarbeiter anwenden, der weniger als 25.000 $ verdient, indem wir den Employees verwenden Tabelle unten:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Drei-Phasen-Update-Strategie
Die schreibgeschützte erste Phase findet alle Datensätze, die WHERE erfüllen -Klauselprädikat und speichert genügend Informationen für die zweite Phase, um ihre Arbeit zu erledigen. In der Praxis bedeutet dies, dass eine eindeutige Kennung für jede qualifizierende Zeile (die gruppierten Indexschlüssel oder die Heap-Zeilenkennung) und der neue Gehaltswert aufgezeichnet werden. Sobald Phase eins abgeschlossen ist, wird der gesamte Satz von Aktualisierungsinformationen an die zweite Phase weitergegeben, die jeden zu aktualisierenden Datensatz unter Verwendung der eindeutigen Kennung lokalisiert und das Gehalt auf den neuen Wert ändert. Die dritte Phase prüft dann, ob durch den endgültigen Zustand der Tabelle keine Einschränkungen der Datenbankintegrität verletzt werden.
Iterative Strategie
Bei diesem Ansatz wird jeweils eine Zeile aus der Quelltabelle gelesen. Wenn die Zeile WHERE erfüllt Klauselprädikat wird die Gehaltserhöhung angewendet. Dieser Vorgang wird wiederholt, bis alle Zeilen aus der Quelle verarbeitet wurden. Ein Beispiel für einen Ausführungsplan, der dieses Modell verwendet, ist unten dargestellt:

Wie bei der bedarfsgesteuerten Pipeline von SQL Server üblich, beginnt die Ausführung beim Operator ganz links – dem UPDATE in diesem Fall. Es fordert eine Zeile von Table Update an, die eine Zeile von Compute Scalar anfordert, und die Kette hinunter zum Table Scan:
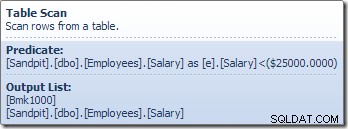
Der Table Scan-Operator liest Zeilen nacheinander aus der Speicher-Engine, bis er eine findet, die das Gehaltsprädikat erfüllt. Die Ausgabeliste in der obigen Grafik zeigt den Tabellen-Scan-Operator, der eine Zeilenkennung und den aktuellen Wert der Spalte „Gehalt“ für diese Zeile zurückgibt. Eine einzelne Zeile, die Verweise auf diese beiden Informationen enthält, wird an den Compute-Skalar weitergegeben:
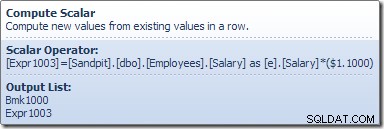
Der Berechnungsskalar definiert einen Ausdruck, der die Gehaltserhöhung auf die aktuelle Zeile anwendet. Es gibt eine Zeile mit Verweisen auf die Zeilenkennung und das geänderte Gehalt an die Tabellenaktualisierung zurück, die die Speichermaschine aufruft, um die Datenänderung durchzuführen. Dieser iterative Prozess wird fortgesetzt, bis dem Table Scan die Zeilen ausgehen. Derselbe grundlegende Prozess wird befolgt, wenn die Tabelle einen gruppierten Index hat:
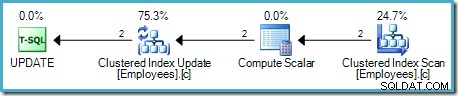
Der Hauptunterschied besteht darin, dass der/die Clustered-Index-Schlüssel und der Uniquifier (falls vorhanden) anstelle einer Heap-RID als Zeilenkennung verwendet werden.
Das Problem
Der Wechsel von der im SQL-Standard definierten logischen dreiphasigen Operation zum physischen iterativen Ausführungsmodell hat eine Reihe subtiler Änderungen eingeführt, von denen wir uns heute nur eine ansehen werden. In unserem laufenden Beispiel kann ein Problem auftreten, wenn es einen nicht gruppierten Index in der Spalte „Gehalt“ gibt, den der Abfrageoptimierer zu verwenden beschließt, um qualifizierte Zeilen zu finden (Gehalt <25.000 $):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
Das zeilenweise Ausführungsmodell kann nun falsche Ergebnisse liefern oder sogar in eine Endlosschleife geraten. Stellen Sie sich einen (imaginären) iterativen Ausführungsplan vor, der nach dem Gehaltsindex sucht, eine Zeile nach der anderen an den Compute-Skalar zurückgibt und schließlich an den Update-Operator weiterleitet:

Es gibt ein paar zusätzliche Compute-Skalare in diesem Plan aufgrund einer Optimierung, die die Wartung des Noncluster-Index überspringt, wenn sich der Gehaltswert nicht geändert hat (in diesem Fall nur möglich für ein Nullgehalt).
Abgesehen davon besteht das wichtige Merkmal dieses Plans darin, dass wir jetzt einen geordneten partiellen Indexscan haben, der jeweils eine Zeile an einen Operator weitergibt, der denselben Index ändert (die grüne Hervorhebung in der obigen Grafik des SQL Sentry-Plan-Explorers macht den Clustered Der Indexaktualisierungsoperator verwaltet sowohl die Basistabelle als auch den nicht gruppierten Index).
Wie auch immer, das Problem besteht darin, dass das Update durch die Verarbeitung einer Zeile nach der anderen die aktuelle Zeile vor die Scanposition verschieben kann, die von der Indexsuche verwendet wird, um zu ändernde Zeilen zu lokalisieren. Das Durcharbeiten des Beispiels sollte diese Aussage etwas klarer machen:
Der Nonclustered-Index ist nach dem Gehaltswert verschlüsselt und aufsteigend sortiert. Der Index enthält auch einen Zeiger auf die übergeordnete Zeile in der Basistabelle (entweder eine Heap-RID oder die Clustered-Index-Schlüssel plus Uniquifier, falls erforderlich). Nehmen Sie zum leichteren Nachvollziehen des Beispiels an, dass die Basistabelle jetzt einen eindeutigen gruppierten Index in der Spalte Name hat, sodass der Inhalt des nicht gruppierten Index zu Beginn der Aktualisierungsverarbeitung wie folgt lautet:
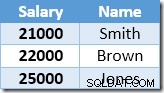
Die erste Zeile, die von der Indexsuche zurückgegeben wird, ist das Gehalt von 21.000 USD für Smith. Dieser Wert wird in der Basistabelle und im Nonclustered-Index durch den Clustered-Index-Operator auf 23.100 $ aktualisiert. Der Nonclustered-Index enthält jetzt:
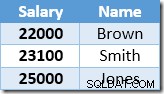
Die nächste von der Indexsuche zurückgegebene Zeile ist der $22.000-Eintrag für Brown, der auf $24.200 aktualisiert wird:
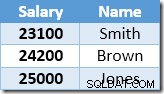
Jetzt findet die Indexsuche den Wert von 23.100 $ für Smith, der erneut aktualisiert wird , auf 25.410 $. Dieser Prozess wird fortgesetzt, bis alle Mitarbeiter ein Gehalt von mindestens 25.000 $ haben – was kein korrektes Ergebnis für das gegebene UPDATE ist Anfrage. Derselbe Effekt kann unter anderen Umständen zu einem außer Kontrolle geratenen Update führen, das nur beendet wird, wenn der Server keinen Protokollspeicher mehr hat oder ein Überlauffehler auftritt (in diesem Fall könnte dies auftreten, wenn jemand ein Nullgehalt hat). Das ist das Halloween-Problem in Bezug auf Updates.
Das Halloween-Problem für Updates vermeiden
Scharfäugige Leser werden bemerkt haben, dass die geschätzten Kostenprozentsätze im imaginären Index Seek-Plan sich nicht zu 100 % summierten. Mit Plan Explorer ist das kein Problem – ich habe absichtlich einen Key Operator aus dem Plan entfernt:

Der Abfrageoptimierer erkennt, dass dieser Pipeline-Aktualisierungsplan anfällig für das Halloween-Problem ist, und führt einen Eager Table Spool ein, um dessen Auftreten zu verhindern. Es gibt keinen Hinweis oder Trace-Flag, um die Aufnahme der Spule in diesen Ausführungsplan zu verhindern, da dies für die Korrektheit erforderlich ist.
Wie der Name schon sagt, verbraucht die Spule eifrig alle Zeilen von ihrem untergeordneten Operator (dem Index Seek), bevor sie eine Zeile an ihren übergeordneten Compute Scalar zurückgibt. Der Effekt davon ist die Einführung einer vollständigen Phasentrennung – Alle qualifizierten Zeilen werden gelesen und im temporären Speicher gespeichert, bevor Aktualisierungen durchgeführt werden.
Dies bringt uns der dreiphasigen logischen Semantik des SQL-Standards näher, obwohl bitte beachten Sie, dass die Planausführung immer noch grundsätzlich iterativ ist, wobei Operatoren rechts von der Spule den Lesecursor bilden , und Operatoren auf der linken Seite, die den Schreibcursor bilden . Der Inhalt der Spool wird weiterhin Zeile für Zeile gelesen und verarbeitet (es wird nicht en masse weitergegeben wie der Vergleich mit dem SQL-Standard sonst vermuten lässt).
Die Nachteile der Phasentrennung sind dieselben wie zuvor erwähnt. Die Tabellenspule verbraucht tempdb Speicherplatz (Seiten im Pufferpool) und kann unter Speicherdruck physische Lese- und Schreibvorgänge auf der Festplatte erfordern. Der Abfrageoptimierer weist der Spule geschätzte Kosten zu (vorbehaltlich aller üblichen Vorbehalte bei Schätzungen) und wählt zwischen Plänen, die einen Schutz gegen das Halloween-Problem erfordern, und solchen, die dies nicht tun, auf der Grundlage der geschätzten Kosten wie üblich. Natürlich kann der Optimierer aus den üblichen Gründen fälschlicherweise zwischen den Optionen wählen.
In diesem Fall besteht der Kompromiss zwischen der Effizienzsteigerung durch die direkte Suche nach qualifizierten Aufzeichnungen (solche mit einem Gehalt von <25.000 USD) und den geschätzten Kosten der Spule, die erforderlich ist, um das Halloween-Problem zu vermeiden. Ein alternativer Plan (in diesem speziellen Fall) ist ein vollständiger Scan des Clustered-Index (oder Heap). Diese Strategie erfordert nicht den gleichen Halloween-Schutz wie die Schlüssel des gruppierten Index werden nicht geändert:

Da die Indexschlüssel stabil sind, können Zeilen ihre Position im Index zwischen Iterationen nicht verschieben, wodurch das Halloween-Problem im vorliegenden Fall vermieden wird. Abhängig von den Laufzeitkosten des Clustered-Index-Scans im Vergleich zu der zuvor gesehenen Kombination Index Seek plus Eager Table Spool kann ein Plan schneller ausgeführt werden als der andere. Eine weitere Überlegung ist, dass der Plan mit Halloween-Schutz mehr Sperren erhält als der Plan mit vollständiger Pipeline und die Sperren länger gehalten werden.
Abschließende Gedanken
Das Verständnis des Halloween-Problems und der Auswirkungen, die es auf Abfragepläne zur Datenänderung haben kann, hilft Ihnen bei der Analyse von Ausführungsplänen zur Datenänderung und bietet Möglichkeiten, die Kosten und Nebenwirkungen unnötigen Schutzes zu vermeiden, wenn eine Alternative verfügbar ist.
Es gibt mehrere Formen des Halloween-Problems, die nicht alle durch Lesen und Schreiben in die Schlüssel eines gemeinsamen Index verursacht werden. Das Halloween-Problem ist auch nicht auf UPDATE beschränkt Abfragen. Der Abfrageoptimierer hat neben der Brute-Force-Phasentrennung mit einem Eager Table Spool weitere Tricks auf Lager, um das Halloween-Problem zu vermeiden. Diese Punkte (und mehr) werden in den nächsten Teilen dieser Serie untersucht.
[ Teil 1 | Teil 2 | Teil 3 | Teil 4 ]