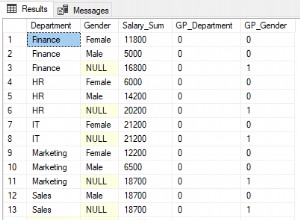
Folgendes ist los.
The SELECT COUNT (...) icd_index where icd='25000'
verwendet den Index, der ein von den Daten getrennter BTree ist. Aber es scannt es auf diese Weise:
- Suchen Sie den ersten Eintrag mit icd='25000'. Dies geschieht fast augenblicklich.
- Vorwärts suchen, bis eine Änderung im icd gefunden wird. Dadurch wird nur der Index gescannt, die Daten werden nicht berührt. Laut EXPLAIN müssen etwa 910.104 Indexeinträge durchsucht werden.
Sehen wir uns nun den BTree für diesen Index an. Basierend auf den Feldern im Index hat jede Zeile genau 22 Byte, plus etwas Overhead (schätzungsweise 40 %). Ein MyISAM-Indexblock ist 1 KB groß (vgl. InnoDBs 16 KB). Ich würde 33 Zeilen pro Block schätzen. 910,104/33 sagt, dass etwa 27K Blöcke gelesen werden müssen, um die ZÄHLUNG durchzuführen. (Beachten Sie COUNT(core_id) muss core_id überprüfen für Null, COUNT(*) nicht; das ist ein kleiner Unterschied.) Das Lesen von 27K-Blöcken auf einer einfachen Festplatte dauert etwa 270 Sekunden. Du hattest Glück, dass du es in 60 Sekunden geschafft hast.
Beim zweiten Durchlauf wurden alle diese Blöcke im key_buffer gefunden (vorausgesetzt, key_buffer_size beträgt mindestens 27 MB), sodass nicht auf die Festplatte gewartet werden musste. Daher ging es viel schneller. (Dies ignoriert den Query-Cache, den Sie klugerweise geleert oder SQL_NO_CACHE verwendet haben.)
5.6 ist zufällig irrelevant (aber danke für die Erwähnung), da sich dieser Prozess seit 4.0 oder davor nicht geändert hat (außer dass utf8 nicht existierte; mehr dazu weiter unten).
Der Wechsel zu InnoDB würde in mehrfacher Hinsicht helfen. Der PRIMARY KEY würde mit den Daten „geclustert“ und nicht als separater BTree gespeichert. Sobald die Daten oder der PK zwischengespeichert sind, ist der andere daher sofort verfügbar. Die Anzahl der Blöcke wäre eher 5K, aber es wären 16KB-Blöcke. Diese können möglicherweise schneller geladen werden, wenn der Cache kalt ist.
Sie fragen:"Brauche ich einen Index nur für icd?" - Nun, das würde die MyISAM-BTree-Größe auf etwa 21 Bytes pro Zeile schrumpfen, also wäre der BTree etwa 21/27 der Größe, keine große Verbesserung (zumindest für die Cold-Cache-Situation).
Ein anderer Gedanke ist, wenn icd ist immer numerisch und immer numerisch, um MEDIUMINT UNSIGNED zu verwenden , und heften Sie ZEROFILL an wenn es führende Nullen haben darf.
Hoppla, ich habe den CHARACTER SET übersehen. (Ich habe die Zahlen oben festgelegt, aber lassen Sie mich näher darauf eingehen.)
- CHAR(5) erlaubt 5 Zeichen .
- ASCII benötigt 1 Byte pro Zeichen .
- utf8 benötigt bis zu 3 Bytes pro Zeichen .
- Also benötigt CHAR(5) CHARACTER SET utf8 15 Bytes immer .
Ändern der Spalte in CHAR(5) CHARACTER SET ascii würde es auf 5 Bytes verkleinern.
Wenn Sie es in MEDIUMINT UNSIGNED ZEROFILL ändern, wird es auf 3 Bytes schrumpfen.
Das Verkleinern der Daten würde die E/A um einen ungefähr proportionalen Betrag beschleunigen (nachdem weitere 6 Bytes für die anderen beiden Felder zugelassen wurden.