Zunächst einmal ist „toxi“ kein Standardbegriff. Definieren Sie immer Ihre Bedingungen! Oder stellen Sie zumindest relevante Links zur Verfügung.
Und nun zur eigentlichen Frage...
Nein, Sie haben 3 Tische.
Sie sind ziemlich genau auf dem richtigen Weg, mit der Ausnahme, dass Sie die mengenbasierte Natur von SQL verwenden können, um viele dieser Schritte "zusammenzuführen". Zum Beispiel kann das Taggen eines Artikels 1 mit Tags:'tag1', 'tag2' und 'tag3' so gemacht werden...
INSERT IGNORE INTO tagmap (item_id, tag_id)
SELECT 1, tag_id FROM tags WHERE tag_text IN ('tag1', 'tag2', 'tag3');
Das IGNORE ermöglicht dies auch dann, wenn Artikel bereits mit einigen dieser Tags verbunden sind.
Dies setzt voraus, dass sich alle erforderlichen Tags bereits in tags befinden . Angenommen tag.tag_id Autoinkrement ist, können Sie so etwas tun, um sicherzustellen, dass sie sind:
INSERT IGNORE INTO tags (tag_text) VALUES ('tag1'), ('tag2'), ('tag3');
Es gibt keine Magie. Wenn "Element ist mit einem bestimmten Tag verbunden" ein Teil des Wissens ist, das Sie aufzeichnen möchten, dann hat es um eine Art physische Repräsentation in der Datenbank zu haben.
Du meinst das Neu-Taggen von Elementen (nicht das Ändern von Tags selbst)?
Um alle Tags zu entfernen, die nicht in der Liste enthalten sind, gehen Sie wie folgt vor:
DELETE FROM tagmap
WHERE
item_id = 1
AND tag_id NOT IN (
SELECT tag_id FROM tags
WHERE tag_text IN ('tag1', 'tag3')
);
Dadurch wird das Element von allen Tags außer „tag1“ und „tag3“ getrennt. Führen Sie das obige INSERT und dieses DELETE nacheinander aus, um sowohl das Hinzufügen als auch das Entfernen von Tags zu "überdecken".
Mit all dem können Sie in SQL Fiddle spielen .
Richtig. Ein untergeordneter Endpunkt eines FK löst keine referenzielle Aktion aus (z. B. ON DELETE CASCADE), nur der übergeordnete Endpunkt.
Übrigens verwenden Sie dieses Schema, weil Sie zusätzliche Felder in tags möchten (neben tag_text ), Rechts? Wenn Sie dies tun, ist es erwünscht, diese zusätzlichen Daten nicht zu verlieren, nur weil alle Verbindungen unterbrochen sind.
Aber wenn Sie nur den tag_text wollten , würden Sie ein einfacheres Schema verwenden, bei dem das Löschen aller Verbindungen dasselbe wäre wie das Löschen des Tags selbst:
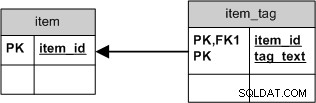
Dies würde nicht nur das SQL vereinfachen, sondern auch ein besseres Clustering ermöglichen .
Auf den ersten Blick mag "toxi" so aussehen, als würde es Platz sparen, aber das ist in der Praxis möglicherweise nicht der Fall, da es zusätzliche Tabellen und Indizes erfordert (und Tags tendenziell kurz sind).
Messen Sie, bevor Sie sich für so etwas entscheiden. Meine oben erwähnte SQL-Fiddle verwendet eine sehr bewusste Reihenfolge der Felder in der tagmap PK, also werden die Daten auf eine Weise gruppiert, die dieser Art des Zählens sehr zuträglich ist (denken Sie daran:InnoDB-Tabellen sind geclustert
). Sie müssten eine wirklich große Menge an Artikeln haben (oder eine ungewöhnlich hohe Leistung benötigen), bevor dies zu einem Problem wird.
In jedem Fall messen auf realistische Datenmengen!