Heutzutage ist es üblich, große Datenmengen in der Datenbank eines Unternehmens zu sehen, aber je nach Größe kann es schwierig sein, sie zu verwalten, und die Leistung kann bei hohem Datenverkehr beeinträchtigt werden, wenn wir sie nicht richtig konfigurieren oder implementieren . Wenn wir eine riesige Datenbank haben und eine kurze Antwortzeit haben möchten, sollten wir sie im Allgemeinen skalieren. PostgreSQL ist in diesem Punkt keine Ausnahme. Es gibt viele Ansätze zum Skalieren von PostgreSQL, aber zuerst wollen wir lernen, was Skalierung ist.
Skalierbarkeit ist die Eigenschaft eines Systems/einer Datenbank, eine wachsende Menge an Anforderungen durch Hinzufügen von Ressourcen zu bewältigen.
Die Gründe für diese Menge an Nachfragen können zeitlicher Natur sein, wenn wir zum Beispiel einen Rabatt auf einen Verkauf einführen, oder dauerhaft, für eine Zunahme von Kunden oder Mitarbeitern. In jedem Fall sollten wir in der Lage sein, Ressourcen hinzuzufügen oder zu entfernen, um diese Änderungen entsprechend den Anforderungen oder dem Anstieg des Datenverkehrs zu verwalten.
In diesem Blog sehen wir uns an, wie wir unsere PostgreSQL-Datenbank skalieren können und wann wir dies tun müssen.
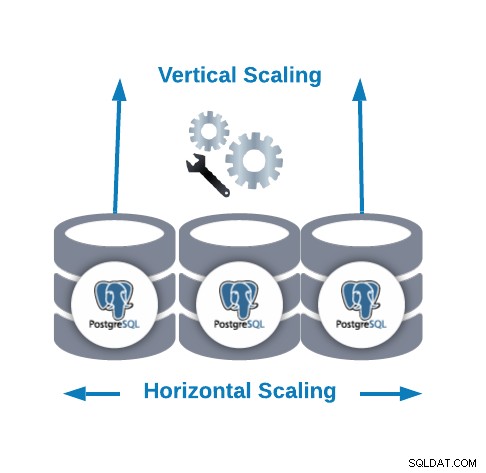
Horizontale Skalierung vs. vertikale Skalierung
Es gibt zwei Möglichkeiten, unsere Datenbank zu skalieren...
- Horizontale Skalierung (Scale-out):Sie wird durchgeführt, indem weitere Datenbankknoten hinzugefügt werden, um einen Datenbankcluster zu erstellen oder zu vergrößern.
- Vertikale Skalierung (Scale-up):Sie wird durchgeführt, indem einem vorhandenen Datenbankknoten weitere Hardwareressourcen (CPU, Arbeitsspeicher, Festplatte) hinzugefügt werden.
Für die horizontale Skalierung können wir weitere Datenbankknoten als Slave-Knoten hinzufügen. Es kann uns helfen, die Leseleistung zu verbessern, indem der Datenverkehr zwischen den Knoten ausgeglichen wird. In diesem Fall müssen wir einen Load Balancer hinzufügen, um den Datenverkehr je nach Richtlinie und Knotenstatus an den richtigen Knoten zu verteilen.
Um einen Single Point of Failure beim Hinzufügen von nur einem Load Balancer zu vermeiden, sollten wir in Betracht ziehen, zwei oder mehr Load Balancer-Knoten hinzuzufügen und ein Tool wie „Keepalived“ zu verwenden, um die Verfügbarkeit sicherzustellen.
Da PostgreSQL keine native Multi-Master-Unterstützung hat, müssen wir für diese Aufgabe ein externes Tool verwenden, wenn wir es implementieren möchten, um die Schreibleistung zu verbessern.
Für die vertikale Skalierung kann es erforderlich sein, einige Konfigurationsparameter zu ändern, damit PostgreSQL eine neue oder bessere Hardwareressource verwenden kann. Sehen wir uns einige dieser Parameter aus der PostgreSQL-Dokumentation an.
- work_mem:Gibt die Speichermenge an, die von internen Sortieroperationen und Hash-Tabellen verwendet werden soll, bevor in temporäre Plattendateien geschrieben wird. Mehrere laufende Sitzungen könnten solche Operationen gleichzeitig ausführen, sodass der verwendete Gesamtspeicher ein Vielfaches des Wertes von work_mem betragen könnte.
- maintenance_work_mem:Gibt die maximale Speichermenge an, die von Wartungsvorgängen wie VACUUM, CREATE INDEX und ALTER TABLE ADD FOREIGN KEY verwendet werden soll. Größere Einstellungen können die Leistung beim Vakuumieren und Wiederherstellen von Datenbank-Dumps verbessern.
- autovacuum_work_mem:Gibt die maximale Speichermenge an, die von jedem Autovacuum-Worker-Prozess verwendet werden soll.
- autovacuum_max_workers:Gibt die maximale Anzahl von Autovacuum-Prozessen an, die gleichzeitig ausgeführt werden können.
- max_worker_processes:Legt die maximale Anzahl von Hintergrundprozessen fest, die das System unterstützen kann. Legen Sie das Limit des Prozesses fest, z. B. Staubsaugen, Kontrollpunkte und weitere Wartungsarbeiten.
- max_parallel_workers:Legt die maximale Anzahl von Workern fest, die das System für parallele Operationen unterstützen kann. Parallele Worker werden aus dem Pool von Worker-Prozessen entnommen, der durch den vorherigen Parameter eingerichtet wurde.
- max_parallel_maintenance_workers:Legt die maximale Anzahl paralleler Worker fest, die durch einen einzigen Utility-Befehl gestartet werden können. Derzeit ist CREATE INDEX der einzige parallele Hilfsbefehl, der die Verwendung paralleler Worker unterstützt, und zwar nur beim Erstellen eines B-Tree-Index.
- effektive_cache_größe:Legt die Annahme des Planers über die effektive Größe des Festplatten-Cache fest, der für eine einzelne Abfrage verfügbar ist. Dies wird bei Schätzungen der Kosten für die Verwendung eines Index berücksichtigt; ein höherer Wert macht es wahrscheinlicher, dass Indexscans verwendet werden, ein niedrigerer Wert macht es wahrscheinlicher, dass sequenzielle Scans verwendet werden.
- shared_buffers:Legt die Speichermenge fest, die der Datenbankserver für gemeinsam genutzte Speicherpuffer verwendet. Einstellungen, die deutlich über dem Minimum liegen, sind normalerweise für eine gute Leistung erforderlich.
- temp_buffers:Legt die maximale Anzahl temporärer Puffer fest, die von jeder Datenbanksitzung verwendet werden. Dies sind sitzungslokale Puffer, die nur für den Zugriff auf temporäre Tabellen verwendet werden.
- effektive_io_concurrency:Legt die Anzahl der gleichzeitigen Festplatten-E/A-Vorgänge fest, die PostgreSQL erwartet, dass sie gleichzeitig ausgeführt werden können. Das Erhöhen dieses Werts erhöht die Anzahl der E/A-Vorgänge, die jede einzelne PostgreSQL-Sitzung parallel zu initiieren versucht. Derzeit wirkt sich diese Einstellung nur auf Bitmap-Heap-Scans aus.
- max_connections:Bestimmt die maximale Anzahl gleichzeitiger Verbindungen zum Datenbankserver. Durch Erhöhen dieses Parameters kann PostgreSQL mehr Backend-Prozesse gleichzeitig ausführen.
An dieser Stelle müssen wir uns eine Frage stellen. Wie können wir wissen, ob wir unsere Datenbank skalieren müssen und wie können wir dies am besten tun?
Überwachung
Das Skalieren unserer PostgreSQL-Datenbank ist ein komplexer Prozess, daher sollten wir einige Metriken überprüfen, um die beste Strategie zum Skalieren bestimmen zu können.
Wir können die CPU-, Arbeitsspeicher- und Festplattennutzung überwachen, um festzustellen, ob es ein Konfigurationsproblem gibt oder ob wir unsere Datenbank tatsächlich skalieren müssen. Wenn wir beispielsweise eine hohe Serverlast sehen, aber die Datenbankaktivität gering ist, ist es wahrscheinlich nicht erforderlich, sie zu skalieren, wir müssen nur die Konfigurationsparameter überprüfen, um sie mit unseren Hardwareressourcen abzugleichen.
Die Überprüfung des Speicherplatzes, der vom PostgreSQL-Knoten pro Datenbank verwendet wird, kann uns helfen zu bestätigen, ob wir mehr Speicherplatz oder sogar eine Tabellenpartitionierung benötigen. Um den von einer Datenbank/Tabelle verwendeten Speicherplatz zu überprüfen, können wir einige PostgreSQL-Funktionen wie pg_database_size oder pg_table_size verwenden.
Von der Datenbankseite sollten wir prüfen
- Verbindungsmenge
- Ausführen von Abfragen
- Indexnutzung
- Aufblasen
- Replikationsverzögerung
Dies könnten klare Metriken sein, um zu bestätigen, ob die Skalierung unserer Datenbank erforderlich ist.
ClusterControl als Skalierungs- und Überwachungssystem
ClusterControl kann uns dabei helfen, mit beiden Skalierungsmethoden fertig zu werden, die wir zuvor gesehen haben, und alle erforderlichen Metriken zu überwachen, um die Skalierungsanforderung zu bestätigen. Mal sehen wie...
Wenn Sie ClusterControl noch nicht verwenden, können Sie es installieren und Ihre aktuelle PostgreSQL-Datenbank bereitstellen oder importieren, indem Sie die Option „Importieren“ auswählen und den Schritten folgen, um alle ClusterControl-Funktionen wie Backups, automatisches Failover, Warnungen, Überwachung, und mehr.
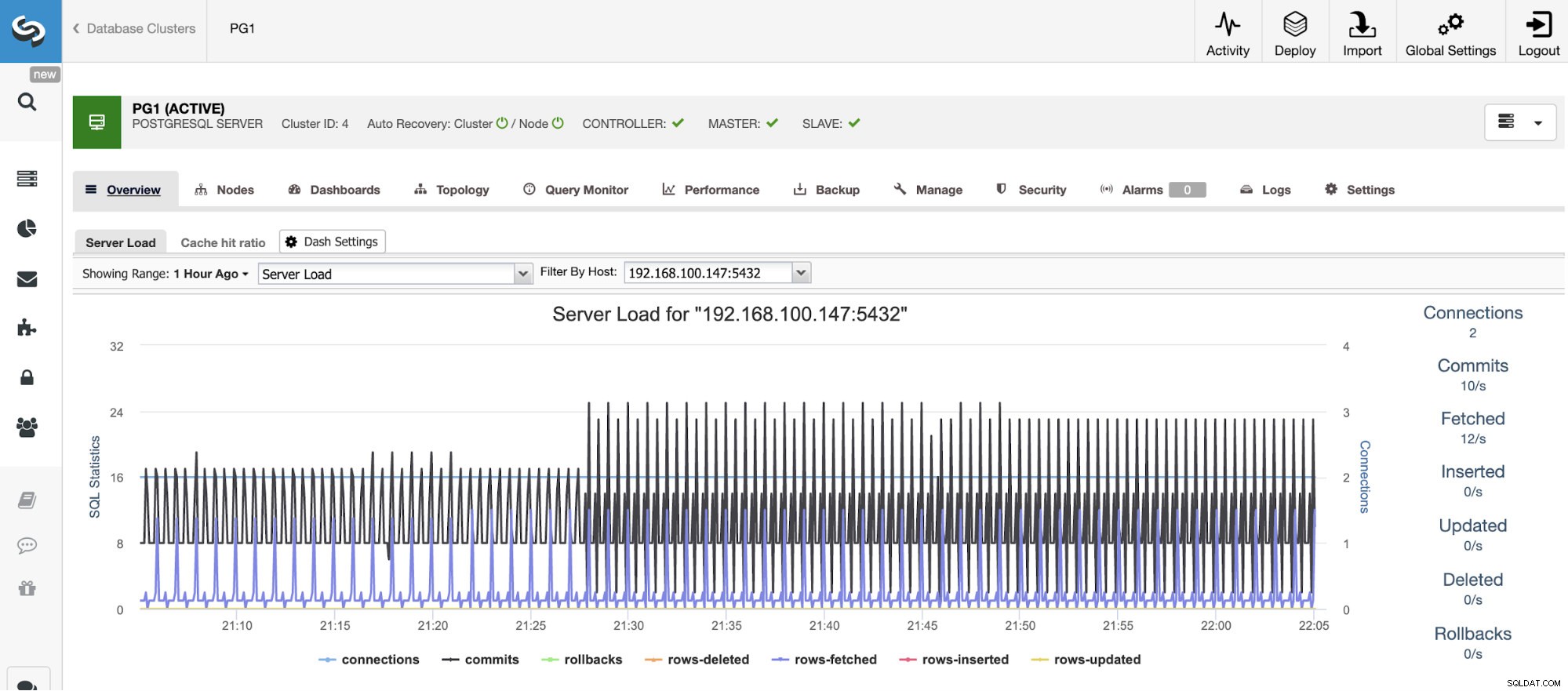
Horizontale Skalierung
Wenn wir für die horizontale Skalierung zu Cluster-Aktionen gehen und „Add Replication Slave“ auswählen, können wir entweder ein neues Replikat von Grund auf neu erstellen oder eine vorhandene PostgreSQL-Datenbank als Replikat hinzufügen.
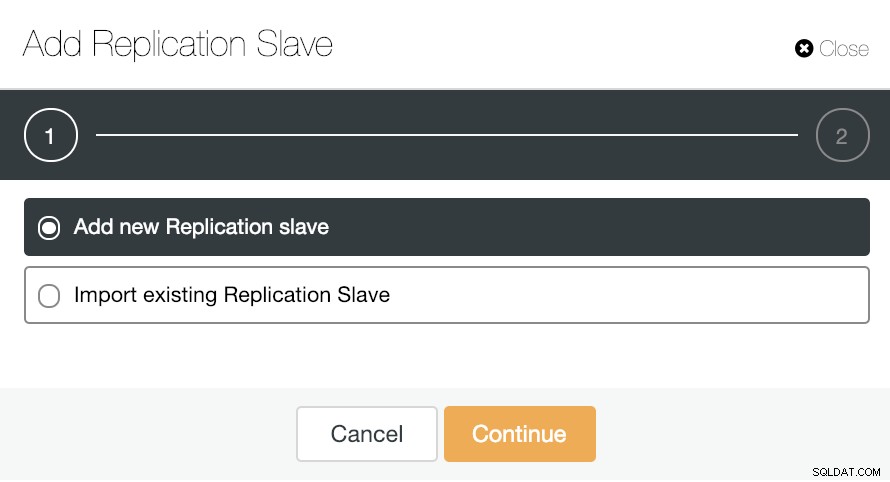
Mal sehen, wie das Hinzufügen eines neuen Replikations-Slaves eine wirklich einfache Aufgabe sein kann.
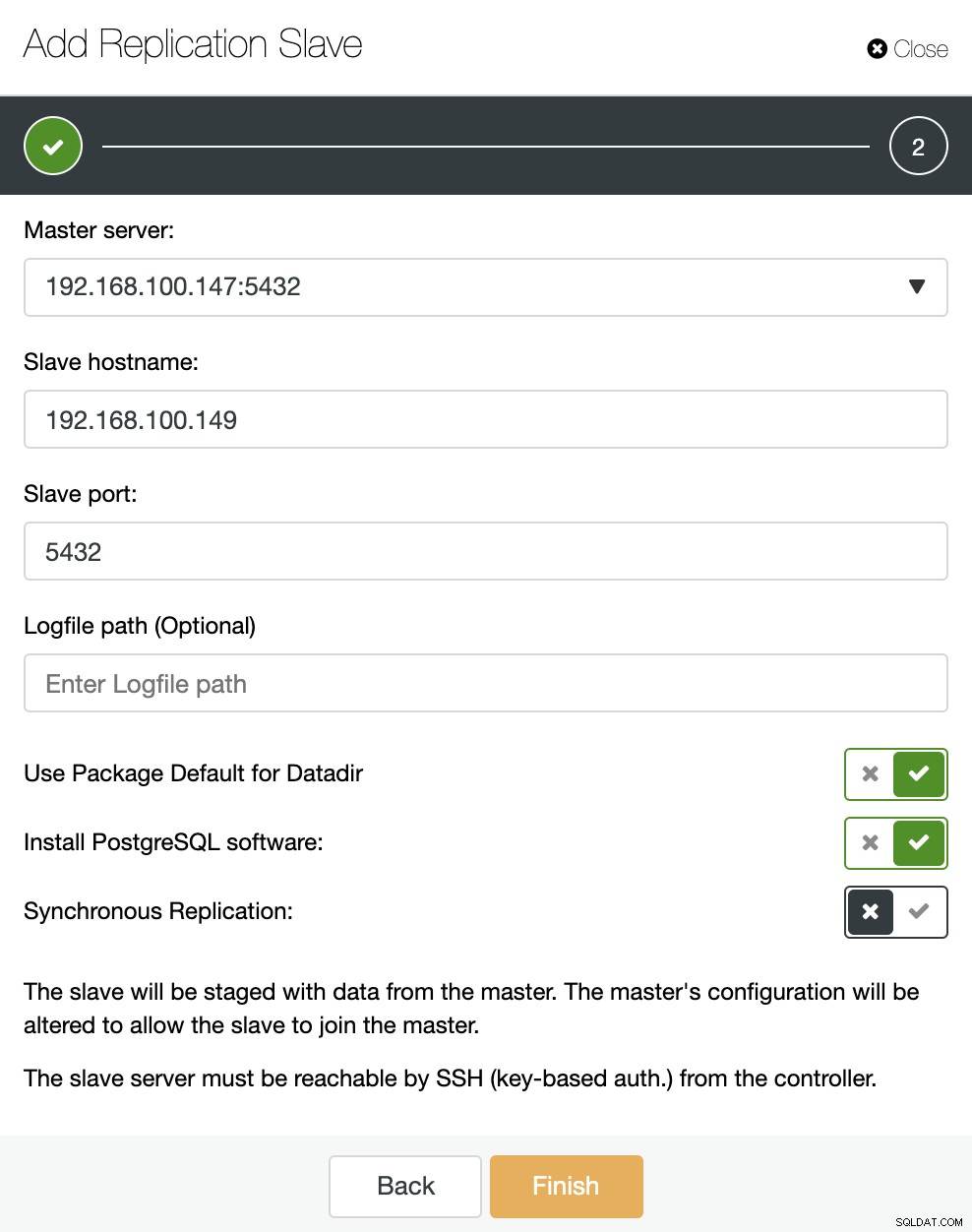
Wie Sie im Bild sehen können, müssen wir nur unseren Master-Server auswählen, die IP-Adresse für unseren neuen Slave-Server und den Datenbank-Port eingeben. Dann können wir wählen, ob ClusterControl die Software für uns installieren soll und ob der Replikations-Slave synchron oder asynchron sein soll.
Auf diese Weise können wir beliebig viele Replikate hinzufügen und den Leseverkehr mithilfe eines Lastenausgleichs verteilen, den wir auch mit ClusterControl implementieren können.
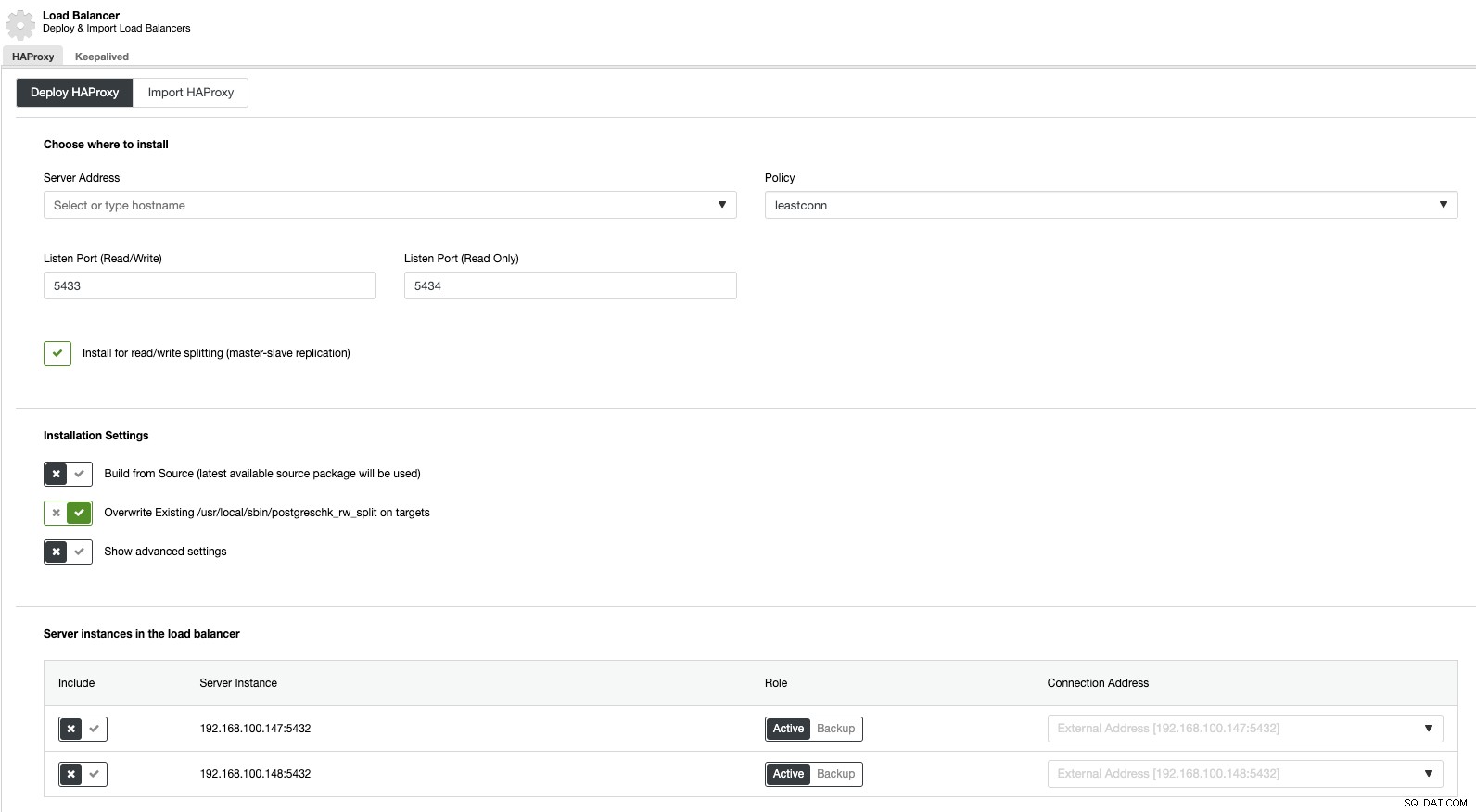
Wenn wir jetzt zu Cluster-Aktionen gehen und „Load Balancer hinzufügen“ auswählen, können wir einen neuen HAProxy Load Balancer bereitstellen oder einen vorhandenen hinzufügen.
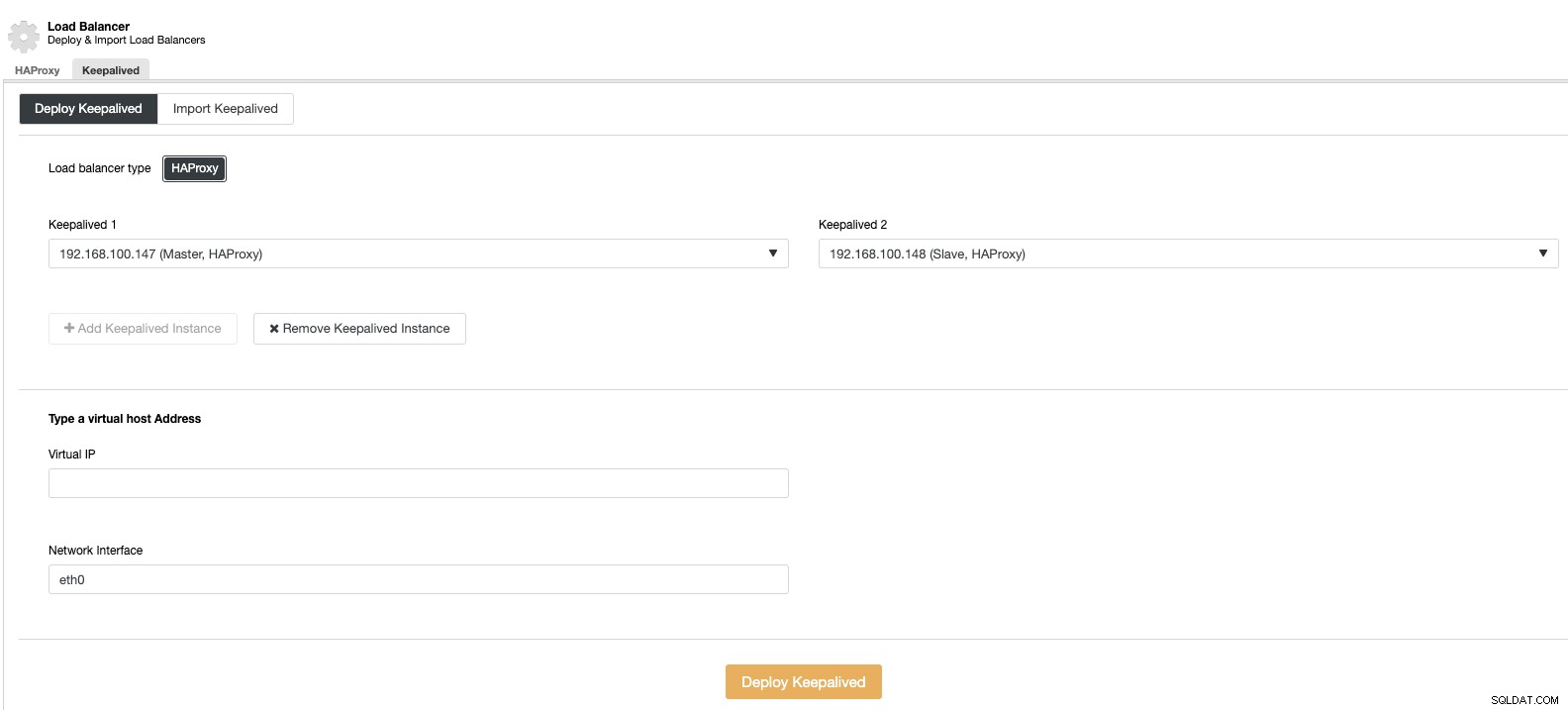
Und dann können wir im selben Load-Balancer-Abschnitt einen Keepalived-Dienst hinzufügen, der auf den Load-Balancer-Knoten läuft, um unsere Hochverfügbarkeitsumgebung zu verbessern.
Vertikale Skalierung
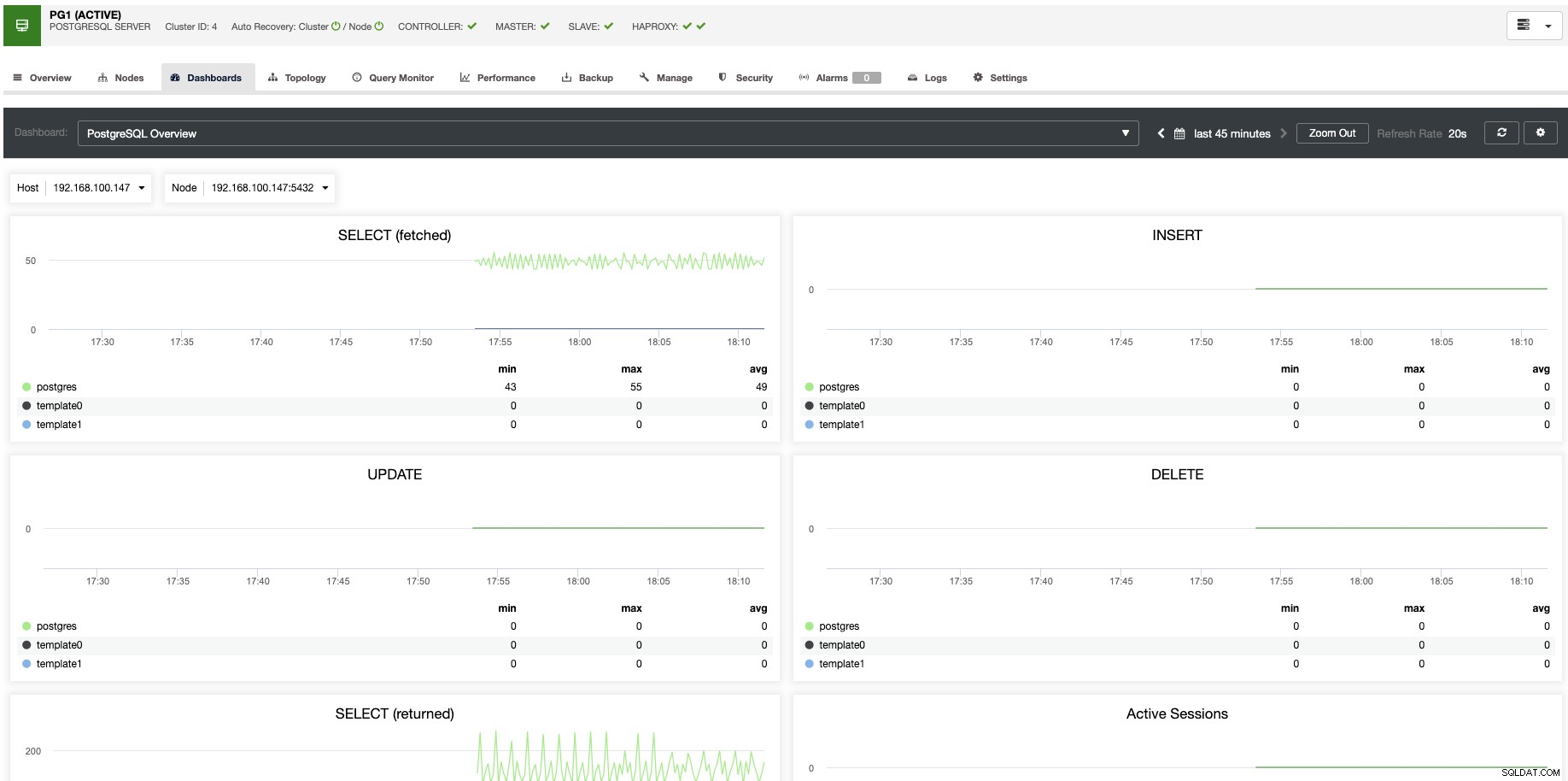
Für die vertikale Skalierung können wir mit ClusterControl unsere Datenbankknoten sowohl von der Betriebssystem- als auch von der Datenbankseite überwachen. Wir können einige Metriken wie CPU-Auslastung, Arbeitsspeicher, Verbindungen, häufigste Abfragen, laufende Abfragen und noch mehr überprüfen. Wir können auch den Dashboard-Bereich aktivieren, der es uns ermöglicht, die Metriken detaillierter und benutzerfreundlicher anzuzeigen.
Von ClusterControl aus können Sie auch verschiedene Verwaltungsaufgaben wie Neustart des Hosts, Rebuild Replication Slave oder Promote Slave mit einem Klick ausführen.
Schlussfolgerung
Das Hochskalieren von PostgreSQL-Datenbanken kann eine zeitaufwändige Aufgabe sein. Wir müssen wissen, was wir skalieren müssen und wie wir es am besten tun. Letztendlich wird die manuelle Verwaltung und Skalierung von Clustern ab einem bestimmten Punkt ziemlich mühsam, sodass sich die meisten Tools wie unserem zuwenden.
Wenn Sie sich für die manuelle Route entscheiden, prüfen Sie, wann Sie erwägen sollten, Ihrem Cluster einen zusätzlichen Knoten hinzuzufügen. Möchten Sie den Ärger vermeiden? Testen Sie ClusterControl 30 Tage lang kostenlos, um zu sehen, wie seine Funktionen den Umgang mit Open Source in großem Umfang einfach und effizient machen.
Wie auch immer Sie Ihre Datenbanken verwalten und skalieren möchten, folgen Sie uns auf Twitter oder LinkedIn oder abonnieren Sie unseren Newsletter, um die neuesten Nachrichten und Best Practices bei der Verwaltung einer Open-Source-basierten Datenbankinfrastruktur zu erhalten, und wir sehen uns bald!