Einführung
Hohe Verfügbarkeit ist heutzutage eine Anforderung an viele Systeme, egal welche Technologie Sie verwenden. Dies ist besonders wichtig für Datenbanken, da sie Daten speichern, auf die kritische Anwendungen und Systeme angewiesen sind. Die gebräuchlichste Strategie zum Erreichen einer hohen Verfügbarkeit ist die Replikation. Es gibt verschiedene Möglichkeiten, Daten über mehrere Server und Failover-Datenverkehr zu replizieren, wenn beispielsweise ein primärer Server nicht mehr antwortet.
Hochverfügbarkeitsarchitektur für PostgreSQL
Es gibt mehrere Architekturen zur Implementierung von Hochverfügbarkeit in PostgreSQL, aber die grundlegenden sind Primär-Standby- und Primär-Primär-Architekturen.
Primär-Standby-Architekturen
Primary-Standby ist möglicherweise die grundlegendste HA-Architektur, die Sie einrichten können, und häufig am einfachsten zu implementieren und zu warten. Es basiert auf einer primären Datenbank mit einem oder mehreren Standby-Servern. Diese Standby-Datenbanken bleiben mit dem primären Knoten synchronisiert (oder nahezu synchronisiert), je nachdem, ob die Replikation synchron oder asynchron ist. Wenn der primäre Server ausfällt, enthält der Standby-Server fast alle Daten des primären Servers und kann schnell in den neuen primären Datenbankserver umgewandelt werden.
Sie können zwei Arten von Standby-Datenbanken implementieren, basierend auf der Art der Replikation:
- Logische Standbys – Die Replikation zwischen Primary und Standby erfolgt über SQL-Anweisungen.
- Physical Standbys – Die Replikation zwischen Primary und Standby erfolgt über die internen Änderungen der Datenstruktur.
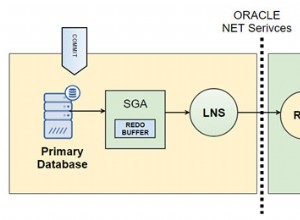
Bei PostgreSQL wird ein Stream von Write-Ahead-Log-Einträgen (WAL) verwendet, um die Standby-Datenbanken synchron zu halten. Dies kann synchron oder asynchron sein, und der gesamte Datenbankserver wird repliziert.
Ab Version 10 enthält PostgreSQL eine integrierte Option zum Einrichten der logischen Replikation, die einen Strom logischer Datenänderungen aus den Informationen im Write-Ahead-Protokoll erstellt. Mit dieser Replikationsmethode können die Datenänderungen aus einzelnen Tabellen repliziert werden, ohne dass ein primärer Server bestimmt werden muss. Außerdem können Daten in mehrere Richtungen fließen.
Leider reicht ein Primary-Standby-Setup nicht aus, um eine hohe Verfügbarkeit effektiv sicherzustellen, da Sie auch Ausfälle handhaben müssen. Um mit Fehlern umgehen zu können, müssen Sie in der Lage sein, sie zu erkennen. Sobald Sie wissen, dass ein Fehler vorliegt, z. B. Fehler auf dem primären Knoten oder der Knoten antwortet nicht, können Sie einen Standby-Knoten auswählen, um den ausgefallenen Knoten mit der geringstmöglichen Verzögerung zu ersetzen. Dieser Prozess muss so effizient wie möglich sein, um die volle Funktionalität der Anwendungen wiederherzustellen. PostgreSQL selbst enthält keinen automatischen Failover-Mechanismus, daher sind für diese Automatisierung einige benutzerdefinierte Skripte oder Tools von Drittanbietern erforderlich.
Nach einem Failover muss Ihre Anwendung entsprechend benachrichtigt werden, damit sie mit der Verwendung des neuen primären Servers beginnen kann. Sie müssen auch den Zustand Ihrer Architektur nach dem Failover bewerten, da Sie in eine Situation geraten können, in der nur der neue primäre Knoten ausgeführt wird (z. B. hatten Sie vor dem Problem einen primären Knoten und nur einen Standby-Knoten). In diesem Fall müssen Sie einen Standby-Knoten hinzufügen, um die Primär-Standby-Konfiguration wiederherzustellen, die Sie ursprünglich für Hochverfügbarkeit hatten.
Primär-Primär-Architekturen
Primär-Primär-Architektur bietet eine Möglichkeit, die Auswirkungen eines Fehlers auf einen der Knoten zu minimieren, da der/die andere(n) Knoten den gesamten Datenverkehr übernehmen kann und die Leistung möglicherweise nur geringfügig beeinträchtigt aber nie an Funktionalität verlieren. Primär-Primär-Architektur wird häufig mit dem doppelten Zweck verwendet, eine Hochverfügbarkeitsumgebung zu erstellen und horizontal zu skalieren (im Vergleich zum Konzept der vertikalen Skalierbarkeit, bei der Sie einem Server mehr Ressourcen hinzufügen).
PostgreSQL unterstützt diese Architektur noch nicht "nativ", daher müssen Sie auf Tools und Implementierungen von Drittanbietern zurückgreifen. Bei der Auswahl einer Lösung müssen Sie bedenken, dass es viele Projekte/Tools gibt, von denen einige jedoch nicht mehr unterstützt werden, während andere neu sind und möglicherweise nicht kampferprobt in der Produktion sind.
Lastenausgleich
Load-Balancer sind Tools, mit denen Sie den Datenverkehr Ihrer Anwendung verwalten können, um Ihre Datenbankarchitektur optimal zu nutzen.
Diese Tools sind nicht nur hilfreich, um die Last Ihrer Datenbanken auszugleichen, sondern sie helfen auch dabei, Anwendungen auf die verfügbaren/fehlerfreien Knoten umzuleiten und sogar Ports mit unterschiedlichen Rollen anzugeben.
HAProxy ist ein Load Balancer, der den Datenverkehr von einem Ursprung zu einem oder mehreren Zielen verteilt und für diese Aufgabe spezifische Regeln und/oder Protokolle definieren kann. Wenn eines der Ziele nicht mehr reagiert, wird es als offline markiert und der Datenverkehr wird an die restlichen verfügbaren Ziele gesendet.
Keepalived ist ein Dienst, mit dem Sie eine virtuelle IP-Adresse innerhalb einer Aktiv/Passiv-Gruppe von Servern konfigurieren können. Diese virtuelle IP-Adresse wird einem aktiven Server zugewiesen. Wenn dieser Server ausfällt, wird die IP-Adresse automatisch auf den „sekundären“ passiven Server migriert, sodass dieser auf für die Systeme transparente Weise mit derselben IP-Adresse weiterarbeiten kann.
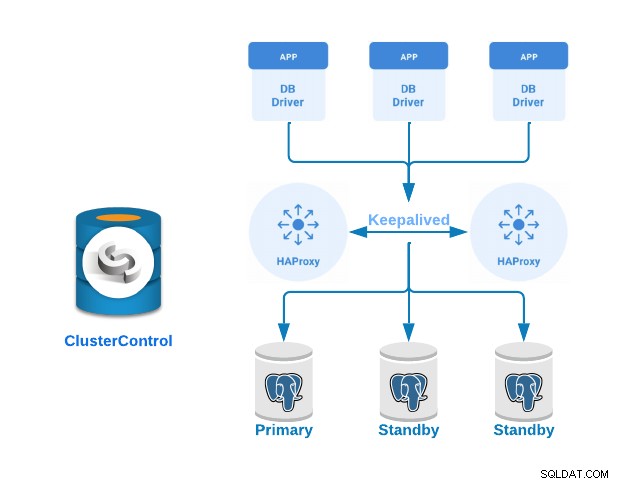
Lassen Sie uns nun sehen, wie ein Primär-Standby-PostgreSQL-Cluster mit Load-Balancer-Servern implementiert und dazwischen konfiguriert Keepalived wird. Wir demonstrieren dies anhand der benutzerfreundlichen Oberfläche von ClusterControl.
Für dieses Beispiel erstellen wir:
- 3 PostgreSQL-Server (ein primärer und zwei Standby-Server).
- 2 HAProxy Load Balancer.
- Keepalived bleibt zwischen den Load-Balancer-Servern konfiguriert.
Datenbankbereitstellung
Um eine Datenbank mit ClusterControl bereitzustellen, wählen Sie einfach die Option „Bereitstellen“ und folgen Sie den angezeigten Anweisungen.
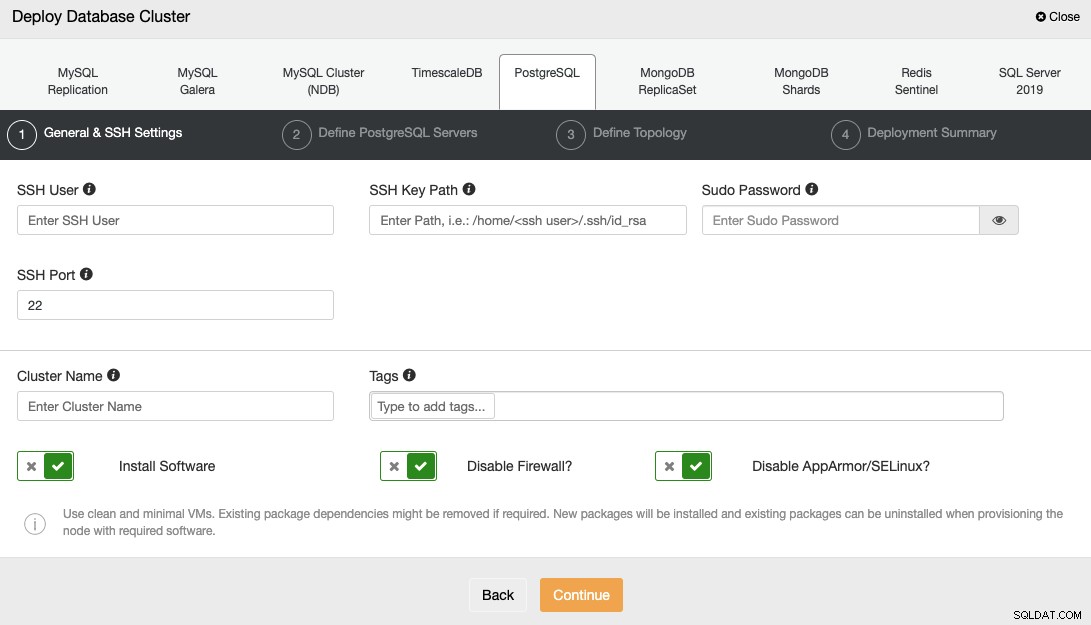
Bei der Auswahl von PostgreSQL müssen Sie den Benutzer, den Schlüssel oder das Passwort und angeben Port für die Verbindung per SSH mit Ihren Servern. Sie benötigen auch den Namen für Ihren neuen Cluster und wählen, ob ClusterControl die entsprechende Software und Konfigurationen für Sie installieren soll.
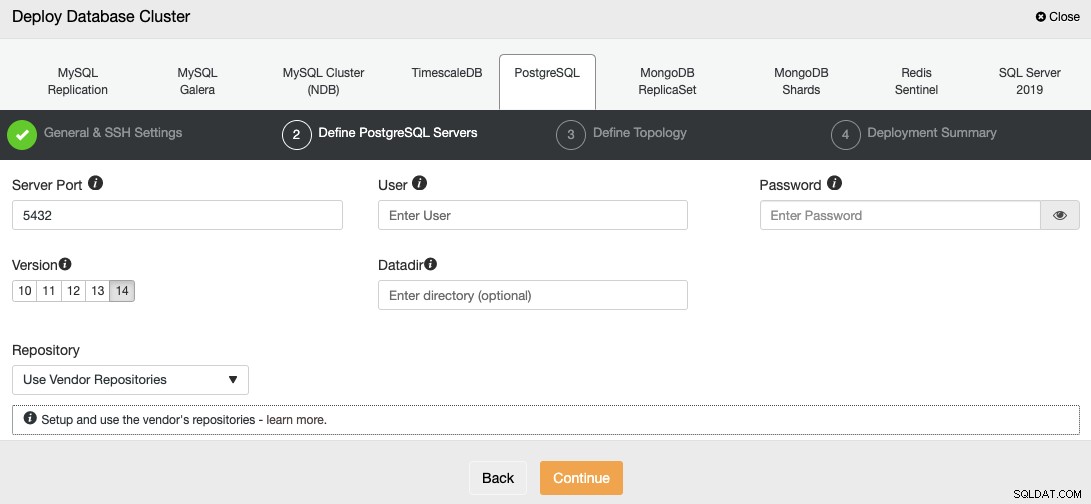
Nachdem Sie die SSH-Zugangsdaten eingerichtet haben, müssen Sie den Datenbankbenutzer definieren, version und datadir (optional). Sie können auch angeben, welches Repository verwendet werden soll; standardmäßig wird das offizielle Anbieter-Repository verwendet.
Im nächsten Schritt müssen Sie Ihre Server zu dem Cluster hinzufügen, den Sie erstellen werden.
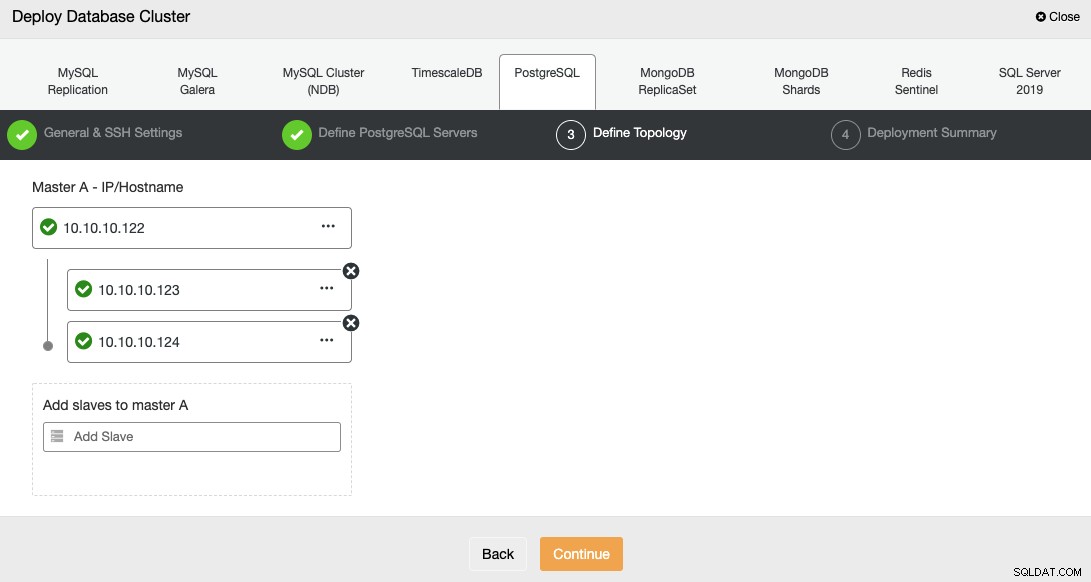
Wenn Sie Ihre Server hinzufügen, können Sie die IP oder den Hostnamen eingeben.
Im letzten Schritt können Sie wählen, ob Ihre Replikation synchron oder asynchron sein soll.
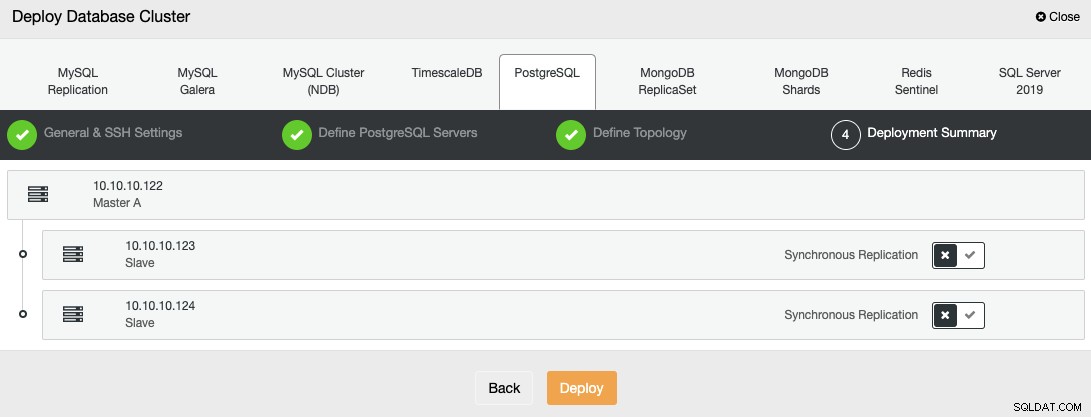
Sie können den Status der Erstellung Ihres neuen Clusters über ClusterControl überwachen Aktivitätsmonitor.
Sobald die Aufgabe abgeschlossen ist, können Sie Ihren Cluster im Haupt-ClusterControl sehen Bildschirm.
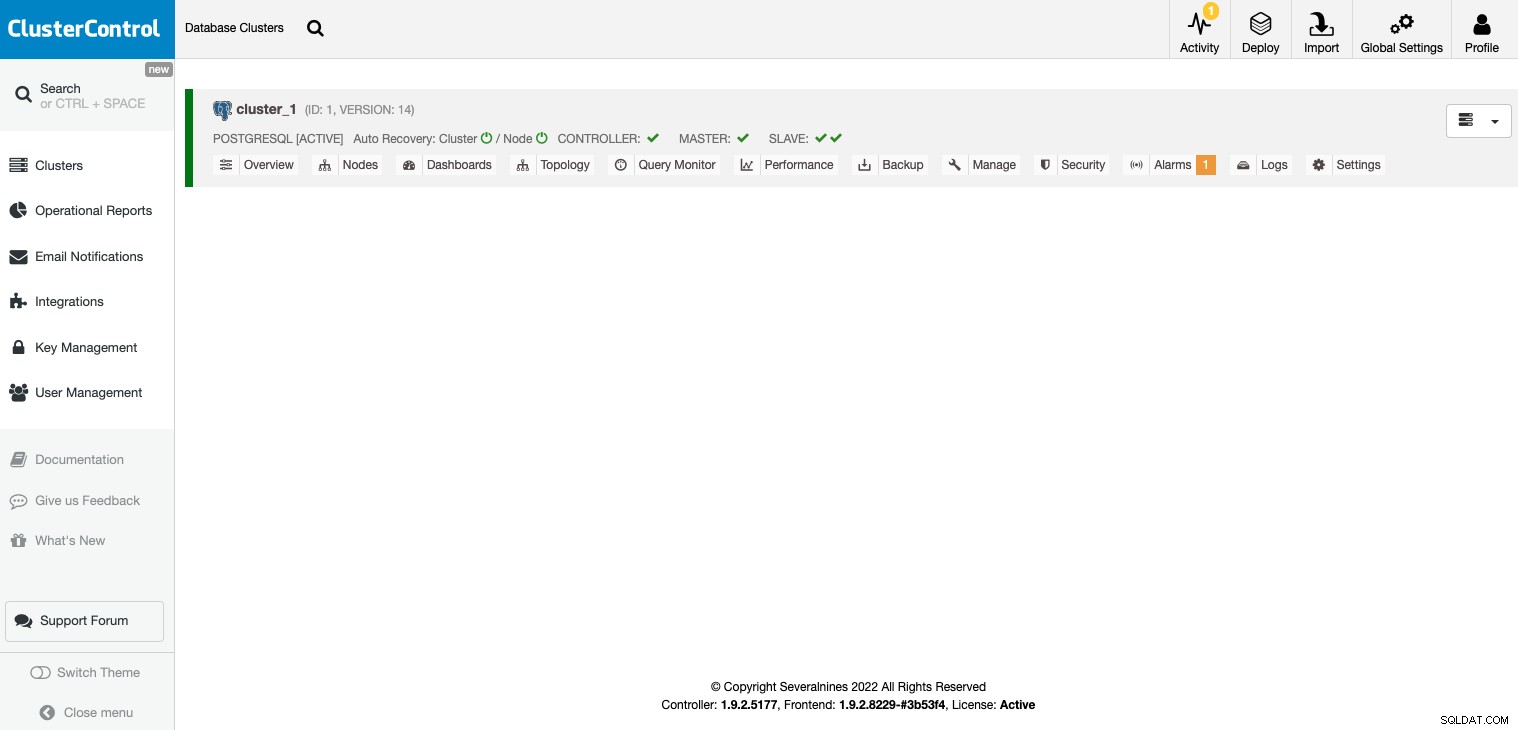
Sobald Ihr Cluster erstellt ist, können Sie verschiedene Aufgaben ausführen, wie z Load Balancer (HAProxy) oder ein neues Replikat.
Load-Balancer-Bereitstellung
Um eine Load-Balancer-Bereitstellung durchzuführen, wählen Sie die Option „Load-Balancer hinzufügen“ in den Cluster-Aktionen und geben Sie die angeforderten Informationen ein.
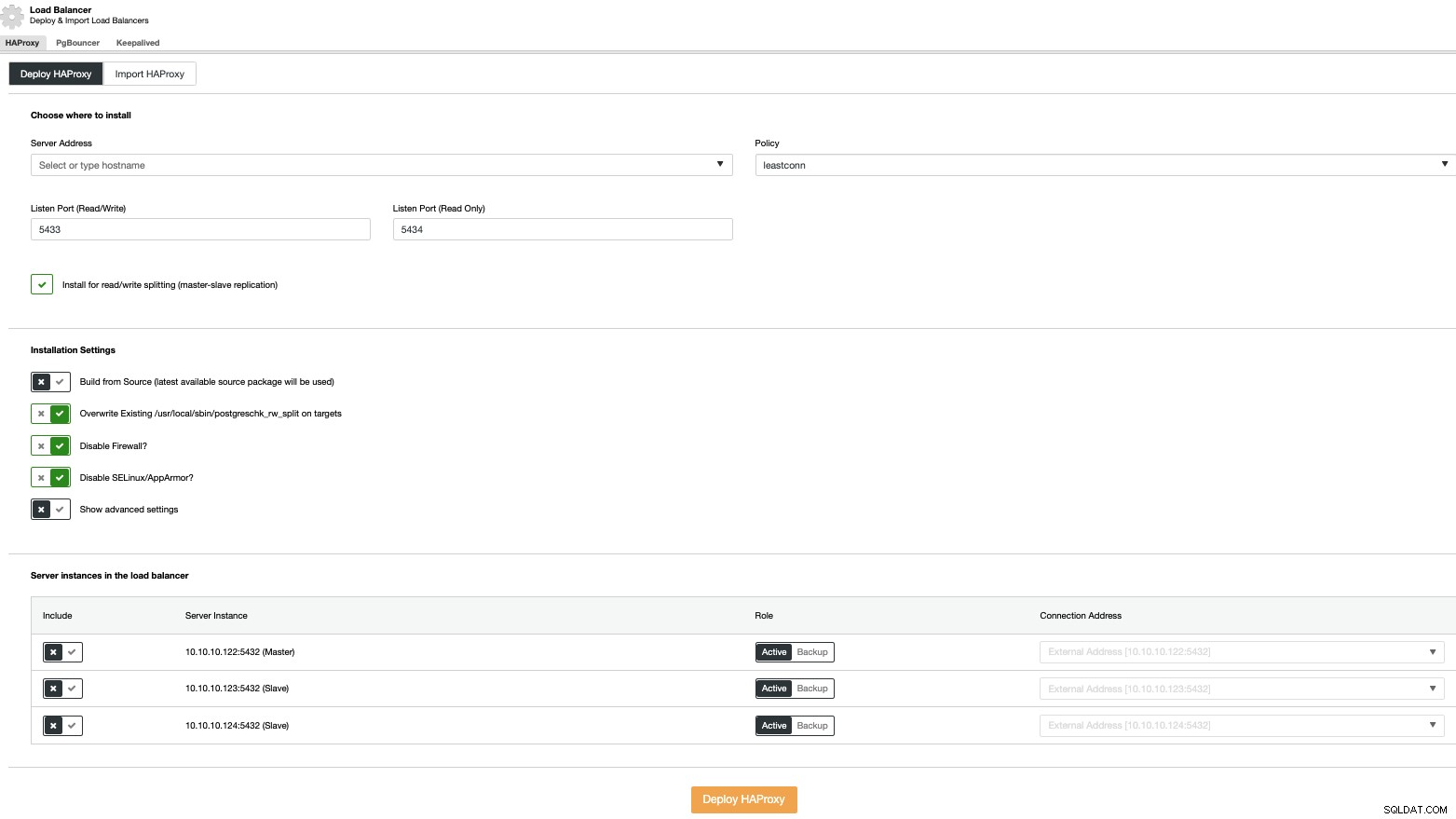
Sie müssen nur die IP-Adresse oder den Hostnamen, den Port, die Richtlinie, und die Knoten, die Sie in Ihren Load Balancern konfigurieren werden.
Keepalived-Bereitstellung
Um eine Keepalive-Bereitstellung durchzuführen, wählen Sie den Cluster aus, gehen Sie zum Menü „Verwalten“ und zum Abschnitt „Load Balancer“ und wählen Sie dann die Option „Keepalived“ aus.
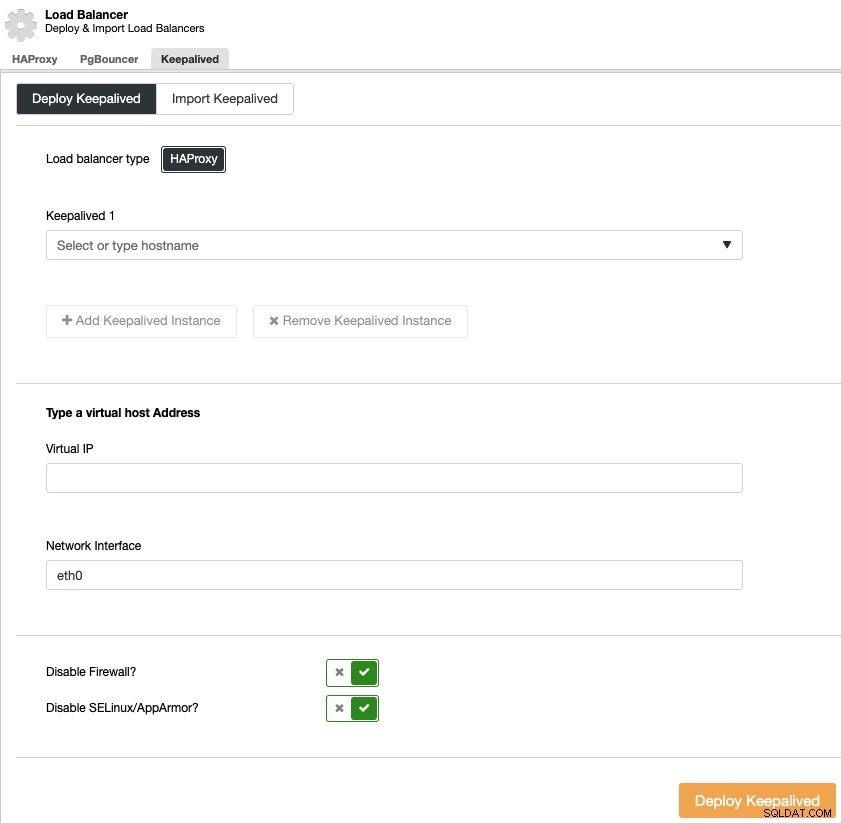
Sie müssen die Load-Balancer-Server und die virtuelle IP-Adresse für Ihr High auswählen Verfügbarkeitsumgebung.
Keepalived verwendet die virtuelle IP-Adresse und migriert sie im Falle eines Ausfalls von einem Load Balancer zu einem anderen, sodass Ihre Systeme weiterhin normal funktionieren können.
Wenn Sie die vorherigen Schritte befolgt haben, sollten Sie die folgende Topologie haben:
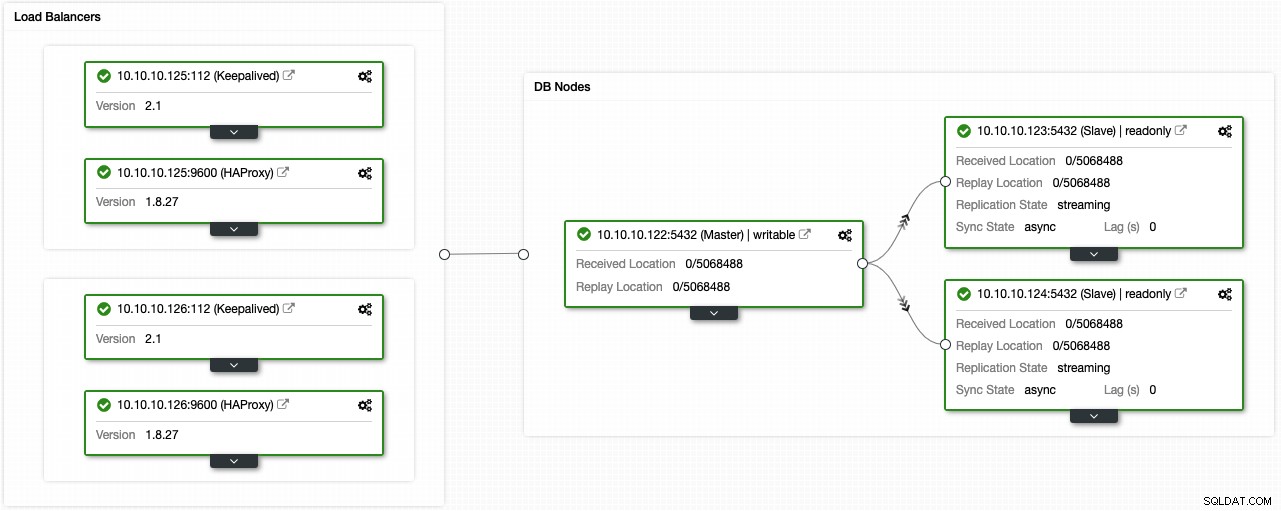
Sie können diese Hochverfügbarkeitsumgebung verbessern, indem Sie einen Verbindungspooler wie PgBouncer hinzufügen. Es ist kein Muss, könnte aber hilfreich sein, um die Leistung zu verbessern und aktive Verbindungen im Falle eines Ausfalls zu handhaben, und das Beste ist, dass Sie es auch mithilfe von ClusterControl bereitstellen können.
ClusterControl-Failover
Angenommen, die Option „Autorecovery“ ist in Ihrem ClusterControl-Server aktiviert. Im Falle eines primären Ausfalls stuft ClusterControl das am weitesten fortgeschrittene Standby (wenn es nicht auf der schwarzen Liste steht) zum primären um und benachrichtigt Sie über das Problem. Es führt auch ein Failover für die restlichen Standby-Knoten durch, um vom neuen Primärknoten zu replizieren.
HAProxy ist standardmäßig mit zwei verschiedenen Ports konfiguriert; Lese-Schreib- und Nur-Lese-Ports.
In Ihrem Lese-Schreib-Port haben Sie Ihren primären Server als online und den Rest Ihrer Knoten als offline, und in dem schreibgeschützten Port haben Sie sowohl den primären als auch den Standby-Server online.
Wenn HAProxy feststellt, dass einer Ihrer Knoten, entweder Primär oder Standby, nicht erreichbar ist, markiert es ihn automatisch als offline. Es berücksichtigt es nicht beim Senden von Datenverkehr an es. Die Erkennung erfolgt durch Zustandsprüfungsskripte, die ClusterControl zum Zeitpunkt der Bereitstellung konfiguriert. Diese prüfen, ob die Instanzen aktiv sind, ob sie gerade wiederhergestellt werden oder schreibgeschützt sind.
Wenn ClusterControl einen Standby-Knoten zum Primärknoten hochstuft, markiert Ihr HAProxy den alten Primärknoten für beide Ports als offline und setzt den heraufgestuften Knoten im Lese-Schreib-Port online.
Wenn Ihr aktiver HAProxy, der die virtuelle IP-Adresse zugewiesen hat, mit der sich Ihre Systeme verbinden, ausfällt, migriert Keepalived diese IP-Adresse automatisch auf Ihren passiven HAProxy. Das bedeutet, dass Ihre Systeme dann normal weiter funktionieren können.
Auf diese Weise funktionieren Ihre Systeme weiterhin wie erwartet und ohne Ihr manuelles Eingreifen.
Überlegungen
Wenn es Ihnen gelingt, Ihren alten ausgefallenen primären Knoten wiederherzustellen, wird er standardmäßig NICHT automatisch wieder in den Cluster eingeführt. Sie müssen es manuell tun. Ein Grund dafür ist, dass, wenn Ihr Replikat zum Zeitpunkt des Ausfalls verzögert war und ClusterControl den alten primären Knoten zum Cluster hinzufügt, dies einen Informationsverlust oder eine Dateninkonsistenz zwischen den Knoten bedeuten würde. Vielleicht möchten Sie das Problem auch im Detail analysieren. Wenn ClusterControl den ausgefallenen Knoten einfach wieder in den Cluster einführte, würden Sie möglicherweise Diagnoseinformationen verlieren.
Auch wenn die Umschaltung fehlschlägt, werden keine weiteren Versuche unternommen. Es ist ein manueller Eingriff erforderlich, um das Problem zu analysieren und die entsprechenden Maßnahmen durchzuführen. Dadurch soll vermieden werden, dass ClusterControl als Hochverfügbarkeitsmanager versucht, den nächsten Standby und den nächsten hochzustufen. Möglicherweise liegt ein Problem vor, das Sie überprüfen müssen.
Sicherheit
Eine wichtige Sache, die Sie nicht vergessen dürfen, bevor Sie mit Ihrer Hochverfügbarkeitsumgebung in Produktion gehen, ist die Gewährleistung ihrer Sicherheit.
Zu den zu berücksichtigenden Sicherheitsaspekten gehören Verschlüsselung, Rollenverwaltung und Zugriffsbeschränkung nach IP-Adresse, die wir in einem früheren Blog ausführlich behandelt haben.
In Ihrer PostgreSQL-Datenbank haben Sie die Datei pg_hba.conf, die die Client-Authentifizierung handhabt. Sie können den Verbindungstyp, die Quell-IP-Adresse oder das Netzwerk einschränken, zu welcher Datenbank Sie eine Verbindung herstellen können und mit welchen Benutzern. Daher ist diese Datei ein kritischer Teil für die PostgreSQL-Sicherheit.
Sie können Ihre PostgreSQL-Datenbank über die Datei postgresql.conf konfigurieren, sodass sie nur auf einer bestimmten Netzwerkschnittstelle und einem anderen Port als dem Standardport (5432) lauscht, wodurch grundlegende Verbindungsversuche von unerwünschten Quellen vermieden werden .
Eine ordnungsgemäße Benutzerverwaltung, entweder mit sicheren Passwörtern oder mit eingeschränktem Zugriff und Privilegien, ist ein weiterer wichtiger Bestandteil Ihrer Sicherheitseinstellungen. Es wird empfohlen, allen Benutzern möglichst wenige Berechtigungen zuzuweisen und, wenn möglich, die Quelle der Verbindung anzugeben.
Sie können auch die Datenverschlüsselung aktivieren, entweder während der Übertragung oder im Ruhezustand, um den Zugriff auf Informationen durch unbefugte Personen zu verhindern.
Ein Prüfprotokoll ist hilfreich, um zu verstehen, was in Ihrer Datenbank passiert oder passiert ist. PostgreSQL ermöglicht es Ihnen, mehrere Parameter für die Protokollierung zu konfigurieren oder sogar die pgAudit-Erweiterung für diese Aufgabe zu verwenden.
Zu guter Letzt wird empfohlen, Ihre Datenbank und Server mit den neuesten Patches auf dem neuesten Stand zu halten, um Sicherheitsrisiken zu vermeiden. Zu diesem Zweck ermöglicht Ihnen ClusterControl, Betriebsberichte zu erstellen, um zu überprüfen, ob Sie über verfügbare Updates verfügen, und hilft Ihnen sogar dabei, Ihre Datenbankserver zu aktualisieren.
Fazit
Hochverfügbarkeitsbereitstellungen können schwierig zu erreichen erscheinen, insbesondere wenn es darum geht, die unterschiedlichen Architekturen und notwendigen Komponenten zu verstehen, um sie richtig zu konfigurieren.
Wenn Sie HA manuell verwalten, lesen Sie unbedingt Performing Replication Topology Changes for PostgreSQL. Viele werden nach Tools wie ClusterControl suchen, um Bereitstellung, Load Balancer, Failover, Sicherheit und mehr für eine vollständige Hochverfügbarkeitsumgebung zu verwalten. Sie können ClusterControl 30 Tage lang kostenlos herunterladen, um zu sehen, wie es die Verwaltung einer hochverfügbaren Datenbankinfrastruktur erleichtern kann.
Wie auch immer Sie Ihre hochverfügbaren PostgreSQL-Datenbanken verwalten möchten, folgen Sie uns auf Twitter oder LinkedIn oder abonnieren Sie unseren Newsletter, um die neuesten Updates und Best Practices für die Verwaltung Ihrer Datenbank-Setups zu erhalten.