Was ist Abfrageoptimierung in SQL Server? Es ist ein großes Thema. Für jede Technik oder jedes Problem ist ein separater Artikel erforderlich, um die Grundlagen abzudecken. Aber wenn Sie gerade erst anfangen, Ihr Spiel mit Abfragen zu verbessern, brauchen Sie etwas Einfacheres, auf das Sie sich verlassen können. Das ist das Ziel dieses Artikels.
Sie könnten sagen, Ihre Abfragen sind optimal, alles funktioniert gut und die Benutzer sind zufrieden. Leistung ist natürlich nicht alles. Auch die Ergebnisse sollten stimmen. Ob es sich um einen Join, eine Unterabfrage, ein Synonym, einen CTE, eine Ansicht oder was auch immer handelt, es muss eine akzeptable Leistung erbringen.
Und am Ende des Tages können Sie mit Ihren Benutzern nach Hause gehen. Sie möchten nicht über Nacht im Büro bleiben und die langsam laufenden Abfragen reparieren.
Bevor wir beginnen, lassen Sie mich Ihnen versichern, dass die Reise nicht rau sein wird. Dies wird nur eine Grundierung sein. Wir werden Beispiele haben, die Ihnen auch nicht allzu fremd sein werden. Wenn Sie bereit sind für eine tiefere Studie, stellen wir Ihnen schließlich einige Links vor, die Sie sich ansehen können.
Fangen wir an.
1. SQL-Abfrageoptimierung beginnt bei Design und Architektur
Überrascht? Die Optimierung von SQL-Abfragen ist kein nachträglicher Einfall oder ein Pflaster, wenn etwas kaputt geht. Ihre Abfrage wird so schnell ausgeführt, wie es Ihr Design zulässt. Wir sprechen über normalisierte Tabellen, die richtigen Datentypen, die Verwendung von Indizes, die Archivierung alter Daten und alle Best Practices, die Sie sich vorstellen können.
Ein gutes Datenbankdesign arbeitet in Synergie mit der richtigen Hardware und den richtigen SQL Server-Einstellungen. Haben Sie es so konzipiert, dass es mehrere Jahre reibungslos läuft und sich immer noch wie neu anfühlt? Das ist ein großer Traum, aber wir haben nur eine gewisse (normalerweise – kurze) Zeit, um darüber nachzudenken.
Es wird am ersten Tag der Produktion nicht perfekt sein, aber wir hätten die Grundlagen abdecken sollen. Wir minimieren technische Schulden. Wenn Sie mit einem Team arbeiten, ist das im Vergleich zu einer One-Man-Show großartig. Sie können einen Großteil des Schnickschnacks abdecken.
Was aber, wenn die Datenbank live läuft und Sie an die Leistungsgrenze stoßen? Hier sind einige Tipps und Tricks zur Optimierung von SQL-Abfragen.
2. Erkennen Sie problematische Abfragen mit dem SQL Server-Standardbericht
Wenn Sie codieren, ist es einfach, eine lange Reihe von Codes oder eine gespeicherte Prozedur zu erkennen. Sie können es Zeile für Zeile debuggen. Die Zeile, die verzögert, muss repariert werden.
Aber was ist, wenn Ihr Helpdesk ein Dutzend Tickets geworfen hat, weil es langsam ist? Benutzer können die genaue Position im Code nicht genau bestimmen, und der Helpdesk kann dies auch nicht. Zeit ist dein schlimmster Feind.
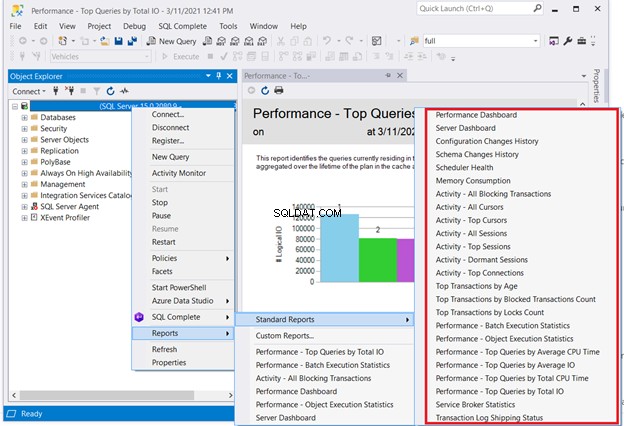
Eine Lösung, die keine Programmierung erfordert, ist die Überprüfung der Standardberichte des SQL-Servers. Klicken Sie in SQL Server Management Studio mit der rechten Maustaste auf den erforderlichen Server> Berichte> Standardberichte . Unser Interessenpunkt könnte das Leistungs-Dashboard sein oder Leistung – Top-Abfragen nach Gesamt-E/A . Wählen Sie die erste Abfrage mit schlechter Leistung aus. Starten Sie dann von dort aus die SQL-Abfrageoptimierung oder das SQL-Performance-Tuning.
3. SQL-Abfrageoptimierung mit STATISTICS IO
Nachdem Sie die betreffende Abfrage lokalisiert haben, können Sie mit der Überprüfung der logischen Lesevorgänge in STATISTICS IO beginnen. Dies ist eines der Tools zur Optimierung von SQL-Abfragen.
Es gibt ein paar E/A-Punkte, aber Sie sollten sich auf logische Lesevorgänge konzentrieren. Je höher die logischen Lesevorgänge sind, desto problematischer ist die Abfrageleistung.
Indem Sie die folgenden 3 Faktoren reduzieren, können Sie die Abfragen zur Leistungsoptimierung in SQL beschleunigen:
- hohe logische Lesevorgänge,
- Logische Lesevorgänge mit hohem LOB
- oder hohe logische WorkTable/WorkFile-Lesevorgänge.
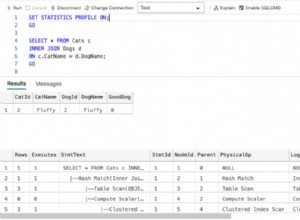
Um Informationen zu logischen Lesevorgängen zu erhalten, aktivieren Sie STATISTICS IO im SQL Server Management Studio-Abfragefenster.
SETZEN SIE STATISTIK IO EIN
Sie können die Ausgabe auf der Registerkarte Nachrichten abrufen, nachdem die Abfrage abgeschlossen ist. Abbildung 2 zeigt die Beispielausgabe:
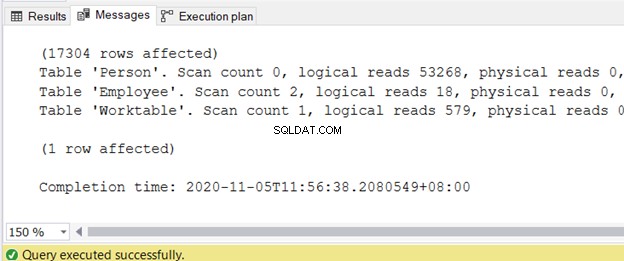
Ich habe einen separaten Artikel über das Reduzieren logischer Lesevorgänge in 3 Nasty I/O Statistics that Lag SQL Query Performance geschrieben. Darin finden Sie die genauen Schritte und Codebeispiele mit hohen logischen Lesezugriffen und Möglichkeiten, diese zu reduzieren.
4. SQL-Abfrageoptimierung mit Ausführungsplänen
Logisches Lesen allein gibt Ihnen kein vollständiges Bild. Die vom Abfrageoptimierer ausgewählte Reihe von Schritten erzählt die Geschichte Ihrer Ergebnismenge. Wie fängt alles an, nachdem Sie die Abfrage ausgeführt haben?
Abbildung 3 unten ist ein Diagramm, das zeigt, was passiert, nachdem Sie die Ausführung ausgelöst haben, bis Sie die Ergebnismenge erhalten.
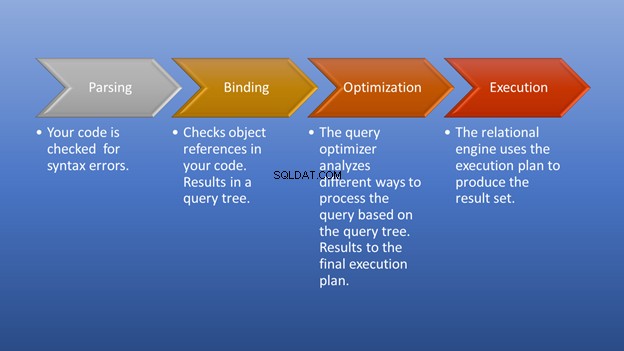
Das Parsen und Binden erfolgt im Handumdrehen. Der großartige Teil ist die Optimierungsphase, auf die wir uns konzentrieren. In dieser Phase spielt der Abfrageoptimierer eine zentrale Rolle bei der Auswahl des bestmöglichen Ausführungsplans. Obwohl dieser Teil einige Ressourcen benötigt, spart er viel Zeit, wenn er einen effizienten Ausführungsplan auswählt. Dies geschieht dynamisch, da sich die Datenbank im Laufe der Zeit ändert. Auf diese Weise kann sich der Programmierer darauf konzentrieren, wie er das Endergebnis bildet.
Jeder Plan, den der Abfrageoptimierer berücksichtigt, hat seine Abfragekosten. Unter vielen Optionen wählt der Optimierer den Plan mit den angemessensten Kosten aus. Hinweis :Angemessene Kosten sind nicht gleich den geringsten Kosten. Es muss auch berücksichtigt werden, welcher Plan die schnellsten Ergebnisse liefert. Der Plan mit den geringsten Kosten ist nicht immer der schnellste. Beispielsweise kann der Optimierer wählen, mehrere Prozessorkerne zu verwenden. Wir nennen dies parallele Ausführung. Dies verbraucht mehr Ressourcen, läuft aber im Vergleich zur seriellen Ausführung schneller.
Ein weiterer zu berücksichtigender Punkt ist die Statistik. Der Abfrageoptimierer verlässt sich darauf, um Ausführungspläne zu erstellen. Wenn die Statistiken veraltet sind, erwarten Sie nicht die beste Entscheidung vom Abfrageoptimierer.
Wenn der Plan entschieden ist und die Ausführung fortgesetzt wird, werden Sie die Ergebnisse sehen. Was jetzt?
Überprüfen Sie den Abfrageausführungsplan in SQL Server
Wenn Sie eine Abfrage erstellen, möchten Sie zuerst die Ergebnisse sehen. Die Ergebnisse müssen stimmen. Wenn dies der Fall ist, sind Sie fertig.
Stimmt das?
Wenn Sie wenig Zeit haben und der Job auf dem Spiel steht, können Sie dem zustimmen. Außerdem kannst du immer wieder zurückkommen. Treten jedoch andere Probleme auf, kann man diese immer wieder vergessen. Und dann wird dich der Geist der Vergangenheit jagen.
Was ist nun das Beste, nachdem Sie die richtigen Ergebnisse erhalten haben?
Untersuchen Sie den Tatsächlichen Ausführungsplan oder die Live-Suchstatistik !
Letzteres ist gut, wenn Ihre Abfrage langsam läuft und Sie sehen möchten, was jede Sekunde passiert, während die Zeilen verarbeitet werden.
Manchmal zwingt Sie die Situation, den Plan sofort zu überprüfen. Drücken Sie zum Starten Strg-M oder klicken Sie auf Aktuellen Ausführungsplan einschließen aus der Symbolleiste von SQL Server Management Studio. Wenn Sie dbForge Studio für SQL Server bevorzugen, gehen Sie zu Query Profiler – Es bietet die gleichen Informationen + einige Schnickschnack, die Sie in SSMS nicht finden können.
Wir haben den Tatsächlichen Ausführungsplan gesehen . Fahren wir fort.
Gibt es einen fehlenden Index oder fehlende Indexempfehlungen?
Ein fehlender Index ist leicht zu erkennen – Sie erhalten sofort eine Warnung.
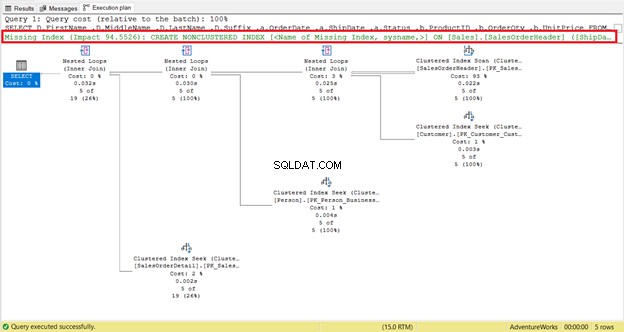
Um einen sofortigen Code zum Erstellen des Index zu erhalten, klicken Sie mit der rechten Maustaste auf Fehlender Index Nachricht (rot umrandet). Wählen Sie dann Fehlende Indexdetails aus . Ein neues Abfragefenster mit dem Code zum Erstellen des fehlenden Index wird angezeigt. Erstellen Sie den Index.
Dieser Teil ist leicht zu befolgen. Es ist ein guter Ausgangspunkt, um eine schnellere Ausführung zu erreichen. Aber in einigen Fällen wird es keine Wirkung geben. Wieso den? Einige Spalten, die von Ihrer Abfrage benötigt werden, befinden sich nicht im Index. Daher wird es zu einem Clustered Index Scan zurückkehren.
Sie müssen den Ausführungsplan nach dem Erstellen des Index erneut überprüfen, um zu sehen, ob eingeschlossene Spalten benötigt werden. Passen Sie dann den Index entsprechend an und führen Sie Ihre Abfrage erneut aus. Überprüfen Sie danach erneut den Ausführungsplan.
Aber was ist, wenn kein fehlender Index vorhanden ist?
Lesen Sie den Ausführungsplan
Sie müssen ein paar grundlegende Dinge wissen, um loszulegen:
- Operatoren
- Eigenschaften
- Leserichtung
- Warnungen
OPERATOREN
Der Abfrageoptimierer verwendet eine Art von Miniprogrammen, die als Operatoren bezeichnet werden. Sie haben einige davon in Abbildung 4 – Clustered Index Seek – gesehen , Clustered-Index-Scan , Verschachtelte Schleifen und Auswählen .
Eine umfassende Liste mit Namen, Symbolen und Beschreibungen finden Sie in dieser Referenz von Microsoft.
EIGENSCHAFTEN
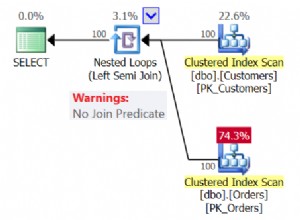
Grafische Diagramme reichen nicht aus, um zu verstehen, was hinter den Kulissen passiert. Sie müssen sich eingehender mit den Eigenschaften jedes Operators befassen. Zum Beispiel der Clustered Index Scan in Abbildung 4 hat die folgenden Eigenschaften:
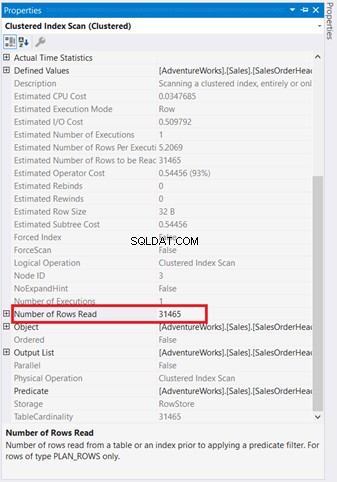
Wenn Sie es genau untersuchen, der Clustered Index Scan Betreiber ist schrecklich. Wie Abbildung 5 zeigt, wurden 31.465 Zeilen gelesen, aber die endgültige Ergebnismenge besteht nur aus 5 Zeilen. Aus diesem Grund gibt es in Abbildung 4 eine Indexempfehlung, um die Anzahl der gelesenen Zeilen zu reduzieren. Die logischen Lesevorgänge der Abfrage sind ebenfalls hoch und dies erklärt warum.
Um mehr über diese Eigenschaften zu erfahren, sehen Sie sich die Liste der allgemeinen Operator-Eigenschaften und Plan-Eigenschaften an.
LESERICHTUNG
Im Allgemeinen ist es, als würde man japanische Mangas lesen – von rechts nach links. Folgen Sie den Pfeilen, die nach links zeigen. Hier ist ein einfaches Beispiel aus dbForge Studio für SQL Server.
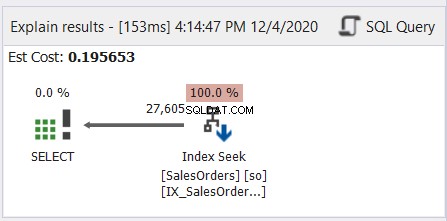
Wie Abbildung 6 zeigt, zeigt der Pfeil vom Index Seek-Operator nach links zum SELECT-Operator.
Das Lesen von rechts nach links ist jedoch möglicherweise nicht immer korrekt. Siehe Abbildung 7 mit einem Beispiel aus SSMS:
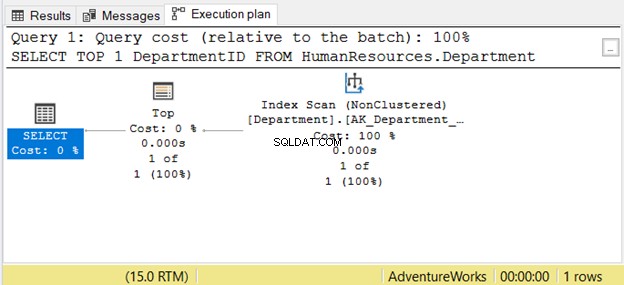
Wenn Sie es von rechts nach links lesen, sehen Sie den Index-Scan Operatorausgabe ist 1 von 1 Zeile. Wie könnte es wissen, dass nur eine Zeile abgerufen werden muss? Es liegt an der Oberseite Operator. Dies wird uns verwirren, wenn wir es von rechts nach links lesen.
Um diesen Fall besser zu verstehen, lesen Sie ihn als „der SELECT-Operator verwendet Top, um 1 Zeile mit Index Scan abzurufen“. Das ist von links nach rechts.
Was sollten wir verwenden? Von rechts nach links oder von links nach rechts?
Es ist irgendwie beides – je nachdem, was Ihnen hilft, den Plan zu verstehen.
Während uns der Pfeil die Richtung des Datenflusses angibt, gibt uns seine Dicke einige Hinweise auf die Größe der Daten. Lassen Sie uns noch einmal auf Abbildung 4 verweisen.
Der Clustered Index Scan zum Nested Loop gehen hat im Vergleich zu den anderen einen dickeren Pfeil. Die Eigenschaften Details zum Index-Scan in Abbildung 5 sagen Sie uns, warum es dick ist (31.465 gelesene Zeilen für ein Endergebnis von 5 Zeilen).
WARNUNGEN
Ein Warnsymbol, das im Ausführungsplan-Operator erscheint, weist uns darauf hin, dass in diesem Operator etwas Schlimmes passiert ist. Dies kann Ihre SQL-Abfrageoptimierung behindern, indem mehr Ressourcen verbraucht werden.
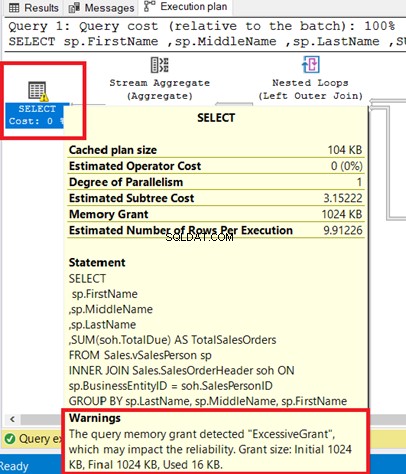
Sie können die Warnung im SELECT-Operator sehen. Wenn Sie den Mauszeiger auf diesen Operator bewegen, wird die Warnmeldung angezeigt. Ein ExcessiveGrant hat diese Warnung verursacht.
ExcessiveGrant passiert, wenn weniger Speicher verwendet wird, als für die Abfrage reserviert wurde. Weitere Informationen finden Sie in dieser Microsoft-Dokumentation.
Abbildung 8 zeigt die Abfrage, die als INNER JOIN einer Ansicht zu einer Tabelle verwendet wird. Sie können die Warnung entfernen, indem Sie anstelle der Ansicht Basistabellen verknüpfen.
Nun, da Sie eine grundlegende Vorstellung vom Lesen von Ausführungsplänen haben, wie definieren Sie, was Ihre Abfrage langsam macht?
Kennen Sie die 5 Common-Plan-Operator-Schurken
Die Verzögerung bei der Ausführung Ihrer Abfrage ist wie ein Verbrechen. Du musst diese Schurken jagen und verhaften.
1. Geclusterter oder nicht geclusterter Index-Scan
Der erste Rogue, von dem jeder erfährt, ist Clustered oder Non-Clustered Index Scan . In der SQL-Abfrageoptimierung ist allgemein bekannt, dass Scans schlecht und Suchvorgänge gut sind. Wir haben einen in Abbildung 4 gesehen. Wegen des fehlenden Index der Clustered Index Scan liest 31.465, um 5 Zeilen zu erhalten.
Dies ist jedoch nicht immer der Fall. Betrachten Sie zwei Abfragen für dieselbe Tabelle in Abbildung 9. Eine hat eine Suche und eine andere eine Suche.
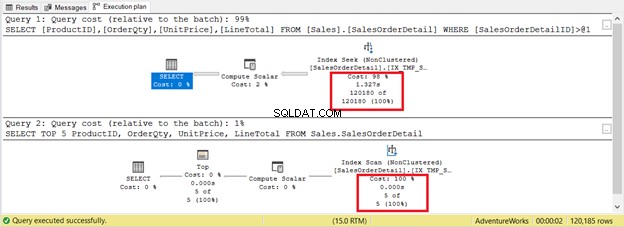
Wenn Sie die Kriterien nur auf die Anzahl der Datensätze stützen, gewinnt der Index-Scan mit nur 5 Datensätzen gegenüber 120.180. Die Indexsuche wird länger dauern.
Hier ist ein weiterer Fall, in dem entweder scannen oder suchen fast keine Rolle spielt. Sie geben dieselben 6 Datensätze aus derselben Tabelle zurück. Die logischen Lesevorgänge sind die gleichen und die verstrichene Zeit ist in beiden Fällen Null. Die Tabelle ist mit nur 6 Datensätzen sehr klein. Fügen Sie den tatsächlichen Ausführungsplan hinzu und führen Sie die folgenden Anweisungen aus.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
Speichern Sie dann den Ausführungsplan für einen späteren Vergleich. Klicken Sie mit der rechten Maustaste auf den Ausführungsplan> Ausführungsplan speichern unter .
Führen Sie nun die folgende Abfrage aus.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
Klicken Sie anschließend mit der rechten Maustaste auf den Ausführungsplan und wählen Sie Showplan vergleichen aus . Wählen Sie dann die zuvor gespeicherte Datei aus. Sie sollten die gleiche Ausgabe wie in Abbildung 10 unten haben.
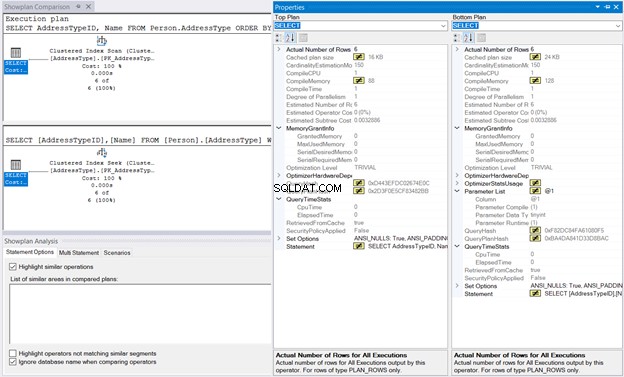
Der MemoryGrant und QueryTimeStats sind gleich. Der 128 KB große CompileMemory in der Clustered Index Seek verwendet im Vergleich zu 88 KB beim Clustered Index Scan ist fast vernachlässigbar. Ohne diese Vergleichszahlen wird sich die Ausführung genauso anfühlen.
2. Tabellen-Scans vermeiden
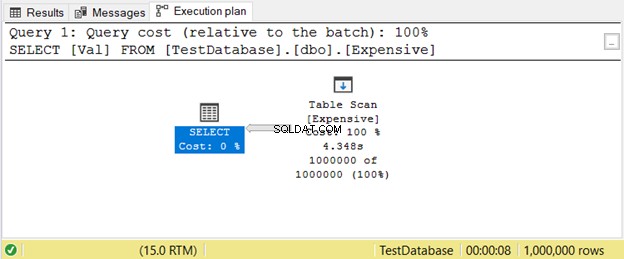
Dies geschieht, wenn Sie keinen Index haben. Anstatt Werte mithilfe eines Indexes zu suchen, scannt SQL Server Zeilen nacheinander, bis er das erhält, was Sie in Ihrer Abfrage benötigen. Dies wird auf großen Tischen stark verzögert. Die einfache Lösung besteht darin, den entsprechenden Index hinzuzufügen.
Hier ist ein Beispiel für einen Ausführungsplan mit Table Scan Operator in Abbildung 11.
3. Verwalten der Sortierleistung
Wie es vom Namen kommt, ändert es die Reihenfolge der Zeilen. Dies kann eine teure Operation sein.
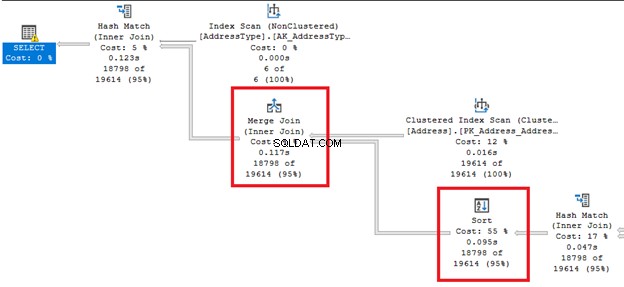
Sehen Sie sich diese dicken Pfeillinien rechts und links von Sortieren an Operator. Da der Abfrageoptimierer entschieden hat, einen Merge-Join durchzuführen , eine Sortierung erforderlich. Beachten Sie auch, dass es die höchsten prozentualen Kosten aller Betreiber hat (55 %).
Das Sortieren kann problematischer sein, wenn SQL Server Zeilen mehrmals sortieren muss. Sie können diesen Operator vermeiden, wenn Ihre Tabelle basierend auf der Abfrageanforderung vorsortiert ist. Oder Sie können eine einzelne Abfrage in mehrere aufteilen.
4. Eliminieren Sie Schlüsselsuchen
In Abbildung 4 zuvor hat SQL Server empfohlen, einen weiteren Index hinzuzufügen. Ich tat es, aber es gab mir nicht genau das, was ich wollte. Stattdessen gab es mir einen Index Seek zum neuen Index gepaart mit einer Schlüsselsuche Betreiber.
Der neue Index fügte also einen zusätzlichen Schritt hinzu.
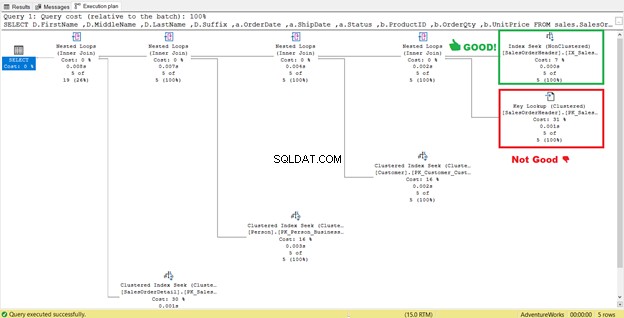
Was bedeutet diese Schlüsselsuche Betreiber tun?
Der Abfrageprozessor verwendete einen neuen nicht geclusterten Index, der in Abbildung 13 grün eingerahmt ist. Da unsere Abfrage Spalten erfordert, die nicht im neuen Index enthalten sind, muss er diese Daten mit Hilfe einer Schlüsselsuche abrufen aus dem gruppierten Index. Woher wissen wir das? Bewegen Sie die Maus auf Key Lookup enthüllt einige seiner Eigenschaften und beweist unseren Standpunkt.
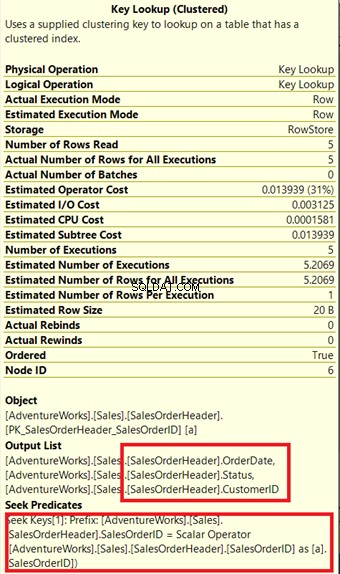
Beachten Sie in Abbildung 14 die Ausgabeliste. Wir müssen 3 Spalten mit der PK_SalesOrderHeader_SalesOrderID abrufen geclusterter Index. Um dies zu entfernen, müssen Sie diese Spalten in den neuen Index aufnehmen. Hier ist der neue Plan, sobald diese Spalten enthalten sind.
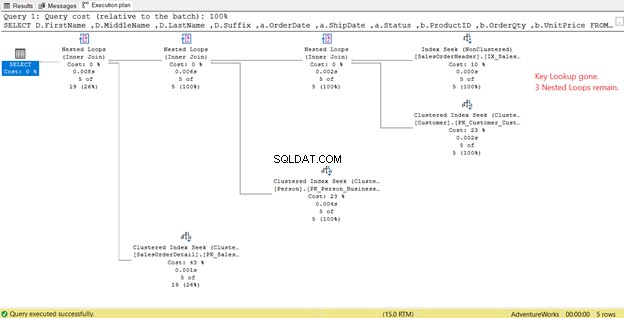
In Abbildung 14 haben wir 4 verschachtelte Schleifen gesehen . Der vierte wird für die hinzugefügte Schlüsselsuche benötigt . Aber nach dem Hinzufügen von 3 Spalten als eingeschlossene Spalten in den neuen Index, nur 3 Nested Loops verbleiben und die Schlüsselsuche ist entfernt. Wir brauchen keine zusätzlichen Schritte.
5. Parallelität im SQL Server-Ausführungsplan
Bisher sahen Sie Ausführungspläne in Serienausführung. Aber hier ist der Plan, der die parallele Ausführung nutzt. Das bedeutet, dass mehr als ein Prozessor vom Abfrageoptimierer verwendet wird, um die Abfrage auszuführen. Wenn wir die parallele Ausführung verwenden, sehen wir Parallelität Betreiber im Plan und auch andere Änderungen.
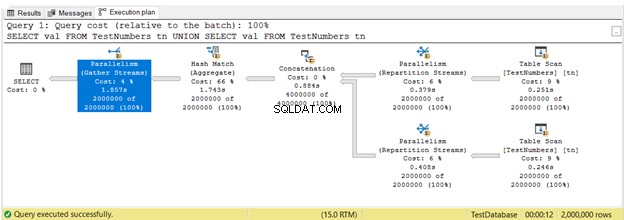
In Abbildung 16, 3 Parallelität Operatoren verwendet wurden. Beachten Sie auch, dass der Table Scan Operator-Symbol ist ein bisschen anders. Dies geschieht, wenn die parallele Ausführung verwendet wird.
Parallelität ist nicht per se schlecht. Es erhöht die Geschwindigkeit von Abfragen, indem mehr Prozessorkerne verwendet werden. Es verbraucht jedoch mehr CPU-Ressourcen. Wenn viele Ihrer Abfragen Parallelismen verwenden, verlangsamt dies den Server. Sie sollten den Kostenschwellenwert für die Parallelitätseinstellung in Ihrem SQL Server überprüfen.
5. Best Practices für die Optimierung von SQL-Abfragen
Bisher haben wir uns mit der Optimierung von SQL-Abfragen mit Methoden befasst, die schwer erkennbare Probleme aufdecken. Aber es gibt Möglichkeiten, es im Code zu erkennen. Hier sind einige Code-Smells in SQL.
Mit SELECT *
In Eile? Dann kann die Eingabe von * einfacher sein als die Angabe von Spaltennamen. Es gibt jedoch einen Haken. Spalten, die Sie nicht benötigen, verzögern Ihre Abfrage.
Es gibt Beweise. Die Beispielabfrage, die ich für Abbildung 15 verwendet habe, lautet wie folgt:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Wir haben es bereits optimiert. Aber ändern wir es in SELECT *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Es ist in Ordnung kürzer, aber überprüfen Sie den Ausführungsplan unten:
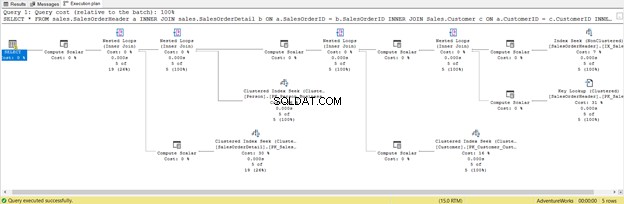
Dies ist die Folge der Einbeziehung aller Spalten, auch derer, die Sie nicht benötigen. Es wurde Key Lookup zurückgegeben und jede Menge Compute Scalar . Kurz gesagt, diese Abfrage hat eine hohe Last und wird daher verzögert. Beachten Sie auch die Warnung im SELECT-Operator. Es war vorher nicht da. Was für eine Verschwendung!
Funktionen in einer WHERE-Klausel oder einem JOIN
Ein weiterer Code-Smell hat eine Funktion in der WHERE-Klausel. Betrachten Sie die folgenden 2 SELECT-Anweisungen mit derselben Ergebnismenge. Der Unterschied liegt in der WHERE-Klausel.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
Die erste SELECT-Anweisung verwendet die Datumsfunktionen YEAR und MONTH, um Versanddaten im Juli 2011 anzugeben. Die zweite SELECT-Anweisung verwendet den BETWEEN-Operator mit Datumsliteralen.
Die erste SELECT-Anweisung hat einen Ausführungsplan ähnlich dem in Abbildung 4, jedoch ohne die Indexempfehlung. Die zweite hat einen besseren Ausführungsplan ähnlich wie in Abbildung 15.
Der besser optimierte ist offensichtlich.
Verwendung von Platzhaltern
Wie stark können Wildcards unsere SQL-Abfrageoptimierung beeinflussen? Lassen Sie uns ein Beispiel haben.
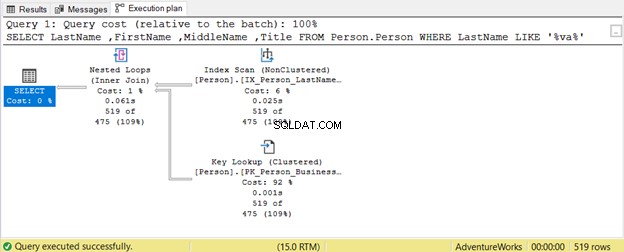
Die Abfrage versucht, nach einer Zeichenfolge in Nachname zu suchen in jeder Stellung. Daher Nachname LIKE ‘%va%’ . Dies ist bei großen Tabellen ineffizient, da Zeilen nacheinander auf das Vorhandensein dieser Zeichenfolge überprüft werden. Deshalb ein Index Scan wird genutzt. Da kein Index den Titel enthält Spalte, eine Schlüsselsuche wird ebenfalls verwendet.
Dies kann durch Design behoben werden.
Verlangt die anrufende App das? Oder reicht es aus, LIKE „va%“ zu verwenden?
LIKE „va%“ verwendet eine Indexsuche weil die Tabelle einen Index auf lastname hat , Vorname , und Zwischenname .
Können Sie auch weitere Filter in der WHERE-Klausel hinzufügen, um das Lesen der Datensätze zu reduzieren?
Ihre Antworten auf diese Fragen helfen Ihnen dabei, diese Abfrage zu beheben.
Implizite Konvertierung
SQL Server führt im Hintergrund eine implizite Konvertierung durch, um Datentypen beim Vergleichen von Werten abzugleichen. Beispielsweise ist es praktisch, einer Zeichenfolgenspalte eine Zahl ohne Anführungszeichen zuzuweisen. Aber da ist ein Fang. Der Effekt ist ähnlich, wenn Sie eine Funktion in einer WHERE-Klausel verwenden.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
Die NationalIDNumner ist NVARCHAR(15), wird aber einer Zahl gleichgesetzt. Es wird aufgrund der impliziten Konvertierung erfolgreich ausgeführt. Aber beachten Sie den Ausführungsplan in Abbildung 19 unten.
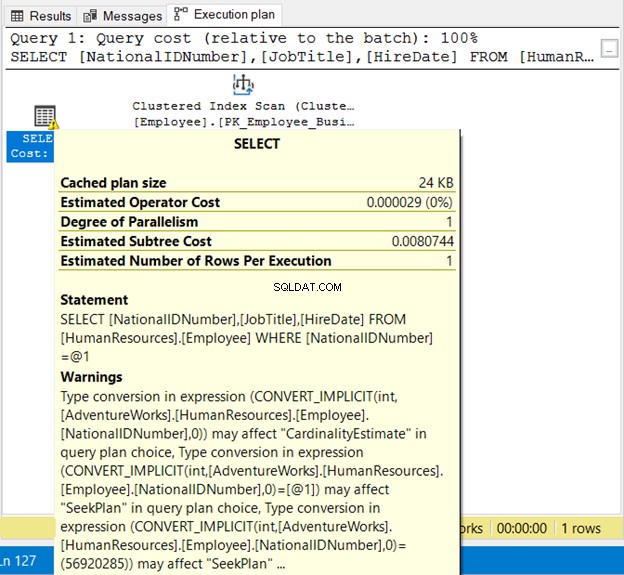
Wir sehen hier 2 schlechte Dinge. Zuerst die Warnung. Dann der Index-Scan . Der Index-Scan erfolgte aufgrund einer impliziten Konvertierung. Achten Sie daher darauf, Zeichenfolgen in Anführungszeichen zu setzen oder Literalwerte mit demselben Datentyp wie die Spalte zu testen.
Imbiss zur SQL-Abfrageoptimierung
Das ist es. Fühlen Sie sich durch die Grundlagen der SQL-Abfrageoptimierung bereit für Ihre Abfragen? Fassen wir zusammen.
- Wenn Sie Ihre Abfragen optimieren möchten, beginnen Sie mit einem guten Datenbankdesign.
- Wenn die Datenbank bereits in Produktion ist, erkennen Sie die problematischen Abfragen mithilfe von SQL Server-Standardberichten.
- Erfahren Sie, wie groß die Auswirkung der langsamen Abfrage mit logischen Lesevorgängen von STATISTICS IO ist.
- Gehen Sie mit Ausführungsplänen tiefer in die Geschichte Ihrer langsamen Abfrage ein.
- Sehen Sie sich 4 Codegerüche an, die Ihre Abfragen verlangsamen.
Es gibt weitere Tipps zur Optimierung von SQL-Abfragen, um eine langsame Abfrage schnell auszuführen. Wie ich eingangs sagte, ist das ein großes Thema. Teilen Sie uns also im Kommentarbereich mit, was wir sonst noch vermisst haben.
Und wenn Ihnen dieser Beitrag gefällt, teilen Sie ihn auf Ihren bevorzugten Social-Media-Plattformen.
Weitere SQL-Abfrageoptimierung aus früheren Artikeln
Wenn Sie weitere Beispiele benötigen, finden Sie hier einige nützliche Beiträge zu Abfrageoptimierungstechniken in SQL Server.
- Sind Unterabfragen schlecht für die Leistung? Sehen Sie sich Die einfache Anleitung zur Verwendung von Unterabfragen in SQL Server an .
- Die Verwendung von HierarchyID im Vergleich zum Parent/Child-Design – was ist schneller? Besuchen Sie So verwenden Sie die SQL Server-Hierarchie-ID anhand einfacher Beispiele .
- Können Graphdatenbankabfragen ihre relationalen Äquivalente in einem Echtzeit-Empfehlungssystem übertreffen? Sehen Sie sich So nutzen Sie die Funktionen der SQL Server-Graphdatenbank an .
- Was ist schneller:COALESCE oder ISNULL? Finden Sie es in den Top-Antworten auf 5 brennende Fragen zur SQL COALESCE-Funktion heraus .
- SELECT FROM View vs. SELECT FROM Basistabellen – welche wird schneller laufen? Besuchen Sie Die 3 wichtigsten Tipps, die Sie kennen sollten, um schnellere SQL-Ansichten zu schreiben .
- CTE vs. Temporäre Tabellen vs. Unterabfragen. Erfahren Sie in Alles, was Sie über SQL CTE wissen müssen, an einem Ort, wer gewinnen wird .
- Die Verwendung von SQL SUBSTRING in einer WHERE-Klausel – eine Performance-Falle? Sehen Sie anhand von Beispielen in How to Parse Strings Like a Professional Using SQL SUBSTRING() Function? nach, ob das stimmt
- SQL UNION ALL ist schneller als UNION. Erfahren Sie warum im SQL UNION Cheat Sheet mit 10 einfachen und nützlichen Tipps .