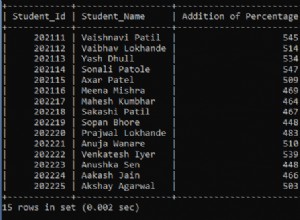
Sammlungen . Sie haben zwei Möglichkeiten, nicht drei:
utf8_bin behandelt all diese als verschieden :demandé und demande und Demandé .
utf8_..._ci (normalerweise utf8_general_ci oder utf8_unicode_ci ) behandelt alle diese als gleich :demandé und demande und Demandé .
Wenn Sie nur die Groß-/Kleinschreibung beachten möchten (demandé =demande , aber keines von beiden entspricht Demandé ), hast du Pech.
Wenn Sie nur Akzentsensitivität wünschen (demandé =demande , aber keiner passt zu demande ), hast du Pech.
Erklärung . Der beste Weg, um das zu tun, was Sie auswählen:
CREATE TABLE (
name VARCHAR(...) CHARACTER SET utf8 COLLATE utf8_... NOT NULL,
...
PRIMARY KEY(name)
)
Sortierung nicht spontan ändern . Dies wird den Index nicht verwenden (d. h. langsam sein), wenn die Sortierung in name unterschiedlich ist :
WHERE name = ... COLLATE ...
BINÄR . Die Datentypen BINARY , VARBINARY und BLOB sind sehr ähnlich wie CHAR , VARCHAR , und TEXT mit COLLATE ..._bin . Vielleicht besteht der einzige Unterschied darin, dass Text auf gültiges utf8-Speichern in einem VARCHAR ... COLLATE ..._bin geprüft wird , wird aber beim Speichern in VARBINARY... nicht überprüft . Vergleiche (WHERE , ORDER BY , usw.) sind gleich; das heißt, vergleiche einfach die Bits, mache kein Case-Folding oder Accent-Stripping usw.