Ich habe ein Beispiel für eine Transformation (Rechtsklick und Speicherlink wählen) zusammengestellt basierend auf dem, was Sie bereitgestellt haben. Der einzige Schritt, bei dem ich mich etwas unsicher fühle, sind die letzten Tabelleneingaben. Im Grunde schreibe ich die Join-Daten in die Tabelle und lasse sie fehlschlagen, wenn eine bestimmte Beziehung bereits besteht.
Hinweis:
Diese Lösung entspricht nicht wirklich dem „Alle Ansätze sollten einige Validierungs- und Rollback-Strategien enthalten, falls eine Einfügung fehlschlägt oder die referenzielle Integrität nicht aufrechterhalten wird“. Kriterien, obwohl es wahrscheinlich nicht scheitern wird. Wenn Sie wirklich etwas Komplexes einrichten möchten, können wir das tun, aber das sollte Sie mit diesen Transformationen definitiv in Schwung bringen.

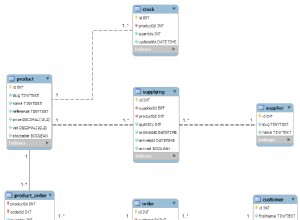
Datenfluss nach Schritt
1. Wir beginnen mit dem Einlesen Ihrer Akte. In meinem Fall habe ich es in CSV konvertiert, aber Tab ist auch in Ordnung. 
2. Jetzt fügen wir die Mitarbeiternamen mithilfe einer combination lookup/update in die Employee-Tabelle ein .Nach dem Einfügen hängen wir die employee_id als id an unseren Datenstrom an und entfernen Sie den EmployeeName aus dem Datenstrom.

3. Hier verwenden wir nur einen Select Values-Schritt, um die id umzubenennen Feld zu employee_id 
4. Fügen Sie Stellenbezeichnungen ein, genau wie wir es bei Mitarbeitern getan haben, und hängen Sie die Titel-ID an unseren Datenstrom an, wobei Sie auch die JobLevelHistory löschen aus dem Datenstrom.

5. Einfache Umbenennung der Titel-ID in title_id (siehe Schritt 3) 
6. Büros einfügen, IDs abrufen, OfficeHistory aus dem Stream entfernen.

7. Einfache Umbenennung der Office-ID in office_id(siehe Schritt 3)

8. Kopieren Sie Daten aus dem letzten Schritt in zwei Streams mit den Werten employee_id,office_id und employee_id,title_id bzw..

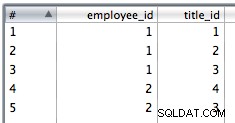
9. Verwenden Sie eine Tabelleneinfügung, um die Join-Daten einzufügen. Ich habe es ausgewählt, um Einfügefehler zu ignorieren, da es Duplikate geben könnte und die PK-Einschränkungen dazu führen, dass einige Zeilen fehlschlagen.
Ausgabetabellen