Moderne Apps wie Microservices erfordern normalerweise viele Datenbankverbindungen, sie verwenden diese Verbindungen auch sehr schnell und geben sie frei. Als PostgreSQL vor fast 25 Jahren entwickelt wurde, beschlossen seine Entwickler, keine Threads für neue Anfragen zu verwenden, sondern stattdessen für jede Anfrage einen neuen Prozess zu erstellen. Während diese Entscheidung damals wahrscheinlich sinnvoll war, können viele Verbindungen heute ein ernstes Problem darstellen. Eine der Lösungen für dieses Problem ist ein Verbindungspool. In diesem Blogbeitrag werden wir den PgBouncer-Verbindungspool und seine Verwendung in ClusterControl 1.8.2 diskutieren.
Warum Connection Pool verwenden
Nun, die kurze Antwort auf diese Frage lautet:Es ist eine einfache, aber effektive Lösung, um die Leistung Ihrer Apps zu verbessern und gleichzeitig die Last auf dem PostgreSQL-Server zu reduzieren. Lassen Sie uns ein wenig tiefer darauf eingehen, oder?
Ein Verbindungspool kann als Cache offener Datenbankverbindungen definiert werden, der von den Clients wiederverwendet werden kann. Mit anderen Worten, es verringert die Belastung der Datenbank, indem es die Anfragen bei jeder neuen Verbindung reduziert. Diese neuen Verbindungen werden grundsätzlich jedes Mal vom Postmaster-Prozess erzeugt, wenn eine Verbindung hergestellt wird, was üblicherweise etwa 2 bis 3 MB Speicher pro Verbindung benötigt.
Ohne Verbindungspool führt dies immer dann zu einem Problem, wenn die Anzahl der Verbindungen zu hoch ist, da der Postmaster viel Speicher bereitstellen muss. In PostgreSQL wird der Verbindungspool von PgBouncer verwaltet.
Was ist PgBouncer
PgBouncer ist ein leichter, Single-Binary-Open-Source- und wahrscheinlich der beliebteste Verbindungspooler für PostgreSQL. PgBouncer ist ein einfaches Dienstprogramm, das genau eine Sache macht, es sitzt zwischen der Datenbank und den Clients und spricht das PostgreSQL-Protokoll, indem es einen PostgreSQL-Server kopiert. Zum Zeitpunkt des Schreibens ist die neueste Version von PgBouncer 1.15.0.
Lassen Sie uns sehen, was einige der besten Funktionen sind, die es bietet, und wahrscheinlich der Grund, warum es in der PostgreSQL-Welt so beliebt ist:
-
Lightweight - nur ein einziger Prozess, alle Anfragen vom Client und Antworten vom Server passieren PgBouncer ohne zusätzliches Verarbeitung
-
Einfache Einrichtung – erfordert keine clientseitigen Codeänderungen und einen der am einfachsten einzurichtenden PostgreSQL-Verbindungspooler
-
Skalierbarkeit &Leistung – es lässt sich gut auf eine große Anzahl von Kunden skalieren und gleichzeitig die Transaktionen erheblich steigern pro Sekunde, die der PostgreSQL-Server unterstützen kann
Schritte zum Einrichten von PgBouncer mit ClusterControl
Es gibt ein paar Schritte, um PgBouncer mit ClusterControl zu installieren und zu konfigurieren. In diesem Abschnitt gehen wir die Schritte durch, vorausgesetzt, Sie haben den PostgreSQL-Cluster bereits bereitgestellt. Wenn Sie den Cluster noch nicht haben, können Sie der Anleitung in diesem Blogbeitrag folgen.
Von Ihrer Web-Benutzeroberfläche> PostgreSQL-Cluster auswählen> Verwalten> Load Balancer> Registerkarte PgBouncer auswählen und der folgende Screenshot wird angezeigt. Hier können Sie auswählen, ob Sie PgBouncer bereitstellen oder importieren möchten. In diesem Beispiel wählen wir Bereitstellen.:
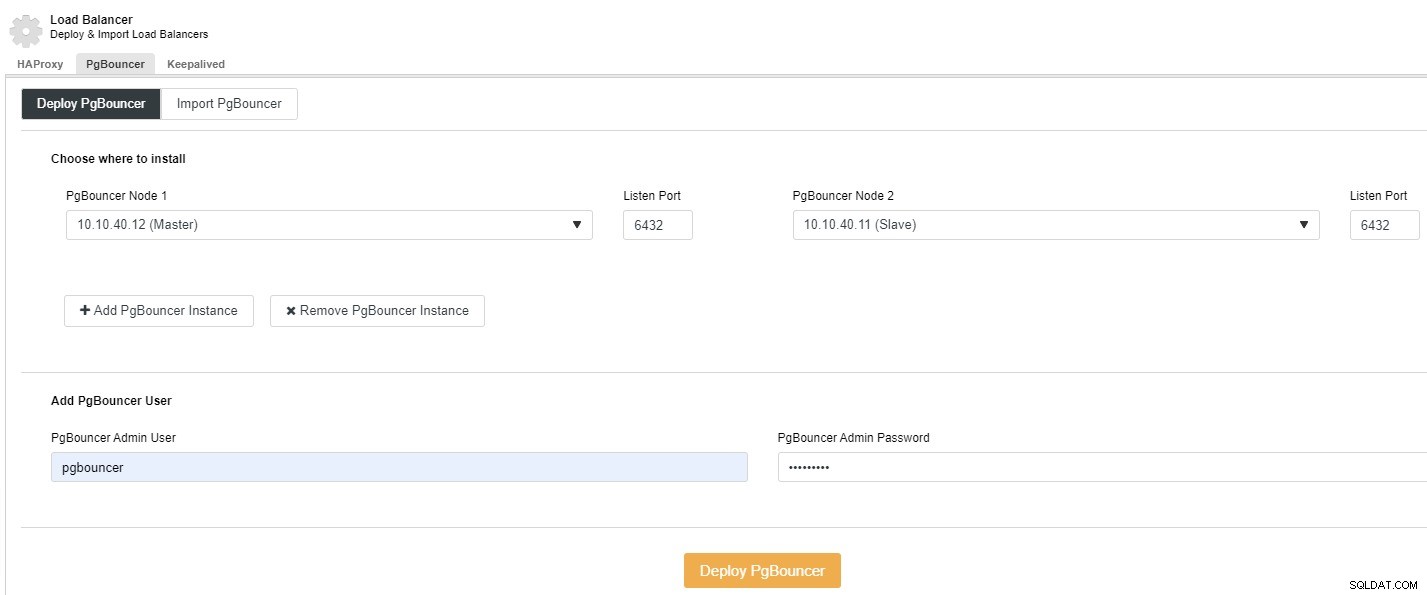
Sie können den Knoten aus der Dropdown-Liste auswählen, den Port angeben, ' PgBouncer Admin User“ sowie das Passwort und klicken Sie auf „PgBouncer bereitstellen“. Der Auftrag wird ausgeführt und der Status wird auf diesem Bildschirm angezeigt. Sie können ihn auch auf der Registerkarte „Aktivität“ überwachen.
Nachdem der PgBouncer-Knoten erfolgreich bereitgestellt wurde, besteht der nächste Schritt darin, den Verbindungspool zu erstellen. Von Ihrem Cluster> Knoten> PgBouncer-Knoten auswählen und der folgende Screenshot wird angezeigt:
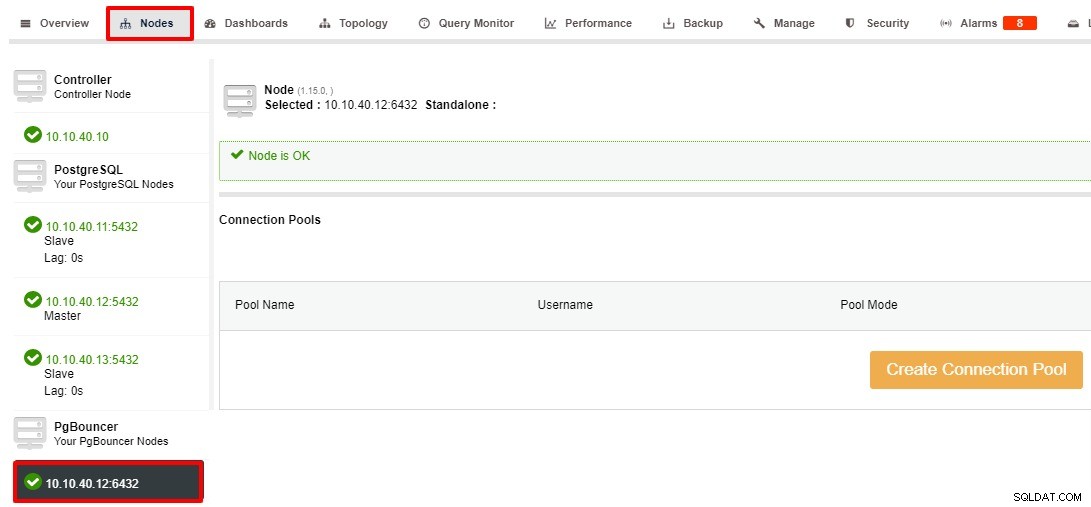
Der Verbindungsbildschirm wird angezeigt, sobald Sie auf „Verbindungspool erstellen“ klicken. Taste. Sie können alle Informationen eingeben und den Wert abhängig von Ihrer Einrichtung aktualisieren. Für dieses Beispiel verwenden wir den Standardwert für „Pool-Modus“, „Pool-Größe“ und „Max. Datenbankverbindung“:
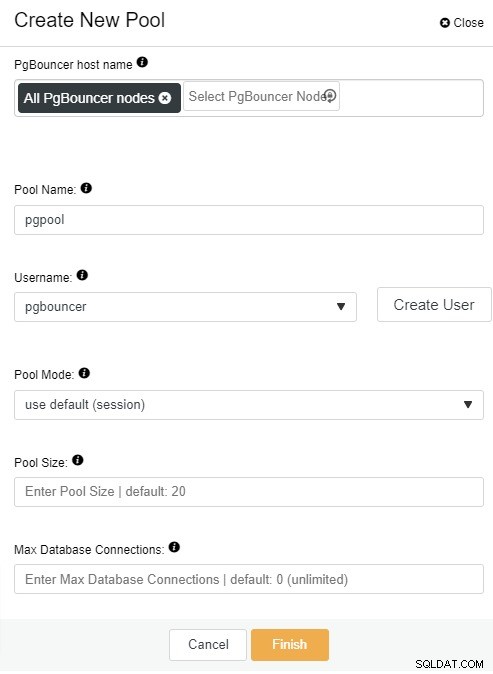
Hier müssen Sie die folgenden Informationen hinzufügen:
-
PgBouncer-Hostname:Wählen Sie die Knotenhosts aus, um den Verbindungspool zu erstellen.
-
Poolname:Pool- und Datenbanknamen müssen identisch sein.
-
Benutzername: Wählen Sie einen Benutzer aus dem PostgreSQL-Masterknoten aus oder erstellen Sie einen neuen.
-
Pool-Modus:Sitzungs- (Standard), Transaktions- oder Statement-Pooling.
-
Sitzung (Standard):Der Server wird wieder in den Pool freigegeben, nachdem der Client die Verbindung getrennt hat
-
transaktion:Der Server wird nach Abschluss der Transaktion wieder für den Pool freigegeben
-
Anweisung:Der Server wird nach Abschluss der Abfrage wieder für den Pool freigegeben. Transaktionen, die sich über mehrere Anweisungen erstrecken, sind in diesem Modus nicht zulässig
-
-
Pool-Größe:Maximale Größe der Pools für diese Datenbank. Der Standardwert ist 20.
-
Max Datenbankverbindungen:Konfigurieren Sie ein datenbankweites Maximum. Der Standardwert ist 0, was unbegrenzt bedeutet.
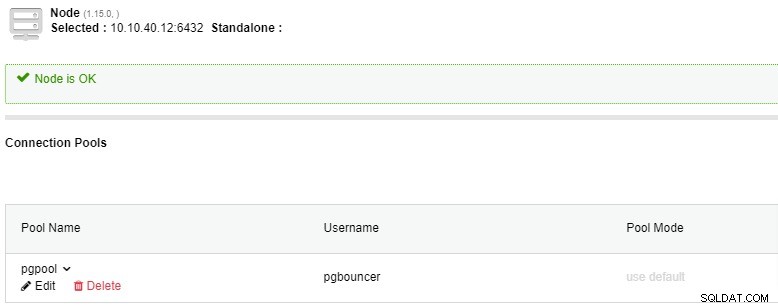
Der Verbindungspool erscheint, nachdem Sie auf die Schaltfläche „Fertig stellen“ geklickt haben, wie im Screenshot unten gezeigt, und sowohl PgBouncer als auch Verbindungspool sind jetzt bereit:
Fazit
Die Verwendung von Verbindungspool und PgBouncer sind einige der Schritte zur Verbesserung der Leistung Ihrer Anwendung, wenn es um Hochverfügbarkeit geht. Mit ClusterControl können Sie PgBouncer bereitstellen sowie einfach und schnell einen Verbindungspool erstellen.
Um es noch besser zu machen, empfehlen wir zusätzlich zu PgBouncer auch den Einsatz von HAProxy. Die HAProxy-Funktion ist in ClusterControl verfügbar und zum Zeitpunkt des Schreibens verwenden wir die Version 1.8.23.



