Hier sind wir. Fast zwei Jahrzehnte im 21. Jahrhundert und der Bedarf an mehr Rechenleistung ist immer noch ein Thema. Technologieunternehmen drängen auf den Bürgersteig, um dieses massive Problem direkt anzugehen. Hardware-Ingenieure haben eine Lösung gefunden, indem sie die Art und Weise geändert haben, wie sie die zentrale Verarbeitungseinheit (CPU) eines Computers entwerfen und herstellen. Sie enthalten jetzt mehrere Kerne, wodurch Parallelität stattfinden kann. Im Gegenzug haben Softwareentwickler die Art und Weise, wie sie Programme schreiben, angepasst, um sich an diese Änderung der Hardware anzupassen.
Die PostgreSQL-Community hat diese Mehrkern-CPUs voll ausgeschöpft, um die Abfrageleistung zu verbessern. Indem Sie lediglich auf Version 9.6 oder höher aktualisieren, können Sie eine Funktion namens Abfrageparallelität verwenden, um verschiedene Vorgänge auszuführen. Es zerlegt Aufgaben in kleinere Teile und verteilt jede Aufgabe auf mehrere CPU-Kerne. Jeder Kern kann die Aufgaben gleichzeitig bearbeiten. Aufgrund von Hardwareeinschränkungen ist dies die einzige Möglichkeit, die Computerleistung in Zukunft zu verbessern.
Bevor Sie die Parallelitätsfunktion in der PostgreSQL-Datenbank verwenden, ist es wichtig zu verstehen, wie sie eine Abfrage parallelisiert. Sie werden in der Lage sein, auftretende Probleme zu debuggen und zu lösen.
Wie funktioniert Abfrageparallelität?
Um besser zu verstehen, wie Parallelität ausgeführt wird, ist es eine gute Idee, auf Clientebene zu beginnen. Um auf PostgreSQL zuzugreifen, muss ein Client eine Verbindungsanforderung an den Datenbankserver namens Postmaster senden. Der Postmaster wird die Authentifizierung abschließen und dann forken, um einen neuen Serverprozess für jede Verbindung zu erstellen. Es ist auch verantwortlich für das Erstellen eines Bereichs des gemeinsam genutzten Speichers, der einen Pufferpool enthält. Der Pufferpool überwacht die Übertragung von Daten zwischen dem gemeinsam genutzten Speicher und dem Speicher. Daher überträgt der Pufferpool in dem Moment, in dem eine Verbindung hergestellt wird, Daten und ermöglicht eine Abfrageparallelität.
Es müssen nicht alle Abfragen parallel sein. Es gibt Fälle, in denen nur eine kleine Datenmenge benötigt wird, die von nur einem Kern schnell verarbeitet werden kann. Diese Funktion wird nur verwendet, wenn eine Abfrage viel Zeit in Anspruch nimmt. Der Datenbankoptimierer bestimmt, ob Parallelismus ausgeführt werden soll. Falls erforderlich, verwendet die Datenbank einen zusätzlichen Teil des Speichers, der als Dynamic Shared Memory (DSM) bezeichnet wird. Dadurch können der Leader-Prozess und die parallelen bewussten Worker-Prozesse die Abfrage auf mehrere Kerne aufteilen und relevante Daten sammeln.
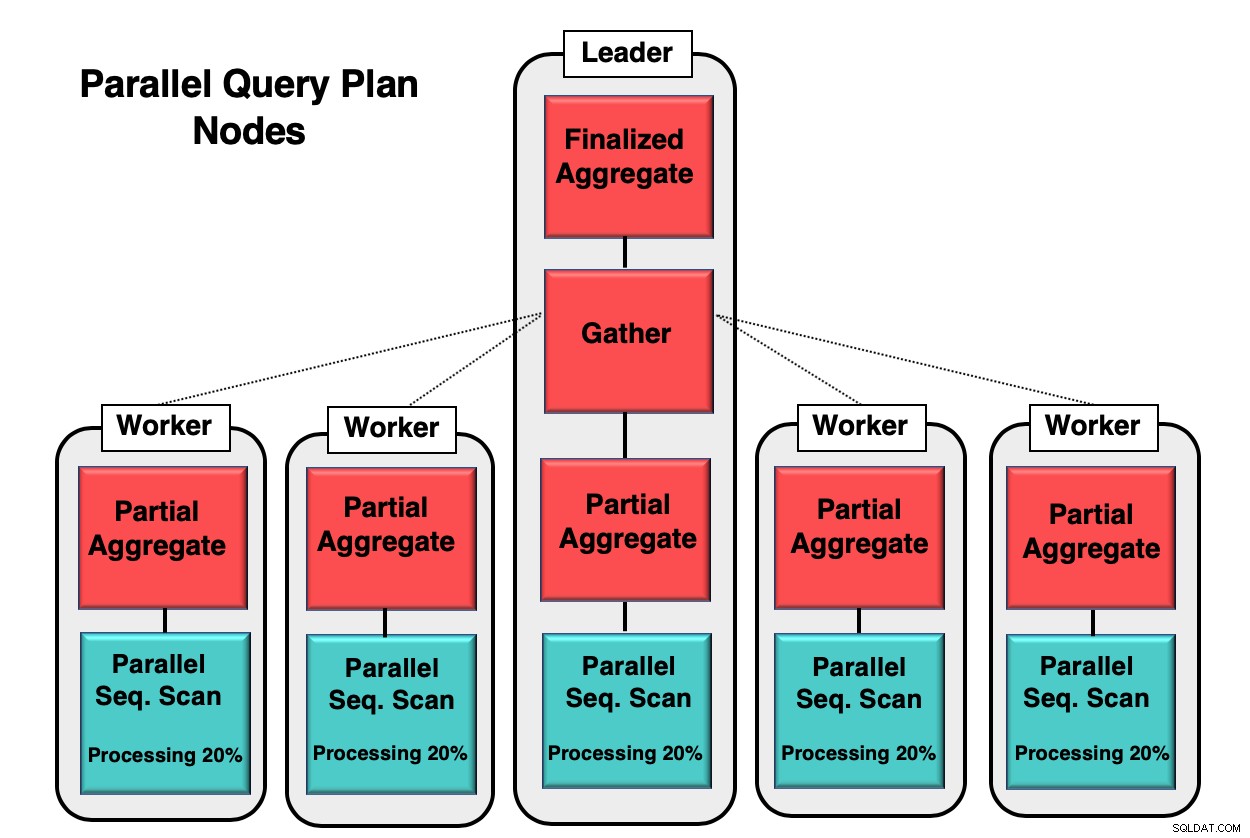
Abbildung 1 gibt Ihnen ein Beispiel dafür, wie Parallelität innerhalb der Datenbank stattfindet. Der Leader-Prozess führt die anfängliche Abfrage aus, während die einzelnen Worker-Prozesse eine Kopie desselben Prozesses initiieren. Der partielle Aggregatknoten oder CPU-Kern ist für die Implementierung des parallelen sequentiellen Scans der Datenbanktabelle verantwortlich.
In diesem Fall verarbeitet jeder sequenzielle Scan-Knoten 20 % der Daten in 8-kb-Blöcken. Dieselben Knoten können ihre Aktivität koordinieren, indem sie eine Technik namens Parallel Awareness verwenden. Jeder Knoten hat volle Kenntnis darüber, welche Daten bereits verarbeitet wurden und welche Daten in der Tabelle gescannt werden müssen, um die Abfrage abzuschließen. Sobald die Tupel vollständig gesammelt sind, werden sie an den Sammelknoten gesendet, um kompiliert und fertiggestellt zu werden.
Parallelbetrieb
Verschiedene Arten von Abfragen können verwendet werden, um Daten aus einer Datenbank abzurufen, um Ergebnismengen zu erzeugen. Hier sind spezifische Vorgänge, die Ihnen die Möglichkeit geben, die Nutzung mehrerer Kerne effektiv zu nutzen.
Sequentielles Scannen
Diese Operation liest Daten in einer Tabelle von Anfang bis Ende, um Daten zu sammeln. Es verteilt die Arbeitslast gleichmäßig auf mehrere Kerne, um die Verarbeitungsgeschwindigkeit von Abfragen zu erhöhen. Es ist sich jeder Kernaktivität bewusst, wodurch es einfacher ist festzustellen, ob die gesamte Abfrage abgeschlossen wurde. Der Gather-Knoten empfängt dann die Daten, die basierend auf der Abfrage extrahiert wurden.
Aggregation
Eine Standardoperation, bei der eine große Datenmenge in eine kleinere Anzahl von Zeilen komprimiert wird. Dies geschieht während der parallelen Verarbeitung, indem nur aus einer Tabelle oder Indizes die entsprechenden Informationen basierend auf der Abfrage extrahiert werden. Das Durchführen eines Durchschnitts spezifischer Daten ist ein hervorragendes Beispiel für die Aggregation.
Hash-Join
Eine Technik, die verwendet wird, um die Daten zwischen zwei Tabellen zu verbinden. Es ist der schnellste Join-Algorithmus, der normalerweise mit einer kleinen und einer großen Tabelle ausgeführt wird. Sie erstellen zunächst eine Hash-Tabelle und laden alle Daten aus einer Tabelle hinein. Dann können Sie alle Daten aus dem Hash und der zweiten Tabelle mit einem parallelen sequentiellen Scan scannen. Jedes aus dem Scan extrahierte Tupel wird mit der Hash-Tabelle verglichen, um festzustellen, ob es eine Übereinstimmung gibt. Wird eine Übereinstimmung festgestellt, werden die Daten zusammengeführt. Mit der Veröffentlichung von PostgreSQL 11 dauert die Verwendung von Parallelität zur Vervollständigung eines Hash-Joins etwa ein Drittel der vorherigen Verarbeitungszeit.
Join zusammenführen
Wenn der Optimierer feststellt, dass ein Hash-Join die Speicherkapazität überschreiten wird, führt er stattdessen einen Merge-Join durch. Dabei werden zwei sortierte Listen gleichzeitig durchsucht und die gleichen Elemente zusammengefügt. Wenn die Elemente nicht gleich sind, werden die Daten nicht zusammengeführt.
Nested-Loop-Join
Diese Operation wird verwendet, wenn Sie zwei Tabellen mit unterschiedlichen Programmiersprachen verbinden mussten, wie z. B. Quick Basic, Python usw. Jede Tabelle wird mithilfe mehrerer Kerne gescannt und verarbeitet. Wenn die Daten übereinstimmen, werden sie an den Sammelknoten gesendet, um beizutreten. Die Indizes werden ebenfalls gescannt, weshalb dieser Prozess mehrere Schleifen zum Abrufen der Daten enthält. Im Durchschnitt dauert es nur ein Drittel der Zeit, um die Verknüpfung mit dem parallelen Prozess abzuschließen.
B-Baum-Index-Scan
Diese Operation durchsucht einen Baum sortierter Daten, um bestimmte Informationen zu finden. Dieser Vorgang dauert länger als der typische sequentielle Scan, da beim Suchen nach Datensätzen viel gewartet werden muss. Die Arbeit des Scannens nach den entsprechenden Daten wird jedoch zwischen mehreren Prozessoren aufgeteilt.
Bitmap-Heap-Scan
Mit dieser Operation können Sie mehrere Indizes zusammenführen. Sie möchten zuerst die entsprechende Anzahl von Bitmaps erstellen, wie Sie Indizes haben. Wenn Sie beispielsweise drei Indizes haben, müssen Sie zuerst drei Bitmaps erstellen. Jede Bitmap ruft und kompiliert Tupel basierend auf der Abfrage.
Laden Sie noch heute das Whitepaper PostgreSQL-Verwaltung und -Automatisierung mit ClusterControl herunterErfahren Sie, was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunterPartitionsparallelität
Es gibt eine andere Form der Parallelität, die innerhalb der PostgreSQL-Datenbank stattfinden kann. Es kommt jedoch nicht vom Scannen von Tabellen und dem Aufbrechen der Aufgaben. Sie können die Daten nach bestimmten Werten partitionieren oder teilen. Sie können beispielsweise den Wert Käufer nehmen und einen einzelnen Kern die Daten nur innerhalb dieses Werts verarbeiten lassen. Auf diese Weise wissen Sie genau, was jeder Kern zu einem bestimmten Zeitpunkt verarbeitet.
Hash-Partitionierung
Diese Operation wird verwendet, um Tabellenzeilen in Untertabellen zu verteilen. Auch hier wird die Aufteilung im Allgemeinen durch einen eindeutigen Wert oder eine Werteliste aus einer Tabelle bestimmt. Dies ist eine ausgezeichnete Methode, wenn Sie nicht über eine effiziente Speicherverwaltungstechnik für alle Ihre Geräte verfügen. Sie sollten Partitionierung verwenden, um die Daten zufällig zu verteilen, um E/A-Engpässe zu vermeiden.
Partitionsweiser Join
Eine Technik, die verwendet wird, um Tabellen nach Partitionen zu zerlegen und sie durch Zusammenfügen ähnlicher Partitionen zu verbinden. Beispielsweise haben Sie möglicherweise eine große Tabelle mit Käufern aus den gesamten Vereinigten Staaten. Sie können die Tabelle zunächst nach verschiedenen Städten aufschlüsseln und dann einige Städte basierend auf der Region in jedem Bundesstaat zusammenfassen. Die partitionsweise Verknüpfung vereinfacht Ihre Daten und ermöglicht die Manipulation von Tabellen.
Parallel unsicher
PostgreSQL 11 führt automatisch Abfrageparallelität aus, wenn der Optimierer feststellt, dass dies der schnellste Weg ist, die Abfrage abzuschließen. Je höher die von Ihnen verwendete PostgreSQL-Version ist, desto paralleler ist Ihre Datenbank. Leider sollten nicht alle Abfragen parallel ausgeführt werden, auch wenn dies möglich ist. Die Art der Abfrage, die Sie durchführen, kann bestimmte Einschränkungen aufweisen und erfordert, dass nur ein Kern die gesamte Verarbeitung abschließt. Dies verlangsamt die Leistung Ihres Systems, garantiert jedoch, dass die empfangenen Daten vollständig sind.
Um sicherzustellen, dass Ihre Abfragen niemals gefährdet werden, haben Entwickler eine Funktion namens parallel unsicher erstellt. Sie können den Datenbankoptimierer manuell außer Kraft setzen und anfordern, dass die Abfrage niemals parallel ist. Der Parallelisierungsprozess wird nicht durchgeführt.
Die Parallelität innerhalb der PostgreSQL-Datenbank ist ein Feature, das mit jeder Datenbankversion immer besser wird. Auch wenn die Zukunft der Technologie ungewiss ist, scheint es, als ob die Verwendung dieser Funktion hier bleiben wird.
Weitere Informationen finden Sie im Folgenden...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-„divide-and-conquer-joins-between-partitioned-table“