Ihre Daten sind wahrscheinlich die wertvollsten Vermögenswerte im Unternehmen, daher sollten Sie einen Disaster Recovery Plan (DRP) haben, um Datenverlust im Falle eines Unfalls oder Hardwareausfalls zu verhindern. Ein Backup ist die einfachste Form von DR. Es reicht möglicherweise nicht immer aus, um ein akzeptables Recovery Point Objective (RPO) zu garantieren, ist aber ein guter erster Ansatz. Außerdem sollten Sie ein Recovery Time Objective (RTO) gemäß den Anforderungen Ihres Unternehmens definieren. Es gibt viele Möglichkeiten, den RTO-Wert zu erreichen, es hängt von den Unternehmenszielen ab.
In diesem Blog werden wir sehen, wie Sie pgBackRest zum Sichern von PostgreSQL und TimescaleDB verwenden und wie Sie eine der wichtigsten Funktionen dieses Sicherungstools, die Kombination aus vollständigen, inkrementellen und differenziellen Sicherungen, verwenden, um Ausfallzeiten zu minimieren.
Was ist pgBackRest?
Es gibt verschiedene Arten von Backups für Datenbanken:
- Logisch:Die Sicherung wird in einem für Menschen lesbaren Format wie SQL gespeichert.
- Physisch:Das Backup enthält binäre Daten.
- Vollständig/Inkrementell/Differentiell:Die Definition dieser drei Arten von Sicherungen ist bereits im Namen enthalten. Die vollständige Sicherung ist eine vollständige Kopie aller Ihrer Daten. Die inkrementelle Sicherung sichert nur die Daten, die sich seit der letzten Sicherung geändert haben, und die differenzielle Sicherung enthält nur die Daten, die sich seit der letzten vollständigen Sicherung geändert haben. Die inkrementellen und differenziellen Sicherungen wurden eingeführt, um den Zeitaufwand und die Speicherplatznutzung zu verringern, die für die Durchführung einer vollständigen Sicherung erforderlich sind.
pgBackRest ist ein Open-Source-Backup-Tool, das physische Backups mit einigen Verbesserungen im Vergleich zum klassischen pg_basebackup-Tool erstellt. Wir können pgBackRest verwenden, um eine anfängliche Datenbankkopie für die Streaming-Replikation durchzuführen, indem wir ein vorhandenes Backup verwenden, oder wir können die Delta-Option verwenden, um einen alten Standby-Server neu aufzubauen.
Einige der wichtigsten Funktionen von pgBackRest sind:
- Parallele Sicherung und Wiederherstellung
- Lokaler oder Remote-Betrieb
- Vollständige, inkrementelle und differenzielle Sicherungen
- Backup-Rotation und Archivablauf
- Integritätsprüfung der Sicherung
- Wiederaufnahme der Sicherung
- Delta-Wiederherstellung
- Verschlüsselung
Sehen wir uns nun an, wie wir pgBackRest verwenden können, um unsere PostgreSQL- und TimescaleDB-Datenbanken zu sichern.
Verwendung von pgBackRest
Für diesen Test verwenden wir CentOS 7 als Betriebssystem und PostgreSQL 11 als Datenbankserver. Wir gehen davon aus, dass Sie die Datenbank installiert haben. Wenn nicht, können Sie diesen Links folgen, um sowohl PostgreSQL als auch TimescaleDB auf einfache Weise mithilfe von ClusterControl bereitzustellen.
Zuerst müssen wir das Paket pgbackrest installieren.
$ yum install pgbackrestpgBackRest kann über die Befehlszeile oder über eine Konfigurationsdatei verwendet werden, die sich unter CentOS7 standardmäßig in /etc/pgbackrest.conf befindet. Diese Datei enthält die folgenden Zeilen:
[global]
repo1-path=/var/lib/pgbackrest
#[main]
#pg1-path=/var/lib/pgsql/10/dataSie können diesen Link überprüfen, um zu sehen, welche Parameter wir in dieser Konfigurationsdatei hinzufügen können.
Wir fügen die folgenden Zeilen hinzu:
[testing]
pg1-path=/var/lib/pgsql/11/dataStellen Sie sicher, dass Sie die folgende Konfiguration in der Datei postgresql.conf hinzugefügt haben (diese Änderungen erfordern einen Dienstneustart).
archive_mode = on
archive_command = 'pgbackrest --stanza=testing archive-push %p'
max_wal_senders = 3
wal_level = logicalLassen Sie uns nun ein grundlegendes Backup erstellen. Zuerst müssen wir eine „Stanza“ erstellen, die die Sicherungskonfiguration für einen bestimmten PostgreSQL- oder TimescaleDB-Datenbankcluster definiert. Der Zeilenabschnitt muss den Datenbank-Cluster-Pfad und den Host/Benutzer definieren, wenn der Datenbank-Cluster entfernt ist.
$ pgbackrest --stanza=testing --log-level-console=info stanza-create
2019-04-29 21:46:36.922 P00 INFO: stanza-create command begin 2.13: --log-level-console=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing
2019-04-29 21:46:37.475 P00 INFO: stanza-create command end: completed successfully (554ms)Und dann können wir den check-Befehl ausführen, um die Konfiguration zu validieren.
$ pgbackrest --stanza=testing --log-level-console=info check
2019-04-29 21:51:09.893 P00 INFO: check command begin 2.13: --log-level-console=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing
2019-04-29 21:51:12.090 P00 INFO: WAL segment 000000010000000000000001 successfully stored in the archive at '/var/lib/pgbackrest/archive/testing/11-1/0000000100000000/000000010000000000000001-f29875cffe780f9e9d9debeb0b44d945a5165409.gz'
2019-04-29 21:51:12.090 P00 INFO: check command end: completed successfully (2197ms)Um die Sicherung zu erstellen, führen Sie den folgenden Befehl aus:
$ pgbackrest --stanza=testing --type=full --log-level-stderr=info backup
INFO: backup command begin 2.13: --log-level-stderr=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing --type=full
WARN: option repo1-retention-full is not set, the repository may run out of space
HINT: to retain full backups indefinitely (without warning), set option 'repo1-retention-full' to the maximum.
INFO: execute non-exclusive pg_start_backup() with label "pgBackRest backup started at 2019-04-30 15:43:21": backup begins after the next regular checkpoint completes
INFO: backup start archive = 000000010000000000000006, lsn = 0/6000028
WARN: aborted backup 20190429-215508F of same type exists, will be cleaned to remove invalid files and resumed
INFO: backup file /var/lib/pgsql/11/data/base/16384/1255 (608KB, 1%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: backup file /var/lib/pgsql/11/data/base/13878/1255 (608KB, 3%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: backup file /var/lib/pgsql/11/data/base/13877/1255 (608KB, 5%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
. . .
INFO: full backup size = 31.8MB
INFO: execute non-exclusive pg_stop_backup() and wait for all WAL segments to archive
INFO: backup stop archive = 000000010000000000000006, lsn = 0/6000130
INFO: new backup label = 20190429-215508F
INFO: backup command end: completed successfully (12810ms)
INFO: expire command begin
INFO: option 'repo1-retention-archive' is not set - archive logs will not be expired
INFO: expire command end: completed successfully (10ms)Jetzt haben wir die Sicherung mit der Ausgabe „Erfolgreich abgeschlossen“ abgeschlossen, also lassen Sie uns sie wiederherstellen. Wir stoppen den postgresql-11-Dienst.
$ service postgresql-11 stop
Redirecting to /bin/systemctl stop postgresql-11.serviceUnd lass das Datenverzeichnis leer.
$ rm -rf /var/lib/pgsql/11/data/*Führen Sie nun den folgenden Befehl aus:
$ pgbackrest --stanza=testing --log-level-stderr=info restore
INFO: restore command begin 2.13: --log-level-stderr=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing
INFO: restore backup set 20190429-215508F
INFO: restore file /var/lib/pgsql/11/data/base/16384/1255 (608KB, 1%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: restore file /var/lib/pgsql/11/data/base/13878/1255 (608KB, 3%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: restore file /var/lib/pgsql/11/data/base/13877/1255 (608KB, 5%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
. . .
INFO: write /var/lib/pgsql/11/data/recovery.conf
INFO: restore global/pg_control (performed last to ensure aborted restores cannot be started)
INFO: restore command end: completed successfully (10819ms)Starten Sie dann den postgresql-11-Dienst.
$ service postgresql-11 stopUnd jetzt haben wir unsere Datenbank am Laufen.
$ psql -U app_user world
world=> select * from city limit 5;
id | name | countrycode | district | population
----+----------------+-------------+---------------+------------
1 | Kabul | AFG | Kabol | 1780000
2 | Qandahar | AFG | Qandahar | 237500
3 | Herat | AFG | Herat | 186800
4 | Mazar-e-Sharif | AFG | Balkh | 127800
5 | Amsterdam | NLD | Noord-Holland | 731200
(5 rows)Sehen wir uns nun an, wie wir eine differenzielle Sicherung erstellen können.
$ pgbackrest --stanza=testing --type=diff --log-level-stderr=info backup
INFO: backup command begin 2.13: --log-level-stderr=info --pg1-path=/var/lib/pgsql/11/data --repo1-path=/var/lib/pgbackrest --stanza=testing --type=diff
WARN: option repo1-retention-full is not set, the repository may run out of space
HINT: to retain full backups indefinitely (without warning), set option 'repo1-retention-full' to the maximum.
INFO: last backup label = 20190429-215508F, version = 2.13
INFO: execute non-exclusive pg_start_backup() with label "pgBackRest backup started at 2019-04-30 21:22:58": backup begins after the next regular checkpoint completes
INFO: backup start archive = 00000002000000000000000B, lsn = 0/B000028
WARN: a timeline switch has occurred since the last backup, enabling delta checksum
INFO: backup file /var/lib/pgsql/11/data/base/16429/1255 (608KB, 1%) checksum e560330eb5300f7e2bcf8260f37f36660ce3a2c1
INFO: backup file /var/lib/pgsql/11/data/base/16429/2608 (448KB, 8%) checksum 53bd7995dc4d29226b1ad645995405e0a96a4a7b
. . .
INFO: diff backup size = 40.1MB
INFO: execute non-exclusive pg_stop_backup() and wait for all WAL segments to archive
INFO: backup stop archive = 00000002000000000000000B, lsn = 0/B000130
INFO: new backup label = 20190429-215508F_20190430-212258D
INFO: backup command end: completed successfully (23982ms)
INFO: expire command begin
INFO: option 'repo1-retention-archive' is not set - archive logs will not be expired
INFO: expire command end: completed successfully (14ms)Für komplexere Sicherungen können Sie der pgBackRest-Benutzeranleitung folgen.
Wie bereits erwähnt, können Sie Ihre Backups über die Befehlszeile oder die Konfigurationsdateien verwalten.
Verwendung von pgBackRest in ClusterControl
Seit Version 1.7.2 hat ClusterControl Unterstützung für pgBackRest zum Sichern von PostgreSQL- und TimescaleDB-Datenbanken hinzugefügt, also sehen wir uns an, wie wir es von ClusterControl aus verwenden können.
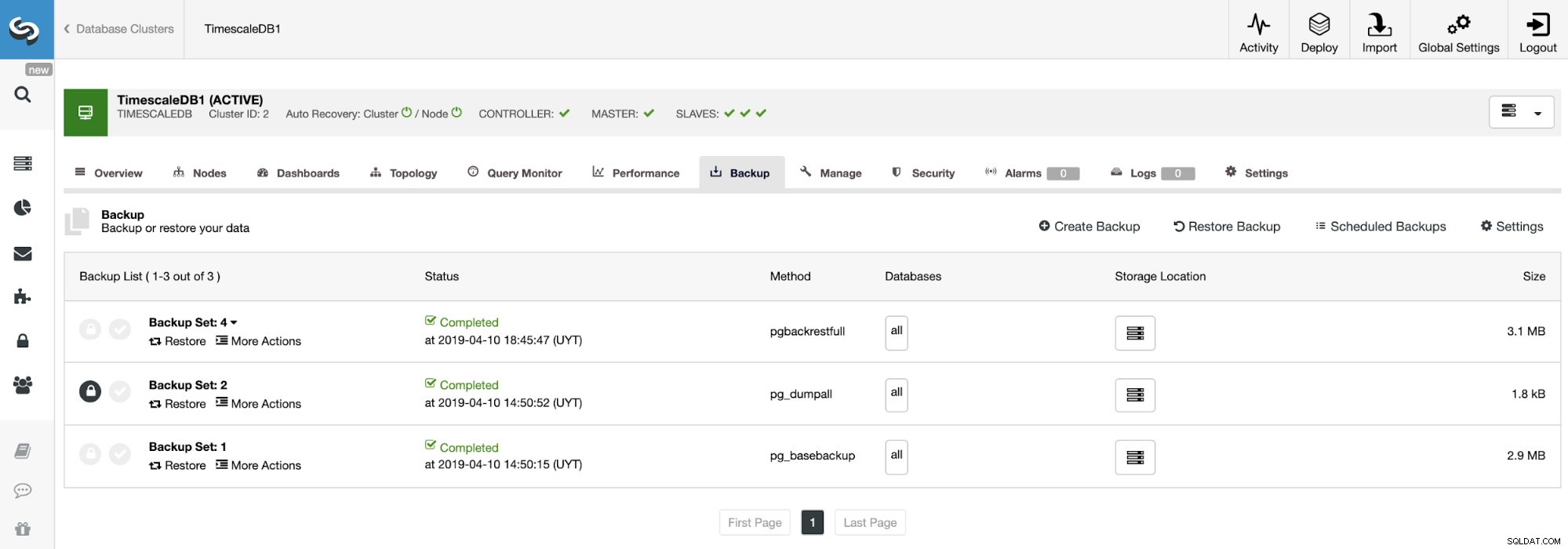
Erstellen einer Sicherung
Gehen Sie für diese Aufgabe zu ClusterControl -> Cluster auswählen -> Backup -> Backup erstellen.
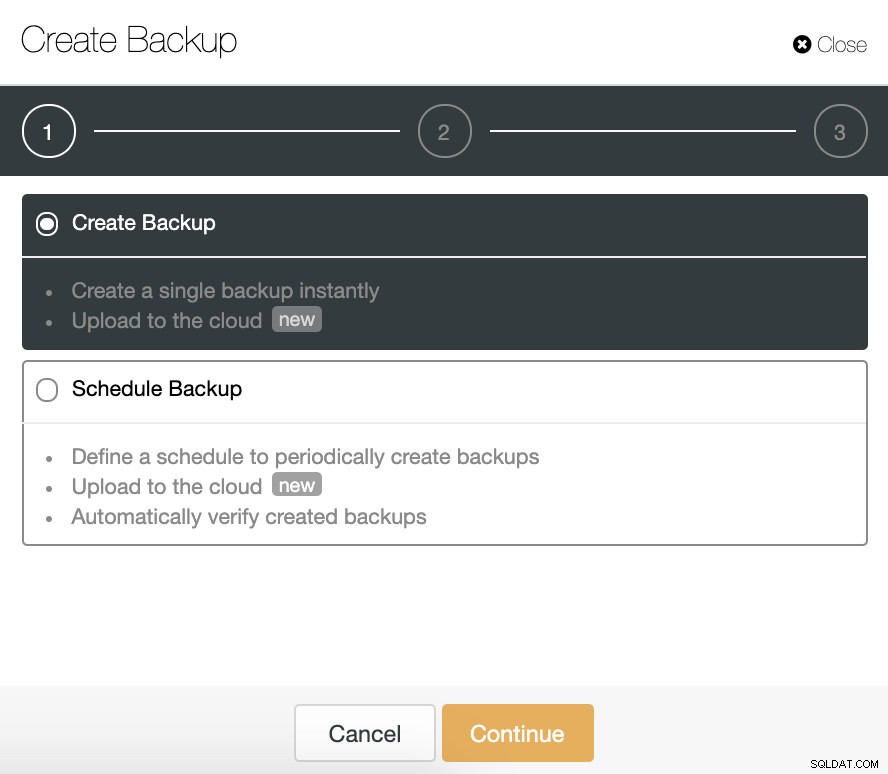
Wir können ein neues Backup erstellen oder ein geplantes konfigurieren. Für unser Beispiel erstellen wir sofort ein einzelnes Backup.
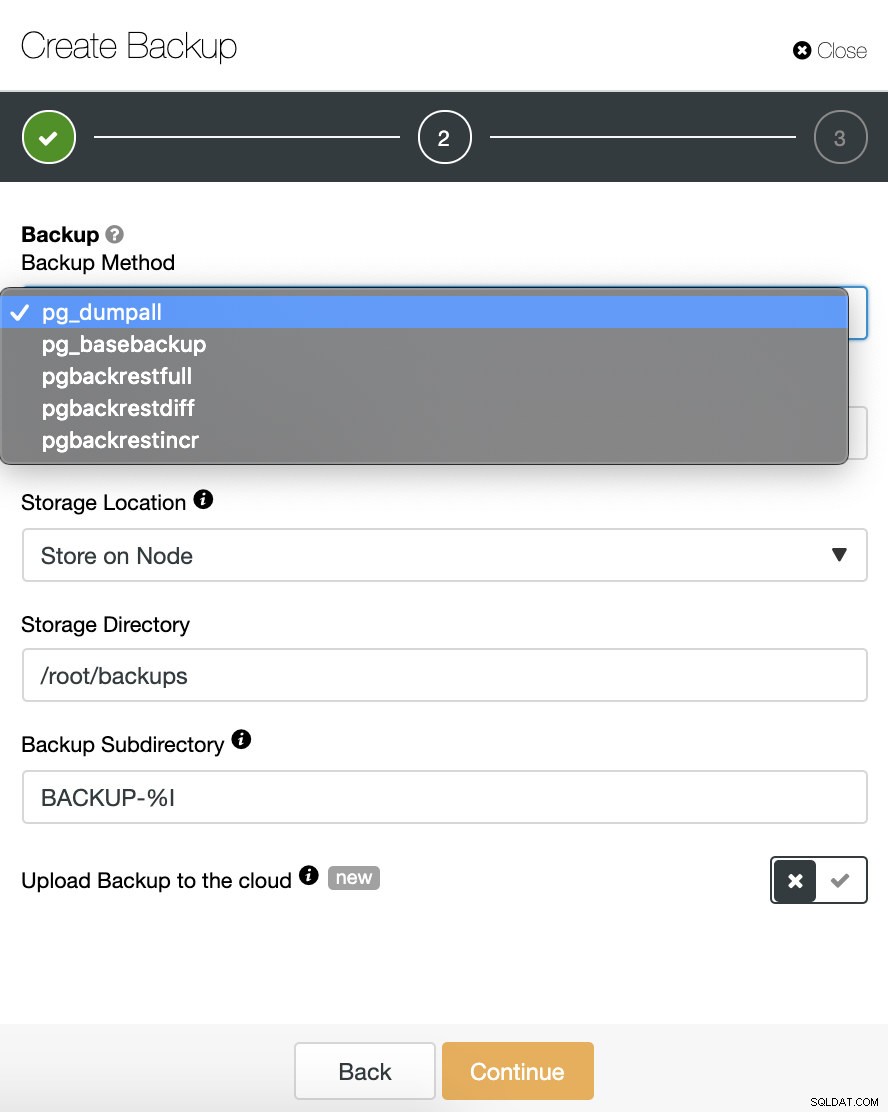
Wir müssen eine Methode auswählen, den Server, von dem die Sicherung erstellt wird, und den Ort, an dem wir die Sicherung speichern möchten. Wir können unser Backup auch in die Cloud (AWS, Google oder Azure) hochladen, indem wir die entsprechende Schaltfläche aktivieren.
In diesem Fall wählen wir die pgbackrestfull-Methode, um eine erste vollständige Sicherung zu erstellen. Wenn Sie diese Option auswählen, sehen wir den folgenden roten Hinweis:
„Während des ersten Versuchs, ein pgBackRest-Backup zu erstellen, konfiguriert ClusterControl den Knoten neu (stellt pgBackRest bereit und konfiguriert ihn) und danach muss der Datenbankknoten zuerst neu gestartet werden.“
Berücksichtigen Sie dies also bitte beim ersten Sicherungsversuch.
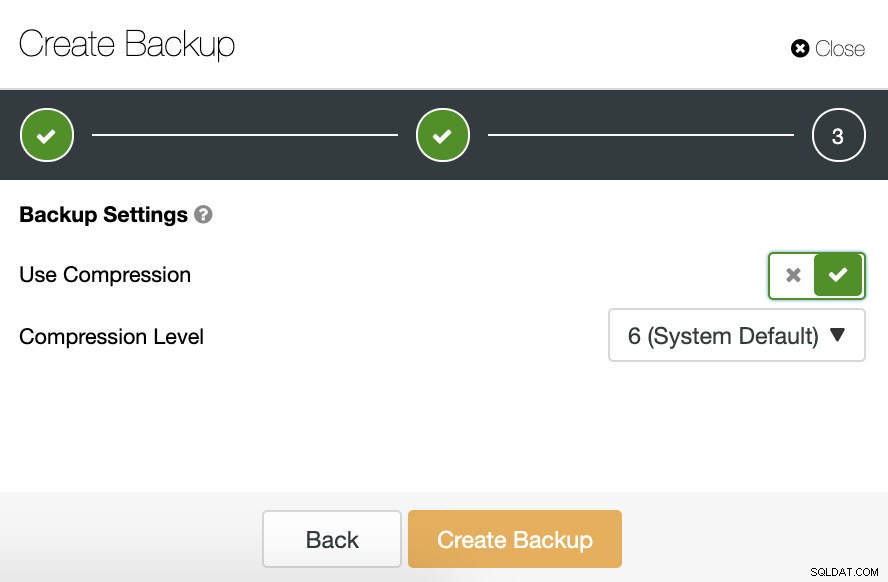
Dann legen wir die Verwendung der Komprimierung und die Komprimierungsstufe für unser Backup fest.
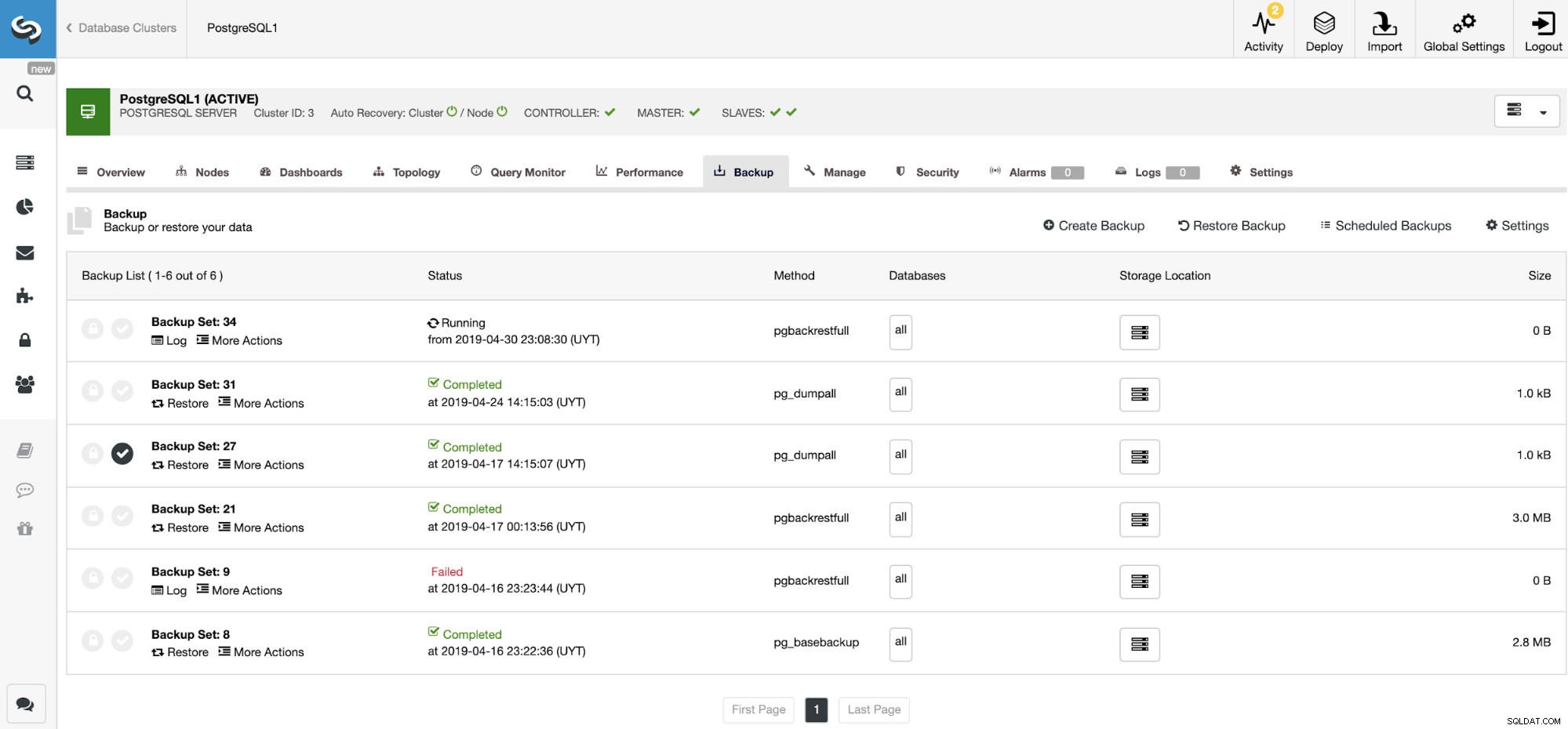
Im Backup-Bereich können wir den Fortschritt des Backups und Informationen wie Methode, Größe, Speicherort und mehr sehen.
Die Schritte sind die gleichen, um eine differenzielle oder inkrementelle Sicherung zu erstellen. Wir müssen nur die gewünschte Methode während der Backup-Erstellung auswählen.
Ein Backup wiederherstellen
Sobald die Sicherung abgeschlossen ist, können wir sie mithilfe von ClusterControl wiederherstellen. Dazu können wir in unserem Backup-Bereich (ClusterControl -> Cluster auswählen -> Backup) „Backup wiederherstellen“ oder direkt „Wiederherstellen“ für das Backup auswählen, das wir wiederherstellen möchten.
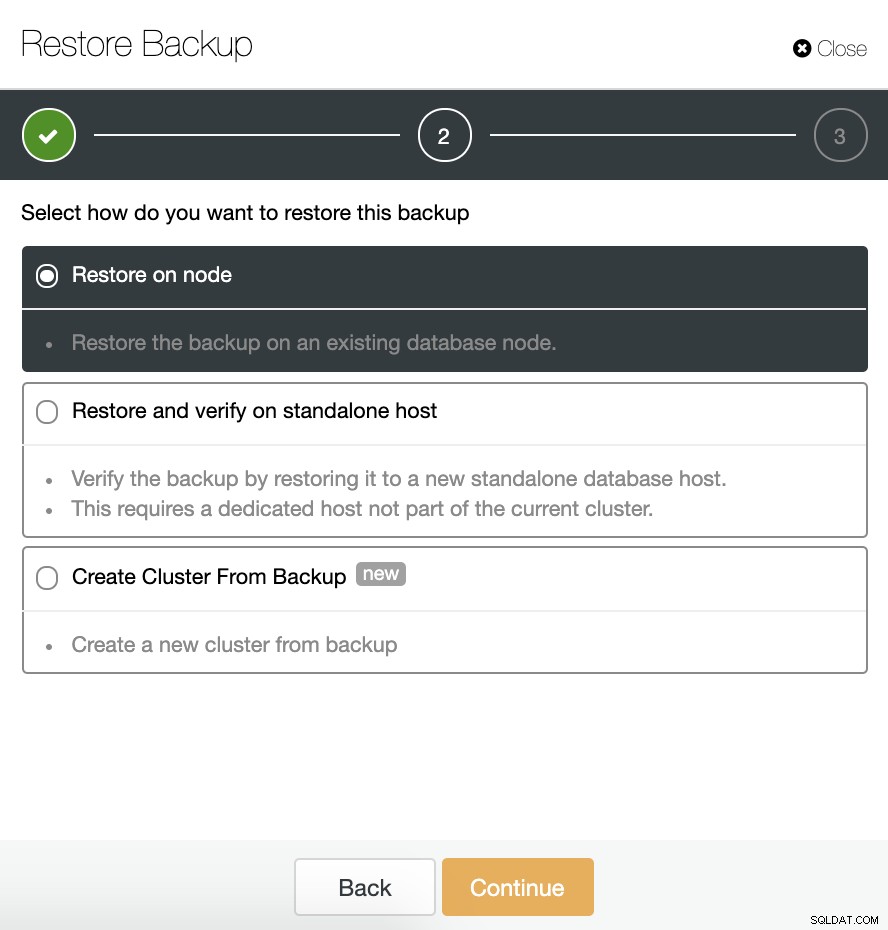
Wir haben drei Möglichkeiten, die Sicherung wiederherzustellen. Wir können die Sicherung in einem vorhandenen Datenbankknoten wiederherstellen, die Sicherung auf einem eigenständigen Host wiederherstellen und überprüfen oder aus der Sicherung einen neuen Cluster erstellen.
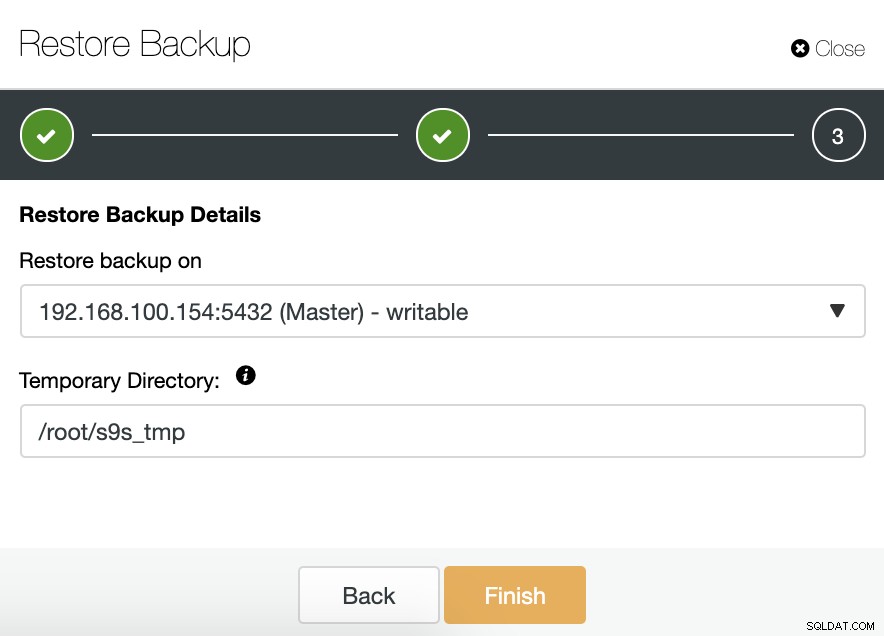
Wenn wir die Option „Auf Knoten wiederherstellen“ wählen, müssen wir den Master-Knoten angeben, da er der einzige im Cluster ist, auf den geschrieben werden kann.
Wir können den Fortschritt unserer Wiederherstellung im Aktivitätsbereich in unserem ClusterControl überwachen.
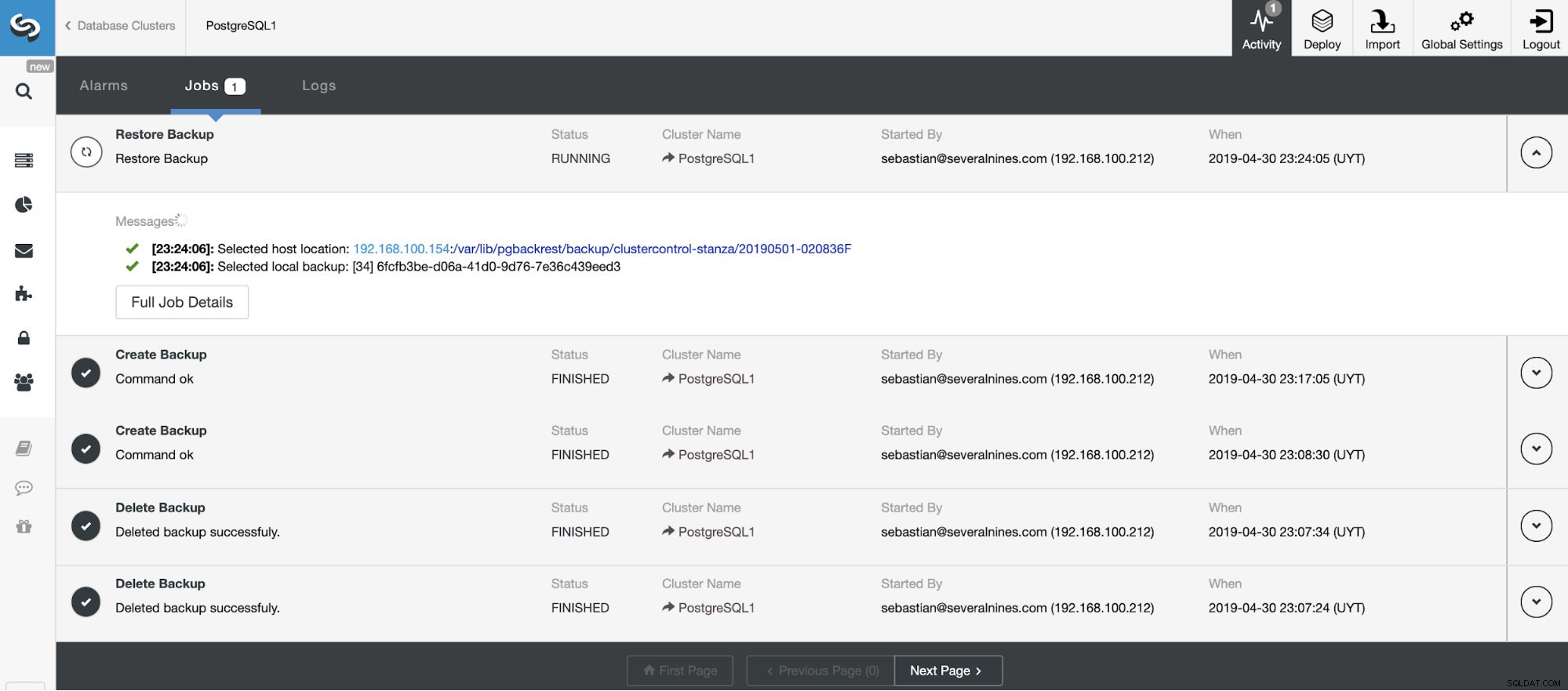
Automatische Sicherungsüberprüfung
Ein Backup ist kein Backup, wenn es nicht wiederherstellbar ist. Das Überprüfen von Backups wird normalerweise von vielen vernachlässigt. Sehen wir uns an, wie ClusterControl die Überprüfung von PostgreSQL- und TimescaleDB-Backups automatisieren und dabei helfen kann, Überraschungen zu vermeiden.
Wählen Sie in ClusterControl Ihren Cluster aus und gehen Sie zum Abschnitt „Sicherung“. Wählen Sie dann „Sicherung erstellen“.
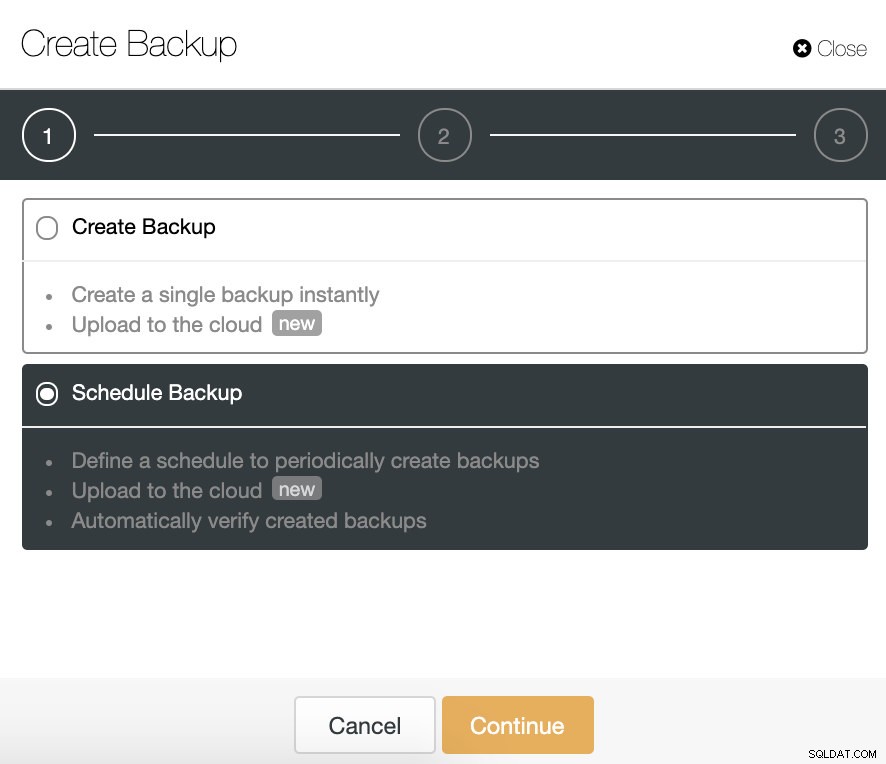
Die Funktion zur automatischen Überprüfung der Sicherung ist für geplante Sicherungen verfügbar. Wählen wir also die Option „Sicherung planen“.
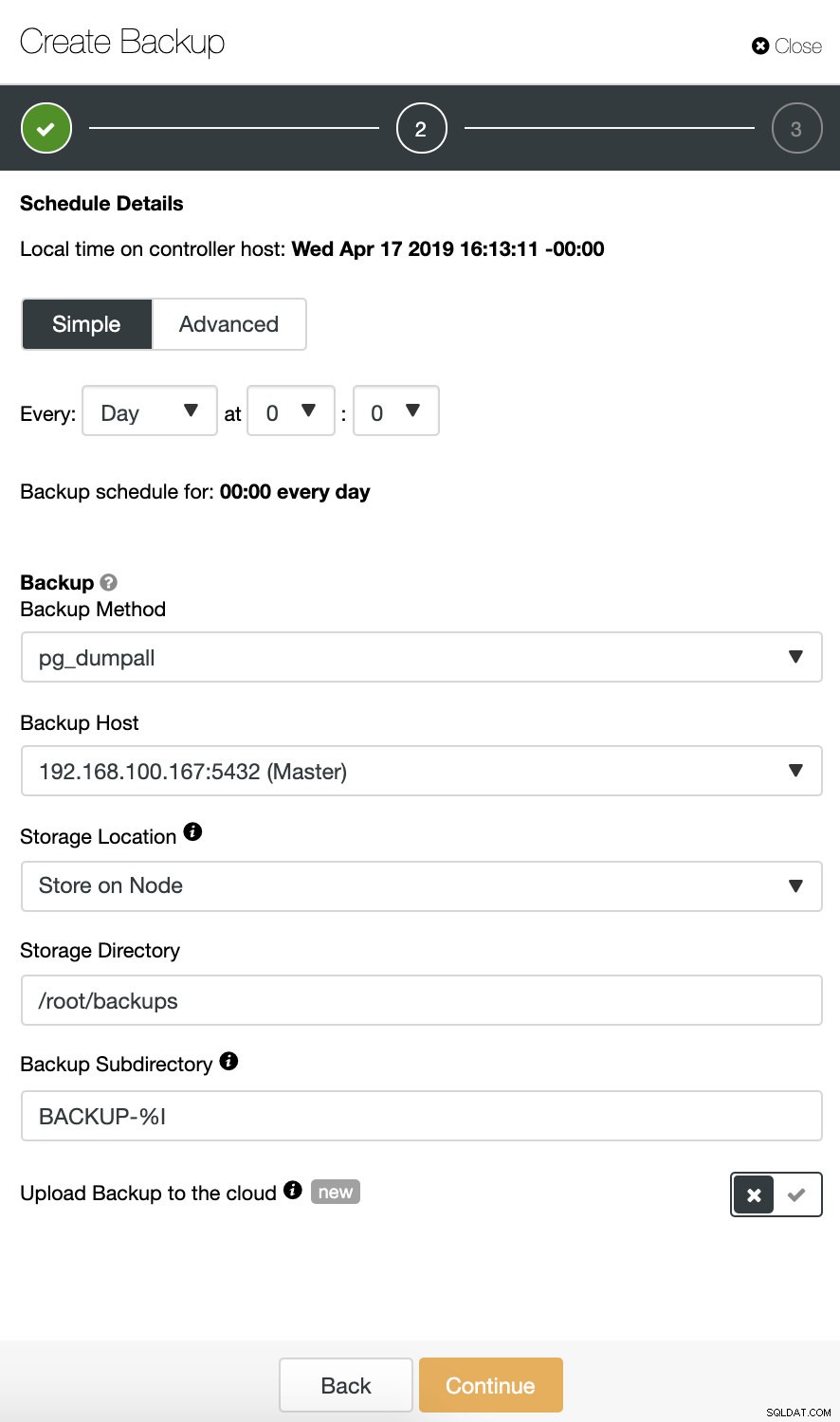
Beim Planen einer Sicherung müssen wir zusätzlich zur Auswahl der üblichen Optionen wie Methode oder Speicher auch Zeitplan/Häufigkeit angeben.
Im nächsten Schritt können wir unser Backup komprimieren und die Funktion „Backup überprüfen“ aktivieren.
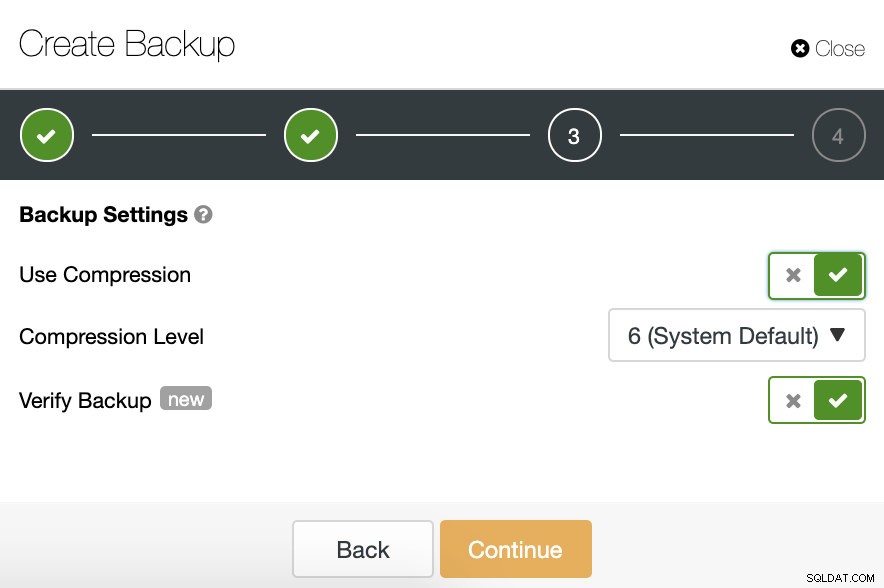
Um diese Funktion nutzen zu können, benötigen wir einen dedizierten Host (oder eine VM), der nicht Teil des Clusters ist.
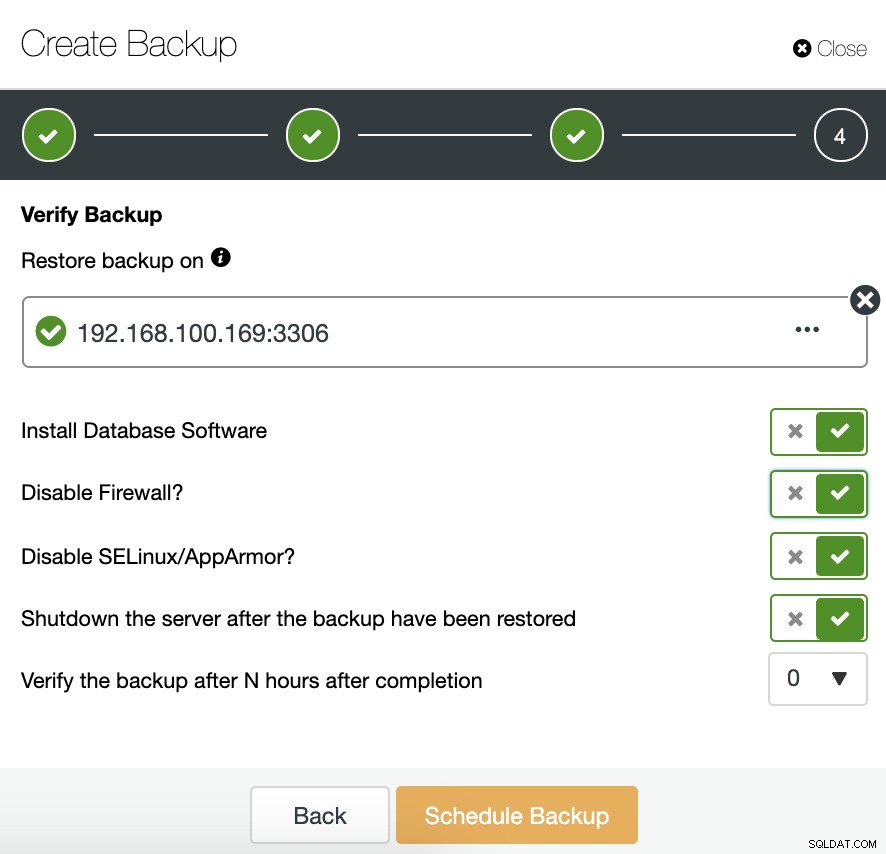
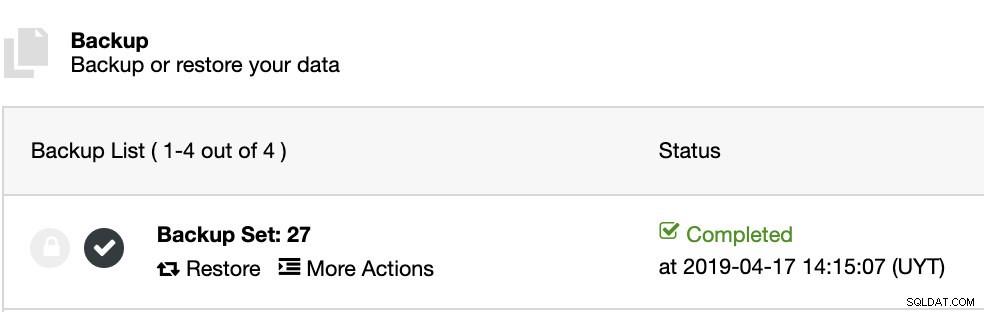
ClusterControl installiert die Software und stellt die Sicherung auf diesem Host wieder her. Nach der Wiederherstellung können wir das Verifizierungssymbol im Bereich ClusterControl Backup sehen.
Empfehlungen
Es gibt auch einige Tipps, die wir bei der Erstellung unserer Backups berücksichtigen können:
- Speichern Sie die Sicherung an einem entfernten Ort:Wir sollten die Sicherung nicht auf dem Datenbankserver speichern. Im Falle eines Serverausfalls könnten wir gleichzeitig die Datenbank und das Backup verlieren.
- Bewahren Sie eine Kopie der letzten Sicherung auf dem Datenbankserver auf:Dies könnte für eine schnellere Wiederherstellung nützlich sein.
- Verwenden Sie inkrementelle/differenzielle Backups:Um die Backup-Wiederherstellungszeit und den Speicherplatzverbrauch zu reduzieren.
- Sichern Sie die WALs:Wenn wir eine Datenbank aus der letzten Sicherung wiederherstellen müssen und Sie sie nur wiederherstellen, verlieren Sie die Änderungen seit der Sicherung bis zum Zeitpunkt der Wiederherstellung, aber wenn wir die WALs haben, können wir sie anwenden die Änderungen und wir können PITR verwenden.
- Verwenden Sie sowohl logische als auch physische Backups:Beide sind aus unterschiedlichen Gründen erforderlich, zum Beispiel, wenn wir nur eine Datenbank/Tabelle wiederherstellen möchten, brauchen wir kein physisches Backup, wir brauchen nur das logische Backup und es wird noch schneller als die Wiederherstellung des gesamten Servers.
- Erstellen Sie Backups von Standby-Knoten (sofern möglich):Um eine zusätzliche Last auf dem primären Knoten zu vermeiden, empfiehlt es sich, das Backup vom Standby-Server zu erstellen.
- Testen Sie Ihre Backups:Die Bestätigung, dass das Backup fertig ist, reicht nicht aus, um sicherzustellen, dass das Backup funktioniert. Wir sollten es auf einem eigenständigen Server wiederherstellen und testen, um im Falle eines Ausfalls eine Überraschung zu vermeiden.
Schlussfolgerung
Wie wir sehen konnten, ist pgBackRest eine gute Option, um unsere Sicherungsstrategie zu verbessern. Es hilft Ihnen, Ihre Daten zu schützen, und es könnte nützlich sein, die RTO zu erreichen, indem die Ausfallzeit im Fehlerfall reduziert wird. Inkrementelle Backups können dazu beitragen, die Zeit und den Speicherplatz zu reduzieren, die für den Backup-Prozess verwendet werden. ClusterControl kann dabei helfen, den Backup-Prozess für Ihre PostgreSQL- und TimescaleDB-Datenbanken zu automatisieren und im Fehlerfall mit wenigen Klicks wiederherzustellen.