Beim Bereitstellen eines Datenbank-Clusters auf verschiedenen Servern haben Sie den Replikationsvorteil der verbesserten Datenverfügbarkeit erreicht. Es ist jedoch erforderlich, Prozesse im Auge zu behalten und zu sehen, ob sie ausgeführt werden oder nicht. Eines der in diesem Prozess verwendeten Programme ist Heartbeat, das in der Lage ist, das Vorhandensein von Ressourcen auf einem oder mehreren Systemen in einem bestimmten Cluster zu überprüfen und zu verifizieren. Neben PostgreSQL und den Dateisystemen, für die PostgreSQL-Daten gespeichert werden, ist DRBD eine der Ressourcen, die wir in diesem Artikel darüber diskutieren werden, wie das Heartbeat-Programm verwendet werden kann.
HA-Herzschlag
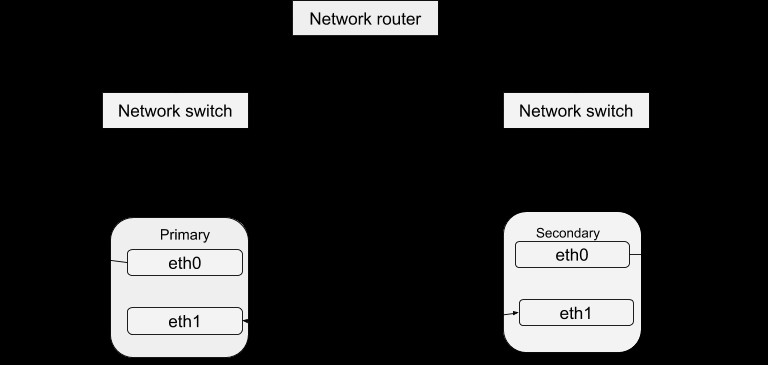
Wie bereits im DRBD-Blog besprochen, wird eine hohe Datenverfügbarkeit dadurch erreicht, dass verschiedene Instanzen des Servers ausgeführt werden, aber dieselben Daten bereitgestellt werden. Diese laufenden Serverinstanzen können in Bezug auf einen Heartbeat als Cluster definiert werden. Grundsätzlich ist jede der Serverinstanzen physisch in der Lage, denselben Dienst wie die anderen innerhalb dieses Clusters bereitzustellen. Es kann jedoch immer nur eine Instanz aktiv Dienste bereitstellen, um eine Hochverfügbarkeit von Daten zu gewährleisten. Wir können daher die anderen Instanzen als „Hot-Spares“ definieren, die bei Ausfall des Masters in Betrieb genommen werden können. Das Heartbeat-Paket kann über diesen Link heruntergeladen werden. Nach der Installation dieses Pakets können Sie es mit dem folgenden Verfahren so konfigurieren, dass es mit Ihrem System funktioniert. Eine einfache Struktur der Heartbeat-Konfiguration ist:
Konfiguration von Heartbeat
Wenn Sie in dieses Verzeichnis /etc/ha.d schauen, finden Sie einige Dateien, die im Konfigurationsprozess verwendet werden. Die ha.cf-Datei bildet die Haupt-Heartbeat-Konfiguration. Es enthält die Liste aller Knoten und Zeiten zum Identifizieren von Fehlern und weist den Heartbeat an, welche Art von Medienpfaden verwendet und wie sie konfiguriert werden sollen. Sicherheitsinformationen für den Cluster werden in der authkeys-Datei aufgezeichnet. Die aufgezeichneten Informationen in diesen Dateien sollten für alle Hosts im Cluster identisch sein, und dies kann leicht durch Synchronisierung über alle Hosts erreicht werden. Das bedeutet, dass jede Informationsänderung in einem Host auf alle anderen kopiert werden sollte.
Ha.cf-Datei
Die Grundstruktur der ha.cf-Datei ist
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Protokollfunktion:Diese wird verwendet, um den Heartbeat anzuweisen, welche Syslog-Protokollierungsfunktion er zum Aufzeichnen von Nachrichten verwenden soll. Die am häufigsten verwendeten Werte sind auth, authpriv, user, local0, syslog und daemon. Sie können auch entscheiden, keine Protokolle zu haben, also können Sie den Wert auf none setzen, d.h.
logfacility none - Keepalive:Dies ist die Zeit zwischen den Heartbeats, dh die Häufigkeit, mit der das Heartbeat-Signal an die anderen Hosts gesendet wird. Im obigen Beispielcode ist sie auf 3 Sekunden festgelegt.
- Totzeit:Dies ist die Verzögerung in Sekunden, nach der ein Knoten als ausgefallen gilt.
- Warnzeit:ist die Verzögerung in Sekunden, nach der eine Warnung in einem Protokoll aufgezeichnet wird, die anzeigt, dass ein Knoten nicht mehr kontaktiert werden kann.
- Initdead:Dies ist die Zeit in Sekunden, die während des Systemstarts gewartet wird, bevor der andere Host als ausgefallen betrachtet wird.
- Mcast:Es ist eine definierte Verfahrensprozedur zum Senden eines Heartbeat-Signals. Für den obigen Beispielcode wird die Multicast-Netzwerkadresse über ein gebundenes Netzwerkgerät verwendet. Bei einem Mehrfach-Cluster muss die Multicast-Adresse für jeden Cluster eindeutig sein. Sie können auch eine serielle Verbindung über den Multicast wählen oder wenn Sie so eingerichtet sind, dass es mehrere Netzwerkschnittstellen gibt, verwenden Sie beide für die Heartbeat-Verbindung wie im Beispiel. Der Vorteil, beide zu verwenden, besteht darin, die Wahrscheinlichkeit eines vorübergehenden Ausfalls zu vermeiden, der folglich ein ungültiges Ausfallereignis verursachen kann.
- Auto_failback:Dies verbindet einen ausgefallenen Server wieder mit dem Cluster, wenn er verfügbar wird. Es kann jedoch zu Verwirrung führen, wenn der Server eingeschaltet wird und dann zu einem anderen Zeitpunkt online geht. In Bezug auf DRBD, wenn es nicht gut konfiguriert ist, könnten Sie am Ende mehr als einen Datensatz auf demselben Server haben. Daher ist es ratsam, es immer auszuschalten.
- Knoten:skizziert den Knoten innerhalb der Heartbeat-Clustergruppe. Sie sollten mindestens 1 Knoten für jeden haben.
Zusätzliche Konfigurationen
Sie können auch zusätzliche Konfigurationsinformationen festlegen wie:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping:Dies ist wichtig, um sicherzustellen, dass Sie eine Verbindung auf der öffentlichen Schnittstelle für die Server und eine Verbindung zu einem anderen Host haben. Es ist wichtig, die IP-Adresse und nicht den Hostnamen für den Zielcomputer zu berücksichtigen.
- Respawn:Dies ist der Befehl, der ausgeführt wird, wenn ein Fehler auftritt.
- Apiauth:ist die Autorität für das Scheitern. Sie müssen die Benutzer- und Gruppen-ID konfigurieren, mit der der Befehl ausgeführt wird. Die authkeys-Datei enthält die Autorisierungsinformationen für das Heartbeat-Cluster und dieser Schlüssel ist sehr einzigartig für die Überprüfung von Computern innerhalb eines bestimmten Heartbeat-Clusters.
- Deadping:definiert die Zeitüberschreitung, bevor eine Nichtantwort einen Fehler auslöst.
Integration von Heartbeat mit Postgres und DRBD
Wie bereits erwähnt, springt ein anderer Server mit einem bestimmten Cluster ein, wenn ein Master-Server ausfällt, um denselben Dienst bereitzustellen. Heartbeat hilft bei der Konfiguration von Ressourcen, die die Auswahl eines Servers im Falle eines Ausfalls verbessern. Es definiert beispielsweise, welche einzelnen Server bei einem Ausfall hochgefahren oder verworfen werden sollen. Beim Einchecken in die Datei haresources im Verzeichnis /etc/ha.d erhalten wir einen Überblick über die Ressourcen, die verwaltet werden können. Der Ressourcendateipfad ist /etc/ha.d/resource.d und die Ressourcendefinition befindet sich in einer Zeile, die lautet:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(beachten Sie die Leerzeichen).
- Drbd1:bezieht sich auf den Namen des bevorzugten Hosts, der besser als der Server ist, der normalerweise als Standard-Master für die Abwicklung des Dienstes verwendet wird. Wie im DRBD-Blog erwähnt, benötigen wir Ressourcen für unseren Server und diese sind in der Zeile als drbddisk, Dateisystem und Postgres definiert. Das letzte Feld ist eine virtuelle IP-Adresse, die verwendet werden sollte, um den Dienst gemeinsam zu nutzen, d. h. eine Verbindung zum Postgres-Server herzustellen. Standardmäßig wird es dem Server zugewiesen, der aktiv ist, wenn der Heartbeat beginnt. Bei einem Ausfall werden diese Ressourcen beim Aufruf des entsprechenden Skripts auf dem Backup-Server der Reihe nach gestartet. In der Einstellung schaltet das Skript die DRBD-Festplatte auf dem sekundären Host in den primären Modus, sodass das Gerät lesen/schreiben kann.
- Dateisystem:Dies verwaltet die Dateisystemressourcen und in diesem Fall wurde das DRBD ausgewählt, damit es während des Aufrufs des Ressourcenskripts gemountet wird.
- Postgres:Dadurch wird der Postgres-Server entweder gestartet oder verwaltet
Manchmal möchten Sie Benachrichtigungen per E-Mail erhalten. Fügen Sie dazu diese Zeile in die Ressourcendatei mit Ihrer E-Mail für den Erhalt der Warntexte ein:
MailTo:: example@sqldat.com::DRBDFailureUm den Heartbeat zu starten, können Sie den Befehl
ausführen/etc/ha.d/heartbeat startoder starten Sie sowohl den primären als auch den sekundären Server neu. Wenn Sie jetzt den Befehl ausführen
$ /usr/lib64/heartbeat/hb_standbyDer aktuelle Knoten wird veranlasst, seine Ressourcen sauber an den anderen Knoten abzugeben.
Laden Sie noch heute das Whitepaper PostgreSQL-Verwaltung und -Automatisierung mit ClusterControl herunterErfahren Sie, was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunterBehandlung von Fehlern auf Systemebene
Manchmal ist der Server-Kernel möglicherweise beschädigt, was auf ein potenzielles Problem mit Ihrem Server hinweist. Sie müssen den Server so konfigurieren, dass er sich im Falle eines Problems selbst aus dem Cluster entfernt. Dieses Problem wird oft als Kernel Panic bezeichnet und löst folglich einen harten Neustart auf Ihrem Computer aus. Sie können einen Neustart erzwingen, indem Sie die Kernel.panic und kernel.panic_on_oop der Kernel-Steuerdatei /etc/sysctl.conf setzen. Dh
kernel.panic_on_oops = 1
kernel.panic = 1Eine andere Möglichkeit besteht darin, dies über die Befehlszeile mit dem Befehl sysctl zu tun, z. B.:
$ sysctl -w kernel.panic=1Sie können auch die Datei sysctl.conf bearbeiten und die Konfigurationsinformationen mit diesem Befehl neu laden.
sysctl -pDer Wert gibt die Anzahl der Sekunden an, die vor dem Neustart gewartet werden soll. Der zweite Heartbeat-Knoten sollte dann erkennen, dass der Server ausgefallen ist, und dann den Failover-Host umschalten.
Schlussfolgerung
Heartbeat ist ein Subsystem, das die Auswahl eines sekundären Servers in ein primäres und ein Backup-System ermöglicht, wenn ein aktiver Server ausfällt. Es bestimmt auch, ob alle anderen Server am Leben sind. Es stellt auch die Übertragung von Ressourcen auf den neuen primären Knoten sicher