In den beiden vorherigen Artikeln dieser Serie haben wir besprochen, wie Python und SQLAlchemy verwendet werden, um den ETL-Prozess durchzuführen. Heute machen wir dasselbe, aber diesmal mit Python und SQL Alchemy ohne SQL-Befehle im Textformat. Dadurch können wir SQLAlchemy unabhängig von der Datenbank-Engine verwenden, mit der wir verbunden sind. Fangen wir also an.
Heute besprechen wir, wie der ETL-Prozess mit Python und SQLAlchemy durchgeführt wird. Wir erstellen ein Skript, um tägliche Daten aus unserer Betriebsdatenbank zu extrahieren, sie umzuwandeln und dann in unser Data Warehouse zu laden.
Dies ist der dritte Artikel in der Serie. Wenn Sie die ersten beiden Artikel (Using Python and MySQL in the ETL Process und SQLAlchemy) noch nicht gelesen haben, empfehle ich Ihnen dringend, dies zu tun, bevor Sie fortfahren.
Diese gesamte Serie ist eine Fortsetzung unserer Data-Warehouse-Serie:
- Erstellen eines DWH, Teil 1:Ein Abonnement-Geschäftsdatenmodell
- Erstellen eines DWH, Teil 2:Ein Abonnement-Geschäftsdatenmodell
- Erstellen eines Data Warehouse, Teil 3:Ein Abonnement-Geschäftsdatenmodell
Okay, fangen wir jetzt mit dem heutigen Thema an. Sehen wir uns zunächst die Datenmodelle an.
Die Datenmodelle
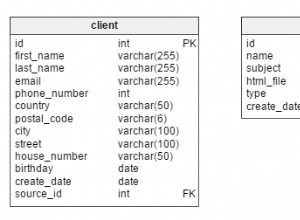
Betriebliches (Live-)Datenbankdatenmodell
DWH-Datenmodell
Dies sind die beiden Datenmodelle, die wir verwenden werden. Weitere Informationen zu Data Warehouses (DWHs) finden Sie in diesen Artikeln:
- Das Sternenschema
- Das Snowflake-Schema
- Sternenschema vs. Schneeflockenschema
Warum SQLAlchemy?
Die ganze Idee hinter SQLAlchemy ist, dass wir nach dem Importieren von Datenbanken keinen SQL-Code benötigen, der für die zugehörige Datenbank-Engine spezifisch ist. Stattdessen können wir Objekte in SQLAlchemy importieren und die SQLAlchemy-Syntax für Anweisungen verwenden. Dadurch können wir dieselbe Sprache verwenden, unabhängig davon, mit welcher Datenbank-Engine wir verbunden sind. Der Hauptvorteil hier ist, dass sich ein Entwickler nicht um die Unterschiede zwischen verschiedenen Datenbank-Engines kümmern muss. Ihr SQLAlchemy-Programm funktioniert genau gleich (mit geringfügigen Änderungen), wenn Sie zu einer anderen Datenbank-Engine migrieren.
Ich habe mich entschieden, nur SQLAlchemy-Befehle und Python-Listen zu verwenden, um mit dem temporären Speicher und zwischen verschiedenen Datenbanken zu kommunizieren. Die Hauptgründe für diese Entscheidung sind, dass 1) Python-Listen bekannt sind und 2) der Code für Personen ohne Python-Kenntnisse lesbar wäre.
Das soll nicht heißen, dass SQLAlchemy perfekt ist. Es hat bestimmte Einschränkungen, die wir später besprechen werden. Werfen wir zunächst einen Blick auf den folgenden Code:

Ausführen des Skripts und Ergebnis
Dies ist der Python-Befehl, der zum Aufrufen unseres Skripts verwendet wird. Das Skript prüft die Daten in der operativen Datenbank, vergleicht die Werte mit dem DWH und importiert die neuen Werte. In diesem Beispiel aktualisieren wir Werte in zwei Dimensionstabellen und einer Faktentabelle; Das Skript gibt die entsprechende Ausgabe zurück. Das gesamte Skript ist so geschrieben, dass Sie es mehrmals am Tag ausführen können. Es werden „alte“ Daten für diesen Tag gelöscht und durch neue ersetzt.
Analysieren wir das gesamte Skript, beginnend von oben.
SQLAlchemy importieren
Als erstes müssen wir die Module importieren, die wir im Skript verwenden werden. Normalerweise importieren Sie Ihre Module, während Sie das Skript schreiben. In den meisten Fällen wissen Sie zu Beginn nicht genau, welche Module Sie benötigen.
from datetime import date # import SQLAlchemy from sqlalchemy import create_engine, select, MetaData, Table, and_, func, case
Wir haben Pythons datetime importiert Modul, das uns Klassen liefert, die mit Datumsangaben arbeiten.
Als nächstes haben wir die sqlalchemy Modul. Wir werden nicht das ganze Modul importieren, sondern nur die Dinge, die wir brauchen – einige spezifisch für SQLAlchemy (create_engine , MetaData , Table ), einige SQL-Anweisungsteile (select , and_ , case ) und func , wodurch wir Funktionen wie count() verwenden können und sum() .
Verbindung zu den Datenbanken herstellen
Wir müssen eine Verbindung zu zwei Datenbanken auf unserem Server herstellen. Wir könnten uns bei Bedarf mit weiteren Datenbanken (MySQL, SQL Server oder anderen) von verschiedenen Servern verbinden. In diesem Fall sind beide Datenbanken MySQL-Datenbanken und werden auf meinem lokalen Rechner gespeichert.
# connect to databases
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
engine_dwh = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_dwh')
connection_dwh = engine_dwh.connect()
metadata = MetaData(bind=None)
Wir haben zwei Engines und zwei Verbindungen erstellt. Ich werde hier nicht ins Detail gehen, weil wir diesen Teil bereits im vorherigen Artikel erklärt haben.
Aktualisierung der dim_time Abmessung
Ziel:Füge das gestrige Datum ein, falls es noch nicht in der Tabelle eingefügt ist.
In unserem Skript aktualisieren wir zwei Dimensionstabellen mit neuen Werten. Der Rest von ihnen folgt dem gleichen Muster, also gehen wir das nur einmal durch; wir müssen den fast identischen Code nicht noch ein paar Mal aufschreiben.
Die Idee ist sehr einfach. Wir führen das Skript immer aus, um neue Daten für gestern einzufügen. Daher müssen wir prüfen, ob dieses Datum in die Dimensionstabelle eingefügt wurde. Wenn es bereits da ist, werden wir nichts tun; Wenn nicht, fügen wir es hinzu. Werfen wir einen Blick auf den Code zum Aktualisieren von dim_time Tabelle.
Zuerst prüfen wir, ob das Datum existiert. Wenn es nicht existiert, werden wir es hinzufügen. Wir beginnen damit, das gestrige Datum in einer Variablen zu speichern. In Python machst du das so:
yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = str(yesterday)
Die erste Zeile nimmt ein aktuelles Datum, wandelt es in einen Zahlenwert um, subtrahiert 1 von diesem Wert und wandelt diesen Zahlenwert zurück in ein Datum (gestern =heute – 1 ). Die zweite Zeile speichert das Datum in einem Textformat.
Als nächstes testen wir, ob das Datum bereits in der Datenbank vorhanden ist:
table_dim_time = Table('dim_time', metadata, autoload = True, autoload_with = engine_dwh)
stmt = select([table_dim_time]).where(table_dim_time.columns.time_date == yesterday_str)
result = connection_dwh.execute(stmt).fetchall()
date_exists = len(result)
Nach dem Laden der Tabelle führen wir eine Abfrage aus, die alle Zeilen aus der Dimensionstabelle zurückgeben sollte, in denen der Zeit-/Datumswert gleich gestern ist. Das Ergebnis könnte 0 (kein solches Datum in der Tabelle) oder 1 Zeile (das Datum ist bereits in der Tabelle) haben.
Wenn das Datum noch nicht in der Tabelle enthalten ist, verwenden wir den Befehl insert(), um es hinzuzufügen:
if date_exists == 0:
print("New value added.")
stmt = table_dim_time.insert().values(time_date=yesterday, time_year=yesterday.year, time_month=yesterday.month, time_week=yesterday.isocalendar()[1], time_weekday=yesterday.weekday())
connection_dwh.execute(stmt)
else:
print("No new values.")
Eine neue Sache hier, auf die ich hinweisen möchte, ist die Verwendung von. .year , .month , .isocalendar()[1] , und .weekday Datumsteile zu erhalten.
Aktualisierung von dim_city Abmessung
Ziel:Neue Städte einfügen, falls vorhanden (d.h. die Liste der Städte in der Live-Datenbank mit der Liste der Städte im DWH vergleichen und fehlende hinzufügen).
Aktualisieren der dim_time Dimension war ziemlich einfach. Wir haben einfach getestet, ob ein Datum in der Tabelle war und es eingefügt, wenn es nicht schon da war. Um einen Wert in der DWH-Datenbank zu testen, haben wir eine Python-Variable verwendet (gestern ). Wir werden diesen Prozess noch einmal verwenden, aber diesmal mit Listen.
Da es keine einfache Möglichkeit gibt, Tabellen aus verschiedenen Datenbanken in einer einzigen SQLAlchemy-Abfrage zu kombinieren, können wir den in Teil 1 dieser Serie beschriebenen Ansatz nicht verwenden. Daher benötigen wir ein Objekt zum Speichern der Werte, die für die Kommunikation zwischen diesen beiden Datenbanken erforderlich sind. Ich habe mich für die Verwendung von Listen entschieden, weil sie weit verbreitet sind und ihre Aufgabe erfüllen.
Zuerst laden wir das country und city Tabellen aus einer Live-Datenbank in die relevanten Objekte.
# dim_city
print("\nUpdating... dim_city")
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
table_dim_city = Table('dim_city', metadata, autoload = True, autoload_with = engine_dwh)
Als Nächstes laden wir dim_city Tabelle aus dem DWH in eine Liste:
# load whole dwh table in the list stmt = select([table_dim_city]); table_dim_city_list = connection_dwh.execute(stmt).fetchall()
Dann machen wir dasselbe für die Werte aus der Live-Datenbank. Wir nehmen an den Tabellen country und city also haben wir alle benötigten Daten in dieser Liste:
# load all live values in the list stmt = select([table_city.columns.city_name, table_city.columns.postal_code, table_country.columns.country_name])\ .select_from(table_city\ .join(table_country)) table_city_list = connection_live.execute(stmt).fetchall()
Jetzt durchlaufen wir die Liste mit den Daten aus der Live-Datenbank. Für jeden Datensatz vergleichen wir die Werte (city_name , postal_code und country_name ). Wenn wir solche Werte nicht finden, fügen wir einen neuen Datensatz zu dim_city hinzu Tabelle.
# loop through live_db table
# for each record test if it is missing in the dwh table
new_values_added = 0
for city in table_city_list:
id = -1;
for dim_city in table_dim_city_list:
if city[0] == dim_city[1] and city[1] == dim_city[2] and city[2] == dim_city[3]:
id = dim_city[0]
if id == -1:
stmt = table_dim_city.insert().values(city_name=city[0], postal_code=city[1], country_name=city[2])
connection_dwh.execute(stmt)
new_values_added = 1
if new_values_added == 0:
print("No new values.")
else:
print("New value(s) added.")
Um festzustellen, ob der Wert bereits im DWH vorhanden ist, haben wir eine Kombination von Attributen getestet, die eindeutig sein sollten. (Der Primärschlüssel aus der Live-Datenbank hilft uns hier nicht viel weiter.) Wir können ähnlichen Code verwenden, um andere Wörterbücher zu aktualisieren. Es ist nicht die schönste Lösung, aber es ist immer noch eine ziemlich elegante. Und es wird genau das tun, was wir brauchen.
Aktualisierung von fact_customer_subscribed Tabelle
Ziel:Wenn wir alte Daten für das gestrige Datum haben, löschen Sie diese zuerst. Fügen Sie die Daten von gestern in das DWH ein – unabhängig davon, ob wir im vorherigen Schritt etwas gelöscht haben oder nicht.
Nach dem Aktualisieren aller Dimensionstabellen sollten wir die Faktentabellen aktualisieren. In unserem Skript aktualisieren wir nur eine Faktentabelle. Die Argumentation ist die gleiche wie im vorherigen Abschnitt:Das Aktualisieren anderer Tabellen würde dem gleichen Muster folgen, also würden wir den Code meistens wiederholen.
Bevor wir Werte in die Faktentabelle einfügen, müssen wir die Werte der zugehörigen Schlüssel aus den Dimensionstabellen kennen. Dazu laden wir erneut Dimensionen in Listen und vergleichen sie mit Werten aus der Live-Datenbank.
Als erstes laden wir den Kunden und fact_customer_subscribed Tabellen in Objekte:
# fact_customer_subscribed
print("\nUpdating... fact_customer_subscribed")
table_customer = Table('customer', metadata, autoload = True, autoload_with = engine_live)
table_fact_customer_subscribed = Table('fact_customer_subscribed', metadata, autoload = True, autoload_with = engine_dwh)
Jetzt müssen wir Schlüssel für die zugehörige Zeitdimension finden. Da wir immer Daten für gestern einfügen, suchen wir nach diesem Datum in dim_time Tabelle und verwenden Sie ihre ID. Die Abfrage gibt 1 Zeile zurück und die ID befindet sich an der ersten Position (der Index beginnt bei 0, das ist also result[0][0] ):
# find key for the dim_time dimension stmt = select([table_dim_time]).where(table_dim_time.columns.time_date == yesterday) result = connection_dwh.execute(stmt).fetchall() dim_time_id = result[0][0]
Für diese Zeit löschen wir alle zugehörigen Datensätze aus der Faktentabelle:
# delete any existing data in the fact table for that time dimension value stmt = table_fact_customer_subscribed.delete().where(table_fact_customer_subscribed.columns.dim_time_id == dim_time_id) connection_dwh.execute(stmt)
Okay, jetzt haben wir die ID der Zeitdimension in dim_time_id gespeichert Variable. Das war einfach, weil wir nur einen Zeitdimensionswert haben können. Anders sieht es bei der Stadtdimension aus. Zuerst laden wir alle die Werte, die wir brauchen – Werte, die die Stadt eindeutig beschreiben (nicht die ID), und aggregierte Werte:
# prepare data for insert
stmt = select([table_city.columns.city_name, table_city.columns.postal_code, table_country.columns.country_name, func.sum(case([(table_customer.columns.active == 1, 1)], else_=0)).label('total_active'), func.sum(case([(table_customer.columns.active == 0, 1)], else_=0)).label('total_inactive'), func.sum(case([(and_(table_customer.columns.active == 1, func.date(table_customer.columns.time_updated) == yesterday), 1)], else_=0)).label('daily_new'), func.sum(case([(and_(table_customer.columns.active == 0, func.date(table_customer.columns.time_updated) == yesterday), 1)], else_=0)).label('daily_canceled')])\
.select_from(table_customer\
.join(table_city)\
.join(table_country))\
.group_by(table_city.columns.city_name, table_city.columns.postal_code, table_country.columns.country_name)
Es gibt ein paar Dinge, die ich über die obige Abfrage hervorheben möchte:
func.sum(...)ist SUMME(...) aus „Standard-SQL“.- Der
case(...)Syntax verwendetand_vor Bedingungen, nicht zwischen ihnen. .label(...)funktioniert wie ein SQL AS-Alias.- Wir verwenden
\um zur nächsten Zeile zu wechseln und die Lesbarkeit der Abfrage zu verbessern. (Vertrau mir, es ist ohne den Schrägstrich ziemlich unlesbar – ich habe es versucht :) ) .group_by(...)spielt die Rolle von GROUP BY in SQL.
Als Nächstes durchlaufen wir jeden Datensatz, der mit der vorherigen Abfrage zurückgegeben wurde. Für jeden Datensatz vergleichen wir Werte, die eine Stadt eindeutig definieren (city_name , postal_code , country_name ) mit den Werten, die in der Liste gespeichert sind, die aus dem DWH dim_city erstellt wurde Tisch. Wenn alle drei Werte übereinstimmen, speichern wir die ID aus der Liste und verwenden sie beim Einfügen neuer Daten. Auf diese Weise haben wir für jeden Datensatz IDs für beide Dimensionen:
# loop through all new records
# use time dimension
# for each record find key for city dimension
# insert row
new_values = connection_live.execute(stmt).fetchall()
for new_value in new_values:
dim_city_id = -1;
for dim_city in table_dim_city_list:
if new_value[0] == dim_city[1] and new_value[1] == dim_city[2] and new_value[2] == dim_city[3]:
dim_city_id = dim_city[0]
if dim_city_id > 0:
stmt_insert = table_fact_customer_subscribed.insert().values(dim_city_id=dim_city_id, dim_time_id=dim_time_id, total_active=new_value[3], total_inactive=new_value[4], daily_new=new_value[5], daily_canceled=new_value[6])
connection_dwh.execute(stmt_insert)
dim_city_id = -1
print("Completed.")
Und das war's. Wir haben unser DWH aktualisiert. Das Skript wäre viel länger, wenn wir alle Dimensions- und Faktentabellen aktualisieren würden. Die Komplexität wäre auch größer, wenn eine Faktentabelle mit mehreren Dimensionstabellen in Beziehung steht. In diesem Fall benötigen wir ein for Schleife für jede Dimensionstabelle.
Das funktioniert nicht!
Ich war sehr enttäuscht, als ich dieses Skript schrieb und dann herausfand, dass so etwas nicht funktionieren wird:
stmt = select([table_city.columns.city_name])\ .select_from(table_city\ .outerjoin(table_dim_city, table_city.columns.city_name == table_dim_city.columns.city_name))\ .where(table_dim_city.columns.id.is_(None))
In diesem Beispiel versuche ich, Tabellen aus zwei verschiedenen Datenbanken zu verwenden. Wenn wir zwei separate Verbindungen herstellen, „sieht“ die erste Verbindung keine Tabellen von einer anderen Verbindung. Wenn wir uns direkt mit dem Server und nicht mit einer Datenbank verbinden, können wir keine Tabellen laden.
Bis sich dies (hoffentlich bald) ändert, müssen Sie eine Art Struktur verwenden (z. B. das, was wir heute getan haben), um zwischen den beiden Datenbanken zu kommunizieren. Dies verkompliziert den Code, da Sie eine einzelne Abfrage durch zwei Listen und verschachtelte for ersetzen müssen Schleifen.
Teilen Sie Ihre Gedanken zu SQLAlchemy und Python mit
Dies war der letzte Artikel dieser Reihe. Aber wer weiß? Vielleicht probieren wir in kommenden Artikeln einen anderen Ansatz aus, also bleiben Sie dran. Bitte teilen Sie in der Zwischenzeit Ihre Gedanken zu SQLAlchemy und Python in Kombination mit Datenbanken mit. Was fehlt uns Ihrer Meinung nach in diesem Artikel? Was würden Sie hinzufügen? Sagen Sie es uns in den Kommentaren unten.
Sie können das vollständige Skript, das wir in diesem Artikel verwendet haben, hier herunterladen.
Und besonderer Dank geht an Dirk J. Bosman (@dirkjobosman), der diese Artikelserie empfohlen hat.