Jedes PostgreSQL-Release kommt mit einigen wichtigen Feature-Verbesserungen, aber was ebenso interessant ist, ist, dass jedes Release auch Verbesserungen gegenüber früheren Features aufweist.
Da PostgreSQL 13 bald veröffentlicht werden soll, ist es an der Zeit, zu prüfen, welche Funktionen und Verbesserungen uns die Community bringt. Eine solche Verbesserung ohne Rauschen ist die „Verbesserung der logischen Replikation für die Partitionierung.“
Lassen Sie uns diese Funktionsverbesserung anhand eines laufenden Beispiels verstehen.
Terminologie
Zwei Begriffe, die zum Verständnis dieser Funktion wichtig sind, sind:
- Partitionstabellen
- Logische Replikation
Partitionstabellen
Eine Möglichkeit, eine große Tabelle in mehrere physische Teile aufzuteilen, um folgende Vorteile zu erzielen:
- Verbesserte Abfrageleistung
- Schnellere Updates
- Schnelleres Massenladen und -löschen
- Selten verwendete Daten auf langsamen Laufwerken organisieren
Einige dieser Vorteile werden durch Partitionsbereinigung (d. h. Abfrageplaner, der die Partitionsdefinition verwendet, um zu entscheiden, ob eine Partition gescannt werden soll oder nicht) und die Tatsache erreicht, dass eine Partition eher einfacher in endlichen Speicher passt im Vergleich zu einem riesigen Tisch.
Eine Tabelle wird partitioniert nach:
- Liste
- Hash
- Bereich

Logische Replikation
Wie der Name schon sagt, handelt es sich hierbei um eine Replikationsmethode, bei der Daten basierend auf ihrer Identität (z. B. Schlüssel) inkrementell repliziert werden. Es ist nicht vergleichbar mit WAL oder physikalischen Replikationsmethoden, bei denen Daten Byte für Byte gesendet werden.
Basierend auf einem Publisher-Subscriber-Muster muss die Quelle der Daten einen Publisher definieren, während das Ziel als Abonnent registriert sein muss. Die interessanten Anwendungsfälle dafür sind:
- Selektive Replikation (nur ein Teil der Datenbank)
- Gleichzeitiges Schreiben in zwei Datenbankinstanzen, in denen Daten repliziert werden
- Replikation zwischen verschiedenen Betriebssystemen (z. B. Linux und Windows)
- Feinkörnige Sicherheit bei der Replikation von Daten
- Löst die Ausführung aus, wenn Daten auf der Empfängerseite eintreffen
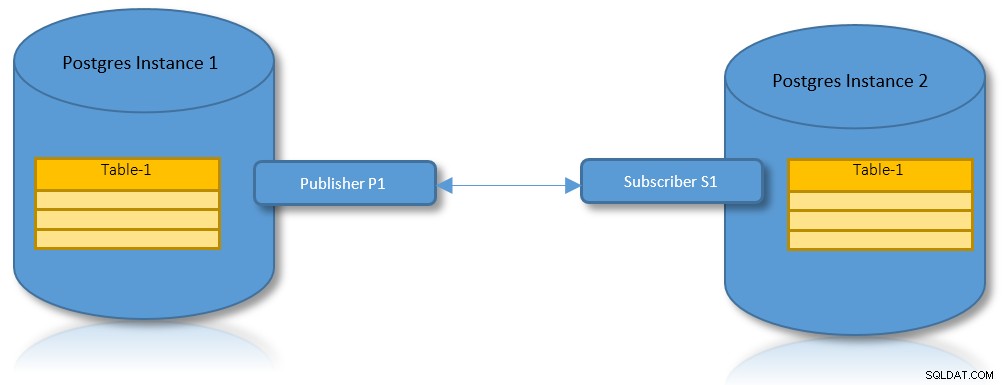
Logische Replikation für Partitionen
Mit den Vorteilen sowohl der logischen Replikation als auch der Partitionierung ist es ein praktischer Anwendungsfall, ein Szenario zu haben, in dem eine partitionierte Tabelle über zwei PostgreSQL-Instanzen repliziert werden muss.
Im Folgenden finden Sie die Schritte, um die in PostgreSQL 13 vorgenommenen Verbesserungen in diesem Zusammenhang zu etablieren und hervorzuheben.
Einrichtung
Erwägen Sie eine Einrichtung mit zwei Knoten, um zwei verschiedene Instanzen auszuführen, die eine partitionierte Tabelle enthalten:
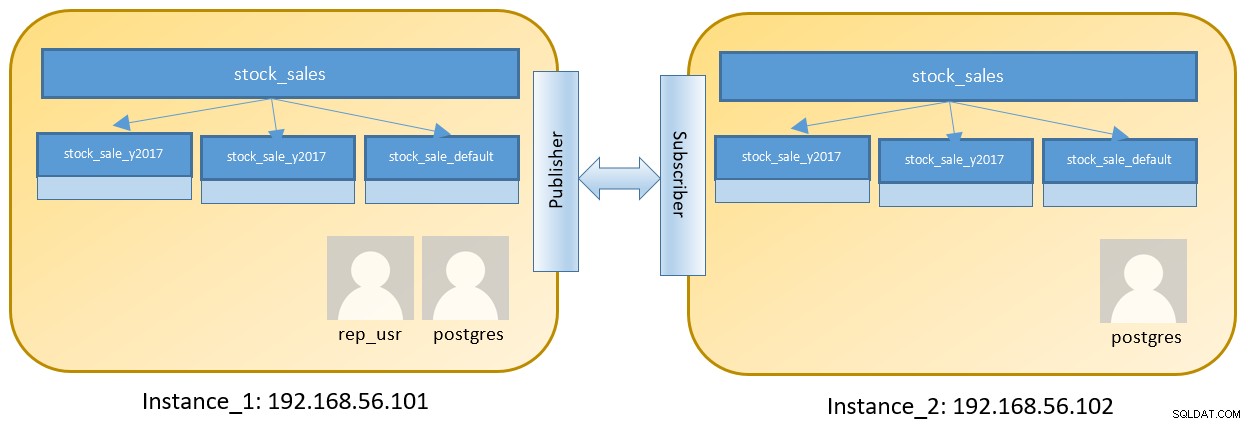
Die Schritte für Instanz_1 sind wie folgt:Nach der Anmeldung unter 192.168.56.101 als Postgres-Benutzer :
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile startDie Einstellung „wal_level“ ist speziell auf „logical“ gesetzt, um anzugeben, dass die logische Replikation verwendet wird, um Daten von dieser Instanz zu replizieren. Die Konfigurationsdatei „pg_hba.conf“ wurde ebenfalls geändert, um Verbindungen von 192.168.56.102 zuzulassen.
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;Obwohl die Postgres-Rolle standardmäßig auf der Datenbank Instance_1 erstellt wird, sollte auch ein separater Benutzer erstellt werden, der eingeschränkten Zugriff hat – was den Bereich nur für eine bestimmte Tabelle einschränkt.
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;Eine fast ähnliche Einrichtung ist für Instanz_2 erforderlich
$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startEs sollte beachtet werden, dass, da Instance_2 keine Datenquelle für andere Knoten sein wird, die wal_level-Einstellungen sowie die Datei pg_hba.conf keine zusätzlichen Einstellungen benötigen. Unnötig zu erwähnen, dass pg_hba.conf je nach Produktionsanforderungen möglicherweise aktualisiert werden muss.
Logische Replikation unterstützt DDL nicht, wir müssen auch eine Tabellenstruktur auf Instanz_2 erstellen. Erstellen Sie eine partitionierte Tabelle mithilfe der obigen Partitionserstellung, um dieselbe Tabellenstruktur auch auf Instance_2 zu erstellen.
Einrichtung der logischen Replikation
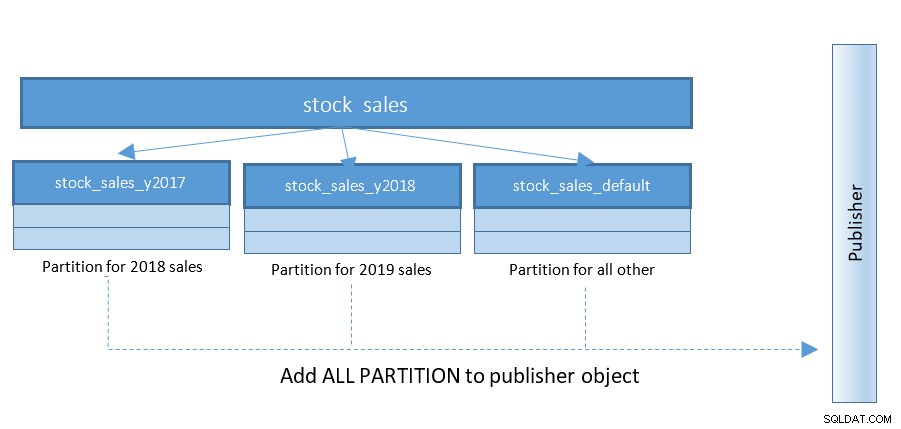
Die Einrichtung der logischen Replikation wird mit PostgreSQL 13 viel einfacher. Bis PostgreSQL 12 war die Struktur wie folgt:
Mit PostgreSQL 13 wird die Veröffentlichung von Partitionen viel einfacher. Sehen Sie sich das folgende Diagramm an und vergleichen Sie es mit dem vorherigen Diagramm:
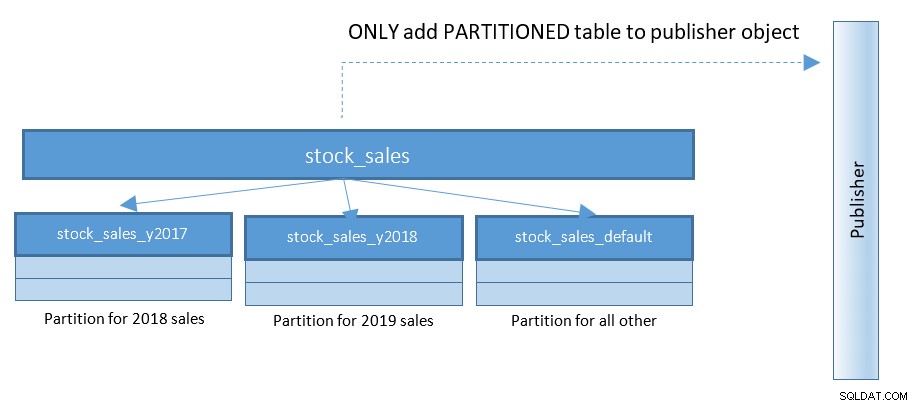
Bei Setups mit Hunderten und Tausenden von partitionierten Tabellen vereinfacht diese kleine Änderung Dinge zu einem großen Teil.
In PostgreSQL 13 lauten die Anweisungen zum Erstellen einer solchen Veröffentlichung:
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);Der Konfigurationsparameter publish_via_partition_root ist neu in PostgreSQL 13, wodurch der Empfängerknoten eine etwas andere Blatthierarchie haben kann. Die bloße Erstellung von Veröffentlichungen auf partitionierten Tabellen in PostgreSQL 12 gibt Fehlermeldungen wie die folgenden zurück:
ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.Ignorieren wir die Einschränkungen von PostgreSQL 12 und fahren wir mit unserem praktischen Einsatz dieser Funktion auf PostgreSQL 13 fort, müssen wir den Abonnenten auf Instanz_2 mit den folgenden Anweisungen einrichten:
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;Überprüfen, ob es wirklich funktioniert
Wir sind mit der gesamten Einrichtung ziemlich fertig, aber lassen Sie uns ein paar Tests durchführen, um zu sehen, ob alles funktioniert.
Fügen Sie auf Instanz_1 mehrere Zeilen ein und stellen Sie sicher, dass sie in mehreren Partitionen erscheinen:
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);Prüfen Sie die Daten auf Instanz_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721Lassen Sie uns nun prüfen, ob die logische Replikation funktioniert, auch wenn die Blattknoten auf der Empfängerseite nicht gleich sind.
Fügen Sie eine weitere Partition auf Instanz_1 hinzu und fügen Sie den Datensatz ein:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );Prüfen Sie die Daten auf Instanz_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174Andere Partitionierungsfunktionen in PostgreSQL 13
Es gibt auch andere Verbesserungen in PostgreSQL 13, die sich auf die Partitionierung beziehen, nämlich:
- Verbesserungen beim Join zwischen partitionierten Tabellen
- Partitionierte Tabellen unterstützen jetzt BEFORE-Trigger auf Zeilenebene
Fazit
Ich werde die oben genannten zwei bevorstehenden Funktionen auf jeden Fall in meinen nächsten Blogs überprüfen. Bis dahin Stoff zum Nachdenken – segelt PostgreSQL mit der kombinierten Kraft der Partitionierung und logischen Replikation einem Master-Master-Setup näher?



