PostgreSQL, auch bekannt als die fortschrittlichste Open-Source-Datenbank der Welt, hat seit dem 24. September 2020 eine neue Release-Version, und jetzt ist sie ausgereift, wir können prüfen, was es Neues gibt, um darüber nachzudenken Migrationsplan. PostgreSQL 13 ist mit vielen neuen Funktionen und Verbesserungen verfügbar. In diesem Blog werden wir einige dieser neuen Funktionen erwähnen und sehen, wie Sie Ihre aktuelle PostgreSQL-Version bereitstellen oder aktualisieren.
Neue Funktionen und Verbesserungen von PostgreSQL 13
Beginnen wir damit, einige der neuen Funktionen und Verbesserungen dieser Version von PostgreSQL 13 zu erwähnen, die Sie in der offiziellen Dokumentation sehen können.
Partitionierung
-
Pruning von Partitionen und partitionsweisen Joins in mehr Fällen zulassen
-
Unterstützung von BEFORE-Triggern auf Zeilenebene für partitionierte Tabellen
-
Zulassen, dass partitionierte Tabellen logisch über die Veröffentlichung repliziert werden
-
Logische Replikation in partitionierte Tabellen auf Abonnenten zulassen
-
Zulassen, dass ganze Zeilenvariablen in Partitionierungsausdrücken verwendet werden
Indizes
-
Effizienteres Speichern von Duplikaten in B-Tree-Indizes
-
GiST- und SP-GiST-Indizes für Box-Spalten zulassen, um ORDER BY-Box <-> Punktabfragen zu unterstützen
-
GIN-Indizes effizienter handhaben ! (NOT)-Klauseln in tsquery-Suchen
-
Indexoperatorklassen erlauben, Parameter anzunehmen
Optimierer
-
Verbesserung der Selektivitätsschätzung des Optimierers für Containment/Match-Operatoren
-
Einstellung des Statistikziels für erweiterte Statistiken zulassen
-
Erlaubt die Verwendung mehrerer erweiterter Statistikobjekte in einer einzigen Abfrage
-
Erlaube die Verwendung erweiterter Statistikobjekte für OR-Klauseln und IN/ANY-Konstantenlisten
-
Zulassen, dass Funktionen in FROM-Klauseln hochgezogen (inlined) werden, wenn sie zu Konstanten ausgewertet werden
Leistung
-
Inkrementelles Sortieren implementieren und Leistung beim Sortieren von Inet-Werten verbessern
-
Hash-Aggregation erlauben, Festplattenspeicher für große Aggregationsergebnissätze zu verwenden
-
Ermöglichen Sie Einfügungen, nicht nur Aktualisierungen und Löschungen, um Bereinigungsaktivitäten im Autovacuum auszulösen
-
Maintenance_io_concurrency-Parameter hinzufügen, um E/A-Parallelität für Wartungsvorgänge zu steuern
-
Zulassen, dass WAL-Schreibvorgänge während einer Transaktion übersprungen werden, die eine Beziehung erstellt oder neu schreibt, wenn wal_level minimal ist
-
Verbessern Sie die Leistung beim Wiedergeben von DROP DATABASE-Befehlen, wenn viele Tablespaces verwendet werden
-
Beschleunigen Sie die Umwandlung von Ganzzahlen in Text
-
Reduzieren Sie die Speichernutzung für Abfragezeichenfolgen und Erweiterungsskripts, die viele SQL-Anweisungen enthalten
Überwachung
-
Erlaube EXPLAIN, auto_explain, autovacuum und pg_stat_statements, WAL-Nutzungsstatistiken zu verfolgen
-
Zulassen, dass statt aller Anweisungen eine Stichprobe von SQL-Anweisungen protokolliert wird
-
Fügen Sie den Backend-Typ zur csvlog- und optional log_line_prefix-Protokollausgabe hinzu
-
Verbesserte Kontrolle über die Parameterprotokollierung vorbereiteter Anweisungen
-
Fügen Sie leader_pid zu pg_stat_activity hinzu, um einen parallelen Worker-Leader-Prozess zu melden
-
Systemansicht pg_stat_progress_basebackup hinzufügen, um den Fortschritt von Streaming-Basissicherungen zu melden
-
Systemansicht pg_stat_progress_analyze hinzufügen, um ANALYZE-Fortschritt zu melden
-
Fügen Sie die Systemansicht pg_shmem_allocations hinzu, um die gemeinsame Speichernutzung anzuzeigen
Replikation und Wiederherstellung
-
Ändern der Streaming-Replikationskonfigurationseinstellungen durch Neuladen zulassen
-
WAL-Empfängern erlauben, einen temporären Replikationsslot zu verwenden, wenn kein permanenter angegeben ist
-
Zulassen, dass WAL-Speicher für Replikationsslots durch max_slot_wal_keep_size begrenzt wird
-
Zulassen, dass die Standby-Beförderung jede angeforderte Pause abbricht
-
Einen Fehler generieren, wenn die Wiederherstellung das angegebene Wiederherstellungsziel nicht erreicht
-
Ermöglichen Sie die Kontrolle darüber, wie viel Speicher durch logische Dekodierung verwendet wird, bevor er auf die Festplatte übertragen wird
-
Wiederherstellung fortsetzen, selbst wenn WAL auf ungültige Seiten verweist
Hilfsbefehle
-
Erlaube VACUUM, die Indizes einer Tabelle parallel zu verarbeiten
-
Bericht über die Verwendung des Planungszeitpuffers in der BUFFER-Ausgabe von EXPLAIN
-
Lassen Sie CREATE TABLE LIKE die Eigenschaft NO INHERIT einer CHECK-Einschränkung an die erstellte Tabelle weitergeben
-
Fügen Sie ALTER TABLE ... DROP EXPRESSION hinzu, um das Entfernen der Eigenschaft GENERATED aus einer Spalte zu ermöglichen
-
ALTER VIEW-Syntax hinzufügen, um Ansichtsspalten umzubenennen
-
Fügen Sie ALTER TYPE-Optionen hinzu, um die TOAST-Eigenschaften und Unterstützungsfunktionen eines Basistyps zu ändern
-
Option CREATE DATABASE LOCALE hinzufügen
-
Erlaube DROP DATABASE, Sitzungen mit der Zieldatenbank zu trennen, damit das Löschen erfolgreich ist
Und viele weitere Änderungen. Wir haben nur einige von ihnen erwähnt, um einen größeren Blogbeitrag zu vermeiden. Sehen wir uns nun an, wie diese neue Version bereitgestellt wird.
So stellen Sie PostgreSQL 13 bereit
Hierfür gehen wir davon aus, dass Sie ClusterControl installiert haben, andernfalls können Sie der entsprechenden Dokumentation folgen, um es zu installieren.
Um eine Bereitstellung von ClusterControl durchzuführen, wählen Sie einfach die Option Bereitstellen und folgen Sie den angezeigten Anweisungen.
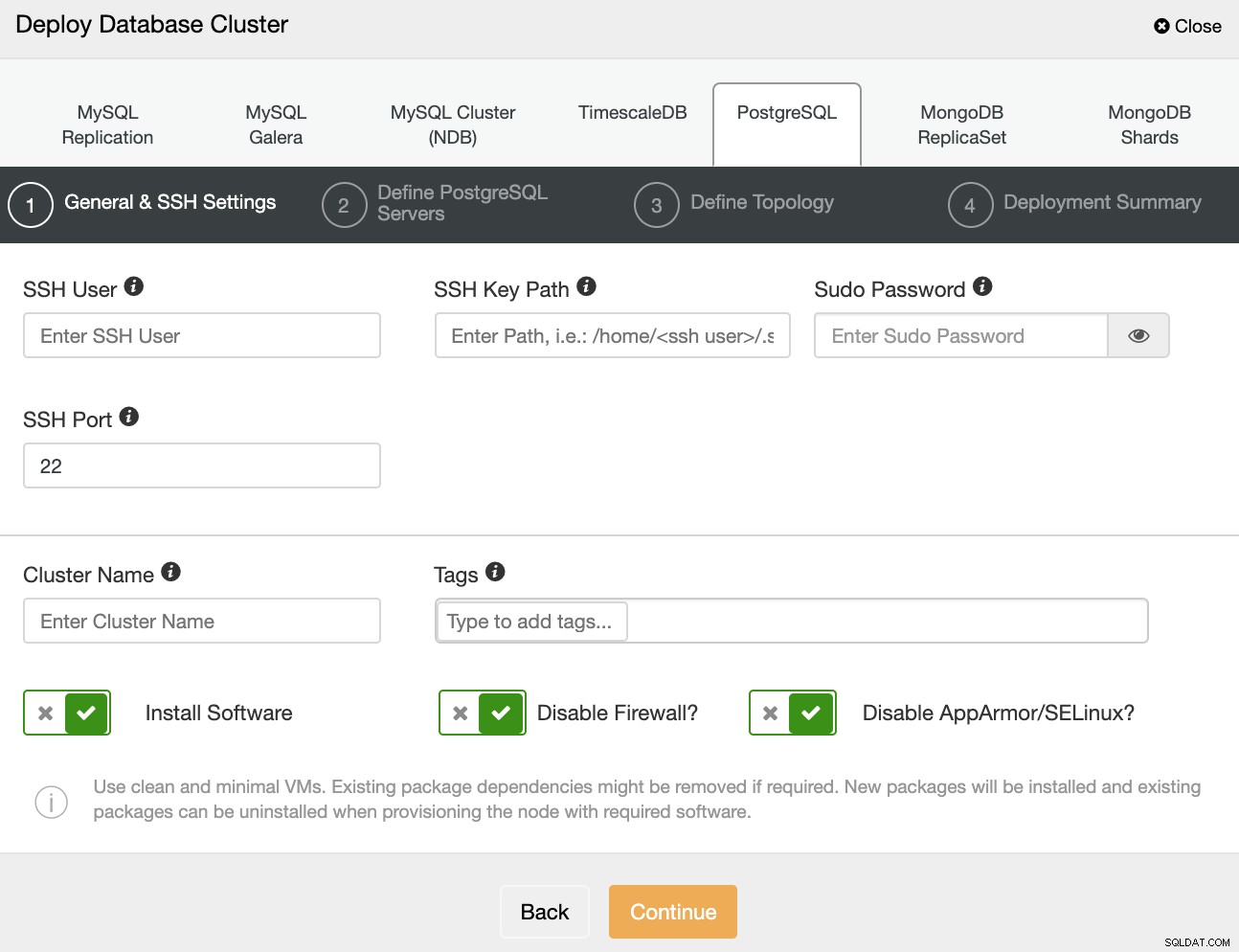
Bei der Auswahl von PostgreSQL müssen Sie Benutzer, Schlüssel oder Passwort und Port angeben um sich per SSH mit Ihren Servern zu verbinden. Sie können auch einen Namen für Ihren neuen Cluster hinzufügen und wenn Sie möchten, dass ClusterControl die entsprechende Software und Konfigurationen für Sie installiert.
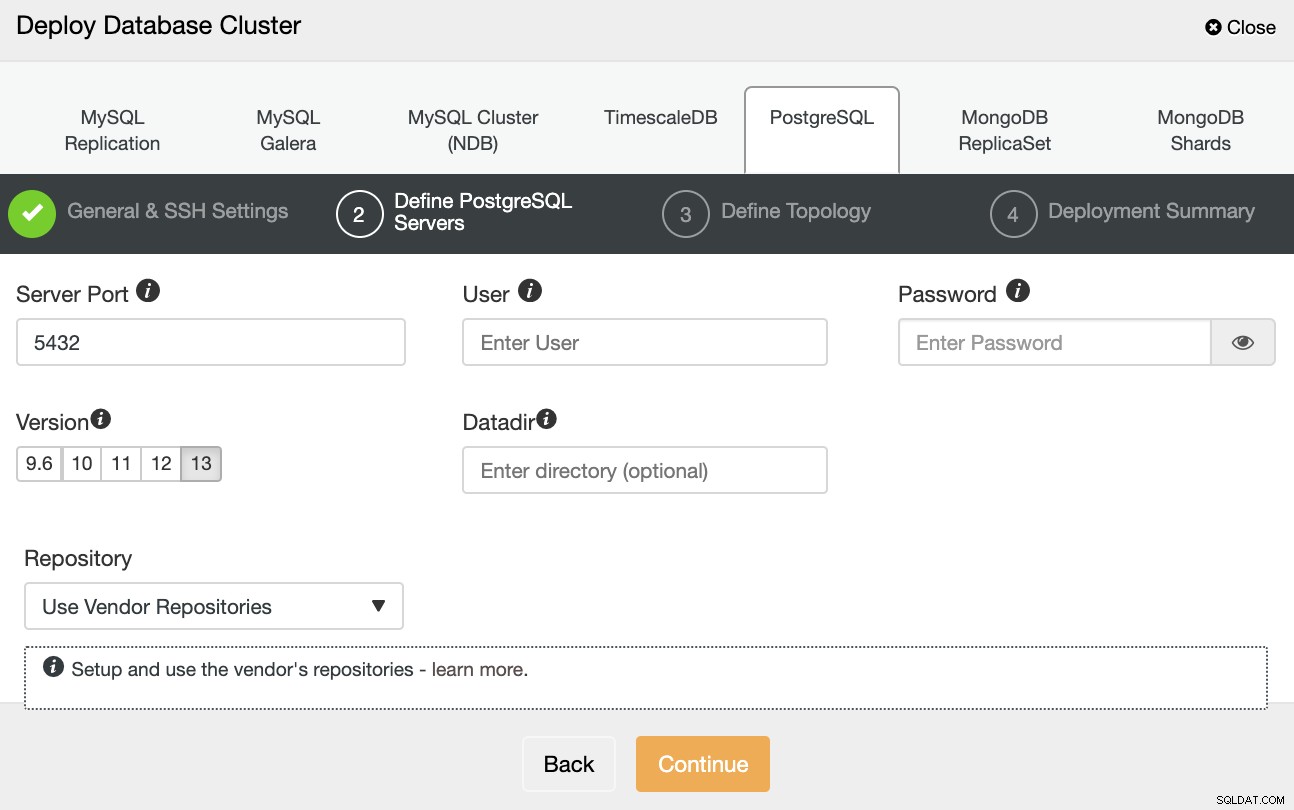
Nachdem Sie die SSH-Zugriffsinformationen eingerichtet haben, müssen Sie die Datenbankanmeldeinformationen definieren , Version und Datenverzeichnis (optional). Sie können auch angeben, welches Repository verwendet werden soll.
Im nächsten Schritt müssen Sie Ihre Server mithilfe der IP-Adresse oder des Hostnamens zu dem Cluster hinzufügen, den Sie erstellen werden.
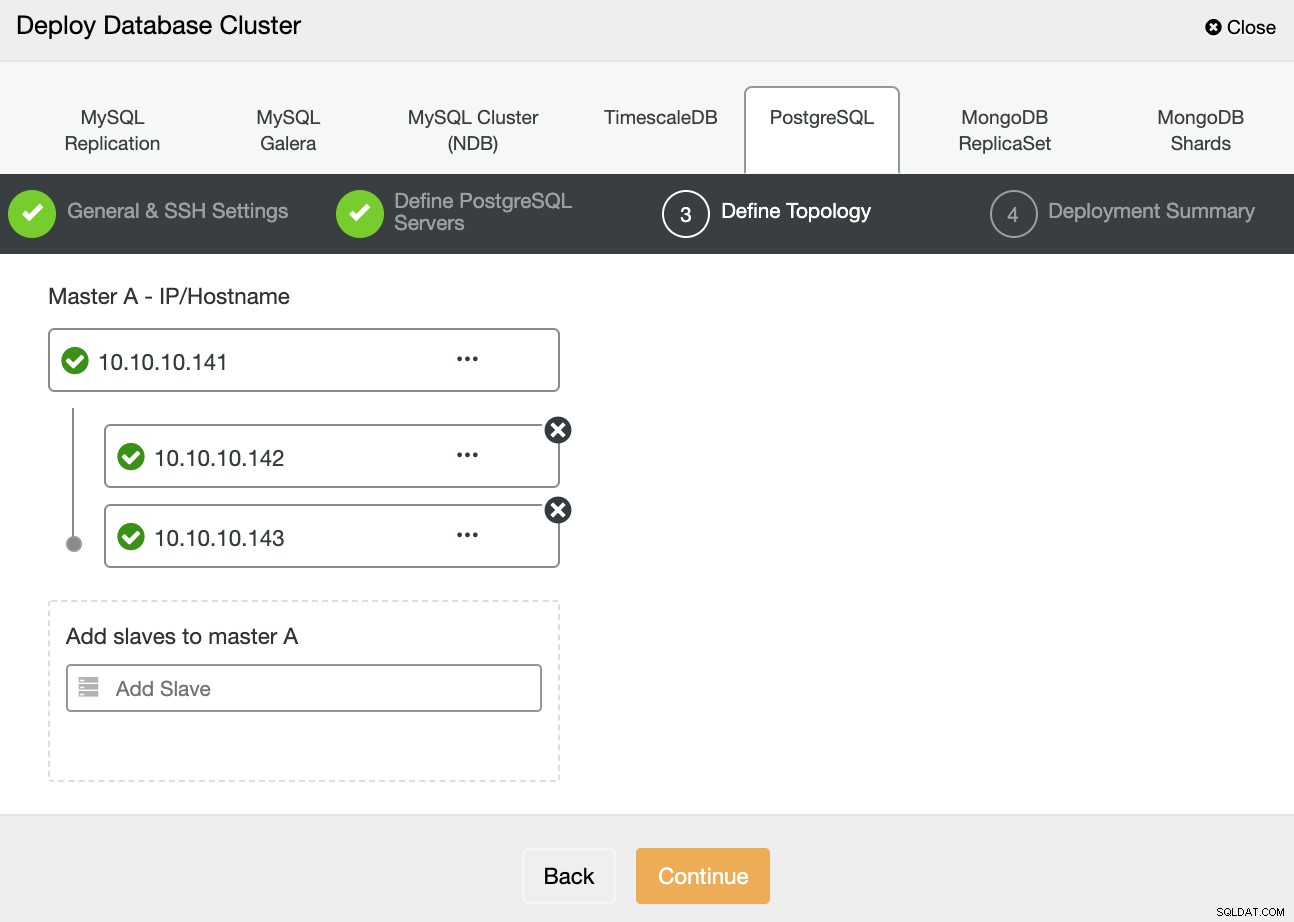
Im letzten Schritt können Sie auswählen, ob Ihre Replikation synchron oder Asynchron, und drücken Sie dann einfach auf Deploy.
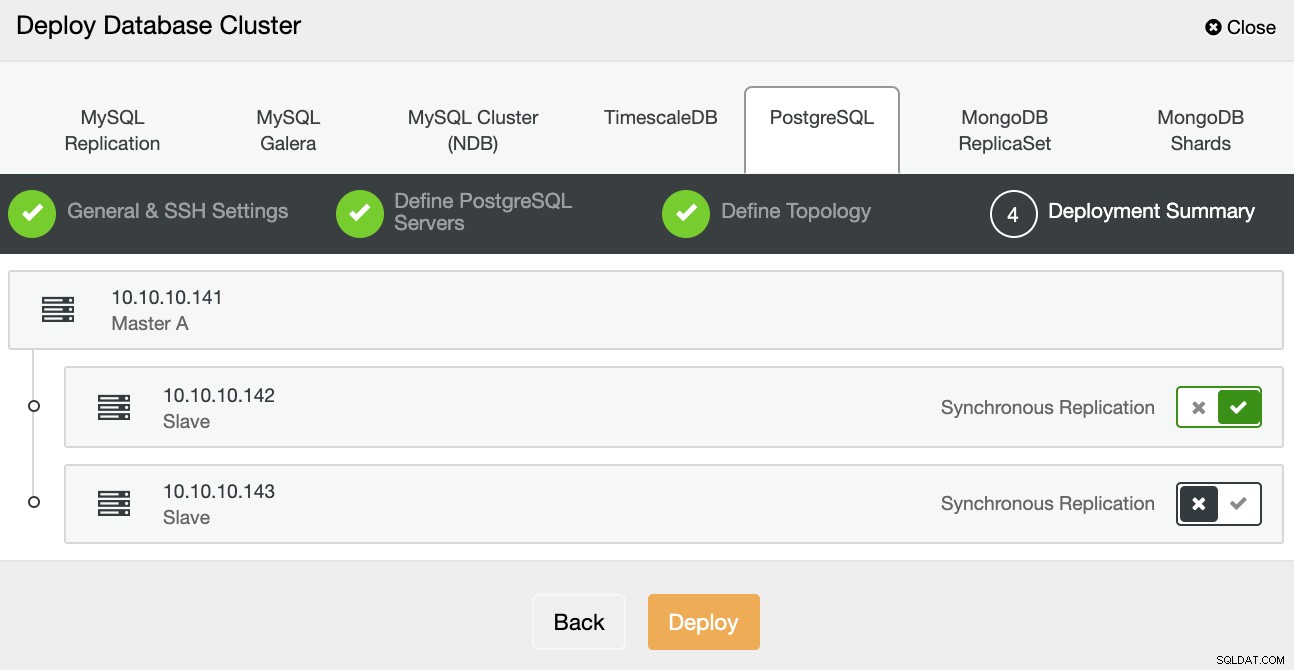
Sobald die Aufgabe abgeschlossen ist, können Sie Ihren neuen PostgreSQL-Cluster im sehen Hauptbildschirm von ClusterControl.

Jetzt haben Sie Ihren Cluster erstellt, Sie können mehrere Aufgaben darauf ausführen, wie das Hinzufügen von Load Balancern (HAProxy), Verbindungspoolern (PgBouncer) oder neuen Replikations-Slaves von derselben ClusterControl-Benutzeroberfläche.
Upgrade auf PostgreSQL 13
Wenn Sie Ihre aktuelle PostgreSQL-Version auf diese neue aktualisieren möchten, haben Sie drei Hauptoptionen, die diese Aufgabe ausführen.
-
Pg_dump:Es ist ein logisches Sicherungstool, mit dem Sie Ihre Daten sichern und im neuen PostgreSQL wiederherstellen können Ausführung. Hier haben Sie eine Ausfallzeit, die je nach Datengröße variiert. Sie müssen das System stoppen oder neue Daten im primären Knoten vermeiden, pg_dump ausführen, den generierten Dump auf den neuen Datenbankknoten verschieben und ihn wiederherstellen. Während dieser Zeit können Sie nicht in Ihre primäre PostgreSQL-Datenbank schreiben, um Dateninkonsistenzen zu vermeiden.
-
Pg_upgrade:Es ist ein PostgreSQL-Tool zum direkten Upgrade Ihrer PostgreSQL-Version. Es könnte in einer Produktionsumgebung gefährlich sein und wir empfehlen diese Methode in diesem Fall nicht. Wenn Sie diese Methode verwenden, werden Sie auch Ausfallzeit haben, aber wahrscheinlich wird sie erheblich kürzer sein als die Verwendung der vorherigen pg_dump-Methode.
-
Logische Replikation:Seit PostgreSQL 10 können Sie diese Replikationsmethode verwenden, mit der Sie größere Versions-Upgrades durchführen können null (oder fast null) Ausfallzeiten. Auf diese Weise können Sie in der letzten PostgreSQL-Version einen Standby-Knoten hinzufügen, und wenn die Replikation auf dem neuesten Stand ist, können Sie einen Failover-Prozess durchführen, um den neuen PostgreSQL-Knoten hochzustufen.
Ausführlichere Informationen zu den neuen Funktionen von PostgreSQL 13 finden Sie in der offiziellen Dokumentation.