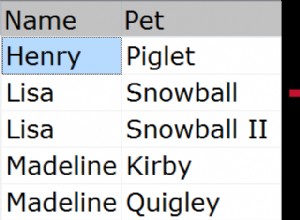
Sie möchten also die Zeile mit dem höchsten OrderField erhalten pro Gruppe? Ich würde es so machen:
SELECT t1.*
FROM `Table` AS t1
LEFT OUTER JOIN `Table` AS t2
ON t1.GroupId = t2.GroupId AND t1.OrderField < t2.OrderField
WHERE t2.GroupId IS NULL
ORDER BY t1.OrderField; // not needed! (note by Tomas)
(EDIT von Tomas: Wenn es innerhalb derselben Gruppe mehrere Datensätze mit demselben OrderField gibt und Sie genau einen davon benötigen, können Sie die Bedingung erweitern:
SELECT t1.*
FROM `Table` AS t1
LEFT OUTER JOIN `Table` AS t2
ON t1.GroupId = t2.GroupId
AND (t1.OrderField < t2.OrderField
OR (t1.OrderField = t2.OrderField AND t1.Id < t2.Id))
WHERE t2.GroupId IS NULL
Ende der Bearbeitung.)
Mit anderen Worten, geben Sie die Zeile t1 zurück für die keine andere Zeile t2 existiert mit derselben GroupId und ein größeres OrderField . Wenn t2.* NULL ist, bedeutet dies, dass der linke äußere Join keine solche Übereinstimmung gefunden hat, und daher t1 hat den größten Wert von OrderField in der Gruppe.
Keine Ränge, keine Unterabfragen. Dies sollte schnell laufen und den Zugriff auf t2 mit "Using index" optimieren, wenn Sie einen zusammengesetzten Index auf (GroupId, OrderField) haben .
Zur Leistung siehe meine Antwort auf Abrufen des letzten Datensatzes in jeder Gruppe . Ich habe eine Unterabfragemethode und die Join-Methode mit dem Stack Overflow-Datendump ausprobiert. Der Unterschied ist beachtlich:Die Join-Methode lief in meinem Test 278-mal schneller.
Es ist wichtig, dass Sie den richtigen Index haben, um die besten Ergebnisse zu erzielen!
In Bezug auf Ihre Methode, die die @Rank-Variable verwendet, funktioniert sie nicht so, wie Sie sie geschrieben haben, da die Werte von @Rank nicht auf Null zurückgesetzt werden, nachdem die Abfrage die erste Tabelle verarbeitet hat. Ich zeige Ihnen ein Beispiel.
Ich habe einige Dummy-Daten eingefügt, mit einem zusätzlichen Feld, das null ist, außer in der Zeile, von der wir wissen, dass sie die größte pro Gruppe ist:
select * from `Table`;
+---------+------------+------+
| GroupId | OrderField | foo |
+---------+------------+------+
| 10 | 10 | NULL |
| 10 | 20 | NULL |
| 10 | 30 | foo |
| 20 | 40 | NULL |
| 20 | 50 | NULL |
| 20 | 60 | foo |
+---------+------------+------+
Wir können zeigen, dass sich der Rang für die erste Gruppe auf drei und für die zweite Gruppe auf sechs erhöht, und die innere Abfrage gibt diese korrekt zurück:
select GroupId, max(Rank) AS MaxRank
from (
select GroupId, @Rank := @Rank + 1 AS Rank
from `Table`
order by OrderField) as t
group by GroupId
+---------+---------+
| GroupId | MaxRank |
+---------+---------+
| 10 | 3 |
| 20 | 6 |
+---------+---------+
Führen Sie nun die Abfrage ohne Join-Bedingung aus, um ein kartesisches Produkt aller Zeilen zu erzwingen, und wir rufen auch alle Spalten ab:
select s.*, t.*
from (select GroupId, max(Rank) AS MaxRank
from (select GroupId, @Rank := @Rank + 1 AS Rank
from `Table`
order by OrderField
) as t
group by GroupId) as t
join (
select *, @Rank := @Rank + 1 AS Rank
from `Table`
order by OrderField
) as s
-- on t.GroupId = s.GroupId and t.MaxRank = s.Rank
order by OrderField;
+---------+---------+---------+------------+------+------+
| GroupId | MaxRank | GroupId | OrderField | foo | Rank |
+---------+---------+---------+------------+------+------+
| 10 | 3 | 10 | 10 | NULL | 7 |
| 20 | 6 | 10 | 10 | NULL | 7 |
| 10 | 3 | 10 | 20 | NULL | 8 |
| 20 | 6 | 10 | 20 | NULL | 8 |
| 20 | 6 | 10 | 30 | foo | 9 |
| 10 | 3 | 10 | 30 | foo | 9 |
| 10 | 3 | 20 | 40 | NULL | 10 |
| 20 | 6 | 20 | 40 | NULL | 10 |
| 10 | 3 | 20 | 50 | NULL | 11 |
| 20 | 6 | 20 | 50 | NULL | 11 |
| 20 | 6 | 20 | 60 | foo | 12 |
| 10 | 3 | 20 | 60 | foo | 12 |
+---------+---------+---------+------------+------+------+
Aus dem Obigen können wir ersehen, dass der maximale Rang pro Gruppe korrekt ist, aber dann steigt der @Rank weiter an, während er die zweite abgeleitete Tabelle verarbeitet, auf 7 und höher. Daher werden sich die Ränge der zweiten abgeleiteten Tabelle niemals mit den Rängen der ersten abgeleiteten Tabelle überschneiden.
Sie müssten eine weitere abgeleitete Tabelle hinzufügen, um zu erzwingen, dass @Rank zwischen der Verarbeitung der beiden Tabellen auf Null zurückgesetzt wird (und hoffen, dass der Optimierer die Reihenfolge, in der er Tabellen auswertet, nicht ändert, oder verwenden Sie STRAIGHT_JOIN, um dies zu verhindern):
select s.*
from (select GroupId, max(Rank) AS MaxRank
from (select GroupId, @Rank := @Rank + 1 AS Rank
from `Table`
order by OrderField
) as t
group by GroupId) as t
join (select @Rank := 0) r -- RESET @Rank TO ZERO HERE
join (
select *, @Rank := @Rank + 1 AS Rank
from `Table`
order by OrderField
) as s
on t.GroupId = s.GroupId and t.MaxRank = s.Rank
order by OrderField;
+---------+------------+------+------+
| GroupId | OrderField | foo | Rank |
+---------+------------+------+------+
| 10 | 30 | foo | 3 |
| 20 | 60 | foo | 6 |
+---------+------------+------+------+
Aber die Optimierung dieser Abfrage ist schrecklich. Es kann keine Indizes verwenden, es erstellt zwei temporäre Tabellen, sortiert sie auf die harte Tour und verwendet sogar einen Join-Puffer, da es beim Join von temporären Tabellen auch keinen Index verwenden kann. Dies ist eine Beispielausgabe von EXPLAIN :
+----+-------------+------------+--------+---------------+------+---------+------+------+---------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+------+---------+------+------+---------------------------------+
| 1 | PRIMARY | <derived4> | system | NULL | NULL | NULL | NULL | 1 | Using temporary; Using filesort |
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 2 | |
| 1 | PRIMARY | <derived5> | ALL | NULL | NULL | NULL | NULL | 6 | Using where; Using join buffer |
| 5 | DERIVED | Table | ALL | NULL | NULL | NULL | NULL | 6 | Using filesort |
| 4 | DERIVED | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
| 2 | DERIVED | <derived3> | ALL | NULL | NULL | NULL | NULL | 6 | Using temporary; Using filesort |
| 3 | DERIVED | Table | ALL | NULL | NULL | NULL | NULL | 6 | Using filesort |
+----+-------------+------------+--------+---------------+------+---------+------+------+---------------------------------+
Während meine Lösung mit dem linken äußeren Join viel besser optimiert wird. Es verwendet keine temporäre Tabelle und meldet sogar "Using index" was bedeutet, dass es den Join nur mit dem Index auflösen kann, ohne die Daten zu berühren.
+----+-------------+-------+------+---------------+---------+---------+-----------------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------+---------+-----------------+------+--------------------------+
| 1 | SIMPLE | t1 | ALL | NULL | NULL | NULL | NULL | 6 | Using filesort |
| 1 | SIMPLE | t2 | ref | GroupId | GroupId | 5 | test.t1.GroupId | 1 | Using where; Using index |
+----+-------------+-------+------+---------------+---------+---------+-----------------+------+--------------------------+
Sie werden wahrscheinlich Leute lesen, die in ihren Blogs behaupten, dass "Joins SQL langsam machen", aber das ist Unsinn. Schlechte Optimierung macht SQL langsam.