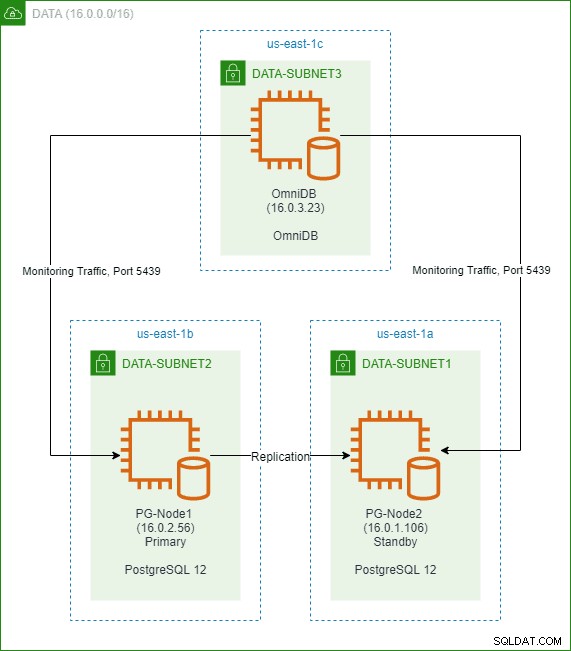
In einem früheren Artikel dieser Serie haben wir einen PostgreSQL 12-Cluster mit zwei Knoten in der AWS-Cloud erstellt. Wir haben auch 2ndQuadrant OmniDB in einem dritten Knoten installiert und konfiguriert. Das folgende Bild zeigt die Architektur:
Wir konnten über die webbasierte Benutzeroberfläche von OmniDB eine Verbindung sowohl zum primären als auch zum Standby-Knoten herstellen. Anschließend haben wir eine Beispieldatenbank namens „dvdrental“ im primären Knoten wiederhergestellt, die mit der Replikation auf den Standby-Knoten begann.
In diesem Teil der Serie erfahren Sie, wie Sie ein Überwachungs-Dashboard in OmniDB erstellen und verwenden. DBAs und Betriebsteams bevorzugen häufig grafische Tools gegenüber komplexen Abfragen, um den Zustand der Datenbank visuell zu überprüfen. OmniDB enthält eine Reihe wichtiger Widgets, die einfach in einem Überwachungs-Dashboard verwendet werden können. Wie wir später sehen werden, ermöglicht es Benutzern auch, ihre eigenen Überwachungs-Widgets zu schreiben.
Erstellen eines Leistungsüberwachungs-Dashboards
Beginnen wir mit dem Standard-Dashboard, mit dem OmniDB geliefert wird.
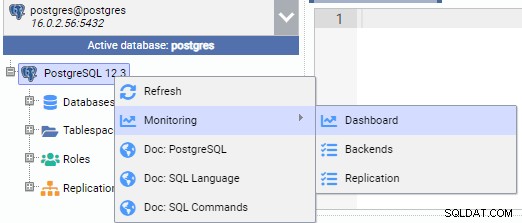
In der Abbildung unten sind wir mit dem primären Knoten (PG-Node1) verbunden. Wir klicken mit der rechten Maustaste auf den Instanznamen und wählen dann aus dem Popup-Menü „Monitor“ und dann „Dashboard“.
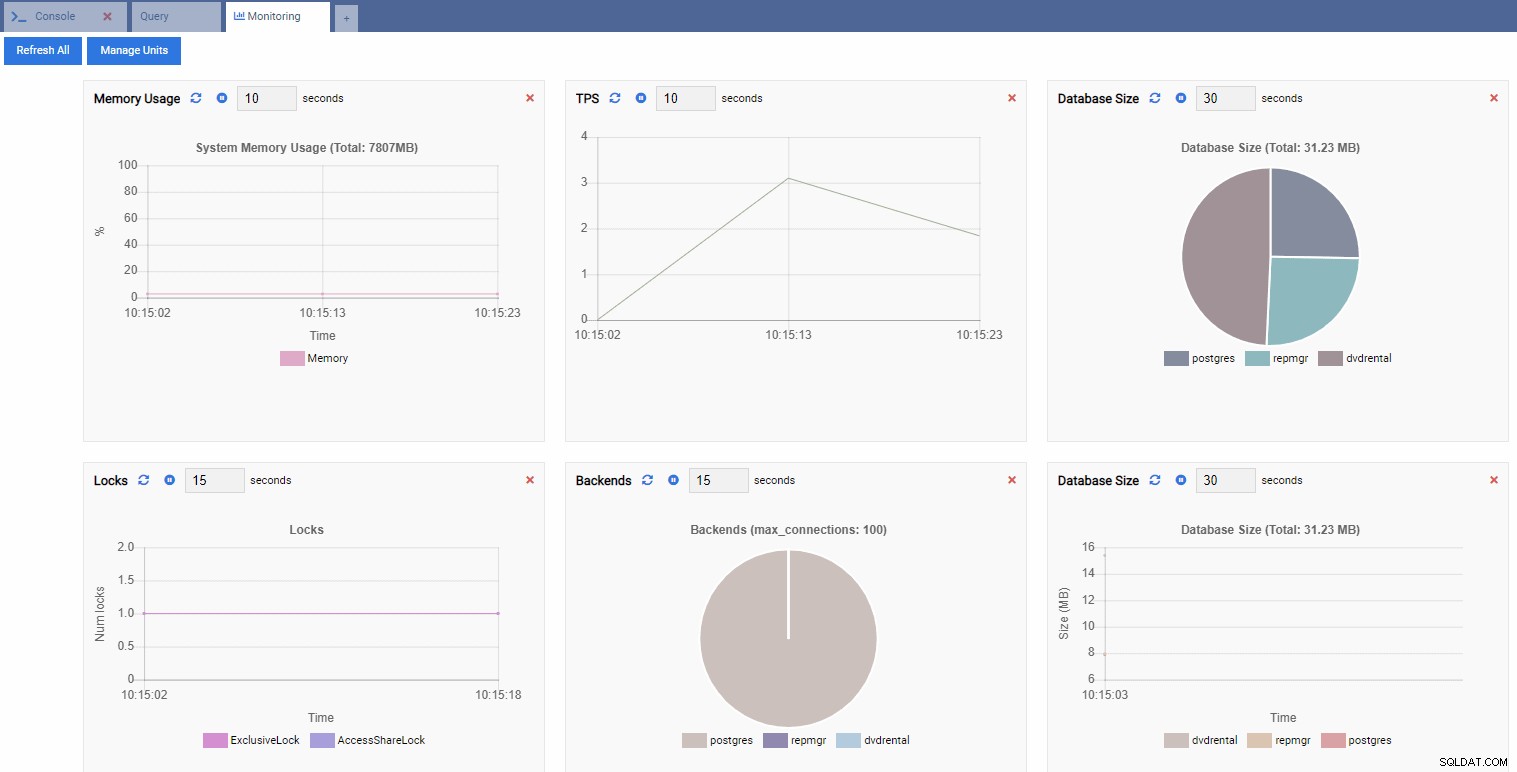
Dies öffnet ein Dashboard mit einigen Widgets darin.
In OmniDB-Begriffen werden die rechteckigen Widgets im Dashboard als Überwachungseinheiten bezeichnet . Jede dieser Einheiten zeigt eine bestimmte Metrik von der PostgreSQL-Instanz, mit der sie verbunden ist, und aktualisiert ihre Daten dynamisch.
Überwachungseinheiten verstehen
OmniDB enthält vier Arten von Überwachungseinheiten:
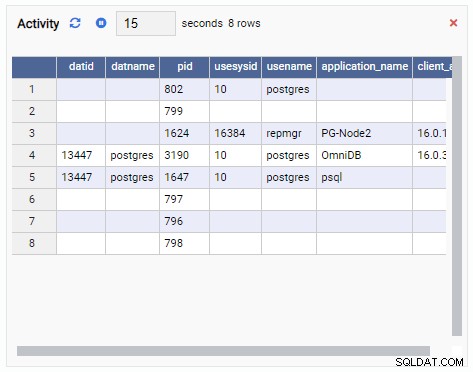
- Ein Raster ist eine tabellarische Struktur, die das Ergebnis einer Abfrage anzeigt. Dies kann beispielsweise die Ausgabe von SELECT * FROM pg_stat_replication sein. Ein Grid sieht so aus:
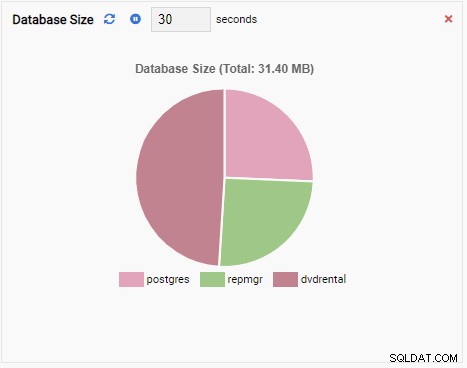
- Ein Diagramm zeigt die Daten in grafischem Format, wie Linien- oder Tortendiagramme. Wenn es aktualisiert wird, wird das gesamte Diagramm mit einem neuen Wert auf dem Bildschirm neu gezeichnet, und der alte Wert ist verschwunden. Mit diesen Überwachungseinheiten können wir nur den aktuellen Wert der Metrik sehen. Hier ist ein Beispiel für ein Diagramm:
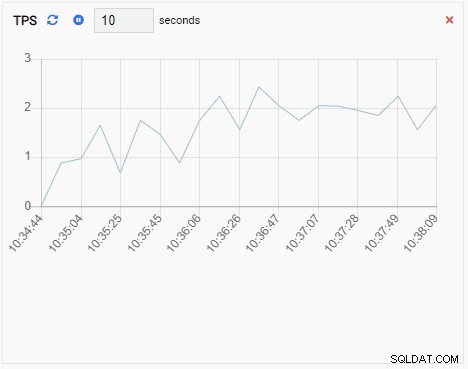
- Ein Diagramm-Anhang ist auch eine Überwachungseinheit vom Typ Diagramm, außer dass bei der Aktualisierung der neue Wert an die vorhandene Reihe angehängt wird. Mit Chart-Append können wir Trends im Laufe der Zeit leicht erkennen. Hier ist ein Beispiel:
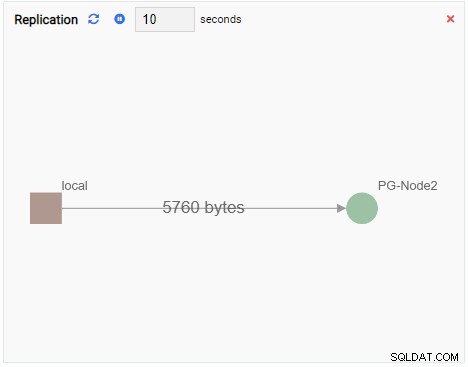
- Eine Grafik zeigt Beziehungen zwischen PostgreSQL-Clusterinstanzen und einer zugehörigen Metrik. Wie die Chart Monitoring Unit aktualisiert auch eine Graph Monitoring Unit ihren alten Wert mit einem neuen. Das folgende Bild zeigt, dass der aktuelle Knoten (PG-Node1) auf PG-Node2 repliziert wird:
Jede Überwachungseinheit hat eine Reihe gemeinsamer Elemente:
- Der Name der Überwachungseinheit
- Eine „Aktualisieren“-Schaltfläche zum manuellen Aktualisieren der Einheit
- Eine „Pause“-Schaltfläche, um die Aktualisierung der Überwachungseinheit vorübergehend anzuhalten
- Ein Textfeld, das das aktuelle Aktualisierungsintervall anzeigt. Dies kann geändert werden
- Eine „Schließen“-Schaltfläche (rotes Kreuz), um die Überwachungseinheit vom Dashboard zu entfernen
- Der eigentliche Zeichenbereich des Monitorings
Vorgefertigte Überwachungseinheiten
OmniDB enthält eine Reihe von Überwachungseinheiten für PostgreSQL, die wir unserem Dashboard hinzufügen können. Um auf diese Einheiten zuzugreifen, klicken wir auf die Schaltfläche „Einheiten verwalten“ oben im Dashboard:
Dies öffnet die Liste „Einheiten verwalten“:
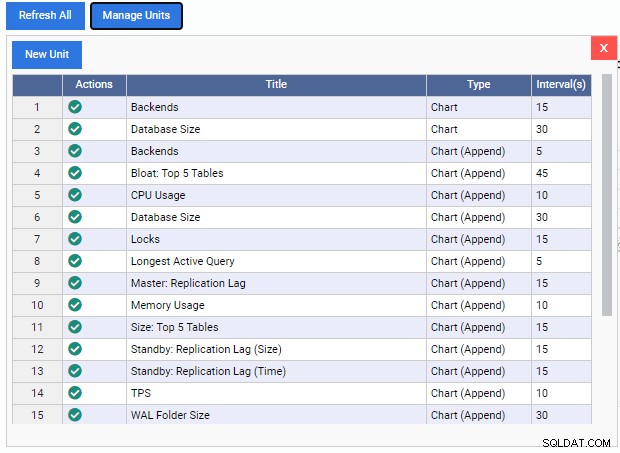
Wie wir sehen können, gibt es hier nur wenige vorgefertigte Überwachungseinheiten. Die Codes für diese Überwachungseinheiten können kostenlos aus dem GitHub-Repo von 2ndQuadrant heruntergeladen werden. Jede hier aufgeführte Einheit zeigt ihren Namen, Typ (Diagramm, Diagramm anhängen, Diagramm oder Gitter) und die Standardaktualisierungsrate.
Um dem Dashboard eine Überwachungseinheit hinzuzufügen, müssen wir nur auf das grüne Häkchen unter der Spalte „Aktionen“ für diese Einheit klicken. Wir können verschiedene Überwachungseinheiten mischen und anpassen, um das gewünschte Dashboard zu erstellen.
In der Abbildung unten haben wir die folgenden Einheiten für unser Leistungsüberwachungs-Dashboard hinzugefügt und alles andere entfernt:
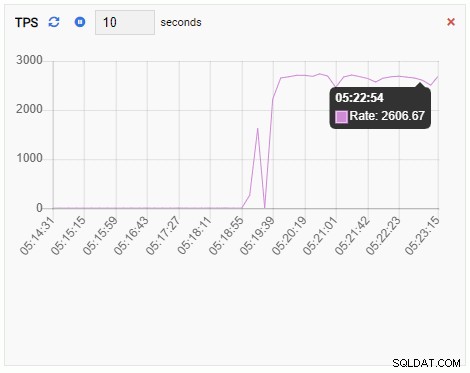
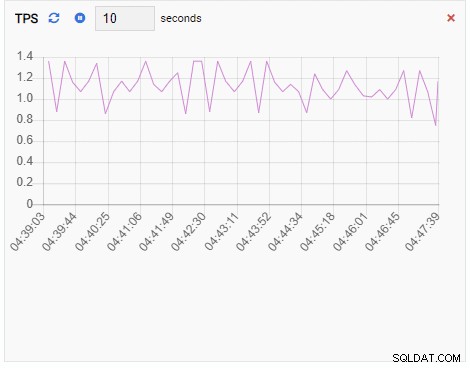
TPS (Transaktion pro Sekunde):
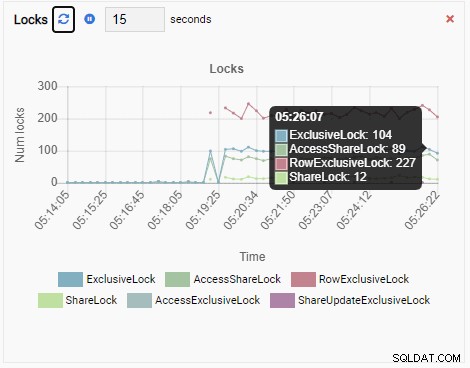
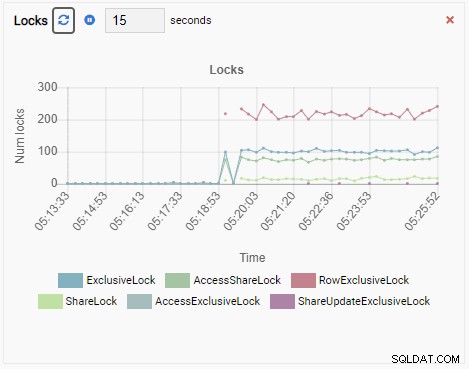
Anzahl der Schlösser:
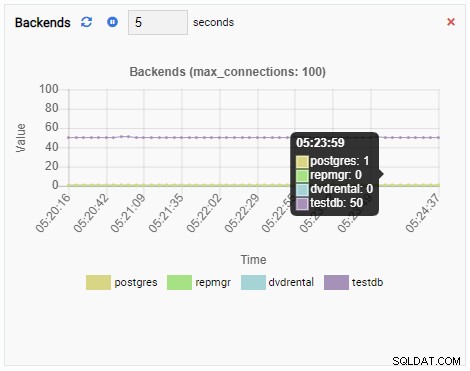
Anzahl der Backends:
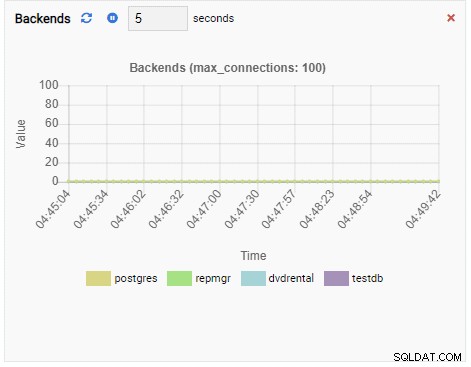
Da unsere Instanz im Leerlauf ist, sehen wir, dass die Werte für TPS, Sperren und Backends minimal sind.
Testen des Überwachungs-Dashboards
Wir werden jetzt pgbench in unserem primären Knoten (PG-Node1) ausführen. pgbench ist ein einfaches Benchmarking-Tool, das mit PostgreSQL ausgeliefert wird. Wie die meisten anderen Tools seiner Art erstellt pgbench bei der Initialisierung ein Musterschema und Tabellen eines OLTP-Systems in einer Datenbank. Danach kann es mehrere Client-Verbindungen emulieren, die jeweils eine Reihe von Transaktionen in der Datenbank ausführen. In diesem Fall führen wir kein Benchmarking des PostgreSQL-Primärknotens durch; Wir erstellen nur die Datenbank für pgbench und prüfen, ob unsere Dashboard-Überwachungseinheiten die Änderung des Systemzustands erkennen.
Zuerst erstellen wir eine Datenbank für pgbench im primären Knoten:
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "CREATE DATABASE testdb";CREATE DATABASE
Als nächstes initialisieren wir die „testdb“-Datenbank für pgbench:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdbLöschen alter Tabellen ... Erstellen von Tabellen ... Generieren Daten...100000 von 2000000 Tupeln (5 %) erledigt (0,02 s verstrichen, 0,43 s verbleibend) erledigt (verstrichene 1,84 s, verbleibende 0,00 s) Staubsaugen ... Primärschlüssel erstellen ... fertig.
Mit der initialisierten Datenbank starten wir nun den eigentlichen Ladevorgang. Im folgenden Code-Snippet bitten wir pgbench, mit 50 gleichzeitigen Client-Verbindungen mit der testdb-Datenbank zu beginnen, wobei jede Verbindung 100.000 Transaktionen in ihren Tabellen ausführt. Der Belastungstest wird über zwei Threads ausgeführt.
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdbstarting vacuum...end.……Wenn wir jetzt zu unserem OmniDB-Dashboard zurückkehren, sehen wir, dass die Überwachungseinheiten sehr unterschiedliche Ergebnisse anzeigen.
Die TPS-Metrik zeigt einen recht hohen Wert. Es gibt einen plötzlichen Sprung von weniger als 2 auf mehr als 2000:
Die Anzahl der Backends hat zugenommen. Wie erwartet hat testdb 50 Verbindungen dagegen, während andere Datenbanken im Leerlauf sind:
Und schließlich ist auch die Anzahl der Zeilen-exklusiven Sperren in der testdb-Datenbank hoch:
Stellen Sie sich das jetzt vor. Sie sind ein DBA und verwenden OmniDB zur Verwaltung einer Flotte von PostgreSQL-Instanzen. Sie erhalten einen Anruf, um die langsame Leistung in einer der Instanzen zu untersuchen.
Mit einem Dashboard wie dem, das wir gerade gesehen haben (obwohl es ein sehr einfaches ist), können Sie die Grundursache leicht finden. Sie können die Anzahl der Backends, Sperren, verfügbaren Speicher usw. überprüfen, um festzustellen, was das Problem verursacht.
Und hier kann OmniDB ein wirklich hilfreiches Tool sein.
Erstellen benutzerdefinierter Überwachungseinheiten
Manchmal müssen wir unsere eigenen Überwachungseinheiten erstellen. Um eine neue Überwachungseinheit zu schreiben, klicken wir in der Liste „Einheiten verwalten“ auf die Schaltfläche „Neue Einheit“. Dies öffnet eine neue Registerkarte mit einer leeren Zeichenfläche zum Schreiben von Code:
Oben auf dem Bildschirm müssen wir einen Namen für unsere Überwachungseinheit angeben, ihren Typ auswählen und ihr Standard-Aktualisierungsintervall angeben. Wir können auch eine vorhandene Einheit als Vorlage auswählen.
Unter dem Kopfbereich befinden sich zwei Textfelder. Im „Data Script“-Editor schreiben wir Code, um Daten für unsere Überwachungseinheit zu erhalten. Jedes Mal, wenn eine Einheit aktualisiert wird, wird der Datenskriptcode ausgeführt. Im „Chart Script“-Editor schreiben wir Code zum Zeichnen der eigentlichen Einheit. Dies wird ausgeführt, wenn die Einheit zum ersten Mal gezogen wird.
Der gesamte Datenskriptcode ist in Python geschrieben. Für die Überwachungseinheit des Diagrammtyps muss OmniDB das Diagrammskript in Chart.js schreiben.
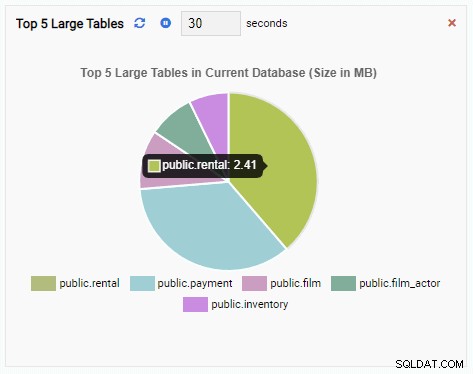
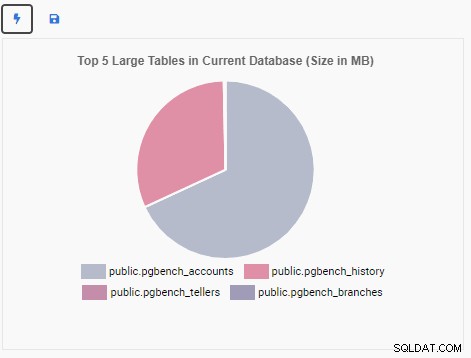
Wir werden jetzt eine Überwachungseinheit erstellen, um die Top 5 der großen Tabellen in der aktuellen Datenbank anzuzeigen. Basierend auf der in OmniDB ausgewählten Datenbank ändert die Überwachungseinheit ihre Anzeige, um die Namen der fünf größten Tabellen in dieser Datenbank wiederzugeben.
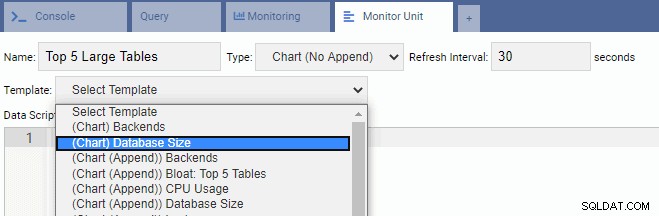
Um eine neue Einheit zu schreiben, ist es am besten, mit einer vorhandenen Vorlage zu beginnen und deren Code zu ändern. Dies spart sowohl Zeit als auch Mühe. In der folgenden Abbildung haben wir unsere Überwachungseinheit „Top 5 Large Tables“ genannt. Wir haben den Diagrammtyp gewählt (kein Anhängen) und eine Aktualisierungsrate von 30 Sekunden bereitgestellt. Wir haben unsere Überwachungseinheit auch auf der Datenbankgrößenvorlage basiert:
Das Textfeld Data Script wird automatisch mit dem Code für Database Size Monitoring Unit:
ausgefülltfrom datetime import datetimefrom random import randintdatabases =connection.Query(''' SELECT d.datname AS dataname, round(pg_catalog.pg_database_size(d.datname)/1048576.0,2) AS size FROM pg_catalog.pg_database d WHERE d. Datenname nicht in ('template0','template1')''')data =[]color =[]label =[]for db in databases.Rows: data.append(db["size"]) color.append( "rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append (db["datname"])total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FROM pg_catalog.pg_database WHERE NOT datistemplate''')result ={ "labels ":label, "datasets":[ { "data":data, "backgroundColor":color, "label":"Dataset 1" } ], "title":"Database Size (Total:" + str(total_size) + "MB)"}Und das Textfeld „Diagrammskript“ wird ebenfalls mit Code ausgefüllt:
total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(dataname)/1048576.0),2) FROM pg_catalog.pg_database WHERE NOT datistemplate''')result ={ "type":"pie" , "data":None, "options":{ "responsive":True, "title":{ "display":True, "text":"Database Size (Total:" + str(total_size) + " MB)" } }}Wir können das Datenskript modifizieren, um die obersten 5 großen Tabellen in der Datenbank zu erhalten. Im folgenden Skript haben wir den größten Teil des Originalcodes beibehalten, mit Ausnahme der SQL-Anweisung:
from datetime import datetimefrom random import randinttables =connection.Query('''SELECT nspname || '.' || relname AS "tablename", round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS " table_size" FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid =C.relnamespace) WO nspname NICHT IN ('pg_catalog', 'information_schema') UND C.relkind <> 'i' UND nspname !~ '^pg_toast' ORDER BY 2 DESC LIMIT 5;''')data =[]color =[]label =[]for table in tables.Rows: data.append(table["table_size"]) color.append("rgb(" + str (randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append(table["tablename" ])result ={ "labels":label, "datasets":[ { "data":data, "backgroundColor":color, "label":"Top 5 Large Tables" } ]}Hier erhalten wir die kombinierte Größe jeder Tabelle und ihrer Indizes in der aktuellen Datenbank. Wir sortieren die Ergebnisse in absteigender Reihenfolge und wählen die obersten fünf Zeilen aus.
Als Nächstes füllen wir drei Python-Arrays, indem wir über die Ergebnismenge iterieren.
Schließlich erstellen wir einen JSON-String basierend auf den Werten der Arrays.
Im Textfeld Diagrammskript haben wir den Code geändert, um den ursprünglichen SQL-Befehl zu entfernen. Hier spezifizieren wir nur den kosmetischen Aspekt des Diagramms. Wir definieren das Diagramm als Kuchentyp und geben ihm einen Titel:
result ={ "type":"pie", "data":None, "options":{ "responsive":True, "title":{ "display":True, "text":"Top 5 Large Tabellen in aktueller Datenbank (Größe in MB)" } }}Jetzt können wir das Gerät testen, indem wir auf das Blitzsymbol klicken. Dadurch wird die neue Überwachungseinheit im Vorschaubereich angezeigt:
Als nächstes speichern wir die Einheit, indem wir auf das Diskettensymbol klicken. Ein Meldungsfeld bestätigt, dass die Einheit gespeichert wurde:
Wir gehen jetzt zurück zu unserem Überwachungs-Dashboard und fügen die neue Überwachungseinheit hinzu:
Beachten Sie, dass wir zwei weitere Symbole unter der Spalte „Aktionen“ für unsere benutzerdefinierte Überwachungseinheit haben. Einer dient zum Bearbeiten, der andere zum Entfernen aus OmniDB.
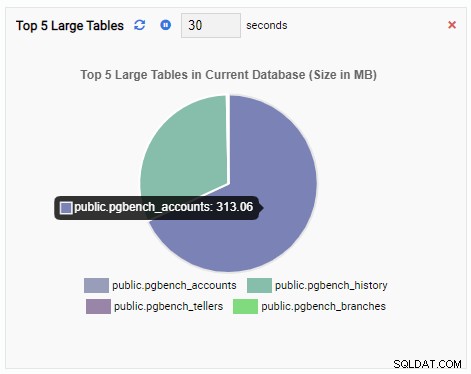
Die Überwachungseinheit „Top 5 Large Tables“ zeigt jetzt die fünf größten Tabellen in der aktuellen Datenbank an:
Wenn wir das Dashboard schließen, vom Navigationsbereich zu einer anderen Datenbank wechseln und das Dashboard erneut öffnen, sehen wir, dass sich die Überwachungseinheit geändert hat, um die Tabellen dieser Datenbank widerzuspiegeln:
Schlussworte
Damit ist unsere zweiteilige Serie zu OmniDB abgeschlossen. Wie wir gesehen haben, verfügt OmniDB über einige raffinierte Überwachungseinheiten, die PostgreSQL-DBAs für die Leistungsverfolgung nützlich finden werden. Wir haben gesehen, wie wir diese Einheiten verwenden können, um potenzielle Engpässe im Server zu identifizieren. Wir haben auch gesehen, wie wir unsere eigenen benutzerdefinierten Einheiten erstellen können. Die Leser werden ermutigt, Leistungsüberwachungseinheiten für ihre spezifischen Workloads zu erstellen und zu testen. 2ndQuadrant begrüßt jeden Beitrag zum GitHub-Repo der OmniDB Monitoring Unit.