Bei allen Engines für relationale Datenbanken ist es erforderlich, einen bestmöglichen Plan zu erstellen, der der Ausführung der Abfrage mit dem geringsten Zeit- und Ressourcenaufwand entspricht. Im Allgemeinen erzeugen alle Datenbanken Pläne in einem Baumstrukturformat, wobei der Blattknoten jedes Planbaums als Tabellenscanknoten bezeichnet wird. Dieser spezielle Knoten des Plans entspricht dem Algorithmus, der zum Abrufen von Daten aus der Basistabelle verwendet werden soll.
Betrachten Sie zum Beispiel ein einfaches Abfragebeispiel als SELECT * FROM TBL1, TBL2 wobei TBL2.ID>1000; und nehmen wir an, der generierte Plan sieht wie folgt aus:
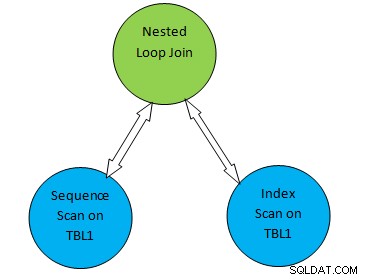
Also in der Planstruktur oben „Sequential Scan on TBL1“ und „ „Index-Scan auf TBL2“ entspricht der Tabellen-Scan-Methode auf Tabelle TBL1 bzw. TBL2. Gemäß diesem Plan wird TBL1 also sequentiell von den entsprechenden Seiten abgerufen und auf TBL2 kann mit INDEX Scan zugegriffen werden.
Die Wahl der richtigen Scanmethode als Teil des Plans ist sehr wichtig im Hinblick auf die Gesamtabfrageleistung.
Bevor wir uns mit allen Arten von Scan-Methoden befassen, die von PostgreSQL unterstützt werden, lassen Sie uns einige der wichtigsten Schlüsselpunkte wiederholen, die häufig verwendet werden, wenn wir durch den Blog gehen.
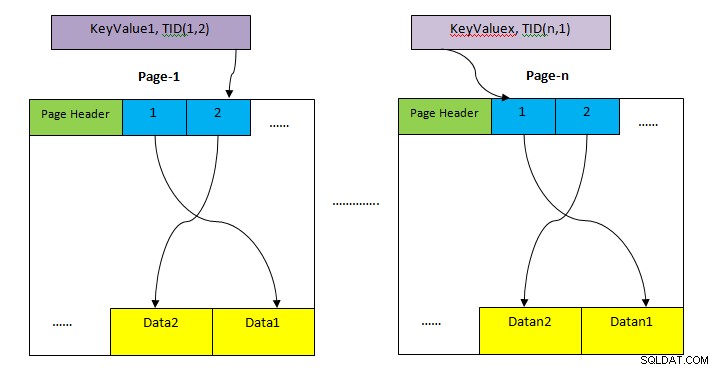
- HEAP: Ablagefläche zum Aufbewahren der gesamten Tabellenzeile. Diese ist in mehrere Seiten unterteilt (wie im obigen Bild gezeigt) und jede Seitengröße beträgt standardmäßig 8 KB. Innerhalb jeder Seite zeigt jeder Elementzeiger (z. B. 1, 2, ….) auf Daten innerhalb der Seite.
- Indexspeicherung: Dieser Speicher speichert nur Schlüsselwerte, d. h. im Index enthaltene Spaltenwerte. Diese ist ebenfalls in mehrere Seiten unterteilt und jede Seitengröße beträgt standardmäßig 8 KB.
- Tupelkennung (TID): TID ist eine 6-Byte-Zahl, die aus zwei Teilen besteht. Der erste Teil ist eine 4-Byte-Seitennummer und der verbleibende 2-Byte-Tupelindex innerhalb der Seite. Die Kombination dieser beiden Zahlen zeigt eindeutig auf den Speicherort für ein bestimmtes Tupel.
Derzeit unterstützt PostgreSQL die folgenden Scan-Methoden, mit denen alle erforderlichen Daten aus der Tabelle gelesen werden können:
- Sequentielles Scannen
- Index-Scan
- Nur Index-Scan
- Bitmap-Scan
- TID-Scan
Jede dieser Scan-Methoden ist gleichermaßen nützlich, abhängig von der Abfrage und anderen Parametern, z. Tabellenkardinalität, Tabellenselektivität, Festplatten-E/A-Kosten, zufällige E/A-Kosten, Sequenz-E/A-Kosten usw. Lassen Sie uns eine voreingestellte Tabelle erstellen und mit einigen Daten füllen, die häufig verwendet werden, um diese Scan-Methoden besser zu erklären .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEIn diesem Beispiel werden also eine Million Datensätze eingefügt und dann wird die Tabelle analysiert, damit alle Statistiken aktuell sind.
Sequentielles Scannen
Wie der Name schon sagt, wird ein sequentielles Scannen einer Tabelle durchgeführt, indem alle Elementzeiger aller Seiten der entsprechenden Tabellen sequentiell gescannt werden. Wenn also 100 Seiten für eine bestimmte Tabelle und dann 1000 Datensätze auf jeder Seite vorhanden sind, werden im Rahmen des sequentiellen Scans 100 * 1000 Datensätze abgerufen und geprüft, ob sie gemäß der Isolationsstufe und auch gemäß der Prädikatklausel übereinstimmen. Selbst wenn also nur 1 Datensatz als Teil des gesamten Tabellenscans ausgewählt wird, müssen 100.000 Datensätze gescannt werden, um einen qualifizierten Datensatz gemäß der Bedingung zu finden.
Gemäß obiger Tabelle und Daten führt die folgende Abfrage zu einem sequentiellen Scan, da die meisten Daten ausgewählt werden.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)HINWEIS
Ohne Berechnung und Vergleich der Plankosten ist es jedoch fast unmöglich zu sagen, welche Art von Scans verwendet werden. Aber damit der sequentielle Scan verwendet werden kann, sollten mindestens die folgenden Kriterien übereinstimmen:
- Kein Index für Schlüssel verfügbar, der Teil des Prädikats ist.
- Die meisten Zeilen werden als Teil der SQL-Abfrage abgerufen.
TIPPS
Falls nur sehr wenige % der Zeilen abgerufen werden und sich das Prädikat auf einer (oder mehreren) Spalte befindet, versuchen Sie, die Leistung mit oder ohne Index zu bewerten.
Index-Scan
Im Gegensatz zum sequenziellen Scan ruft der Index-Scan nicht alle Datensätze sequentiell ab. Vielmehr verwendet es eine andere Datenstruktur (abhängig vom Indextyp), die dem an der Abfrage beteiligten Index entspricht, und sucht die erforderlichen Daten (gemäß der Prädikatsklausel) mit sehr minimalen Scans. Dann zeigt der mit dem Index-Scan gefundene Eintrag direkt auf Daten im Heap-Bereich (wie in der obigen Abbildung gezeigt), die dann abgerufen werden, um die Sichtbarkeit gemäß der Isolationsstufe zu überprüfen. Es gibt also zwei Schritte für den Index-Scan:
- Daten aus indexbezogener Datenstruktur abrufen. Es gibt die TID der entsprechenden Daten im Heap zurück.
- Dann wird direkt auf die entsprechende Heap-Seite zugegriffen, um ganze Daten zu erhalten. Dieser zusätzliche Schritt ist aus folgenden Gründen erforderlich:
- Die Abfrage hat möglicherweise angefordert, mehr Spalten abzurufen, als im entsprechenden Index verfügbar sind.
- Sichtbarkeitsinformationen werden nicht zusammen mit Indexdaten gepflegt. Um also die Sichtbarkeit von Daten gemäß der Isolationsstufe zu überprüfen, muss auf Heap-Daten zugegriffen werden.
Jetzt fragen wir uns vielleicht, warum Index Scan nicht immer verwendet wird, wenn es doch so effizient ist. Wie wir wissen, hat alles seinen Preis. Hier beziehen sich die anfallenden Kosten auf die Art der E/A, die wir durchführen. Beim Index-Scan ist Random I/O beteiligt, da für jeden im Indexspeicher gefundenen Datensatz die entsprechenden Daten aus dem HEAP-Speicher abgerufen werden müssen, während beim Sequential Scan Sequential I/O erforderlich ist, was nur etwa 25 % in Anspruch nimmt. des zufälligen E/A-Timings.
Der Index-Scan sollte also nur gewählt werden, wenn die Gesamtverstärkung den Overhead übertrifft, der aufgrund der zufälligen I/O-Kosten entsteht.
Gemäß obiger Tabelle und Daten führt die folgende Abfrage zu einem Index-Scan, da nur ein Datensatz ausgewählt wird. So ist zufälliges I/O weniger und die Suche nach dem entsprechenden Datensatz ist schnell.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Nur Index-Scan
Index Only Scan ist dem Index Scan ähnlich, mit Ausnahme des zweiten Schritts, d.h. wie der Name schon sagt, scannt er nur die Indexdatenstruktur. Es gibt zwei zusätzliche Voraussetzungen, um den Index-Only-Scan im Vergleich zum Index-Scan zu wählen:
- Die Abfrage sollte nur Schlüsselspalten abrufen, die Teil des Indexes sind.
- Alle Tupel (Datensätze) auf der ausgewählten Heap-Seite sollten sichtbar sein. Wie im vorherigen Abschnitt besprochen, enthält die Indexdatenstruktur keine Sichtbarkeitsinformationen. Um Daten nur aus dem Index auszuwählen, sollten wir also vermeiden, die Sichtbarkeit zu prüfen, und dies könnte passieren, wenn alle Daten dieser Seite als sichtbar betrachtet werden.
Die folgende Abfrage führt zu einem reinen Index-Scan. Auch wenn diese Abfrage in Bezug auf die Auswahl der Anzahl von Datensätzen fast ähnlich ist, aber da nur das Schlüsselfeld (z. B. „num“) ausgewählt wird, wird nur der Index-Scan ausgewählt.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Bitmap-Scan
Bitmap-Scan ist eine Mischung aus Index-Scan und sequentiellem Scan. Es versucht, den Nachteil des Index-Scans zu lösen, behält aber dennoch seinen vollen Vorteil. Wie oben besprochen, müssen für alle in der Indexdatenstruktur gefundenen Daten entsprechende Daten auf der Heap-Seite gefunden werden. Alternativ muss also die Indexseite einmal abgerufen werden, gefolgt von der Heap-Seite, was viele zufällige E / A-Vorgänge verursacht. Die Bitmap-Scan-Methode nutzt also den Vorteil des Index-Scans ohne zufällige E/A. Dies funktioniert auf zwei Ebenen wie folgt:
- Bitmap Index Scan:Zuerst werden alle Indexdaten aus der Indexdatenstruktur abgerufen und eine Bitmap aller TID erstellt. Zum einfachen Verständnis können Sie davon ausgehen, dass diese Bitmap einen Hash aller Seiten enthält (gehasht basierend auf der Seitennummer) und jeder Seiteneintrag ein Array aller Offsets innerhalb dieser Seite enthält.
- Bitmap-Heap-Scan:Wie der Name schon sagt, liest es Bitmaps von Seiten und scannt dann Daten vom Heap, die der gespeicherten Seite und dem Offset entsprechen. Am Ende prüft es auf Sichtbarkeit und Prädikat usw. und gibt das Tupel basierend auf dem Ergebnis all dieser Prüfungen zurück.
Die folgende Abfrage führt zu einem Bitmap-Scan, da sie nicht sehr wenige Datensätze auswählt (d. h. zu viele für einen Index-Scan) und gleichzeitig keine große Anzahl von Datensätzen auswählt (d. h. zu wenig für einen sequentiellen scannen).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Betrachten Sie nun die folgende Abfrage, die dieselbe Anzahl von Datensätzen auswählt, aber nur Schlüsselfelder (d. h. nur Indexspalten). Da es nur Schlüssel auswählt, muss es keine Heap-Seiten für andere Datenteile referenzieren, und daher ist keine zufällige E/A beteiligt. Diese Abfrage wählt also nur den Index-Scan statt den Bitmap-Scan.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)TID-Scan
TID ist, wie oben erwähnt, eine 6-Byte-Zahl, die aus 4-Byte-Seitennummer und den verbleibenden 2-Byte-Tupelindex innerhalb der Seite besteht. Der TID-Scan ist eine sehr spezifische Art des Scans in PostgreSQL und wird nur ausgewählt, wenn TID im Abfrageprädikat enthalten ist. Betrachten Sie die folgende Abfrage, die den TID-Scan demonstriert:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Also hier im Prädikat, anstatt einen genauen Wert der Spalte als Bedingung anzugeben, wird TID bereitgestellt. Dies ähnelt der ROWID-basierten Suche in Oracle.
Bonus
Alle Scanmethoden sind weit verbreitet und berühmt. Außerdem sind diese Scan-Methoden in fast allen relationalen Datenbanken verfügbar. Aber es gibt eine andere Scan-Methode, die kürzlich in der PostgreSQL-Community diskutiert und kürzlich auch in anderen relationalen Datenbanken hinzugefügt wurde. Es heißt „Loose IndexScan“ in MySQL, „Index Skip Scan“ in Oracle und „Jump Scan“ in DB2.
Diese Scan-Methode wird für ein bestimmtes Szenario verwendet, in dem ein eindeutiger Wert der führenden Schlüsselspalte des B-Tree-Index ausgewählt wird. Als Teil dieses Scans wird vermieden, alle gleichen Schlüsselspaltenwerte zu durchlaufen, sondern nur den ersten eindeutigen Wert zu durchlaufen und dann zum nächsten großen zu springen.
Diese Arbeit ist in PostgreSQL mit dem vorläufigen Namen „Index Skip Scan“ noch im Gange und wir erwarten, dass dies in einer zukünftigen Version zu sehen ist.