In einer Zeit, in der täglich riesige Datenmengen generiert werden, spielen Daten eine entscheidende Rolle bei der Entscheidungsfindung für den Geschäftsbetrieb. Um mit Daten umgehen zu können, benötigen wir also Datenbanken, und dies gibt uns die Notwendigkeit, Datenbankverwaltungssysteme zu verstehen. Mit verschiedenen Datenbankverwaltungssystemen ist MS SQL Server eines der beliebtesten relationalen Datenbankverwaltungssysteme. Diese Art von DBMS verwendet eine Struktur, die es Benutzern ermöglicht, Daten in Relation zu identifizieren und darauf zuzugreifen zu einem anderen Datenelement in der Datenbank. Die Kenntnis von MS SQL Server öffnet Ihnen also die Türen, um Datenbankadministrator zu werden. Ich glaube, dass Sie sich dieser Tatsachen bereits bewusst sind, und das hat Sie dazu gebracht, auf diesem Artikel zu Fragen im Vorstellungsgespräch für MS SQL Server zu landen.
In diesem Artikel über Fragen in Vorstellungsgesprächen zu Microsoft SQL Server werde ich die wichtigsten Fragen zu MS SQL Server besprechen, die in Ihren Vorstellungsgesprächen gestellt wurden. Diese Fragen werden nach Rücksprache mit Personen mit hervorragenden Kenntnissen auf diesem Gebiet erhoben.
Fangen wir an!
Q1. Nennen Sie die Unterschiede zwischen SQL Server und MySQL.
| SQL-Server | MySQL |
Entwickelt von Microsoft | Entwickelt von Oracle |
Lizenzierte Software | Open-Source-Software |
Unterstützt C#, Java C++, PHP, Visual Basic, Perl, Python, Ruby usw. | Unterstützt PHP, Perl, Python, Ruby usw. |
Erlaubt keine Manipulation von Datenbankdateien während der Ausführung | Ermöglicht die Manipulation von Datenbankdateien während der Ausführung. |
Ermöglicht das Abbrechen der Abfrage mitten im Prozess | Lässt keinen Abfrageabbruch mitten im Prozess zu. |
Beim Sichern der Daten wird die Datenbank nicht blockiert | Beim Sichern der Daten wird die Datenbank blockiert |
Nimmt viel Speicherplatz in Anspruch. | Nehmt weniger Speicherplatz in Anspruch. |
Verfügbar im Express- und benutzerdefinierten Modus. | Verfügbar in MySQL Community Edition und MySQL Enterprise Edition |
Q2. Was verstehen Sie unter SQL Server Agent?
SQL Server Agent ist ein Windows-Dienst, der zum Planen und Ausführen von Jobs verwendet wird. Hier enthält jeder Job einen oder mehrere Schritte, und jeder Schritt enthält eine Aufgabe. Der Server-Agent verwendet also den SQL Server, um Jobinformationen zu speichern und einen Job nach einem Zeitplan auszuführen.
Die Hauptkomponenten des SQL Server-Agenten sind Jobs, Zeitpläne, Operatoren und Warnungen.
Beispiel:
Wenn ein Unternehmen jeden Freitag um 21:00 Uhr ein Backup der Firmenserver erstellen möchte, dann können Sie diese Aufgabe sehr gut automatisieren, damit der Zeitplan von selbst ablaufen kann . In einem Szenario, bei dem die Sicherung auf einen Fehler stößt, zeichnet der SQL Server-Agent das Ereignis auf und benachrichtigt das entsprechende Team.
Q3. Erwähnen Sie die verschiedenen Authentifizierungsmodi in SQL Server.
Bevor ich Ihnen die verschiedenen Authentifizierungsmodi in SQL Server erzähle, lassen Sie mich Ihnen sagen, dass der Authentifizierungsmodus zur Authentifizierung eines Benutzers in SQL Server verwendet wird. Der Authentifizierungsmodus wird beim Einrichten der Datenbank-Engine ausgewählt. Wenn Sie also wissen möchten, wie Sie Microsoft SQL Server einrichten, können Sie sich auf meinen Artikel beziehen.
Die verschiedenen von SQL SERVER angebotenen Authentifizierungsmodi sind wie folgt:
- Windows-Authentifizierungsmodus: Dieser Modus wird verwendet, um den Server über ein Windows-Konto zu verbinden. Hier nimmt der Server den Benutzernamen und das Passwort des Computers zu Authentifizierungszwecken. Außerdem ist der SQL-Server-Authentifizierungsmodus in diesem Modus deaktiviert.
- Gemischter Modus: Der gemischte Modus wird verwendet, um eine Verbindung mit einer Instanz von SQL Server mithilfe der SQL Server-Authentifizierung oder der Windows-Authentifizierung herzustellen. In diesem Modus werden ein Benutzername und ein Passwort vom Benutzer für die Datenbank festgelegt.
Q4. Nennen Sie die Unterschiede zwischen lokalen und globalen temporären Tabellen.
| Lokale temporäre Tabelle | Globale temporäre Tabelle |
Diese Tabellen existieren nur für die Dauer der Verbindung oder die Dauer dieser Aussage. | Diese Tabellen existieren dauerhaft in der Datenbank und nur die Zeilen werden gelöscht, wenn die Verbindung geschlossen wird. |
Syntax: TABELLE ERSTELLEN # | Syntax: TABELLE ERSTELLEN ## |
F5. Wie können Sie die Version von SQL Server überprüfen?
Um die Version von SQL Server zu überprüfen, können Sie den folgenden Befehl verwenden:
SELECT @@version
Die @@VERSION gibt die Ausgabe als eine nvarchar-Zeichenfolge aus.
F6. Was ist der Einzelbenutzermodus und welche Schritte sollten Sie befolgen, um SQL Server im Einzelbenutzermodus zu starten?
Es kann oft vorkommen, dass Sie eine Instanz von SQL Server im Einzelbenutzermodus starten möchten. Sie können dies tun, wenn Sie entweder Daten von anderen Datenbanksystemen wiederherstellen oder Serverkonfigurationen ändern möchten.
Wenn Sie den SQL Server im Einzelbenutzermodus starten, wird jedes Mitglied der lokalen Administratorengruppe des Computers als sysadmin mit der Instanz von SQL Server verbunden.
Die folgenden Ereignisse treten beim Starten der Datenbank im Einzelbenutzermodus auf:
- Ein einzelner Benutzer stellt eine Verbindung zum Server her.
- Der CHECKPOINT Der Prozess wird nicht ausgeführt, da er standardmäßig beim Start ausgeführt wird.
Beachten Sie außerdem, dass Sie den SQL Server Agent-Dienst stoppen müssen, bevor Sie im Einzelbenutzermodus eine Verbindung zu einer Instanz von SQL Server herstellen.
- Um SQL Server im Einzelbenutzermodus zu starten, verwenden Sie den Befehl:
sqlcmd –m - Um eine Verbindung über den Abfrage-Editor in Management Studio herzustellen, verwenden Sie:
-m"Microsoft SQL Server Management Studio - Query".
F7. Was ist SQL Server Profiler?
Der Microsoft SQL Server Profiler ist eine Schnittstelle zum Erstellen und Verwalten von Ablaufverfolgungen. Außerdem werden die Trace-Ergebnisse analysiert und wiedergegeben. Hier werden Ereignisse in einer Ablaufverfolgungsdatei gespeichert, die später analysiert oder verwendet werden, um eine bestimmte Reihe von Schritten beim Debuggen eines Problems zu wiederholen.
Sie können SQL Server Profiler für Aktivitäten wie die folgenden verwenden:
- Die Ursache des Problems finden
- Überwachung der Leistung von SQL Server zur Bewältigung der Arbeitslasten.
- Diagnose der langsamen Abfragen
- Erfassen einer Reihe von SQL-Anweisungen, die Probleme verursachen, um das Problem auf dem Testserver weiter zu replizieren, während das Problem debuggt wird.
- Es hilft auch beim Korrelieren von Leistungsindikatoren, um Probleme einfach zu debuggen.
F8. Wie lautet der TCP/IP-Port, auf dem SQL Server ausgeführt wird?
Der TCP/IP-Port, auf dem SQL Server ausgeführt wird, ist 1433.
F9. Was sind Unterabfragen in SQL Server? Erklären Sie seine Eigenschaften.
Eine Unterabfrage ist eine Abfrage innerhalb einer anderen Abfrage, in der eine Abfrage definiert ist, um Daten oder Informationen aus der Datenbank abzurufen. In einer Unterabfrage wird die äußere Abfrage als Hauptabfrage bezeichnet, während die innere Abfrage als Unterabfrage bezeichnet wird. Unterabfragen werden immer zuerst ausgeführt und das Ergebnis der Unterabfrage an die Hauptabfrage weitergegeben. Es kann in eine SELECT-, UPDATE- oder jede andere Abfrage eingebettet werden. Eine Unterabfrage kann auch beliebige Vergleichsoperatoren wie>, Die Eigenschaften von Unterabfragen lauten wie folgt: Bei einer Cluster-Installation verwendet der SQL Server die verfügbare DLL-Verbindung und blockiert somit alle anderen Verbindungen zum Server. Wenn Sie in diesem Zustand versuchen, SQL Server-Agent-Ressourcen online zu schalten, kann ein Failover von SQL-Ressourcen auf einen anderen Knoten erfolgen, da sie für eine Gruppe konfiguriert werden könnten. Um also einen Einzelbenutzermodus in einer Cluster-Installation zu starten, können Sie die folgenden Schritte ausführen: Die Replikation in Microsoft SQL Server ist ein Prozess zum Synchronisieren der Daten über mehrere Server. Dies erfolgt im Allgemeinen durch einen Replikatsatz, und diese Sätze bieten mehrere Kopien von Daten mit Redundanz und hoher Verfügbarkeit auf verschiedenen Servern. Nicht nur das, sondern die Replikation bietet einen Mechanismus zur Wiederherstellung nach Ausfällen. Es entfernt auch Abhängigkeiten von einzelnen Servern, um den Verlust von Daten von einem einzelnen Server zu verhindern. Folgend sind drei Arten von Replikationen in SQL Server: Bietet eine einfache und einfache Syntax. Besteht aus einer komplexen und vergleichsweise effizienteren Syntax. Verwendet Transact SQL oder T-SQL. Verwendet PL/SQL Unterstützt keine Abfrageoptimierung. Verwendet Sternabfrageoptimierung. Rollbacks sind im Transaktionsprozess nicht zulässig. Rollbacks sind während des Transaktionsprozesses zulässig. Ermöglicht inkrementelle, teilweise und vollständige Sicherungen Ermöglicht inkrementelle , vollständige, dateibasierte und differenzielle Sicherungen. Unterstützt kein Clustering. Bietet Unterstützung für Cluster-Konfiguration. Anweisungen wie INSERT, UPDATE, DELETE werden seriell ausgeführt. Anweisungen wie INSERT, UPDATE, DELETE, MERGE werden parallel ausgeführt. Jobs werden über den SQL Server Agent geplant Aufträge werden über Oracle Scheduler oder OEM geplant Microsoft SQL Server verwendet immer dann eine Sperrhierarchie, wenn die Daten gelesen oder etwas in den Daten geändert wird. Immer wenn eine Zeile gelesen wird, erwirbt SQL Server eine gemeinsame Sperre. Ebenso erwirbt SQL Server eine exklusive Sperre, sobald wir eine Zeile ändern. Diese Sperren sind nicht miteinander kompatibel. Die INTENT-Sperren werden also verwendet, um auf einer höheren Ebene anzuzeigen, welche Sperren innerhalb einer Sperrhierarchie angewendet werden. Es gibt hauptsächlich drei Arten von INTENT-Sperren:
Die Schritte, die Sie befolgen müssen, um SQL Server-Instanzen auszublenden, lauten wie folgt:
Die Datenqualitätsdienste in SQL Server sind ein wissensbasiertes Datenqualitätsprodukt. SQL Server Data Quality Services (DQS) ermöglichen es dem Benutzer, eine Wissensdatenbank aufzubauen und diese anschließend zur Durchführung von Aufgaben wie Korrektur, Deduplizierung, Anreicherung und Standardisierung von Daten zu verwenden. Außerdem bietet DQS auch Profiling und ermöglicht Ihnen die Datenbereinigung mit Hilfe von Cloud-basierten Datendiensten. DQS besteht aus zwei Komponenten: Magic Tables sind automatisch erstellte Tabellen in SQL Server, die verwendet werden, um die eingefügten, aktualisierten Werte für DML-Operationen wie (SELECT, DELETE, INSERT, UPDATE usw.) intern zu speichern. Change Data Capture oder am häufigsten bekannt als CDC wird verwendet, um INSERT-, UPDATE-, DELETE-Aktivitäten aufzuzeichnen, die auf die Tabellen angewendet werden. Wie der Name schon sagt, wird Change Data Capture verwendet, um die Daten zu erfassen, die kürzlich geändert wurden. Die zum Anwenden der Änderungen auf die Zielumgebung erforderlichen Spalteninformationen und Metadaten werden für die geänderten Zeilen erfasst und schließlich in den Änderungstabellen gespeichert. Diese Änderungstabellen sind das Spiegelbild der ursprünglichen Spaltenstruktur. Trigger werden verwendet, um Stapel von SQL-Code auszuführen, wenn INSERT-, DELETE- oder UPDATE-Befehle für eine Tabelle ausgeführt werden. Trigger werden also grundsätzlich automatisch ausgeführt, wenn die Daten basierend auf den Datenmanipulationsvorgängen geändert werden.
Die verschiedenen Arten von Triggern sind wie folgt: Eine rekursive gespeicherte Prozedur ist eine Problemlösungsmethode, durch die Sie immer wieder zur Lösung gelangen können. Der Prozess der Automatisierung der Sicherung zum Wiederherstellen von Datenbanken von einem eigenständigen Server auf einem anderen eigenständigen Standby-Server wird als Protokollversand bezeichnet. Log Shipping kann man auch als eine der Disaster-Recovery-Lösungen verstehen, da es dafür sorgt, dass auch bei Ausfall eines Servers der Standby-Server über die gleichen Daten verfügt wie der Server selbst.
Die Vorteile des Protokollversands sind wie folgt: Diese Flags werden verwendet, um das Serververhalten zu ändern oder Servereigenschaften festzulegen. Einige allgemeine Trace-Flags, die mit SQL Server verwendet werden, lauten wie folgt Wird verwendet, um einen bestimmten Teil der Zeichenfolge in einer bestimmten Zeichenfolge zurückzugeben Wird verwendet, um eine Zeichenposition in einer bestimmten angegebenen Zeichenfolge zurückzugeben Beispiel: SUBSTRING(‘Edureka’,1,4) Ausgabe: Edur Beispiel: CHARINDEX(‘r’,’Edureka’,1) Ausgabe: 4 Analysis Services in Microsoft SQL Server ist eine analytische Daten-Engine, die in der Geschäftsanalyse und Entscheidungsunterstützung verwendet wird. Dieser Dienst bietet semantische Modelle der Enterprise-Klasse für Clientanwendungen und Berichte wie Power BI, Microsoft Excel und andere Visualisierungstools. Die Analysis Services sind auf Plattformen wie : Mirroring in SQL Server dient dazu, einen Hot-Standby-Server zu verwalten, der hinsichtlich einer Transaktion mit dem primären Server konsistent ist. Außerdem werden die Transaktionsprotokolldatensätze vom Prinzipalserver an den sekundären Server gesendet. Im Folgenden sind die Vorteile der Spiegelung aufgeführt: SQL Server-basierte Cursor werden verwendet, wenn Sie jederzeit an einem Datensatz arbeiten möchten, anstatt alle Daten aus einer Tabelle als Masse zu entnehmen. Cursor werden jedoch nicht bevorzugt verwendet, wenn große Datenmengen vorhanden sind, da dies die Leistung beeinträchtigt. In einem Szenario, in dem es nicht möglich ist, Cursor zu vermeiden, versuchen Sie, die Anzahl der zu verarbeitenden Datensätze zu reduzieren, indem Sie eine temporäre Tabelle verwenden, und bauen Sie dann schließlich den Cursor daraus auf. Das physische und logische Design spielt eine wichtige Rolle bei der Leistung von SQL Server-basierten Anwendungen. Wir müssen sicherstellen, dass die richtigen Daten in den richtigen Tabellen erfasst werden, die Datenelemente richtige Beziehungen zueinander haben und die Datenredundanz reduziert wird. Ich würde auch vorschlagen, dass Sie beim Entwerfen einer Datenbank sicherstellen, dass es sich um einen iterativen Prozess handelt, um alle erforderlichen Systemziele zu erreichen, und dass er unter ständiger Beobachtung steht. Sobald das Datenbankdesign festgelegt ist, ist es sehr schwierig, das Design entsprechend den Anforderungen zu ändern. Sie können nur neue Beziehungen und Datenelemente hinzufügen. F27. Was verstehen Sie unter einer benutzerdefinierten Funktion in SQL Server und erklären Sie die Schritte zum Erstellen und Ausführen einer benutzerdefinierten Funktion in SQL Server? Eine benutzerdefinierte Funktion ist eine Funktion, die gemäß den Bedürfnissen des Benutzers durch Implementieren von Logik geschrieben wurde. Bei dieser Art von Funktionen ist der Benutzer nicht auf vordefinierte Funktionen beschränkt und vereinfacht den komplexen Code vordefinierter Funktionen durch Schreiben von einfachem Code. Diese Funktion gibt einen Skalarwert oder eine Tabelle zurück. Um eine benutzerdefinierte Funktion zu erstellen, siehe folgendes Beispiel:
Um die oben erstellte Funktion auszuführen, verwenden Sie den folgenden Befehl: Ein Entwickler muss die Art der gespeicherten Informationen, das Datenvolumen und die Daten überprüfen auf die zugegriffen wird. In einem Szenario, in dem Sie ein vorhandenes System aktualisieren, sollten Sie die vorhandenen Daten analysieren, vorhandene Datenmengen auftreten und die Methode überprüfen, über die auf die Daten zugegriffen wird, um Ihnen zu helfen die Problembereiche für das Design verstehen. In einem Szenario, in dem Sie ein neues System verwenden, müssen Sie die Informationen darüber aufbewahren, welche Daten erfasst werden, was die Datenbestandteile sind und in welcher Beziehung sie stehen die Datenelemente. Eine Beziehung in DBMS ist das Szenario, in dem zwei Entitäten miteinander in Beziehung stehen. In einem solchen Szenario verweist die aus Fremdschlüsseln bestehende Tabelle auf den Primärschlüssel der anderen Tabelle. Die verschiedenen Arten von Beziehungen in DBMS sind wie folgt:
Eine JOIN-Klausel wird verwendet, um Zeilen aus zwei oder mehr Tabellen zu kombinieren, basierend auf einer verwandten Spalte zwischen ihnen. Es wird verwendet, um zwei Tabellen zusammenzuführen oder Daten von dort abzurufen. Es gibt 4 Joins in SQL, nämlich: Der Befehl DBCC CHECKDB wird verwendet, um die physische und logische Integrität aller Objekte in der erwähnten Datenbank zu prüfen. Dazu führt es die folgenden Operationen aus: Sie müssen also nur den Befehl DBCC CHECKDB ausführen, und automatisch werden die Befehle DBCC CHECKALLOC, DBCC CHECKTABLE oder DBCC CHECKCATALOG ausgeführt. Beachten Sie außerdem, dass DBCC auf Datenbanken unterstützt wird, die speicheroptimierte Tabellen enthalten, aber keine Reparaturoptionen bieten. Das bedeutet, dass Sie Datenbanken regelmäßig sichern und diese Sicherungen testen müssen. Die CHECK-Einschränkung in SQL Server wird verwendet, um die in einer Spalte gespeicherten Werte oder Datentypen einzuschränken. Sobald Sie die CHECK-Einschränkung auf eine einzelne Spalte angewendet haben, können Sie fortfahren und bestimmte Werte für diese bestimmte Spalte anwenden. Diese Funktion wird verwendet, um den ersten Nicht-Null-Ausdruck innerhalb von Argumenten zurückzugeben. Der COALESCE-Befehl wird verwendet, um einen Nicht-Null-Wert aus mehr als einer einzelnen Spalte in Argumenten zurückzugeben. Die FLOOR-Funktion wird verwendet, um einen nicht ganzzahligen Wert auf den vorherigen kleinsten ganzzahligen Wert aufzurunden. Diese Funktion gibt nach dem Runden der Ziffern einen eindeutigen Wert zurück.
Syntax:
Beispiel: Um Sperren in der Datenbank zu überprüfen, können Sie die eingebaute gespeicherte Prozedur sp_lock. verwenden
Verwenden Sie den folgenden Befehl, um alle derzeit in einer Instanz der Datenbank-Engine gehaltenen Sperren aufzulisten:
Es gibt drei Möglichkeiten, die Anzahl der Datensätze in der Tabelle zu zählen:
Diese Funktion wird verwendet, um zu bestimmen, ob die genannte Zahl null, positiv oder negativ ist. Es wird also entweder 0, +1, -1 zurückgeben.
Um den ersten Wochentag des Monats zu finden, können Sie eine Abfrage wie folgt schreiben: Um eine Datenbank umzubenennen, müssen Sie den Befehl sp_renamedb wie folgt verwenden:
Um den fünfthöchsten gezahlten Betrag aus der Kundentabelle zu finden, können Sie eine Abfrage wie folgt schreiben:
To delete a table in SQL Server, use the Delete command. With REPEATABLE_READ and SERIALIZABLE isolation levels, locks are held during the transaction. But, if you consider READ_COMMITTED, then locks are held for isolation level.
Hinweis: Whenever GROUP BY is not used, HAVING behaves like a WHERE clause. Integration services is a platform offered by Microsoft to build enterprise-level data transformation solutions and integration. These services solve complex business problems by loading data warehouses, perform data wrangling, copy or download files, and manage SQL Server objects. Also, integration services can extract and transform data from a wide variety of sources such as relational data sources, XML data files, load the data into more than a single database. So, basically, you can use the integration services to create solutions without coding, code complex tasks, program the extensive integration object model to create packages. The integration services include good set of built-in tasks and transformations, graphical tools used for building packages and also contain the Catalog database to store, run and manage packages.
Hotfixes are single, cumulative software packages applied to live systems. This includes one or more files used to address a problem in a software product. Patches are a programs installed on the machines to rectify the problem occurred in the system and ensured the security of the system. So, basically hotfixes are a kind of patch offered by Microsoft SQL Server to address specific issues. These are few encryption mechanisms in SQL Server to encrypt data in the database:
The READ_COMMITED_SNAPSHOT option and the ALLOW_SNAPSHOT_ISOLATION option must be set to allow the usage of optimistic models.
The common performance issues in SQL Server are as follows: So this brings us to the end of the SQL Server Interview Questions article. I hope this set of SQL Server Interview Questions will help you ace your job interview. All the best for your interview! Check out this MySQL-DBA-Zertifizierungsschulung by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. This course trains you on the core concepts &advanced tools and techniques to manage data and administer the MySQL Database. It includes hands-on learning on concepts like MySQL Workbench, MySQL Server, Data Modeling, MySQL Connector, Database Design, MySQL Command line, MySQL Functions, etc. End of the training you will be able to create and administer your own MySQL Database and manage data. Haben Sie eine Frage an uns? Please mention it in the comments section of this “SQL Server Interview Questions” article and we will get back to you as soon as possible.
F10. Wie starten Sie den Einzelbenutzermodus in Clustered Installationen?
net start MSSQLSERVER /m. SQLCMD -E -S<servername>. F11. Was versteht man unter Replikation in SQL Server? Nennen Sie die verschiedenen Replikationstypen in SQL Server.
F12. Was sind die Unterschiede zwischen MS SQL Server und Oracle?
MS SQL Server Oracle F13. Was verstehen Sie unter INTENT-Sperren?
F14. Welche Schritte müssen Sie befolgen, um SQL Server-Instanzen auszublenden?

F15. Was verstehen Sie unter den Datenqualitätsdiensten in SQL Server?
F16. Erklären Sie Magic Tables in SQL Server
F17. Was verstehen Sie unter Datenerfassung ändern ?
F18. Was verstehen Sie unter Triggern und nennen Sie die verschiedenen Arten davon?
F19. Was verstehen Sie unter rekursiver gespeicherter Prozedur?
F20. Erklären Sie den Protokollversand und nennen Sie seine Vorteile.
F21. Was sind Trace-Flags und einige gängige Trace-Flags erwähnen, die mit SQL Server verwendet werden?
F22. Erwähnen Sie die Unterschiede zwischen SUBSTR und CHARINDEX in SQL Server.
SUBSTR CHARINDEX F23. Was verstehen Sie unter Analysis Services in SQL Server?
F24. Was verstehen Sie unter Spiegelung und nennen Sie die Vorteile der Spiegelung?
F25. Wann sollte ein Entwickler Ihrer Meinung nach SQL Server-basierte Cursor verwenden?
F26. Welche Rolle spielt das Datenbankdesign bei der Leistung einer SQL Server-basierten Anwendung?
CREATE FUNCTION samplefunc(@num INT)
RETURNS TABLE
AS
RETURN SELECT * FROM customers WHERE CustId=@num
SELECT * FROM samplefunc(10)
F28. Wie können Sie sicherstellen, dass die Datenbank und die SQL Server-basierte Anwendung gut funktionieren?
F29. Was sind Beziehungen und erwähnen Sie verschiedene Arten von Beziehungen im DBMS
F30. Was sind Verknüpfungen in SQL und welche unterschiedlichen Arten von Verknüpfungen gibt es?
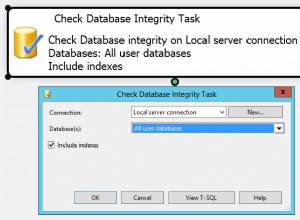
F31. Wofür wird der Befehl DBCC CHECKDB verwendet?
F32. Was verstehen Sie unter CHECK-Einschränkung in SQL Server?
Beispiel:
CREATE TABLE Customer (
Cust_ID int NOT NULL,
FirstName varchar(255),
Age int,
City varchar(255),
CONSTRAINT CHK_Customer CHECK (Age>20 AND City= 'Hyderabad')
);
F33. Was tun verstehen Sie unter COALESCE in SQL Server?
Beispiel:
SELECT COALESCE(CustID, CustName, Amount) from Customers;
F34. Erläutern Sie die Verwendung der FLOOR-Funktion in SQL Server.
FLOOR(expression)
FLOOR(7.3)
F35. Welcher Befehl wird zum Überprüfen von Sperren in Microsoft SQL Server verwendet?
Syntax
sp_lock [ [ @spid1 = ] 'session ID1' ] [ , [@spid2 = ] 'session ID2' ]
[ ; ]
Beispiel:
USE SampleDB;
GO
EXEC sp_lock;
GO
F36. Nennen Sie die 3 Möglichkeiten, die Anzahl der Datensätze in einer Tabelle zu ermitteln.
SELECT * FROM TableName;
SELECT COUNT(*) FROM TableName;
SELECT rows FROM indexes WHERE id = OBJECT_ID(TableName) AND indexid< 2;
F37. Wozu dient die SIGN-Funktion?
Syntax:
SIGN(number)
Beispiel:
SIGN (0) returns 0
SIGN (21) returns 1
SIGN (-21) returns -1
F38. Schreiben Sie eine SQL-Abfrage, um den ersten Wochentag des Monats zu finden?
SELECT DATENAME(dw, DATEADD(dd, – DATEPART(dd, GETDATE()) + 1, GETDATE())) AS FirstDay;
F39. Erwähnen Sie den Befehl zum Umbenennen der Datenbank.
sp_renamedb 'OldDatabaseName', 'NewDatabaseName';
F40. Schreiben Sie eine Abfrage, um den fünfthöchsten bezahlten Betrag aus der Kundentabelle zu finden.
SELECT TOP 1 amount FROM (SELECT DISTINCT TOP 5 amount FROM customers ORDER BY amount DESC) ORDER BY amount;
Q41. How can we delete a table in SQL Server?
Syntax:
DELETE TableName
Beispiel:
DELETE Customers;
Q42. What is the purpose of UPDATE STATISTICS and SCOPE_IDENTITY() function ?
Q43. What do you understand by PHYSICAL_ONLY option in DBCC CHECKDB?
Q44. Can you explain how long are locks retained within the REPEATABLE_READ and SERIALIZABLE isolation levels, during a read operation with row-level locking?
Q45. Mention the differences between HAVING and WHERE clause.
HAVING WHERE Used only with SELECT statement Used in a GROUP BY clause Used with the GROUP BY function in a query Applied to each row before they are a part of the GROUP BY function in a query Q46. What do you understand by integration services in SQL Server?
Q47. What do you understand by Hotfixes and Patches in SQL Server?
Q48. Can you name a few encryption mechanisms in SQL server?
Q49. What are the options which must be set to allow the usage of optimistic models?
Q50. What are the common performance issues in SQL Server?