Es gibt kein relevantes fest codiertes Limit (65.536 * Netzwerkpaketgröße von 4 KB ist 268 MB und Ihre Skriptlänge ist bei weitem nicht so lang), obwohl es nicht ratsam ist, diese Methode für eine große Anzahl von Zeilen zu verwenden.
Der Fehler, den Sie sehen, wird von den Clienttools und nicht von SQL Server ausgelöst. Wenn Sie den SQL-String dynamisch aufbauen, kann die SQL-Kompilierung zumindest erfolgreich gestartet werden
DECLARE @SQL NVARCHAR(MAX) = '(100,200,300),
';
SELECT @SQL = 'SELECT * FROM (VALUES ' + REPLICATE(@SQL, 1000000) + '
(100,200,300)) tc (proj_d, period_sid, val)';
SELECT @SQL AS [processing-instruction(x)]
FOR XML PATH('')
SELECT DATALENGTH(@SQL) / 1048576.0 AS [Length in MB] --30.517705917
EXEC(@SQL);
Obwohl ich das obige nach ~ 30 Minuten Kompilierzeit beendet habe und es immer noch keinen Streit produziert hatte. Die Literalwerte müssen im Plan selbst als Tabelle mit Konstanten gespeichert werden, und SQL Server gibt viel Zeit versuchen, auch Eigenschaften über sie abzuleiten.
SSMS ist eine 32-Bit-Anwendung und wirft einen std::bad_alloc Ausnahme beim Analysieren des Stapels
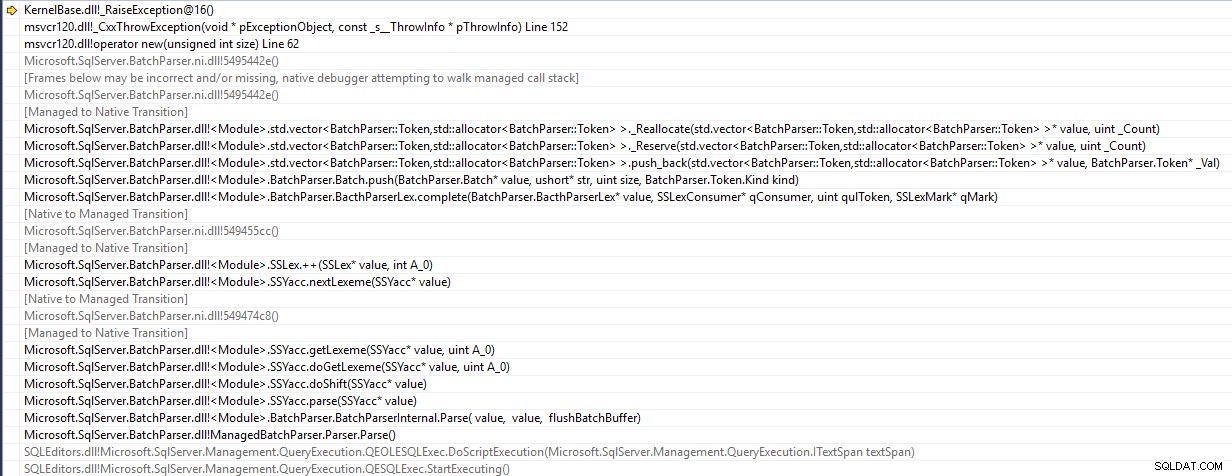
Es versucht, ein Element auf einen Token-Vektor zu schieben, der die Kapazität erreicht hat, und sein Versuch, die Größe zu ändern, schlägt fehl, da kein ausreichend großer zusammenhängender Speicherbereich verfügbar ist. Die Aussage gelangt also nicht einmal bis zum Server.
Die Vektorkapazität wächst jedes Mal um 50 % (d. h. nach der Sequenz hier ). ). Die Kapazität, auf die der Vektor anwachsen muss, hängt davon ab, wie der Code angelegt ist.
Die folgenden müssen von einer Kapazität von 19 auf 28 wachsen.
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
und das Folgende braucht nur eine Größe von 2
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
Folgendes benötigt eine Kapazität von> 63 und <=94.
SELECT *
FROM (VALUES
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300)
) tc (proj_d, period_sid, val)
Für eine Million Zeilen, die wie in Fall 1 ausgelegt sind, muss die Vektorkapazität auf 3.543.306 anwachsen.
Möglicherweise stellen Sie fest, dass eine der folgenden Methoden das Parsen auf Clientseite erfolgreich durchführen lässt.
- Reduzieren Sie die Anzahl der Zeilenumbrüche.
- Neustart von SSMS in der Hoffnung, dass die Anforderung für großen zusammenhängenden Speicher erfolgreich ist, wenn weniger Adressraumfragmentierung vorliegt.
Aber selbst wenn Sie es erfolgreich an den Server senden, wird es den Server sowieso nur während der Generierung des Ausführungsplans beenden, wie oben beschrieben.
Sie werden viel besser dran sein, den Import-Export-Assistenten zu verwenden, um die Tabelle zu laden. Wenn Sie dies in TSQL tun müssen, werden Sie feststellen, dass die Aufteilung in kleinere Stapel und/oder die Verwendung einer anderen Methode wie das Zerkleinern von XML eine bessere Leistung als Tabellenwertkonstruktoren erbringt. Das Folgende wird beispielsweise auf meinem Computer in 13 Sekunden ausgeführt (obwohl Sie bei Verwendung von SSMS wahrscheinlich immer noch in mehrere Stapel aufteilen müssten, anstatt ein massives XML-String-Literal einzufügen).
DECLARE @S NVARCHAR(MAX) = '<x proj_d="100" period_sid="200" val="300" />
' ;
DECLARE @Xml XML = REPLICATE(@S,1000000);
SELECT
x.value('@proj_d','int'),
x.value('@period_sid','int'),
x.value('@val','int')
FROM @Xml.nodes('/x') c(x)