Überwachung ist eine der grundlegenden Aufgaben in jedem System. Es kann uns helfen, Probleme zu erkennen und Maßnahmen zu ergreifen oder einfach den aktuellen Zustand unserer Systeme zu kennen. Die Verwendung visueller Anzeigen kann uns effektiver machen, da wir Leistungsprobleme leichter erkennen können.
In diesem Blog werden wir sehen, wie wir SCUMM verwenden, um unsere PostgreSQL-Datenbanken zu überwachen und welche Metriken wir für diese Aufgabe verwenden können. Wir gehen auch die verfügbaren Dashboards durch, damit Sie leicht herausfinden können, was wirklich mit Ihren PostgreSQL-Instanzen passiert.
Was ist SCUMM?
Lassen Sie uns zunächst sehen, was SCUMM (Severalnines ClusterControl Unified Monitoring and Management) ist.
Es ist eine neue agentenbasierte Lösung mit Agenten, die auf den Datenbankknoten installiert sind.
Die SCUMM-Agenten sind Prometheus-Exporter, die Metriken von Diensten wie PostgreSQL als Prometheus-Metriken exportieren.
Ein Prometheus-Server wird zum Scrapen und Speichern von Zeitreihendaten von den SCUMM-Agenten verwendet.
Prometheus ist ein Open-Source-Toolkit zur Systemüberwachung und -warnung, das ursprünglich bei SoundCloud entwickelt wurde. Es ist jetzt ein eigenständiges Open-Source-Projekt und wird unabhängig gepflegt.
Prometheus ist auf Zuverlässigkeit ausgelegt, um das System zu sein, zu dem Sie während eines Ausfalls gehen, damit Sie Probleme schnell diagnostizieren können.
Wie benutzt man SCUMM?
Wenn wir ClusterControl verwenden, sehen wir bei der Auswahl eines Clusters eine Übersicht unserer Datenbanken sowie einige grundlegende Metriken, die zur Identifizierung eines Problems verwendet werden können. Im unteren Dashboard sehen wir ein Master-Slave-Setup mit einem Master und 2 Slaves, mit HAProxy und Keepalived.
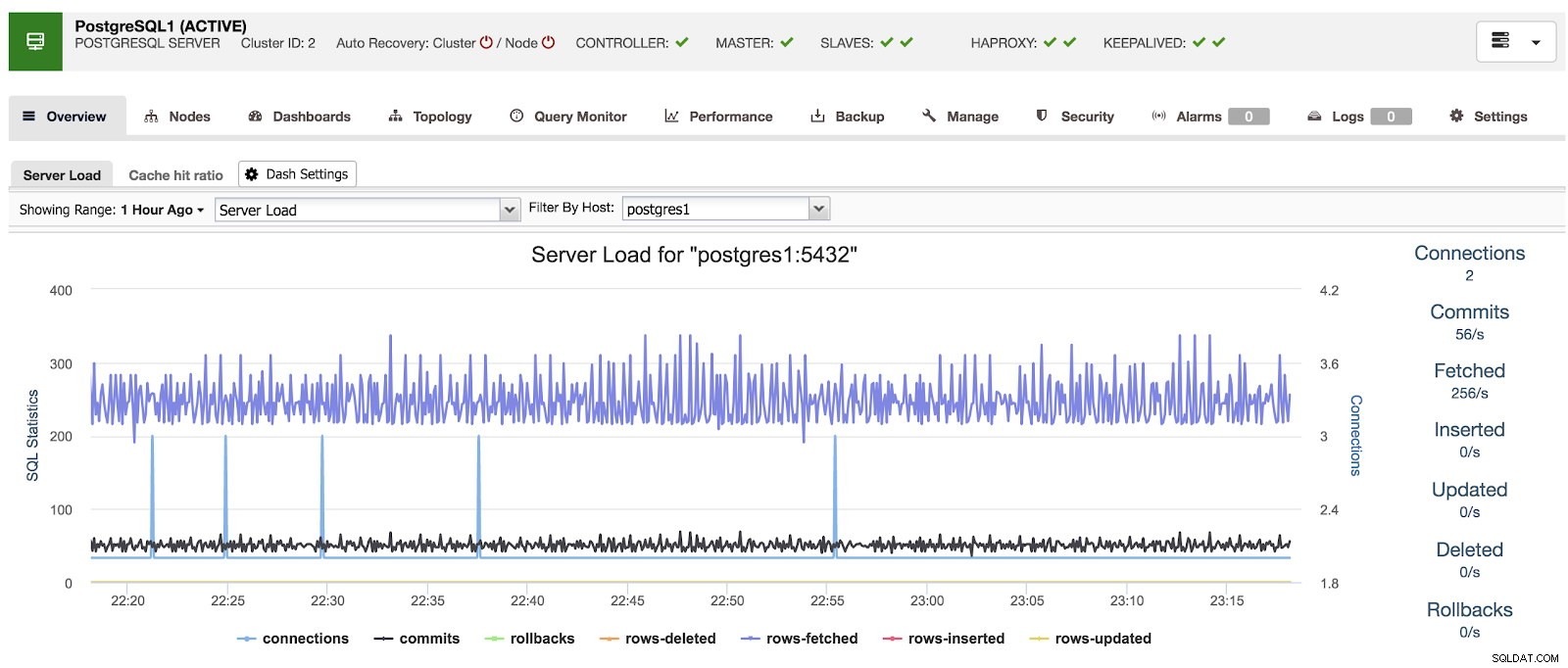 ClusterControl-Übersicht
ClusterControl-Übersicht Wenn wir zur Option „Dashboards“ gehen, sehen wir eine Nachricht wie die folgende.
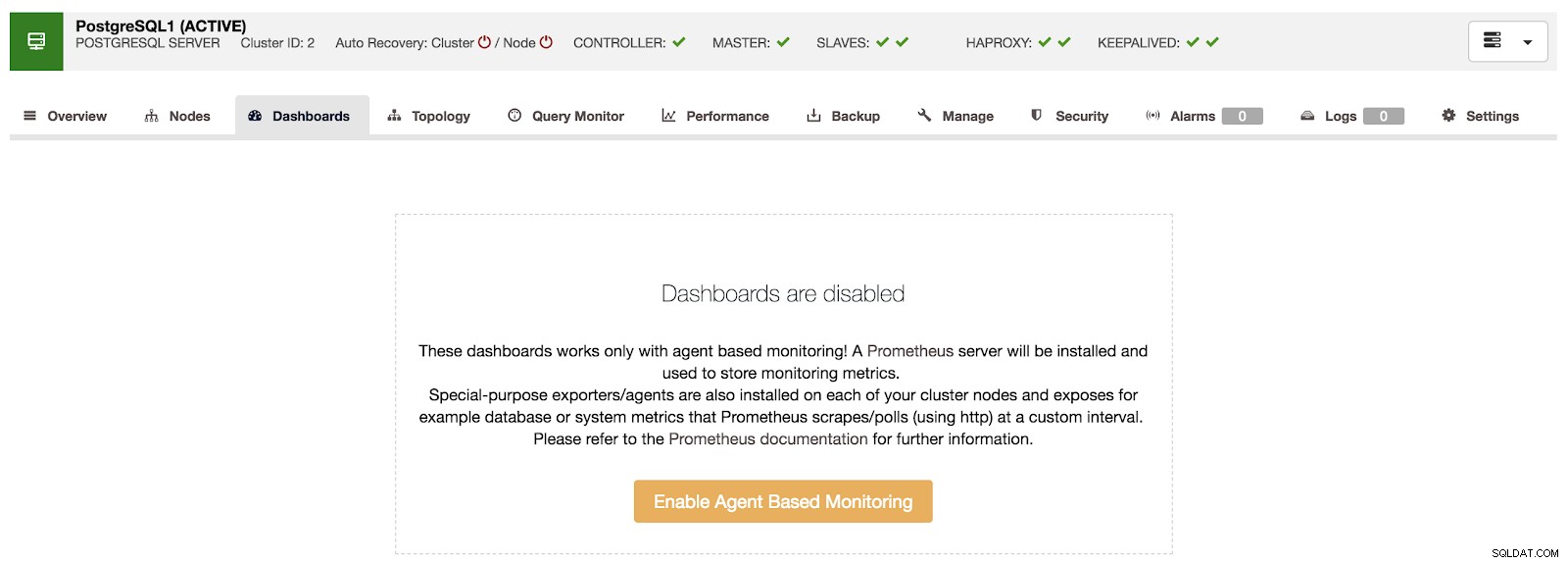 ClusterControl-Dashboards deaktiviert
ClusterControl-Dashboards deaktiviert Um diese Funktion nutzen zu können, müssen wir den oben genannten Agenten aktivieren. Dazu müssen wir in diesem Abschnitt nur auf die Schaltfläche „Enable Agent Based Monitoring“ klicken.
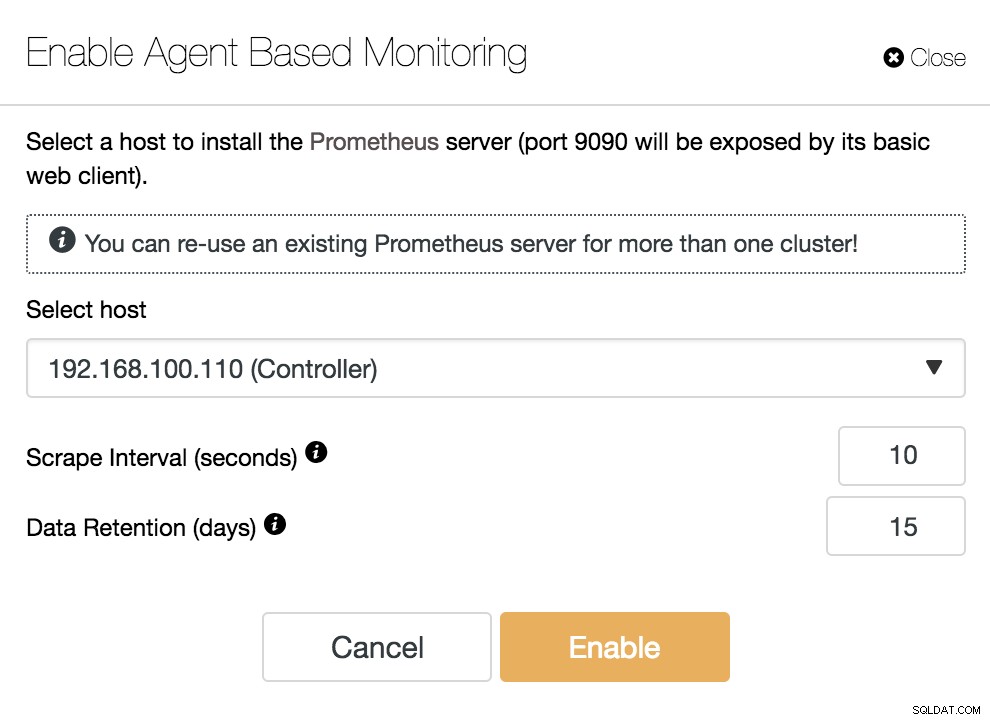 ClusterControl Agentenbasierte Überwachung aktivieren
ClusterControl Agentenbasierte Überwachung aktivieren Um unseren Agenten zu aktivieren, müssen wir den Host angeben, auf dem wir unseren Prometheus-Server installieren, der, wie wir im Beispiel sehen können, unser ClusterControl-Server sein kann.
Wir müssen auch angeben:
- Scrape-Intervall (Sekunden):Legen Sie fest, wie oft die Knoten nach Metriken gescraped werden. Standard ist 10 Sekunden.
- Datenaufbewahrung (Tage):Legen Sie fest, wie lange die Messwerte aufbewahrt werden, bevor sie entfernt werden. Standard ist 15 Tage.
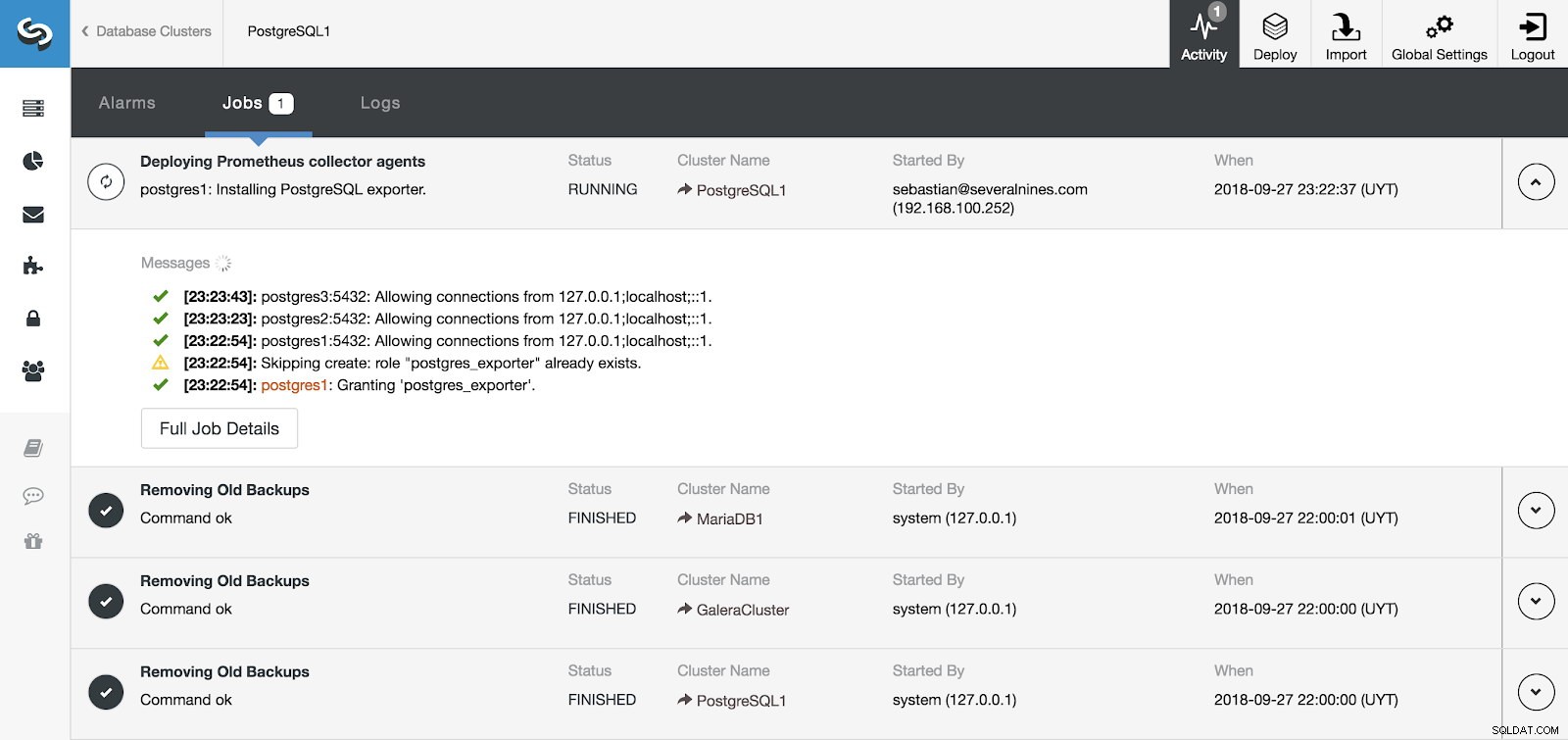 ClusterControl-Aktivitätsabschnitt
ClusterControl-Aktivitätsabschnitt Wir können die Installation unseres Servers und unserer Agenten im Abschnitt „Aktivität“ in ClusterControl überwachen, und sobald sie abgeschlossen ist, können wir unseren Cluster mit den aktivierten Agenten auf dem Hauptbildschirm von ClusterControl sehen.
 ClusterControl-Agents aktiviert
ClusterControl-Agents aktiviert Dashboards
Wenn unsere Agenten aktiviert sind und wir zum Abschnitt Dashboards gehen, sehen wir etwa Folgendes:
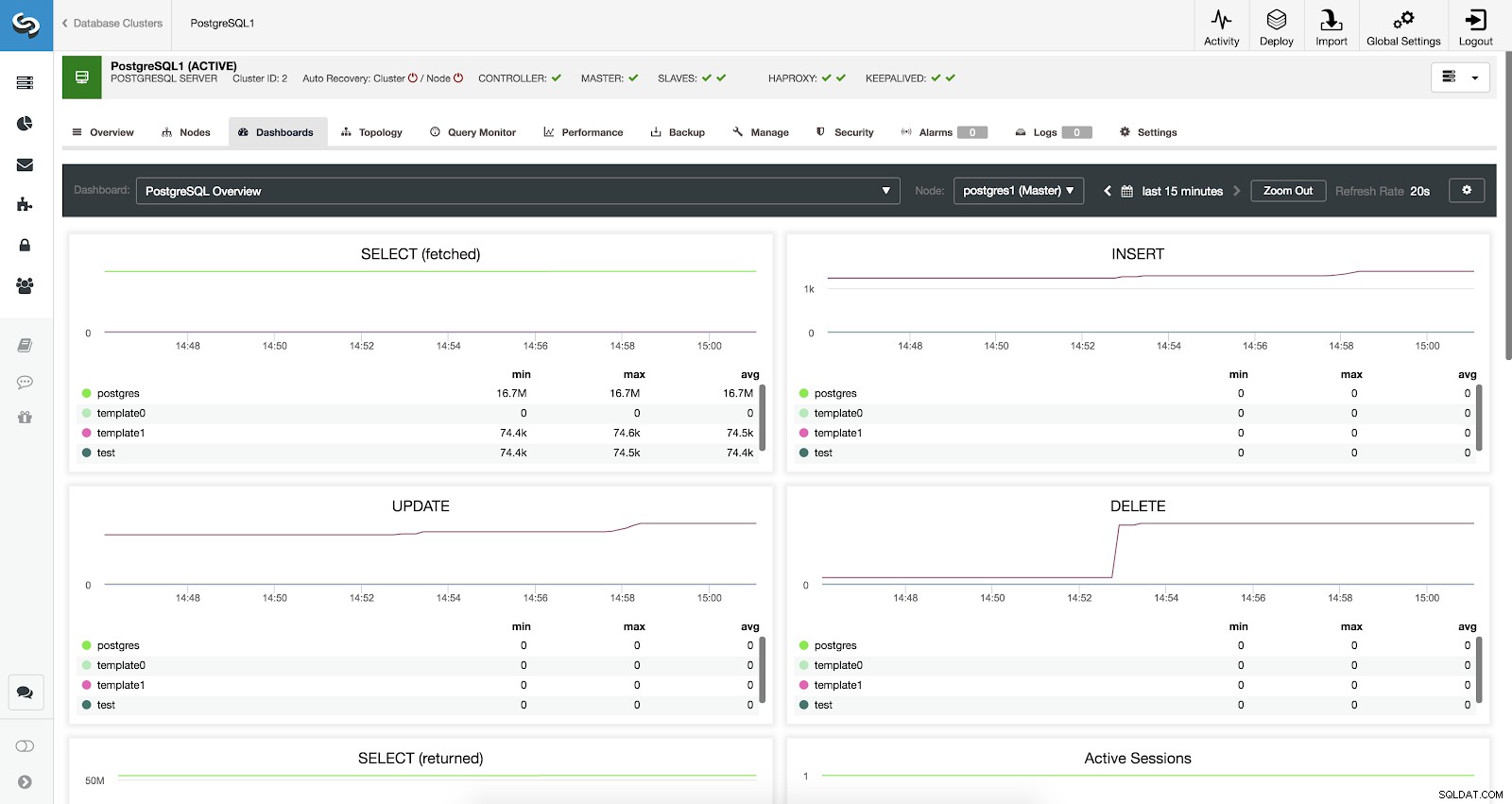 ClusterControl-Dashboards aktiviert
ClusterControl-Dashboards aktiviert Wir haben drei verschiedene Arten von Dashboards zur Verfügung:Systemübersicht, serverübergreifende Diagramme und PostgreSQL-Übersicht. Das letzte ist das, was wir standardmäßig sehen, wenn wir diesen Abschnitt betreten.
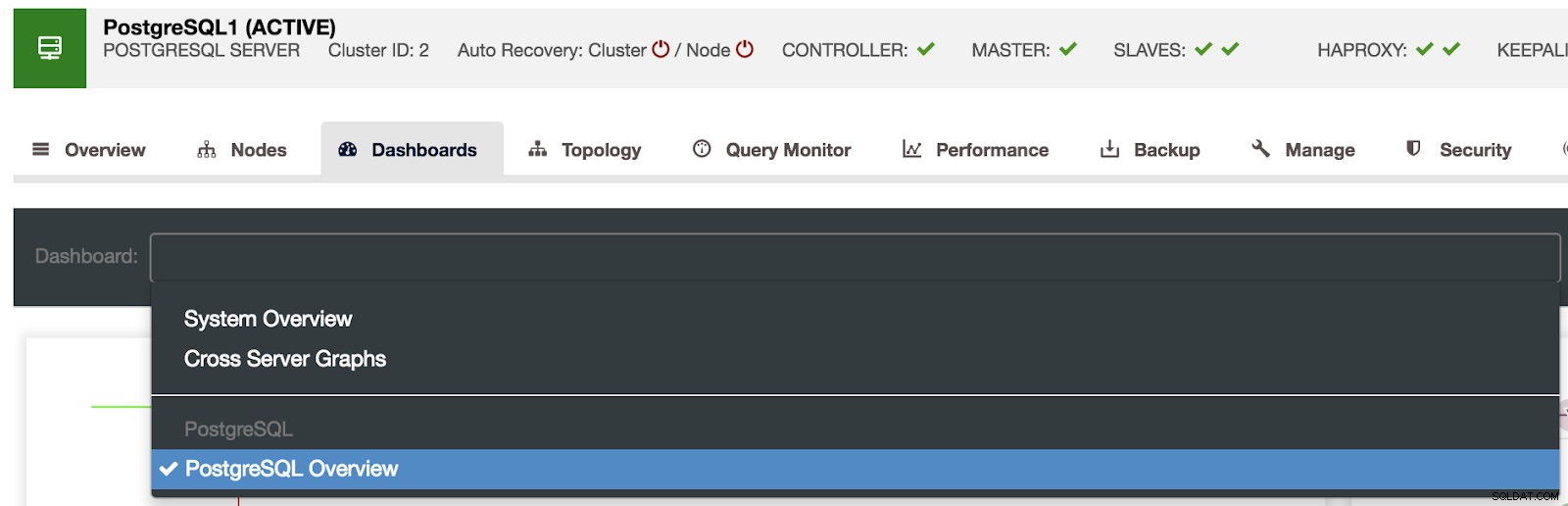 Auswahl der ClusterControl-Dashboards
Auswahl der ClusterControl-Dashboards Hier können wir auch angeben, welcher Knoten überwacht werden soll, den Zeitbereich und die Aktualisierungsrate.
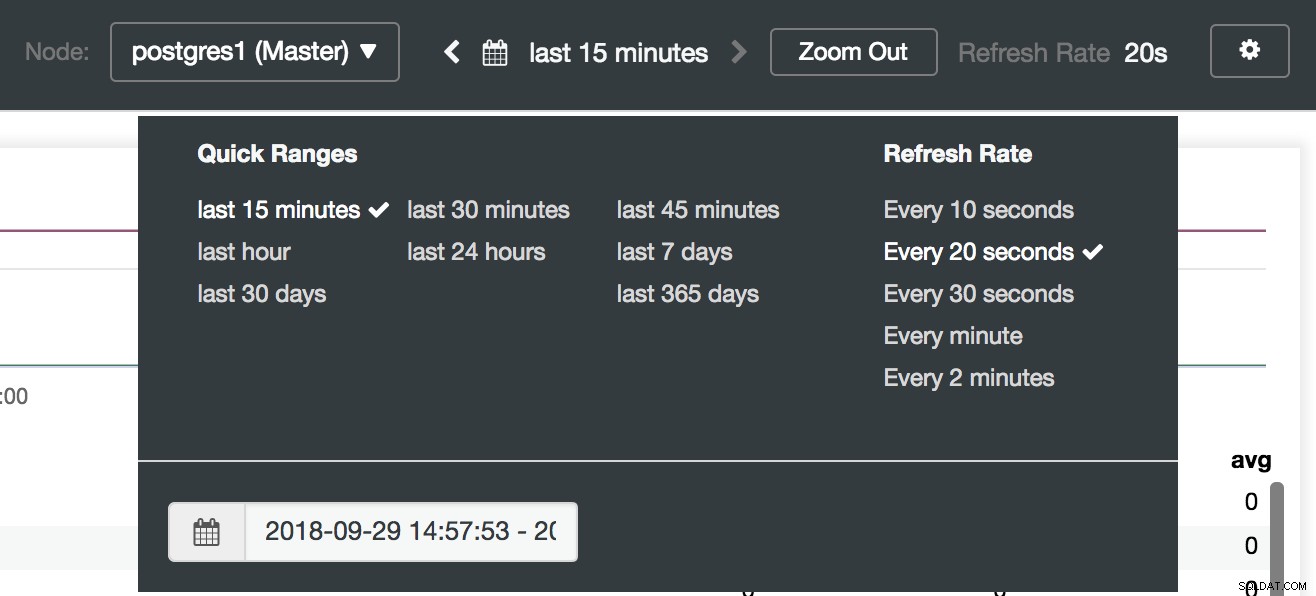 ClusterControl-Dashboard-Optionen
ClusterControl-Dashboard-Optionen Im Konfigurationsabschnitt können wir unsere Agenten (Exporter) aktivieren oder deaktivieren, den Status der Agenten überprüfen und die Version unseres Prometheus-Servers überprüfen.
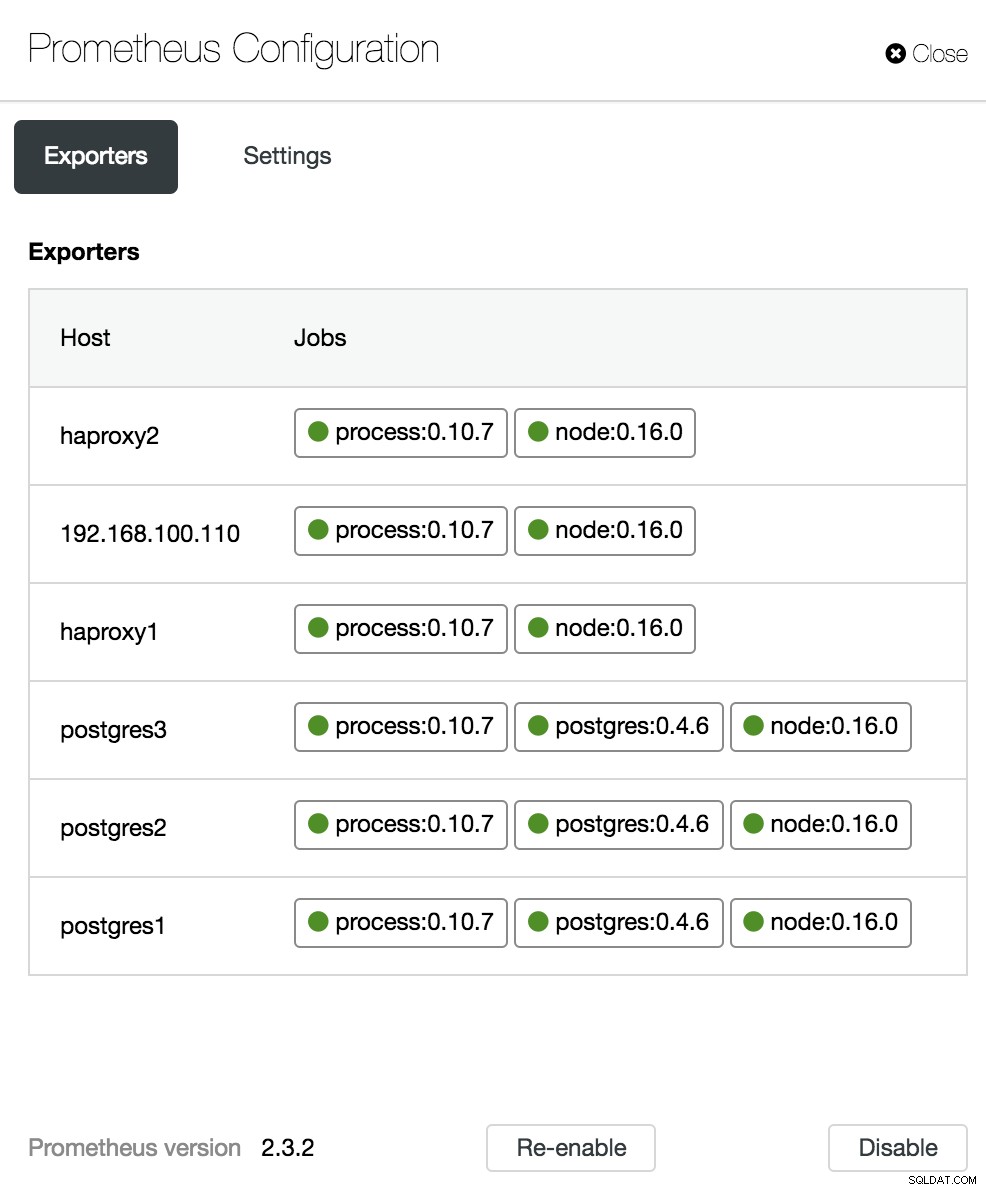 ClusterControl-Dashboard-Konfiguration
ClusterControl-Dashboard-Konfiguration PostgreSQL-Übersichtsmetriken
Sehen wir uns nun an, welche Metriken wir für jede unserer PostgreSQL-Datenbanken zur Verfügung haben (alle für den ausgewählten Knoten).
- SELECT (fetched):Anzahl der ausgewählten (geholten) Zeilen für jede Datenbank. Die abgerufenen Zeilen beziehen sich auf Live-Zeilen, die aus der Tabelle abgerufen wurden.
- SELECT (zurückgegeben):Anzahl der ausgewählten (zurückgegebenen) Zeilen für jede Datenbank. Die zurückgegebenen Zeilen beziehen sich auf alle aus der Tabelle gelesenen Zeilen, einschließlich toter Zeilen und noch nicht festgeschriebener Zeilen (im Gegensatz zu den abgerufenen Zeilen, die nur die aktiven Tupel zählen).
- INSERT:Anzahl der Zeilen, die für jede Datenbank eingefügt wurden.
- UPDATE:Anzahl der aktualisierten Zeilen für jede Datenbank.
- DELETE:Anzahl der Zeilen, die für jede Datenbank gelöscht wurden.
- Aktive Sitzungen:Anzahl aktiver Sitzungen (Min., Max. und Durchschnitt) für jede Datenbank.
- Untätige Sitzungen:Anzahl der untätigen Sitzungen (min., max. und durchschnittlich) für jede Datenbank.
- Sperrtabellen:Anzahl der Sperren (min., max. und durchschnittlich), getrennt nach Typ für jede Datenbank.
- E/A-Auslastung der Festplatte:E/A-Auslastung der Serverfestplatte.
- Festplattennutzung:Prozentsatz der Festplattennutzung des Servers (min., max. und durchschnittlich).
- Datenträgerlatenz:Serverdatenträgerlatenz.
ClusterControl PostgreSQL-Übersichtsmetriken Metriken der Systemübersicht
Um unser System zu überwachen, stehen uns für jeden Server die folgenden Metriken zur Verfügung (alle für den ausgewählten Knoten):
- Systembetriebszeit:Zeit, seit der Server hochgefahren ist.
- CPUs:Anzahl der CPUs.
- RAM:Größe des RAM-Speichers.
- Verfügbarer Speicher:Prozentsatz des verfügbaren RAM-Speichers.
- Durchschnittliche Auslastung:Minimale, maximale und durchschnittliche Serverauslastung.
- Speicher:Verfügbarer, gesamter und verwendeter Serverspeicher.
- CPU-Auslastung:Informationen zur minimalen, maximalen und durchschnittlichen Server-CPU-Auslastung.
- Speicherverteilung:Speicherverteilung (Puffer, Cache, frei und belegt) auf dem ausgewählten Knoten.
- Sättigungsmetriken:Min., Max. und Durchschnitt der E/A-Last und CPU-Last auf dem ausgewählten Knoten.
- Erweiterte Speicherdetails:Speichernutzungsdetails wie Seiten, Puffer und mehr auf dem ausgewählten Knoten.
- Forks:Anzahl der Forks-Prozesse. Fork ist eine Operation, bei der ein Prozess eine Kopie von sich selbst erstellt. Es ist normalerweise ein Systemaufruf, der im Kernel implementiert ist.
- Prozesse:Anzahl der Prozesse, die auf dem Betriebssystem ausgeführt werden oder darauf warten.
- Kontextwechsel:Ein Kontextwechsel ist die Aktion des Speicherns des Status eines Prozesses oder eines Threads.
- Interrupts:Anzahl der Interrupts. Ein Interrupt ist ein Ereignis, das den normalen Ausführungsablauf eines Programms verändert und von Hardwaregeräten oder sogar von der CPU selbst generiert werden kann.
- Netzwerkverkehr:Eingehender und ausgehender Netzwerkverkehr in KByte pro Sekunde auf dem ausgewählten Knoten.
- Stündliche Netzwerkauslastung:Am letzten Tag gesendeter und empfangener Traffic.
- Swap:Swap-Nutzung (frei und verwendet) auf dem ausgewählten Knoten.
- Swap-Aktivität:Liest und schreibt Daten beim Swap.
- I/O-Aktivität:Ein- und Auslagern auf IO.
- Dateideskriptoren:Zugewiesene und begrenzte Dateideskriptoren.
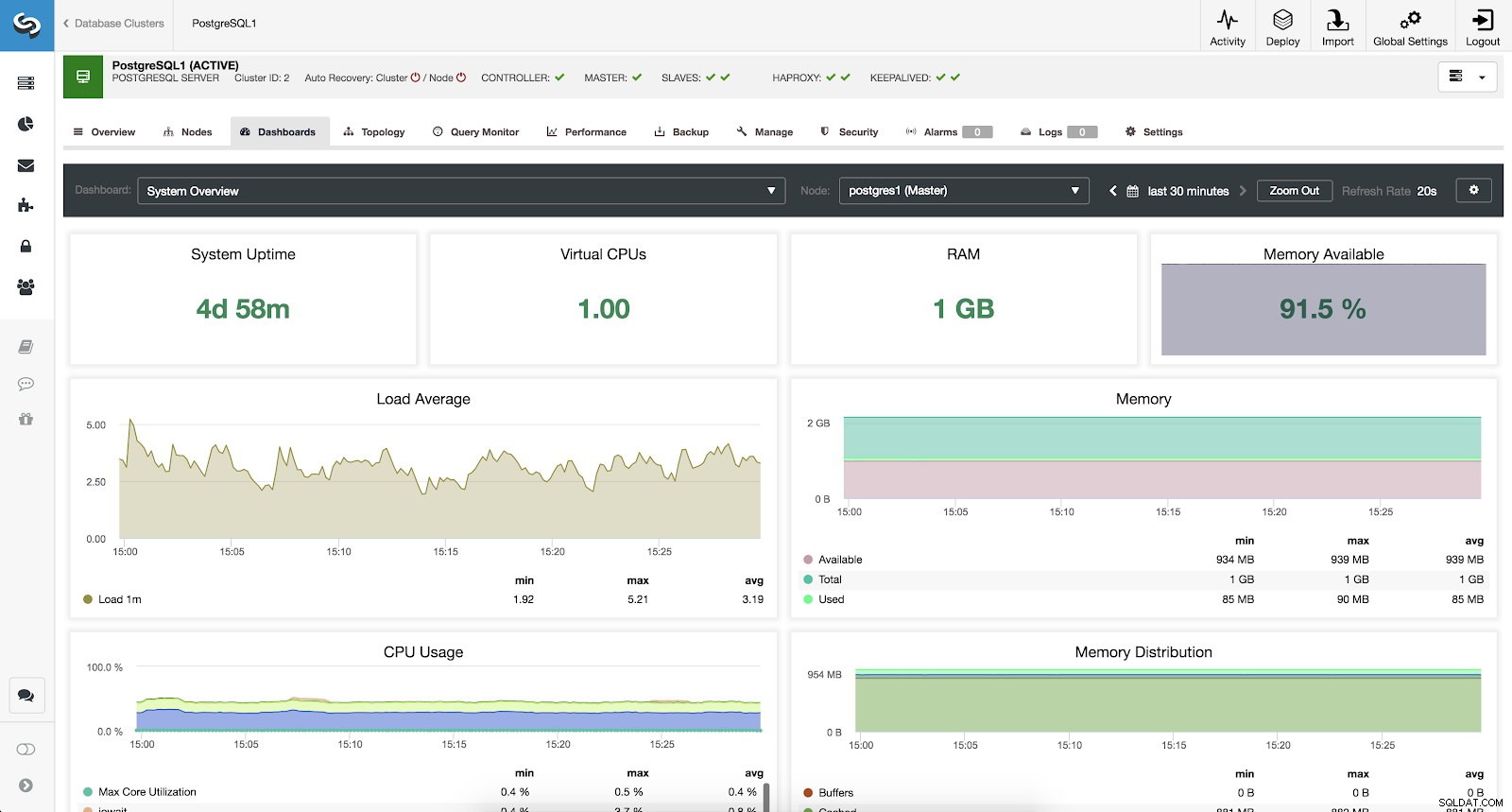 ClusterControl-Systemübersichtsmetriken
ClusterControl-Systemübersichtsmetriken Serverübergreifende Graphs-Metriken
Wenn wir den allgemeinen Zustand aller unserer Server sehen möchten, können wir dieses Dashboard mit den folgenden Metriken verwenden:
- Lastdurchschnitt:Serverlastdurchschnitt für jeden Server.
- Speichernutzung:Prozentsatz der Speichernutzung für jeden Server.
- Netzwerkverkehr:Minimaler, maximaler und durchschnittlicher Netzwerkverkehr in kByte pro Sekunde.
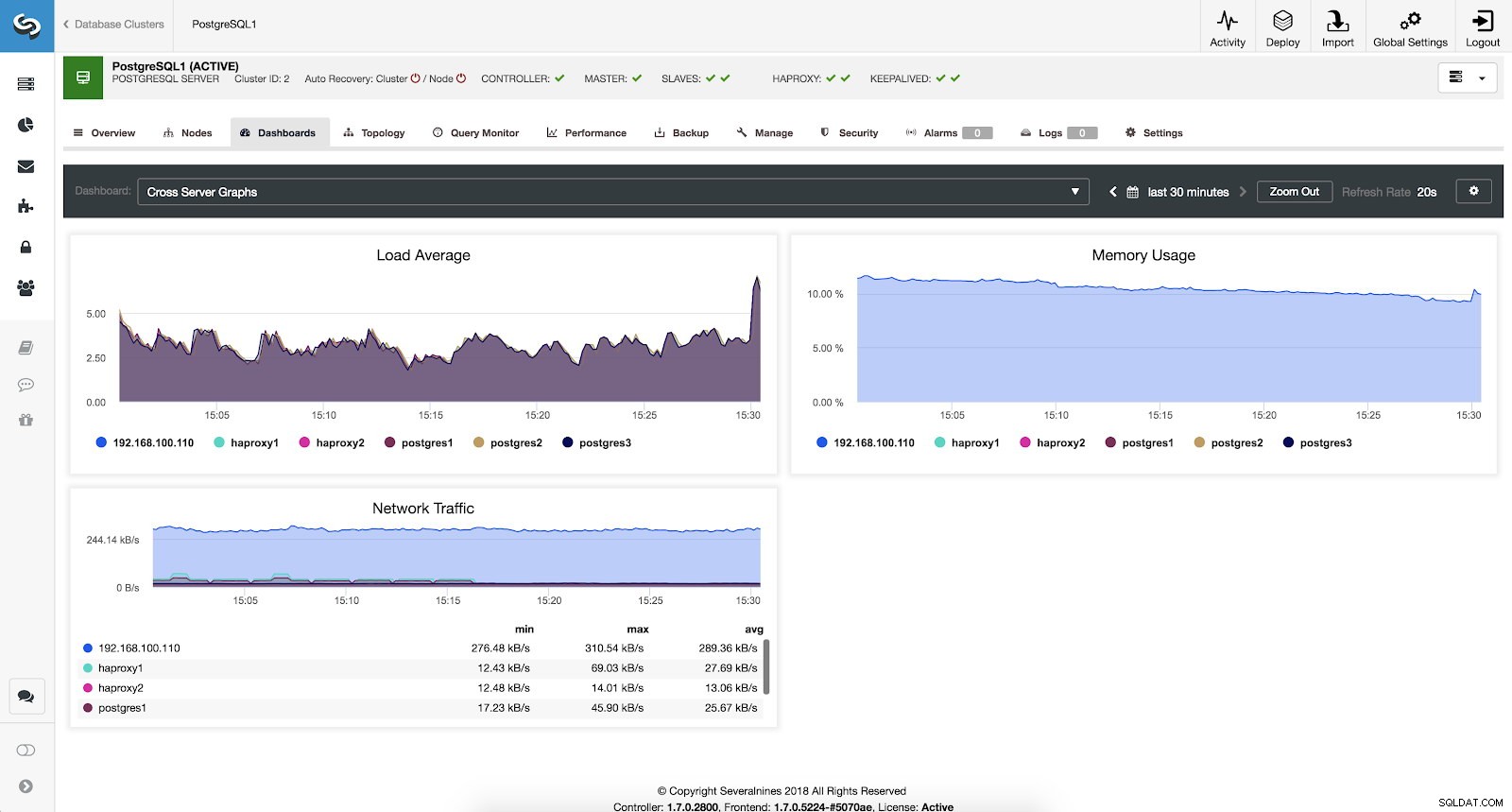 ClusterControl Cross Server Graphs Metriken
ClusterControl Cross Server Graphs Metriken Schlussfolgerung
Es gibt mehrere Möglichkeiten, PostgreSQL zu überwachen. ClusterControl bietet über Prometheus sowohl eine agentenlose als auch jetzt eine agentenbasierte Überwachung. Es bietet Überwachungsdaten mit höherer Auflösung sowie verschiedene Dashboards, um die Datenbankleistung zu verstehen. ClusterControl kann auch mit externen Tools wie Slack oder PagerDuty zur Benachrichtigung integriert werden.



