Einführung
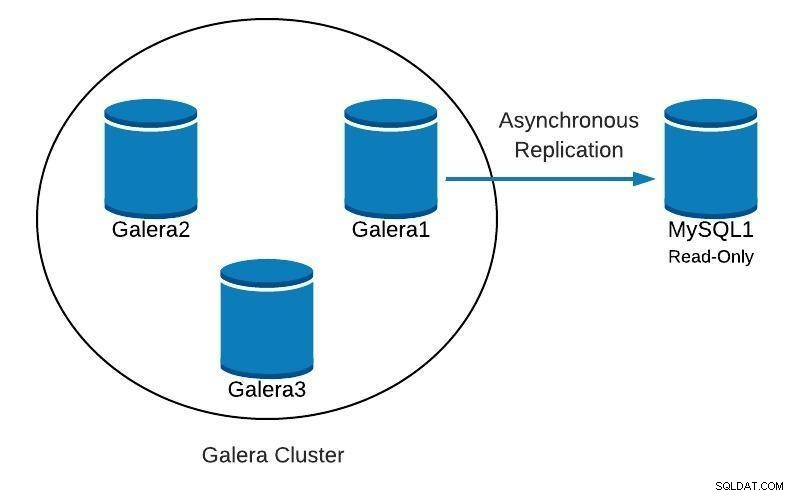
Beim Ausführen von Galera Cluster ist es üblich, einen oder mehrere asynchrone Slaves im selben oder in einem anderen Rechenzentrum hinzuzufügen. Dies bietet uns einen Notfallplan mit niedriger RTO und niedrigen Betriebskosten. Im Falle eines nicht behebbaren Problems in unserem Cluster können wir schnell darauf umschalten, sodass Anwendungen weiterhin auf Daten zugreifen können.
Wenn Sie diese Art von Setup verwenden, können wir unseren Cluster nicht einfach aus einer früheren Sicherung neu erstellen. Da der asynchrone Slave nun die neue Quelle der Wahrheit ist, müssen wir den Cluster daraus neu erstellen.
Das bedeutet nicht, dass wir nur einen Weg haben, es zu tun, vielleicht gibt es sogar einen besseren Weg! Fühlen Sie sich frei, uns Ihre Vorschläge im Kommentarbereich am Ende dieses Beitrags mitzuteilen.
Topologie
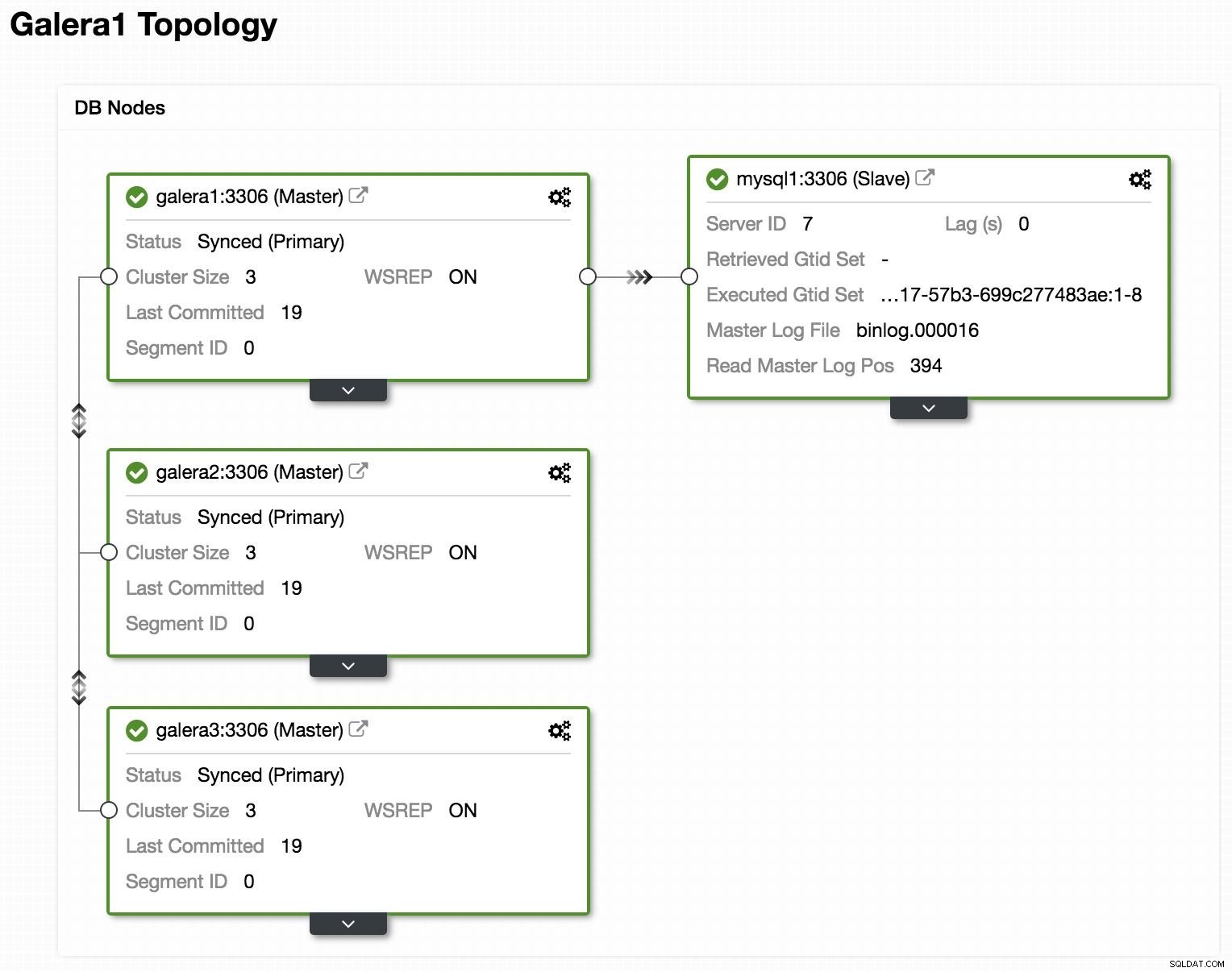 ClusterControl-Topologieansicht online
ClusterControl-Topologieansicht online Oben sehen wir eine Beispieltopologie mit Galera Cluster und einem asynchronen Replikat/Slave.
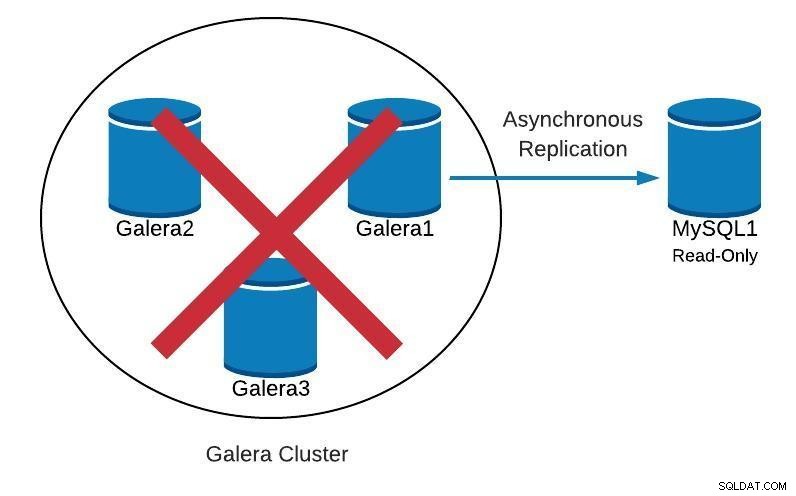
 Datenbankdiagramm 1
Datenbankdiagramm 1 Als nächstes werden wir sehen, wie wir unseren Cluster ausgehend vom Slave neu erstellen können, falls wir so etwas finden:
 Datenbankdiagramm 2
Datenbankdiagramm 2 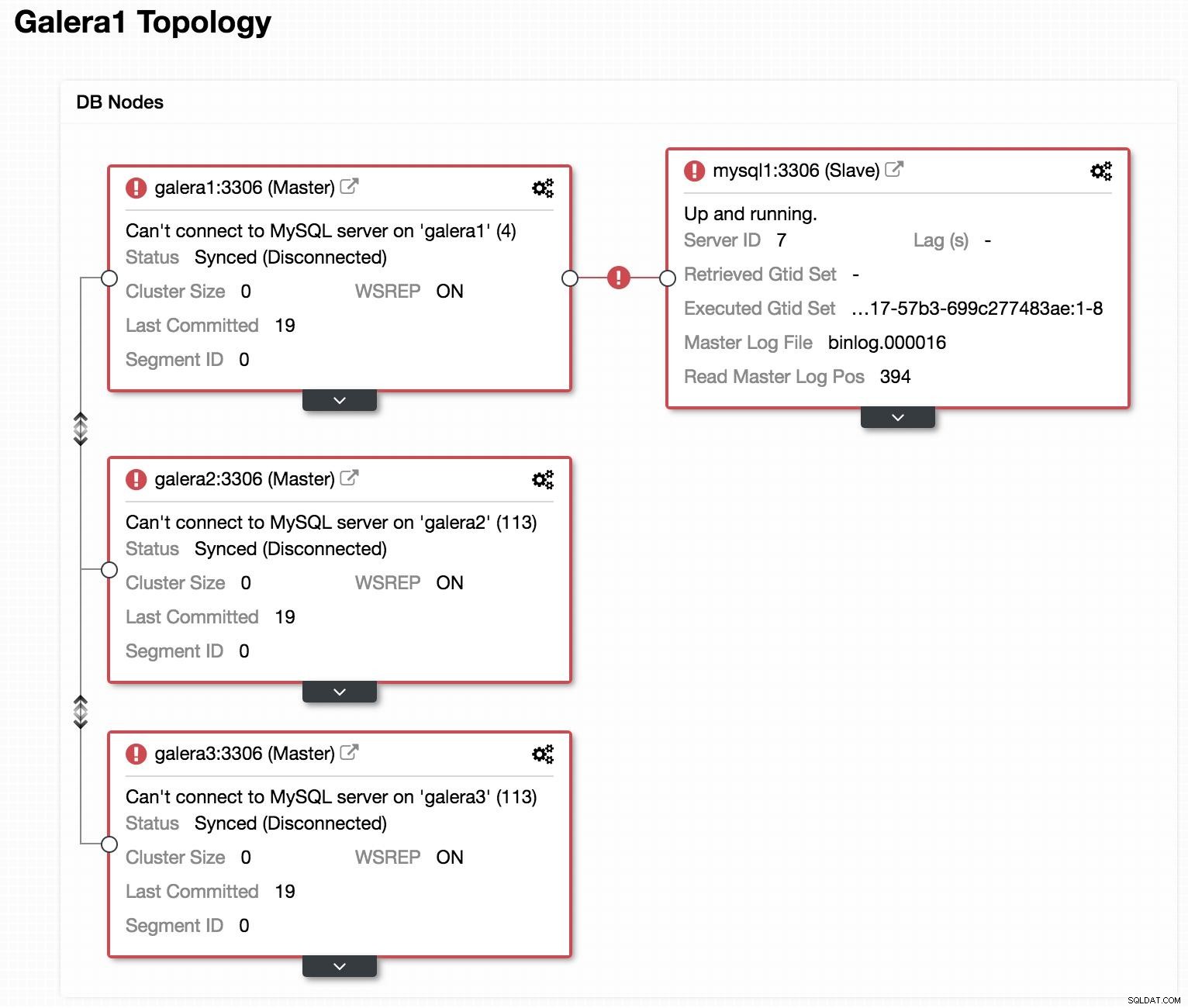 ClusterControl-Topologieansicht offline
ClusterControl-Topologieansicht offline Wenn wir uns das vorherige Bild ansehen, können wir sehen, dass unsere 3 Galera-Knoten ausgefallen sind. Unser Slave ist nicht in der Lage, sich mit dem Galera-Master zu verbinden, aber er befindet sich im Status "Up and running".
Sklave befördern
Da unser Sklave richtig arbeitet, können wir ihn zum Meister machen und unsere Bewerbungen darauf ausrichten. Dazu müssen wir den Nur-Lese-Parameter in unserem Slave deaktivieren und die Slave-Konfiguration zurücksetzen.
In unserem Slave (mysql1):
mysql> SET GLOBAL read_only=0;
Query OK, 0 rows affected (0.00 sec)
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.00 sec)
mysql> RESET SLAVE;
Query OK, 0 rows affected (0.18 sec)Neuen Cluster erstellen
Als Nächstes erstellen wir einen neuen Galera-Cluster, um mit der Wiederherstellung unseres ausgefallenen Clusters zu beginnen. Das geht ganz einfach über ClusterControl ClusterControl, bitte scrollen Sie in diesem Blog weiter nach unten, um zu sehen, wie.
Sobald wir unseren neuen Galera-Cluster bereitgestellt haben, hätten wir etwa Folgendes:
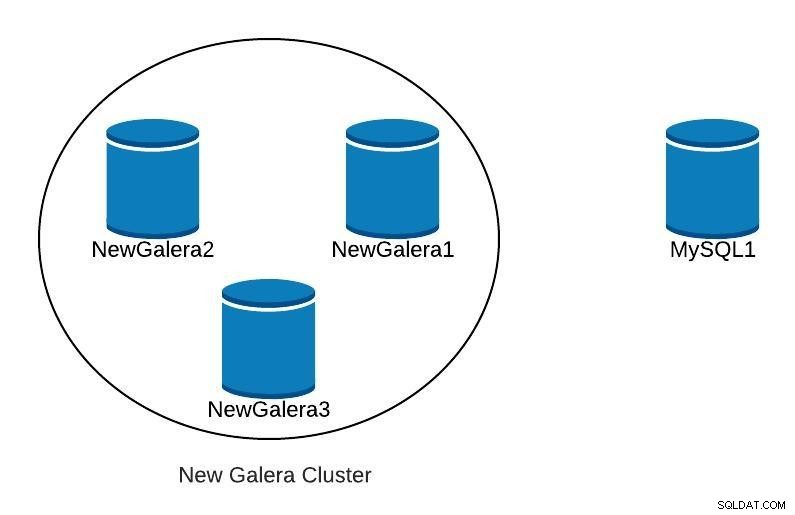 Datenbankdiagramm 3
Datenbankdiagramm 3 Replikation
Wir müssen sicherstellen, dass die Replikationsparameter konfiguriert sind.
Für Galera-Knoten (galera1, galera2, galera3):
server_id=<ID> # Different value in each node
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-bin
expire_logs_days = 7Für Master-Knoten (mysql1):
server_id=<ID> # Different value in each node
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
gtid_mode=ON
enforce_gtid_consistency=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON
sync_binlog=1
report_host=<HOSTNAME or IP> # Local serverDamit sich unser neuer Slave (galera1) mit unserem neuen Master (mysql1) verbinden kann, müssen wir in unserem Master einen Benutzer mit Replikationsberechtigungen erstellen.
In unserem neuen Master (mysql1):
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%' IDENTIFIED BY 'slave_password';Hinweis:Wir können das "%" durch die IP des Galera-Cluster-Knotens ersetzen, der unser Slave sein wird, in unserem Beispiel galera1.
Sicherung
Wenn wir es nicht haben, müssen wir ein konsistentes Backup unseres Masters (mysql1) erstellen und es in unseren neuen Galera-Cluster laden. Dazu können wir das XtraBackup-Tool oder mysqldump verwenden. Sehen wir uns beide Optionen an.
In unserem Beispiel verwenden wir die zum Testen verfügbare sakila-Datenbank.
XtraBackup-Tool
Das Backup erstellen wir im neuen Master (mysql1). In unserem Fall senden wir es an das lokale Verzeichnis /root/backup:
$ innobackupex /root/backup/Wir müssen die Nachricht erhalten:
180705 22:08:14 completed OK!Wir komprimieren das Backup und senden es an den Knoten, der unser Slave sein wird (galera1):
$ cd /root/backup
$ tar zcvf 2018-07-05_22-08-07.tar.gz 2018-07-05_22-08-07
$ scp /root/backup/2018-07-05_22-08-07.tar.gz galera1:/root/backup/Extrahieren Sie in galera1 das Backup:
$ tar zxvf /root/backup/2018-07-05_22-08-07.tar.gzWir stoppen den Cluster (falls er gestartet wurde). Dazu stoppen wir die mysql-Dienste der 3 Knoten:
$ service mysql stopIn galera1 benennen wir das Datenverzeichnis von mysql um und laden das Backup:
$ mv /var/lib/mysql /var/lib/mysql.bak
$ innobackupex --copy-back /root/backup/2018-07-05_22-08-07Wir müssen die Nachricht erhalten:
180705 23:00:01 completed OK!Wir weisen dem Datenverzeichnis die richtigen Berechtigungen zu:
$ chown -R mysql.mysql /var/lib/mysqlDann müssen wir den Cluster initialisieren.
Sobald der erste Knoten initialisiert ist, müssen wir den MySQL-Dienst für die verbleibenden Knoten starten, alle vorherigen Kopien der Datei grastate.dat löschen und dann überprüfen, ob unsere Daten aktualisiert sind.
$ rm /var/lib/mysql/grastate.dat
$ service mysql startHinweis:Stellen Sie sicher, dass der von XtraBackup verwendete Benutzer in unserem initialisierten Knoten erstellt wurde und in jedem Knoten gleich ist.
mysqldump
Im Allgemeinen empfehlen wir nicht, dies mit mysqldump zu tun, da es bei einem großen Datenvolumen ziemlich langsam sein kann. Aber es ist eine Alternative, um die Aufgabe auszuführen.
Das Backup erstellen wir im neuen Master (mysql1):
$ mysqldump -uroot -p --single-transaction --skip-add-locks --triggers --routines --events --databases sakila > /root/backup/sakila_dump.sqlWir komprimieren es und senden es an unseren Slave-Knoten (galera1):
$ gzip /root/backup/sakila_dump.sql
$ scp /root/backup/sakila_dump.sql.gz galera1:/root/backup/Wir laden den Dump in galera1.
$ gunzip /root/backup/sakila_dump.sql.gz
$ mysql -p < /root/backup/sakila_dump.sqlWenn der Dump in galera1 geladen ist, müssen wir den MySQL-Dienst auf den verbleibenden Knoten neu starten, die Datei grastate.dat entfernen und überprüfen, ob wir unsere Daten aktualisiert haben.
$ rm /var/lib/mysql/grastate.dat
$ service mysql startReplikations-Slave starten
Unabhängig davon, welche Option wir wählen, XtraBackup oder mysqldump, wenn alles gut gelaufen ist, können wir in diesem Schritt bereits die Replikation in dem Knoten aktivieren, der unser Slave sein wird (galera1).
$ mysql> CHANGE MASTER TO MASTER_HOST = 'mysql1', MASTER_PORT = 3306, MASTER_USER = 'slave_user', MASTER_PASSWORD = 'slave_password', MASTER_AUTO_POSITION = 1;
$ mysql> START SLAVE;Wir überprüfen, ob der Slave funktioniert:
mysql> SHOW SLAVE STATUS\G
Slave_IO_Running: Yes
Slave_SQL_Running: YesAn diesem Punkt haben wir etwa Folgendes:
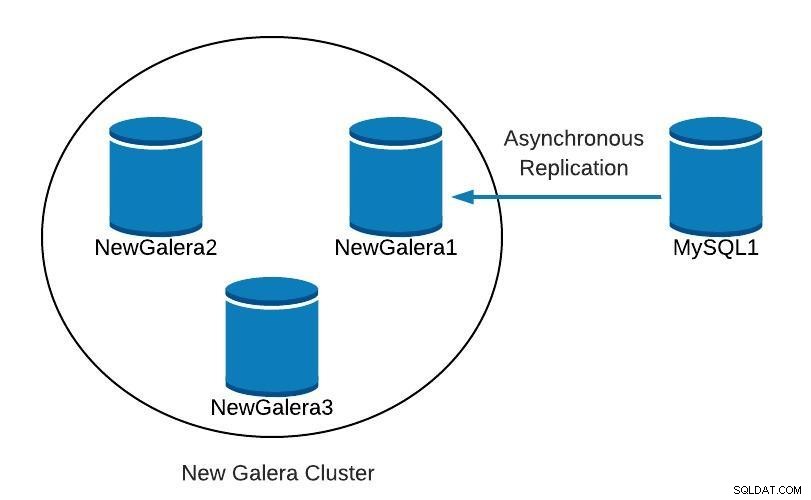 Datenbankdiagramm 4
Datenbankdiagramm 4 Nachdem NewGalera1 auf dem neuesten Stand ist, können wir die Anwendung auf unseren neuen Galera-Cluster verweisen und die asynchrone Replikation neu konfigurieren.
ClusterControl
Wie wir bereits erwähnt haben, können wir mit ClusterControl mehrere der oben genannten Aufgaben mit ein paar einfachen Klicks erledigen. Es verfügt auch über automatische Wiederherstellungsoptionen, sowohl für die Knoten als auch für den Cluster. Sehen wir uns einige Aufgaben an, bei denen es helfen kann.
 ClusterControl-Bereitstellung 1
ClusterControl-Bereitstellung 1 Um eine Bereitstellung durchzuführen, wählen Sie einfach die Option „Datenbankcluster bereitstellen“ und folgen Sie den angezeigten Anweisungen.
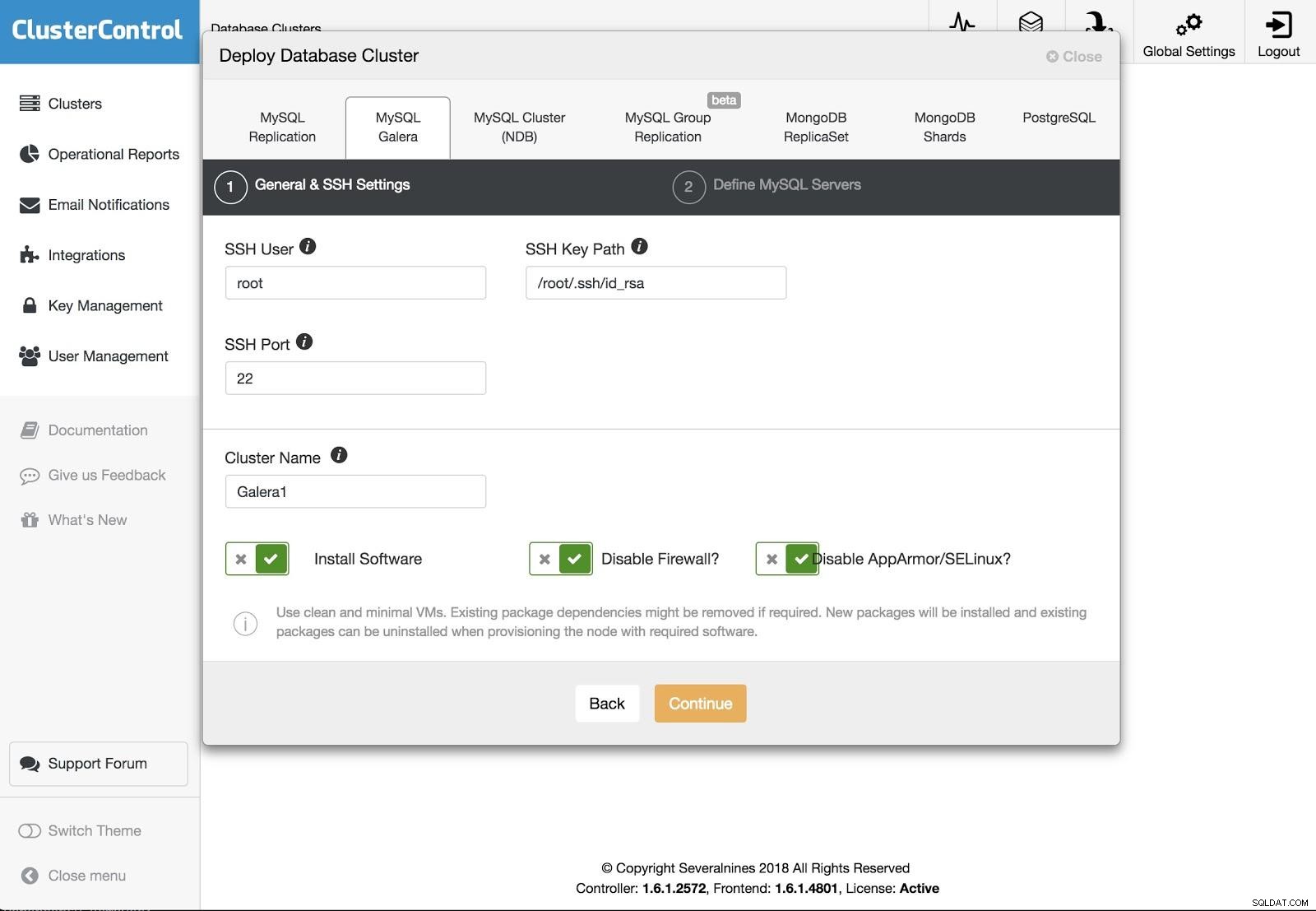 ClusterControl-Bereitstellung 2
ClusterControl-Bereitstellung 2 Wir können zwischen verschiedenen Arten von Technologien und Anbietern wählen. Wir müssen Benutzer, Schlüssel oder Passwort und Port angeben, um uns per SSH mit unseren Servern zu verbinden. Wir brauchen auch den Namen für unseren neuen Cluster und wenn wir möchten, dass ClusterControl die entsprechende Software und Konfigurationen für uns installiert.
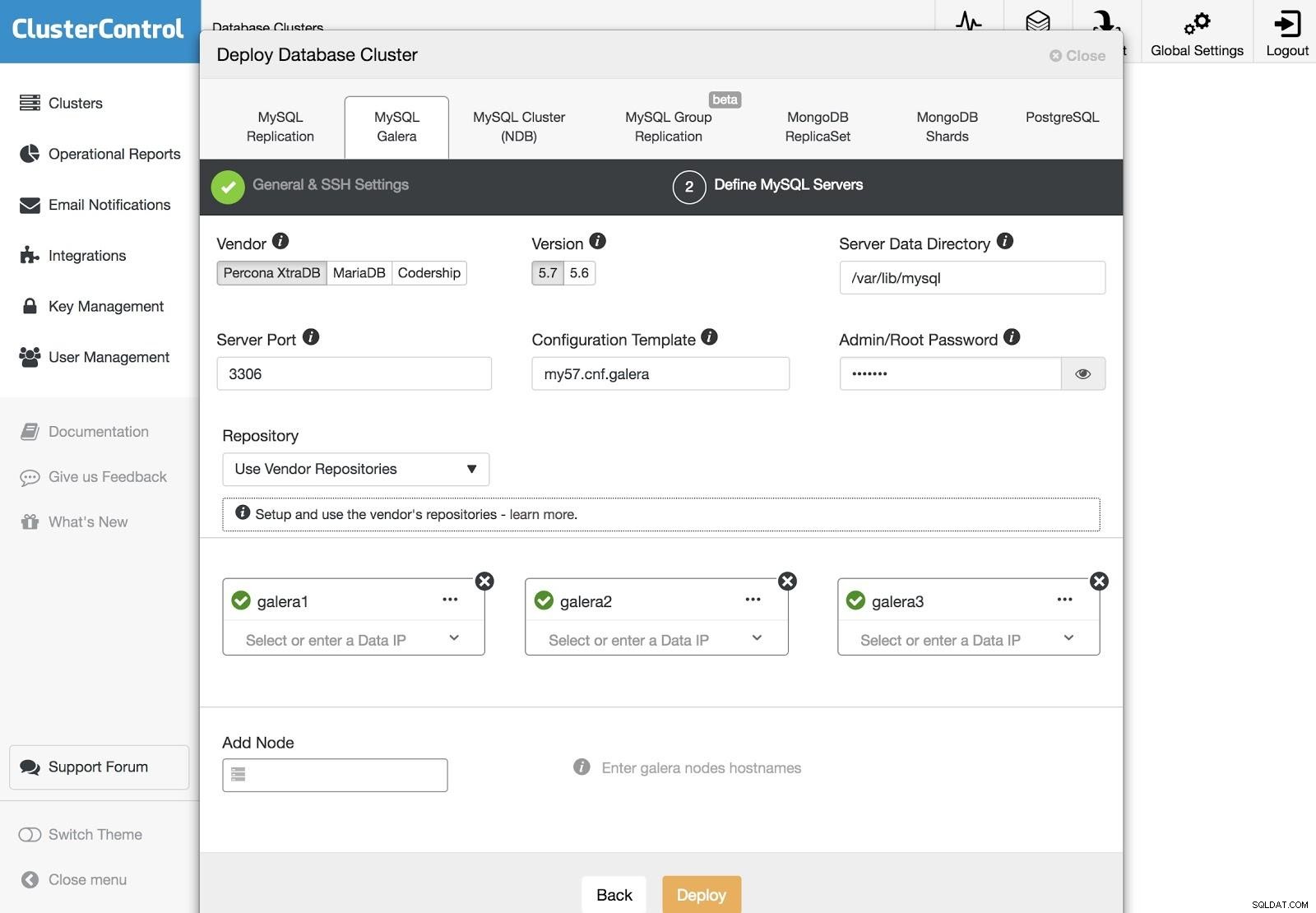 ClusterControl-Bereitstellung 3
ClusterControl-Bereitstellung 3 Nach dem Einrichten der SSH-Zugangsinformationen müssen wir die Knoten in unserem Cluster definieren. Wir können auch angeben, welches Repository verwendet werden soll. Wir müssen unsere Server zu dem Cluster hinzufügen, den wir erstellen werden.
Wir können den Status der Erstellung unseres neuen Clusters über den Aktivitätsmonitor von ClusterControl überwachen.
Außerdem können wir mit den gleichen Schritten einen Import unseres aktuellen Clusters oder unserer aktuellen Datenbank durchführen. In diesem Fall installiert ClusterControl die Datenbanksoftware nicht, da bereits eine Datenbank läuft.
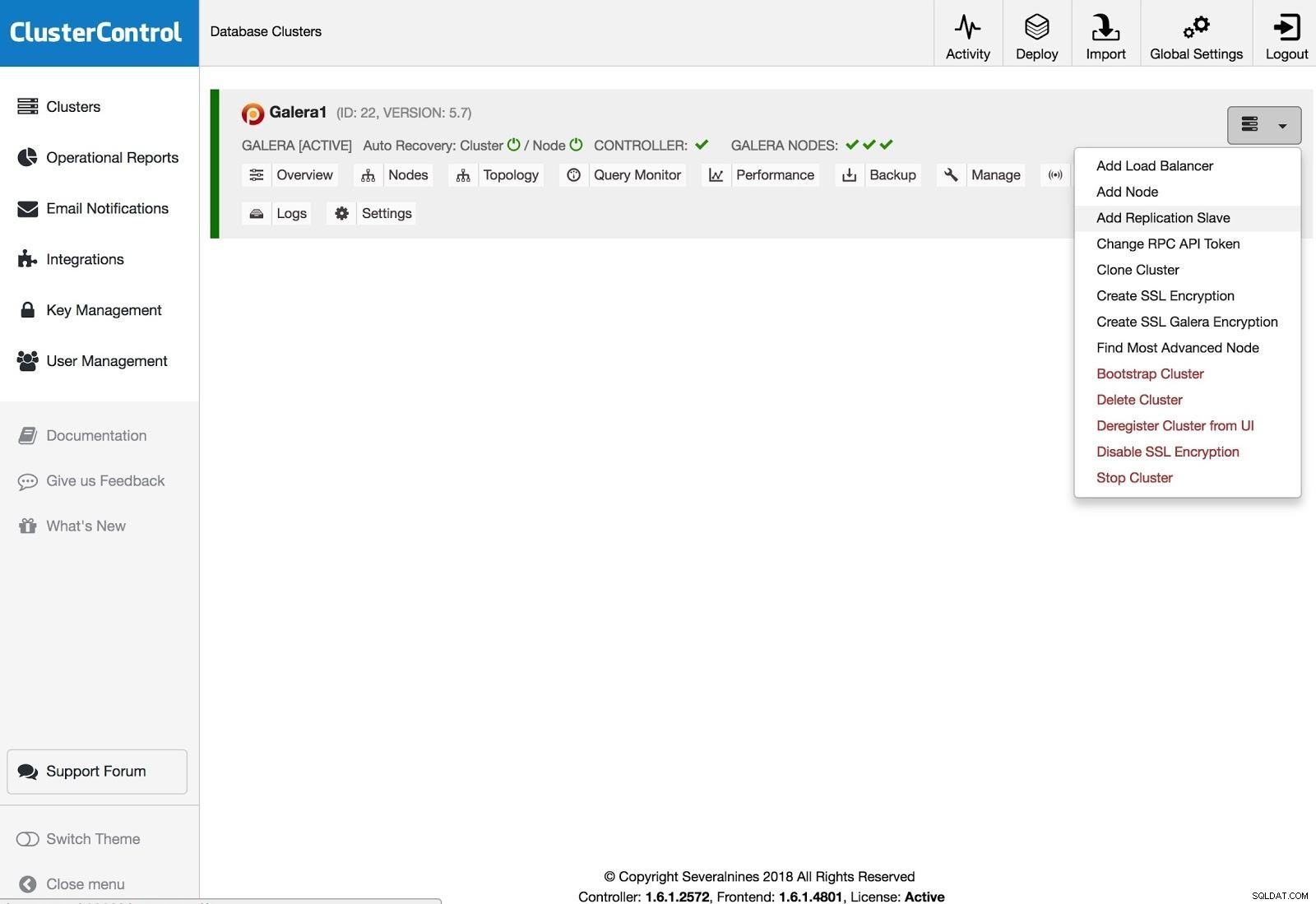 ClusterControl fügt Replikationssalve hinzu
ClusterControl fügt Replikationssalve hinzu Um einen Replikations-Slave hinzuzufügen, müssen Sie auf Clusteraktionen klicken, Replikations-Slave hinzufügen auswählen und die SSH-Zugangsinformationen des neuen Servers hinzufügen. ClusterControl wird sich mit dem Server verbinden, um die notwendigen Konfigurationen für diese Aktion vorzunehmen.
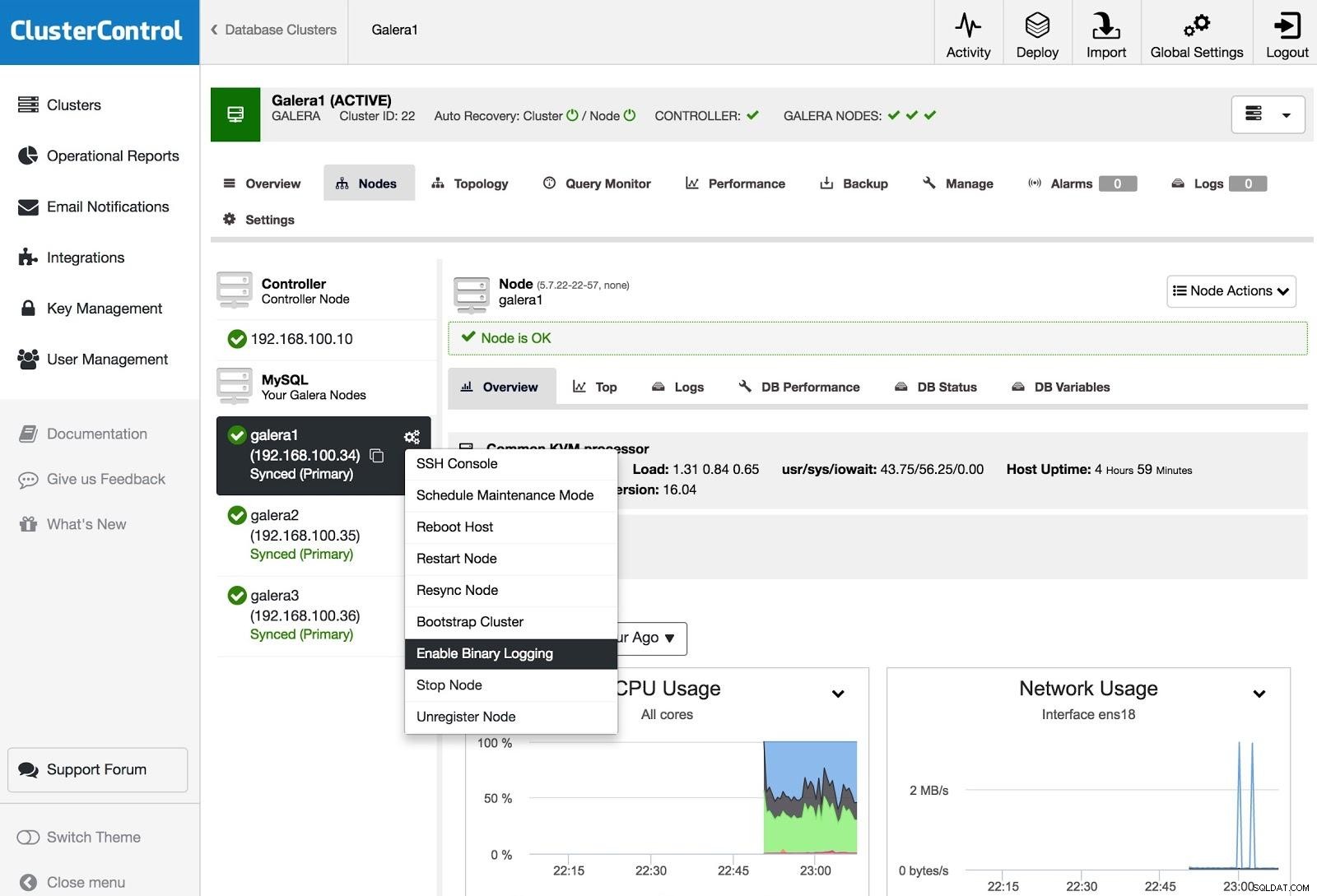 ClusterControl Binäre Protokollierung aktivieren
ClusterControl Binäre Protokollierung aktivieren Um einen oder mehrere Galera-Knoten in Master-Server umzuwandeln (wie im Sinne der Erstellung von Binlogs), können Sie zu Node Actions gehen und Enable Binary Logging auswählen.
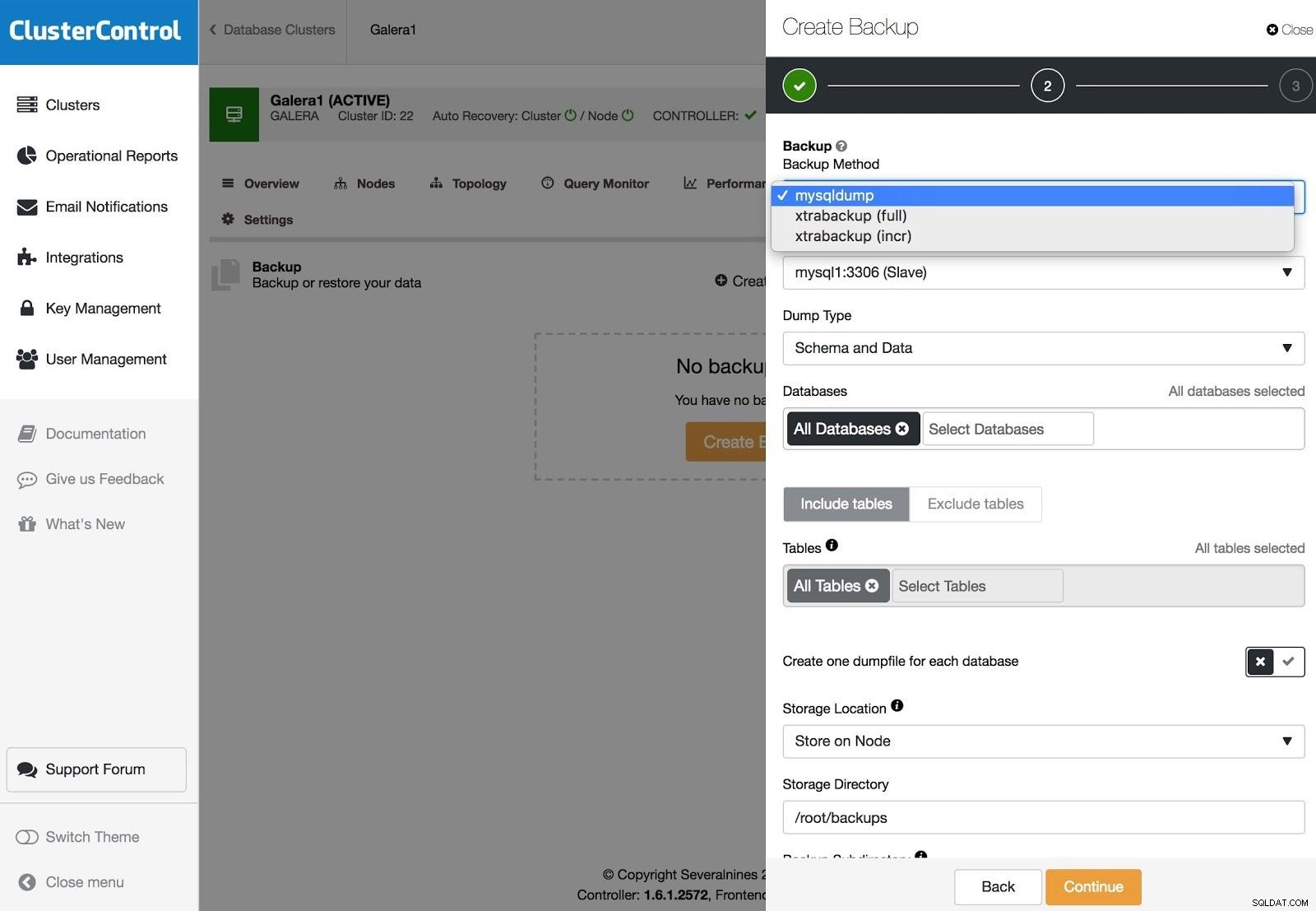 ClusterControl-Sicherungen
ClusterControl-Sicherungen Backups können mit XtraBackup (vollständig oder inkrementell) und mysqldump konfiguriert werden, und Sie haben weitere Optionen wie Hochladen des Backups in die Cloud, Verschlüsselung, Komprimierung, Zeitplan und mehr.
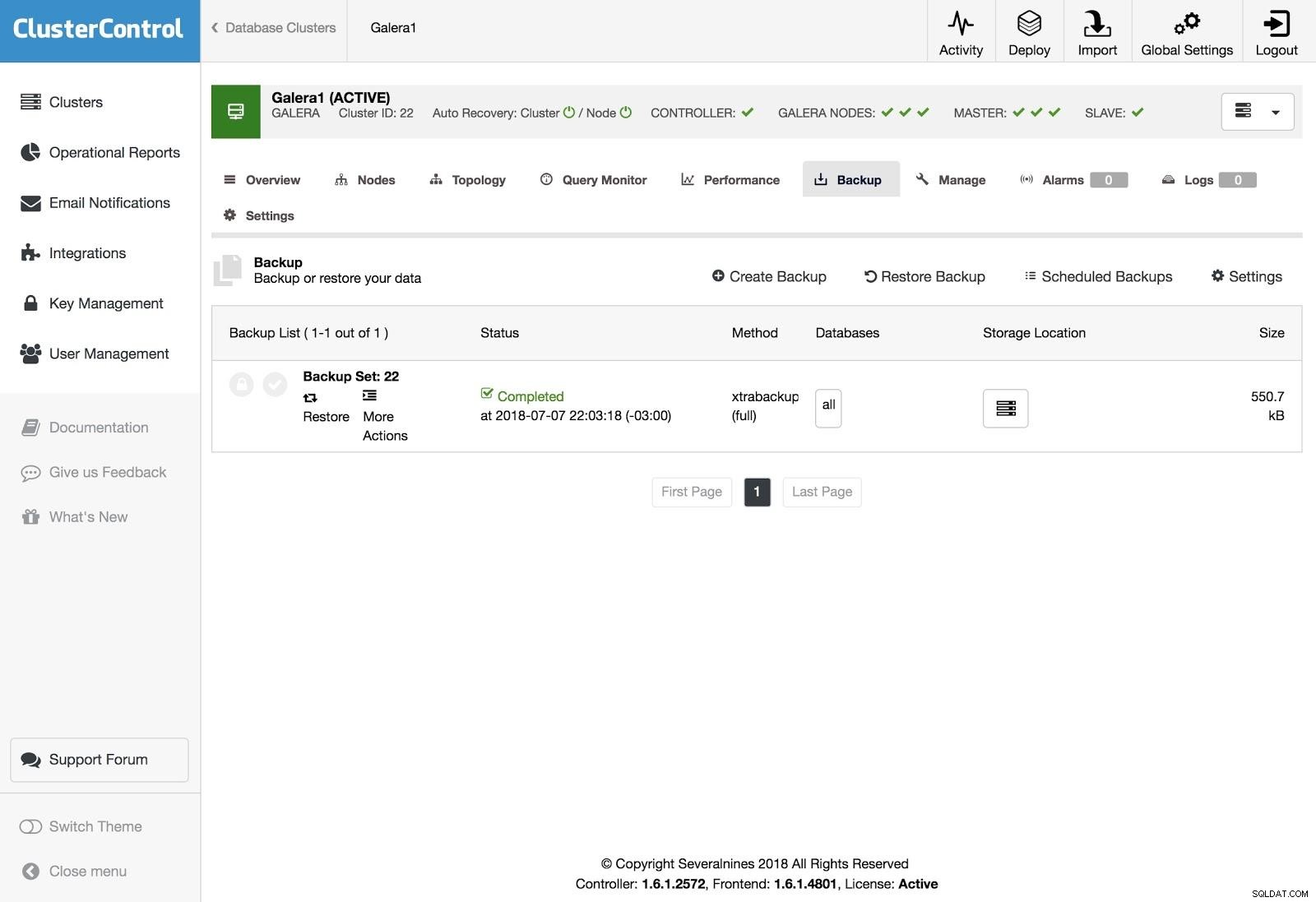 ClusterControl-Wiederherstellung
ClusterControl-Wiederherstellung Um die Sicherung wiederherzustellen, gehen Sie zur Registerkarte Sicherung und wählen Sie die Option Wiederherstellen, dann wählen Sie aus, auf welchem Server Sie wiederherstellen möchten.
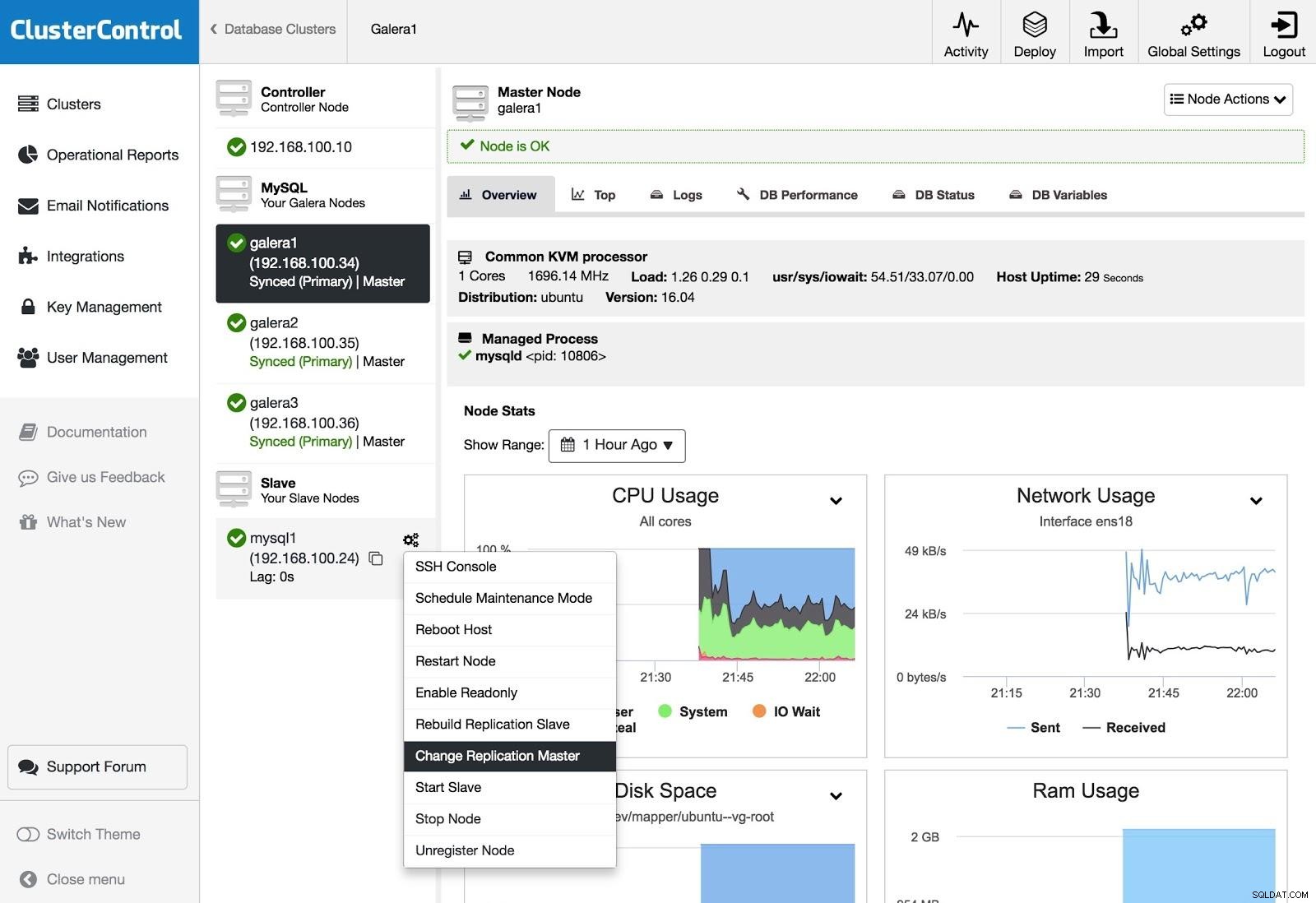 ClusterControl Change Replication Master
ClusterControl Change Replication Master Wenn Sie einen Slave haben und den Master ändern oder die Replikation neu erstellen möchten, können Sie zu Node Actions gehen und die Option auswählen.
Schlussfolgerung
Wie wir sehen konnten, haben wir mehrere Möglichkeiten, unser Ziel zu erreichen, einige komplexer, andere benutzerfreundlicher, aber mit jeder von ihnen können Sie einen Cluster aus einem asynchronen Slave neu erstellen. Xtrabackup würde bei größeren Datenmengen schneller wiederherstellen. Zum Schutz vor Bedienerfehlern (z. B. einer fehlerhaften DROP TABLE) könnten Sie auch einen verzögerten Slave verwenden, damit Sie hoffentlich Zeit haben, die Weitergabe der Anweisung zu stoppen.
Wir hoffen, dass diese Informationen nützlich sind und Sie sie niemals in der Produktion verwenden müssen;)