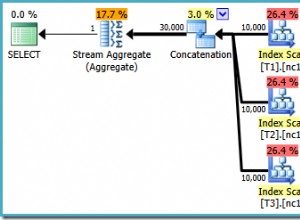
Netzwerk
Zunächst einmal seit der Verwendung von rowid und rownum ohnehin herstellergebunden ist, sollten Sie in Betracht ziehen, in der Datenbank gespeicherte Routinen zu verwenden. Es könnte den Aufwand für die Übertragung von Daten von der Datenbank zum Anwendungsserver erheblich reduzieren (insbesondere wenn sie sich auf verschiedenen Computern befinden und über das Netzwerk verbunden sind).
Wenn man bedenkt, dass Sie 80 Millionen Datensätze zu übertragen haben, könnte dies der beste Leistungsschub für Sie sein, obwohl es von der Art der Arbeit abhängt, die Ihre Threads erledigen.
Offensichtlich würde eine Erhöhung der Bandbreite auch helfen, Netzwerkprobleme zu lösen.
Festplattenleistung
Bevor Sie Änderungen am Code vornehmen, überprüfen Sie die Festplattenauslastung, während Tasks ausgeführt werden, vielleicht kann sie einfach nicht so viel I/O verarbeiten (10 Threads lesen gleichzeitig).
Die Migration auf SSD/RAID oder eine Clustering-Datenbank könnte das Problem lösen. Während Sie die Art und Weise ändern, wie Sie auf die Datenbank zugreifen, wird dies in diesem Fall nicht der Fall sein.
Multithreading könnte CPU-Probleme lösen, aber Datenbanken hängen hauptsächlich vom Festplattensystem ab.
Rownum
Es gibt ein paar Probleme, auf die Sie stoßen könnten, wenn Sie es mit rowid und rownum implementieren.
1) rownum wird spontan für die Ergebnisse jeder Abfrage generiert. Wenn die Abfrage also keine explizite Sortierung hat und es möglich ist, dass einige Datensätze bei jeder Abfrage eine andere Zeilennummer haben.
Wenn Sie es beispielsweise zum ersten Mal ausführen, erhalten Sie folgende Ergebnisse:
some_column | rownum
____________|________
A | 1
B | 2
C | 3
dann führen Sie es ein zweites Mal aus, da Sie keine explizite Sortierung haben, entscheidet dbms (aus irgendeinem Grund, der sich selbst bekannt ist), Ergebnisse wie diese zurückzugeben:
some_column | rownum
____________|________
C | 1
A | 2
B | 3
2) Punkt 1 impliziert auch, dass Sie Ergebnisse nach rownum filtern es wird eine temporäre Tabelle mit ALL generiert Ergebnisse und filtern Sie sie dann
Also rownum ist keine gute Wahl zum Aufteilen von Ergebnissen. Während rowid schien besser, es hat auch einige Probleme.
Reihe
Wenn Sie sich die ROWID-Beschreibung ansehen Möglicherweise stellen Sie fest, dass der „rowid-Wert“ eine Zeile in der Datenbank eindeutig identifiziert ".
Aus diesem Grund und aufgrund der Tatsache, dass Sie beim Löschen einer Zeile ein "Loch" in der Zeilen-ID-Sequenz haben, werden die Zeilen-IDs möglicherweise nicht gleichmäßig auf die Tabellendatensätze verteilt.
Wenn Sie also beispielsweise drei Threads haben und jeder 1.000.000 Zeilen-IDs abruft, ist es möglich, dass einer 1.000.000 Datensätze erhält und die anderen beiden jeweils 1 Datensatz. So wird einer überfordert, während zwei andere hungern .
In Ihrem Fall ist dies möglicherweise keine große Sache, obwohl es sehr wohl das Problem sein könnte, mit dem Sie derzeit mit dem Primärschlüsselmuster konfrontiert sind.
Oder wenn Sie zuerst alle Rowids im Dispatcher abrufen und sie dann gleichmäßig aufteilen (wie von peter.petrov vorgeschlagen), könnte dies funktionieren, obwohl das Abrufen von 80 Millionen IDs immer noch nach viel klingt. Ich denke, es wäre besser, die Aufteilung mit einem durchzuführen SQL-Abfrage, die Grenzen von Chunks zurückgibt.
Oder Sie könnten dieses Problem lösen, indem Sie eine geringe Anzahl von Rowids pro Aufgabe angeben und das Fork-Join-Framework verwenden, das in Java 7 eingeführt wurde, jedoch sollte sein verwendet sorgfältig .
Auch ein offensichtlicher Punkt:Sowohl rownum als auch rowid sind nicht über Datenbanken hinweg portierbar.
Es ist also viel besser, eine eigene "Sharding"-Spalte zu haben, aber dann müssen Sie selbst dafür sorgen, dass sie Datensätze in mehr oder weniger gleiche Stücke aufteilt.
Denken Sie auch daran, dass es wichtig ist, zu überprüfen, was die Sperrmodus-Datenbank verwendet, wenn Sie dies in mehreren Threads tun , vielleicht sperrt es nur die Tabelle für jeden Zugriff, dann ist Multithreading sinnlos.
Wie andere vorgeschlagen haben, sollten Sie zuerst herausfinden, was der Hauptgrund für die geringe Leistung ist (Netzwerk, Festplatte, Datenbanksperrung, Thread-Hunger oder vielleicht haben Sie nur suboptimale Abfragen - überprüfen Sie die Abfragepläne).