Die Beobachtbarkeit von Daten ist ein entscheidender Teil des Datenbankbetriebs-Puzzles – Daten ermöglichen Ihnen einen Einblick in den Zustand und Zustand Ihrer kritischen Systeme. Idealerweise sollten diese Daten an einem einzigen Ort verfügbar sein. Wenn Sie mehrere Anwendungen haben, die jeweils separate Daten verarbeiten, setzen Sie sich potenziell schwerwiegenden Problemen aus. Wenn Probleme auftreten, müssen Sie in der Lage sein, die Situation schnell einzuschätzen und festzustellen, was vor sich geht, anstatt zu versuchen, Berichte aus mehreren Quellen zu analysieren und zusammenzuführen.

ClusterControl bietet Benutzern neben anderen Funktionen einen einzigen Ausgangspunkt den Zustand ihrer Datenbanken verfolgen. In diesem Blogbeitrag werden wir einige der in ClusterControl verfügbaren Beobachtbarkeitsfunktionen demonstrieren.
Registerkarte "Übersicht"
Der Abschnitt „Übersicht“ ist ein konsolidierter Ort, an dem Benutzer den Status eines Clusters, einschließlich aller Cluster-Knoten und aller Load-Balancer, leicht verfolgen können.
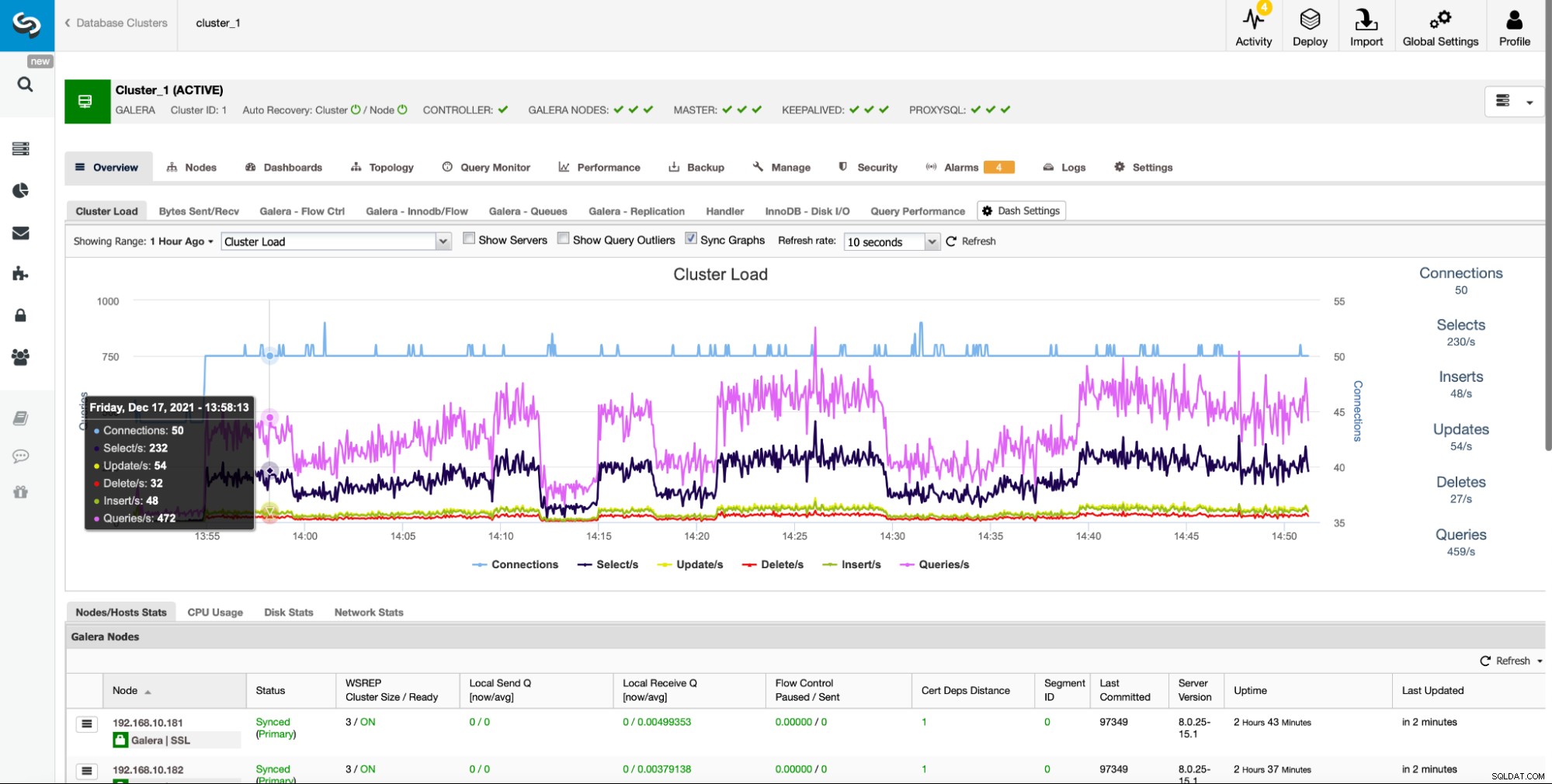
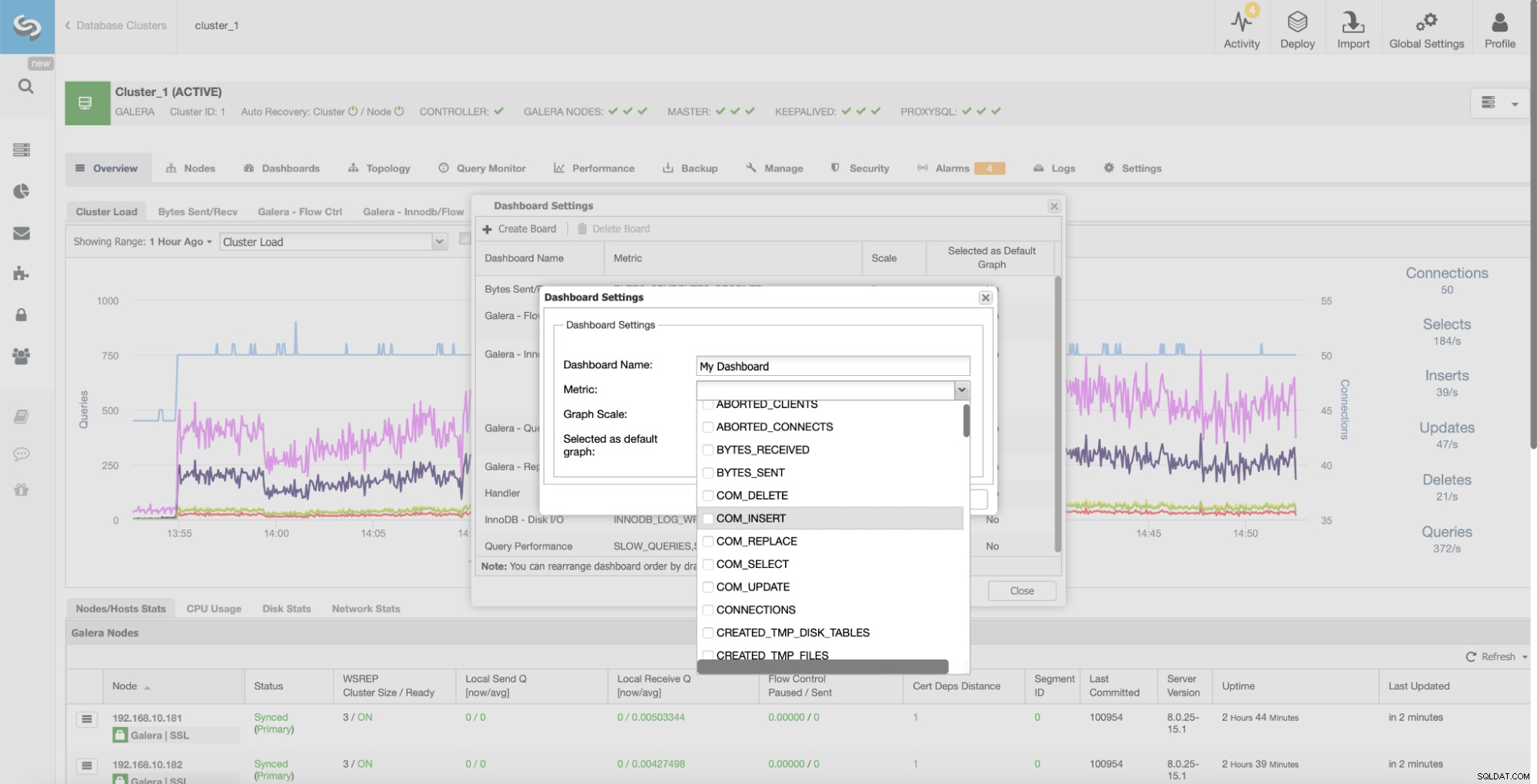
Es bietet einfachen Zugriff auf mehrere vordefinierte Dashboards, die die wichtigsten anzeigen Informationen für den angegebenen Clustertyp. ClusterControl unterstützt verschiedene Open-Source-Datenspeicher, und je nach Anbieter werden verschiedene Diagramme angezeigt. ClusterControl bietet auch eine Option zum Erstellen eigener benutzerdefinierter Dashboards:
ClusterControl aggregiert Diagramme über alle Clusterknoten hinweg. Diese Schlüsselfunktion erleichtert die Nachverfolgung des Status des gesamten Clusters. Wenn Sie Diagramme von jedem Knoten überprüfen möchten, können Sie dies ganz einfach wie unten gezeigt tun:
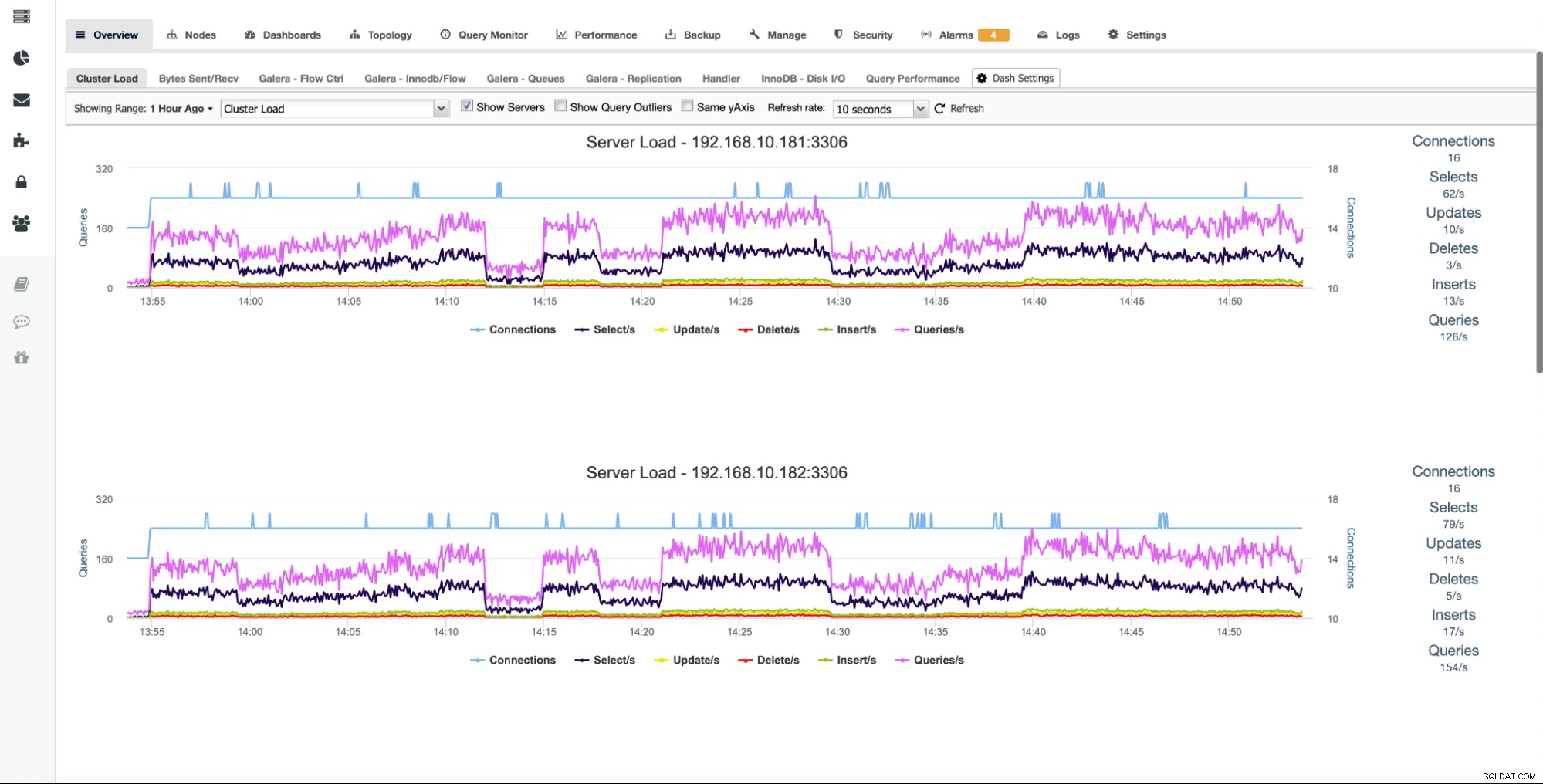
Durch Aktivieren von „Server anzeigen“ werden alle Knoten im Cluster angezeigt separat, so dass Sie jeden einzeln aufschlüsseln können.
Registerkarte "Knoten"
Wenn Sie einen bestimmten Knoten genauer prüfen möchten, können Sie dies auf der Registerkarte "Knoten" tun.
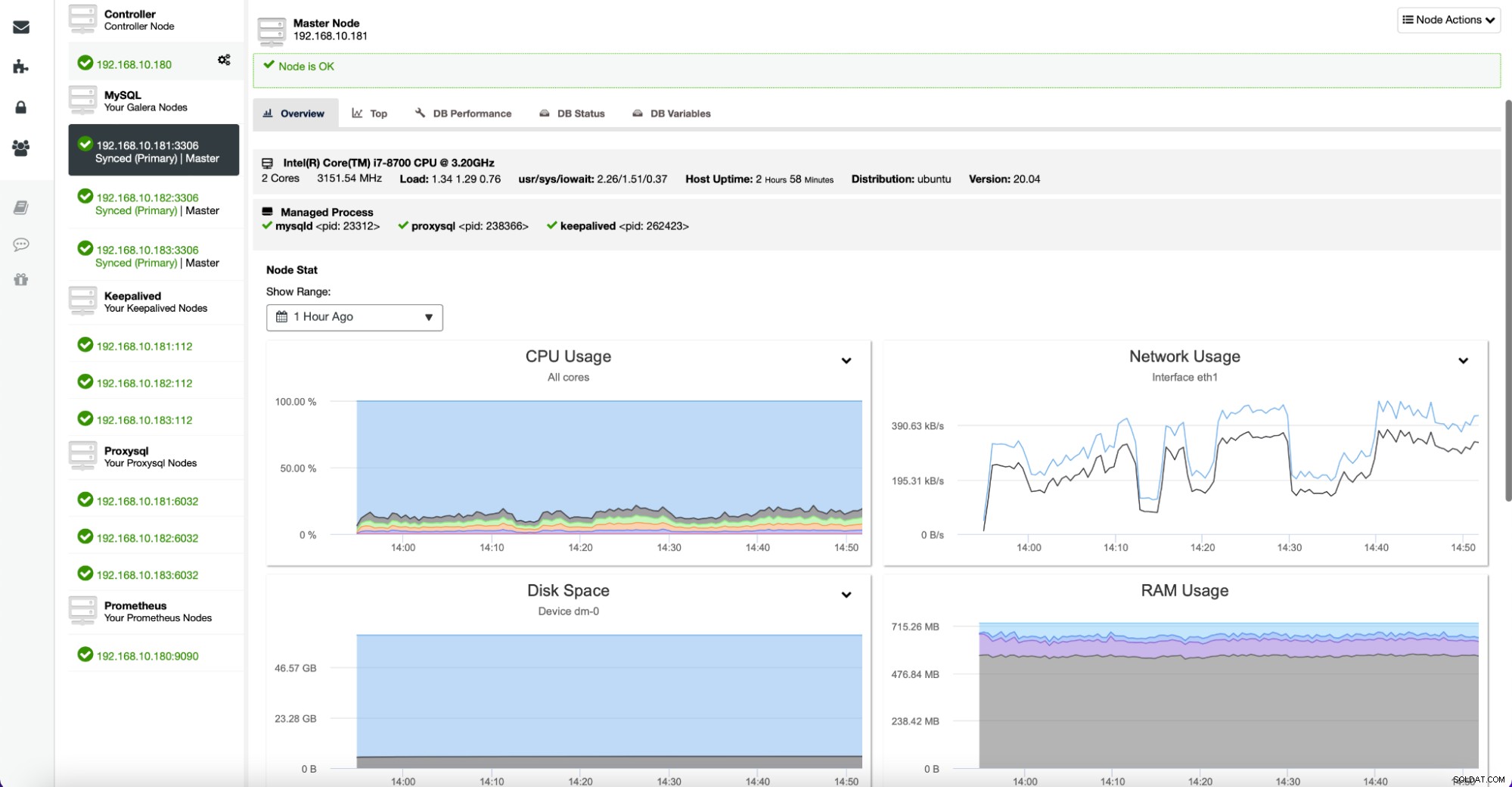
Hier finden Sie Metriken zu einem bestimmten Host – CPU, Festplatte, Netzwerk und Arbeitsspeicher – all die wichtigen Datenbits, die definieren, wie sich ein bestimmter Server verhält und wie ausgelastet er ist.
Die Registerkarte "Knoten" bietet Ihnen auch eine Option zum Überprüfen der Datenbankmetriken für einen bestimmten Knoten, wie unten gezeigt:
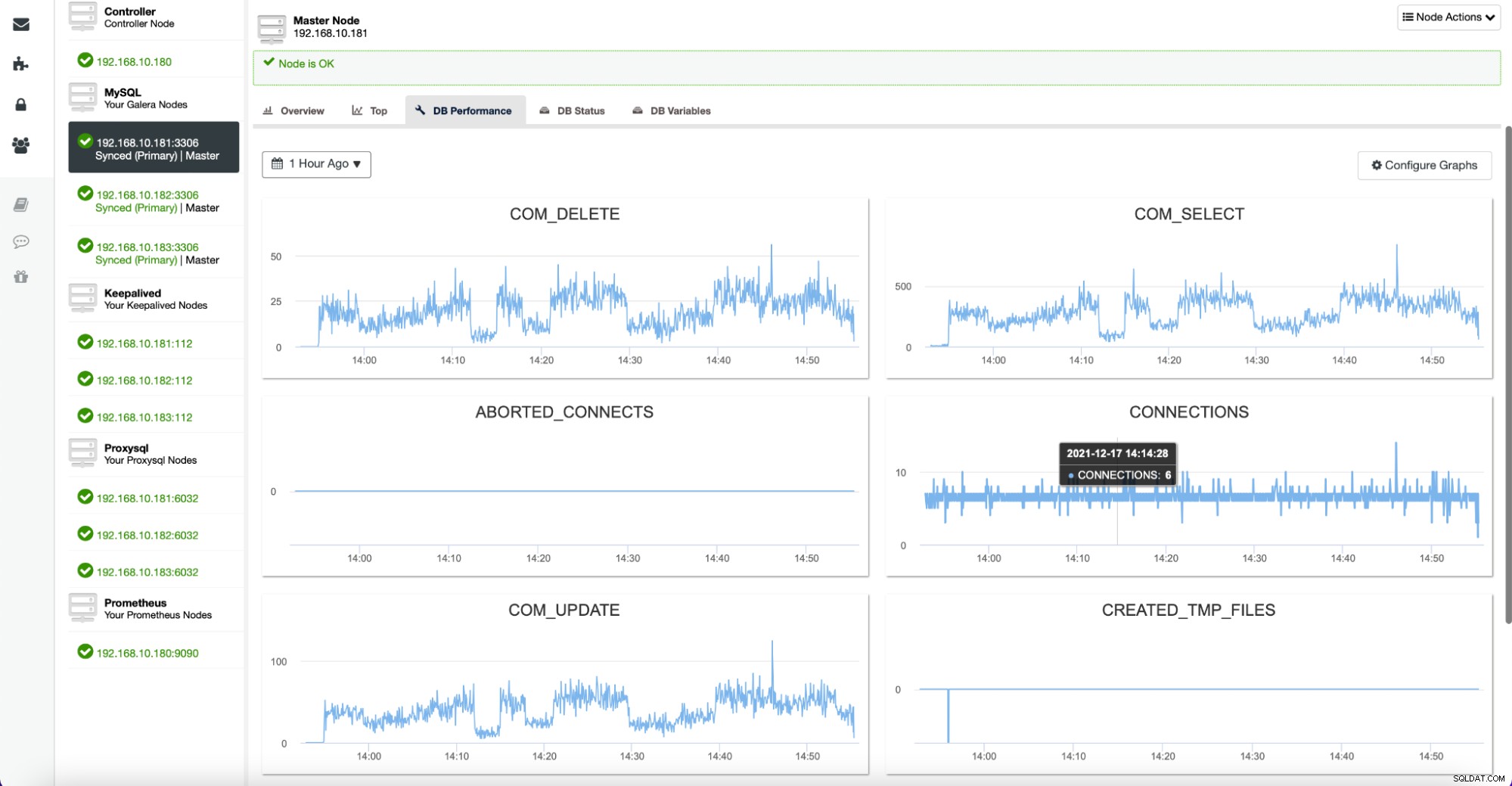
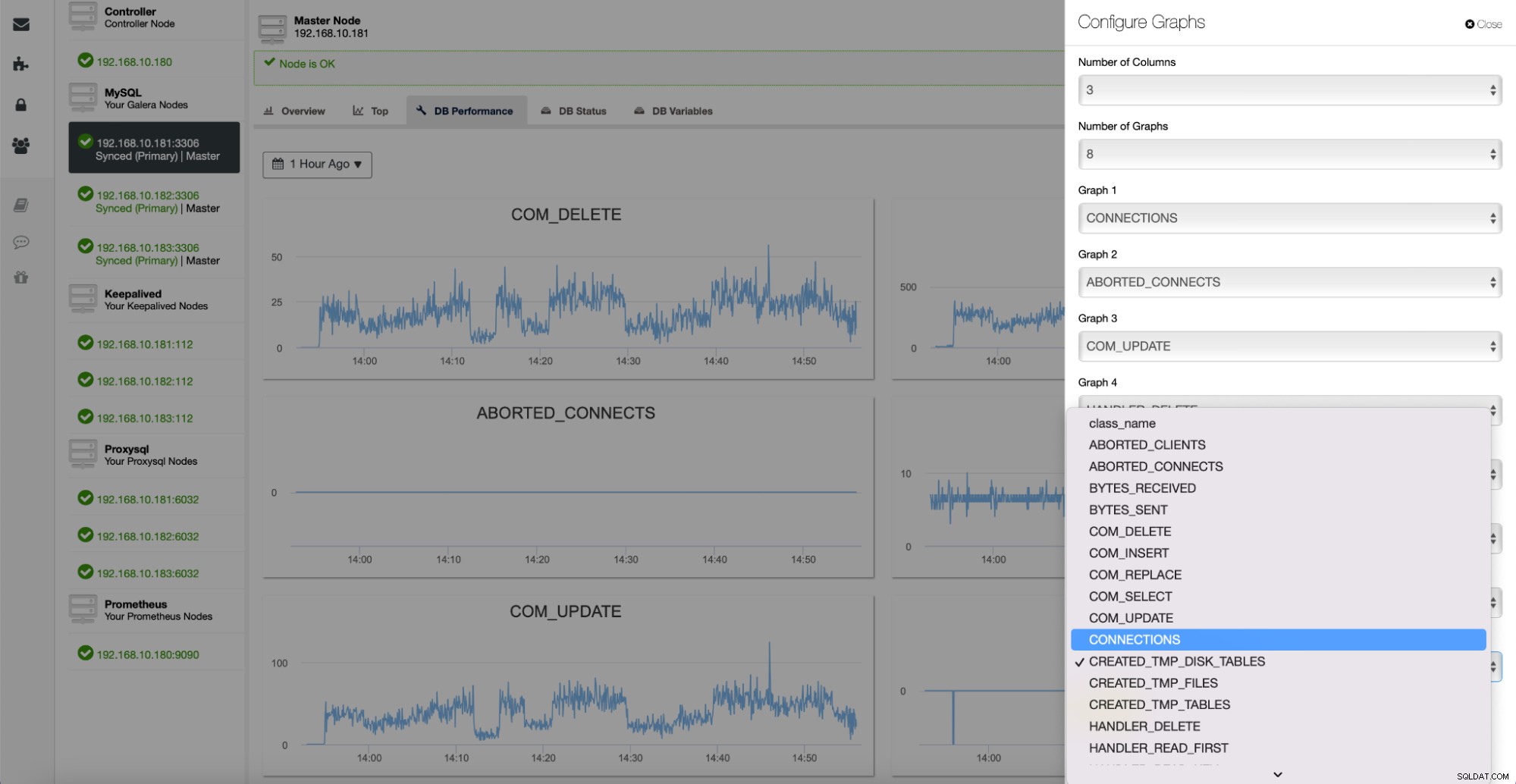
Alle diese Diagramme sind anpassbar, und Sie können bei Bedarf problemlos weitere hinzufügen :
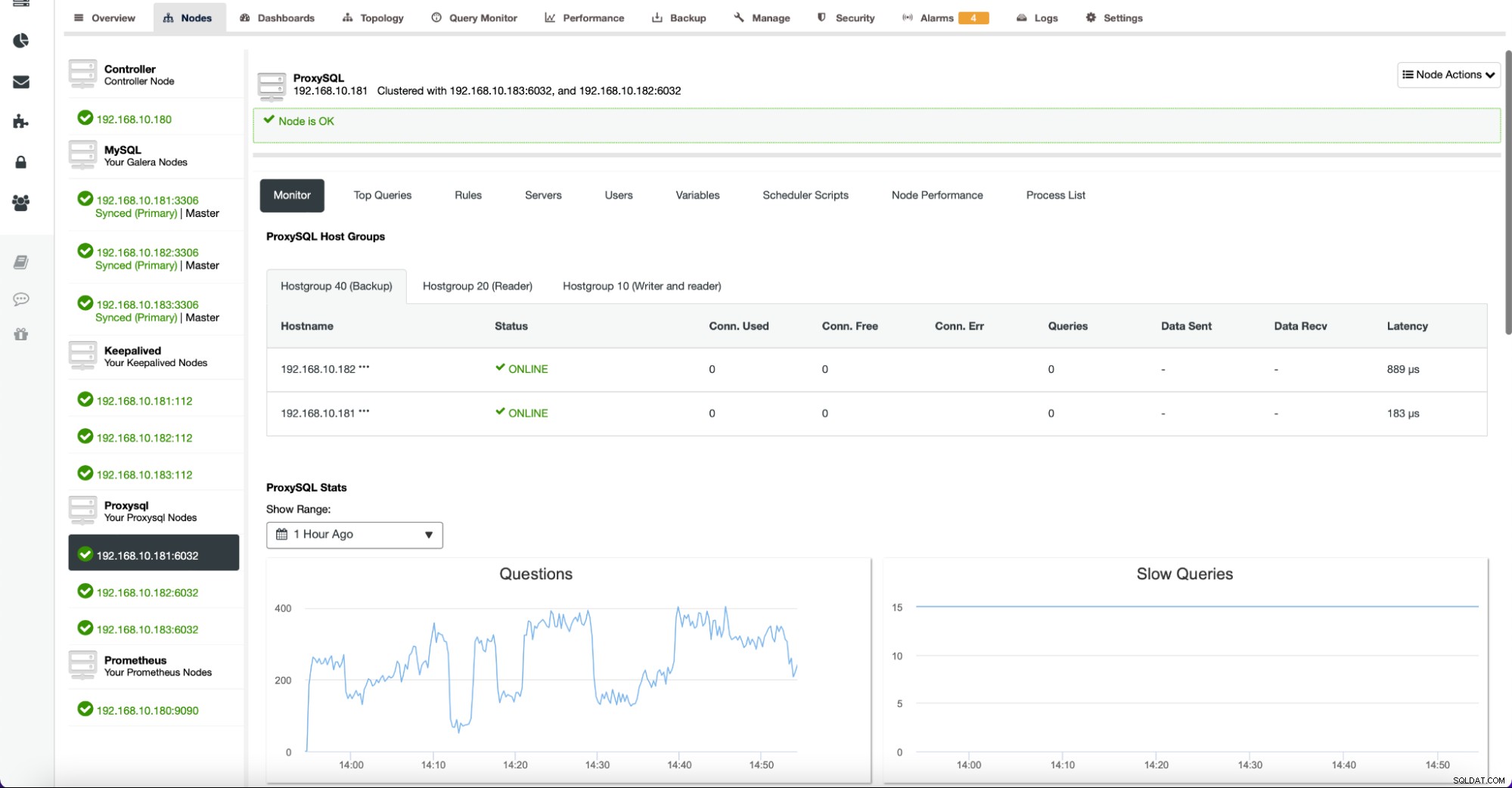
Die Registerkarte "Knoten" enthält auch Metriken, die sich auf andere Knoten als Datenbanken beziehen. Beispielsweise bietet ClusterControl für ProxySQL eine umfangreiche Liste von Diagrammen, um den Status der wichtigsten Metriken zu verfolgen.
Dashboards
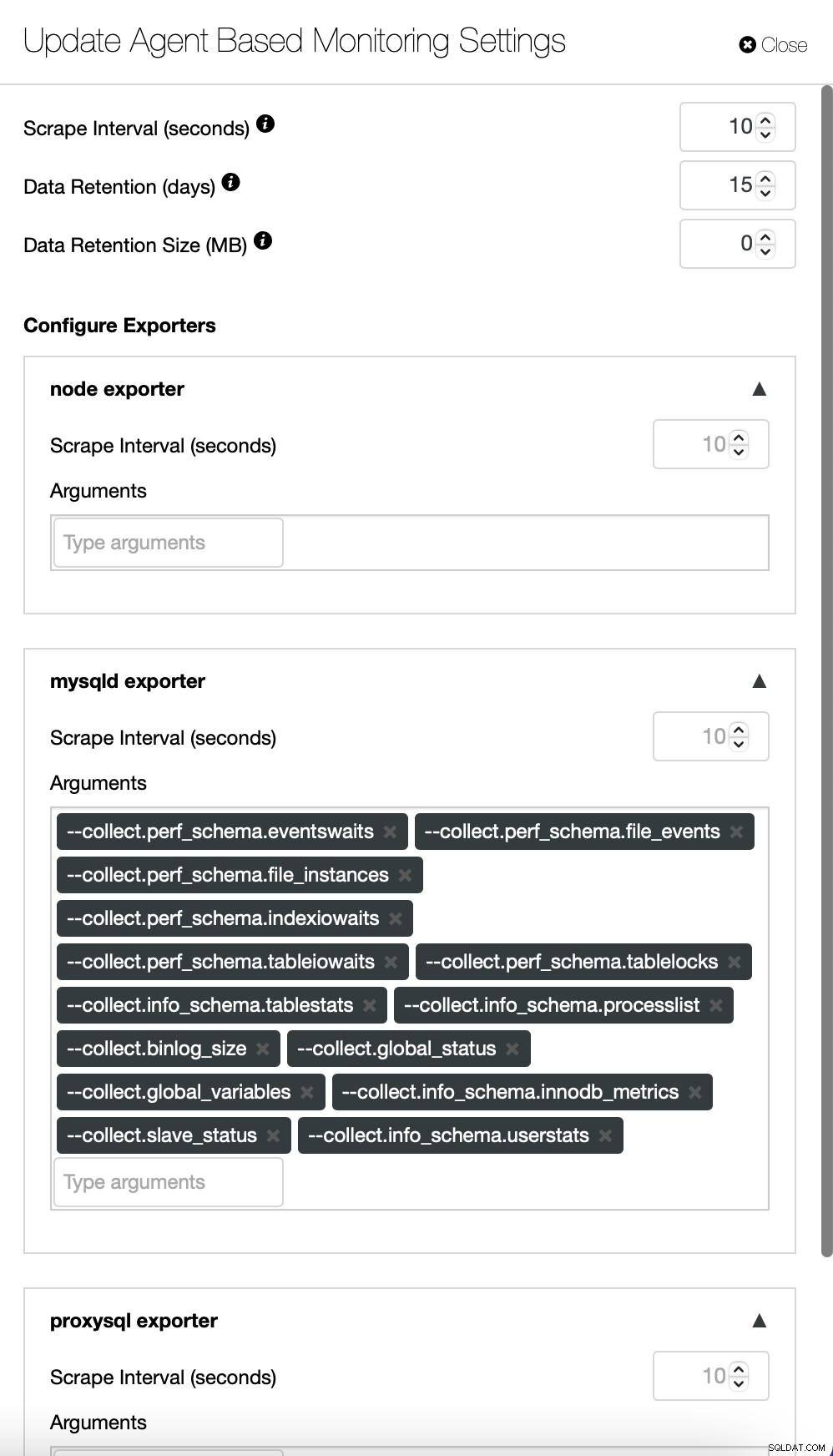
Standardmäßig verwendet ClusterControl einen agentenlosen Überwachungsansatz, und alle Daten werden direkt von ClusterControl gesammelt, indem entweder SSH oder eine native Verbindung zur Datenbank verwendet wird. Es ist jedoch möglich, einen agentenbasierten Ansatz zu ermöglichen. Das geht mit nur einem Klick.
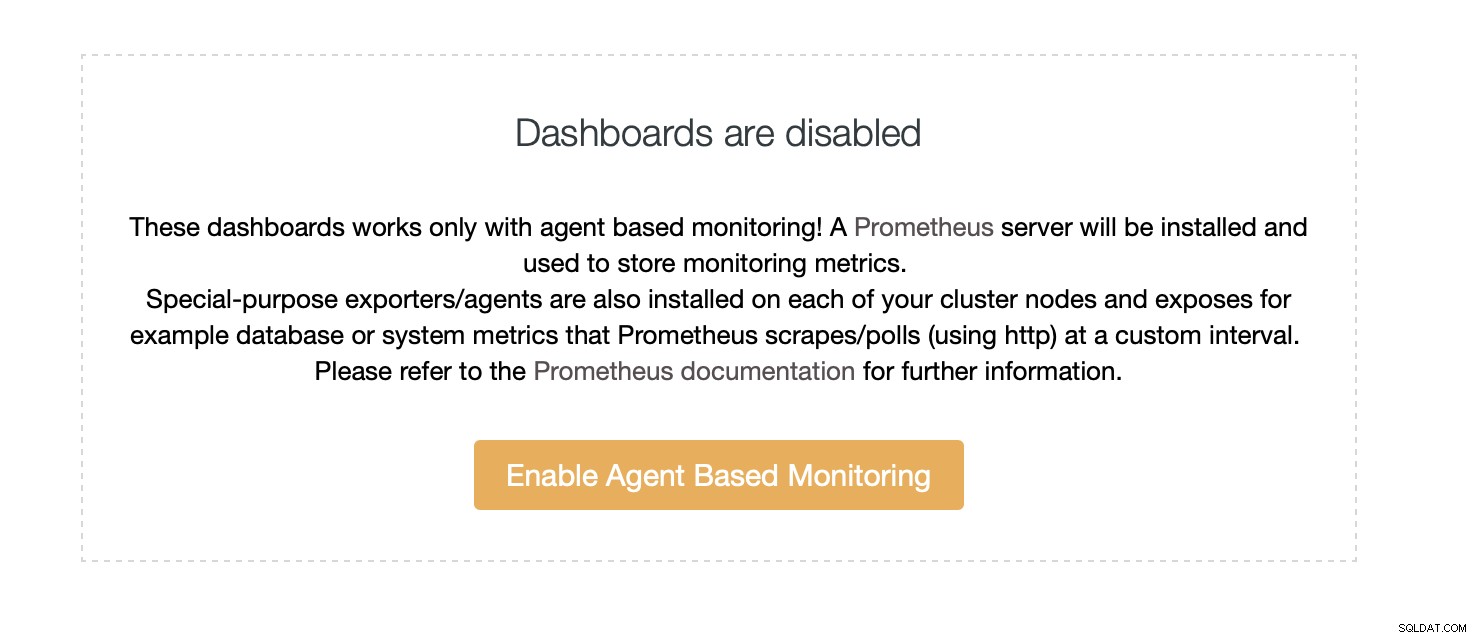
Sobald Sie die agentenbasierte Überwachung aktivieren, wird ein Job gestartet, der konfiguriert wird eine Prometheus-Zeitreihendatenbank, die die Daten speichert, und verschiedene Agenten, die die Daten sammeln und an Prometheus weiterleiten.
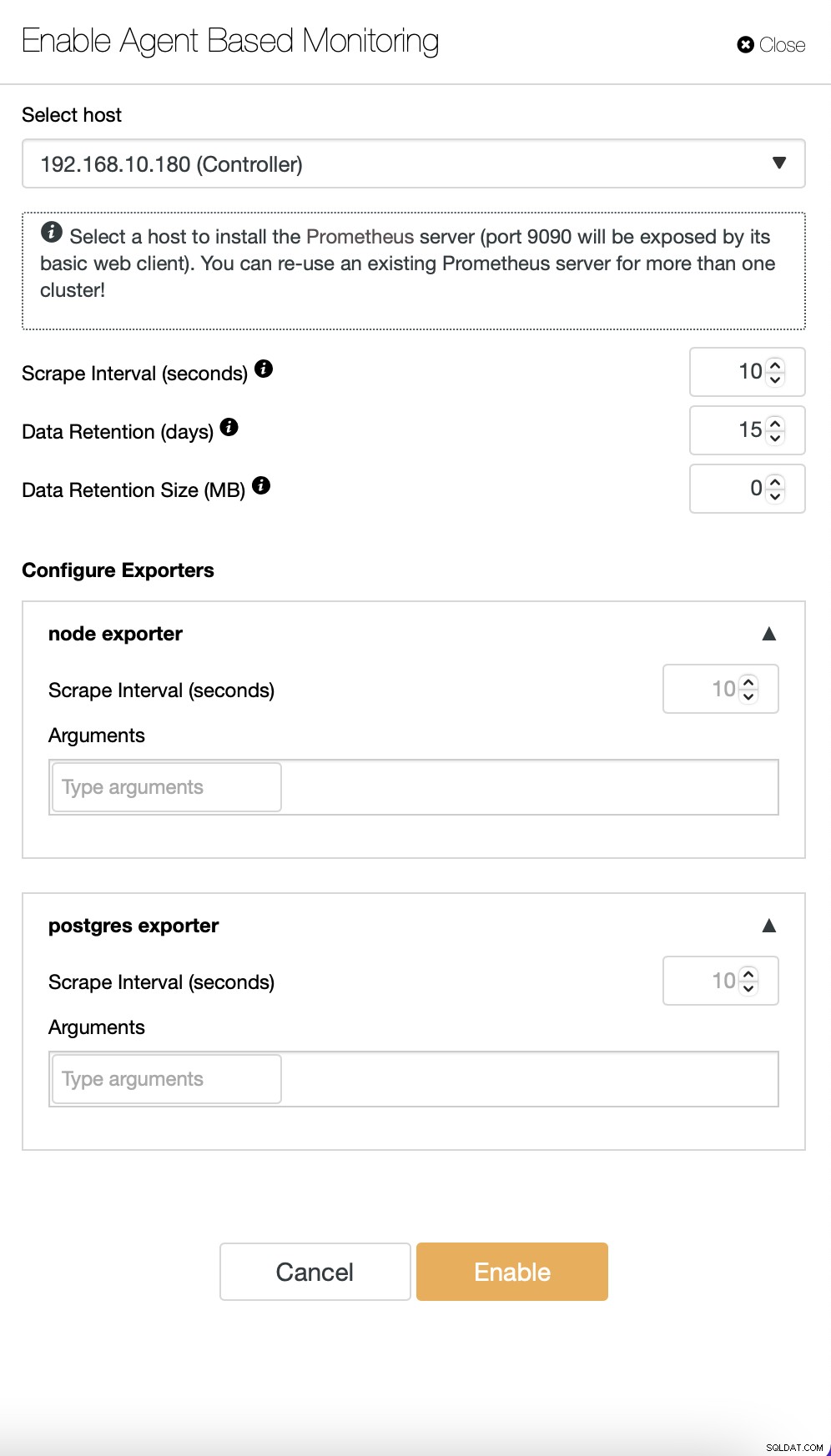
Sobald dies fertig ist, wird eine Reihe von Dashboards gemäß erstellt im Cluster verfügbare Knotentypen.
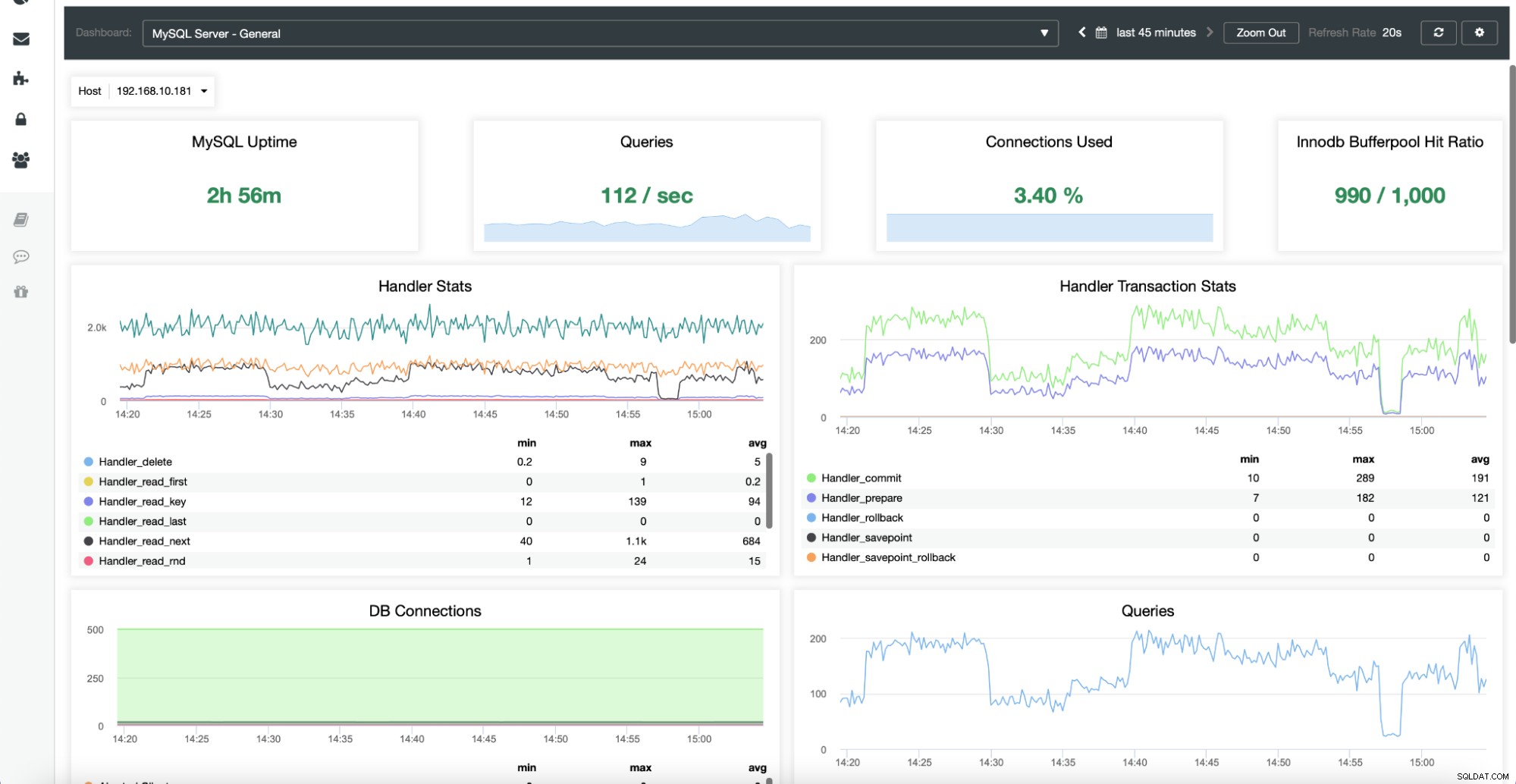
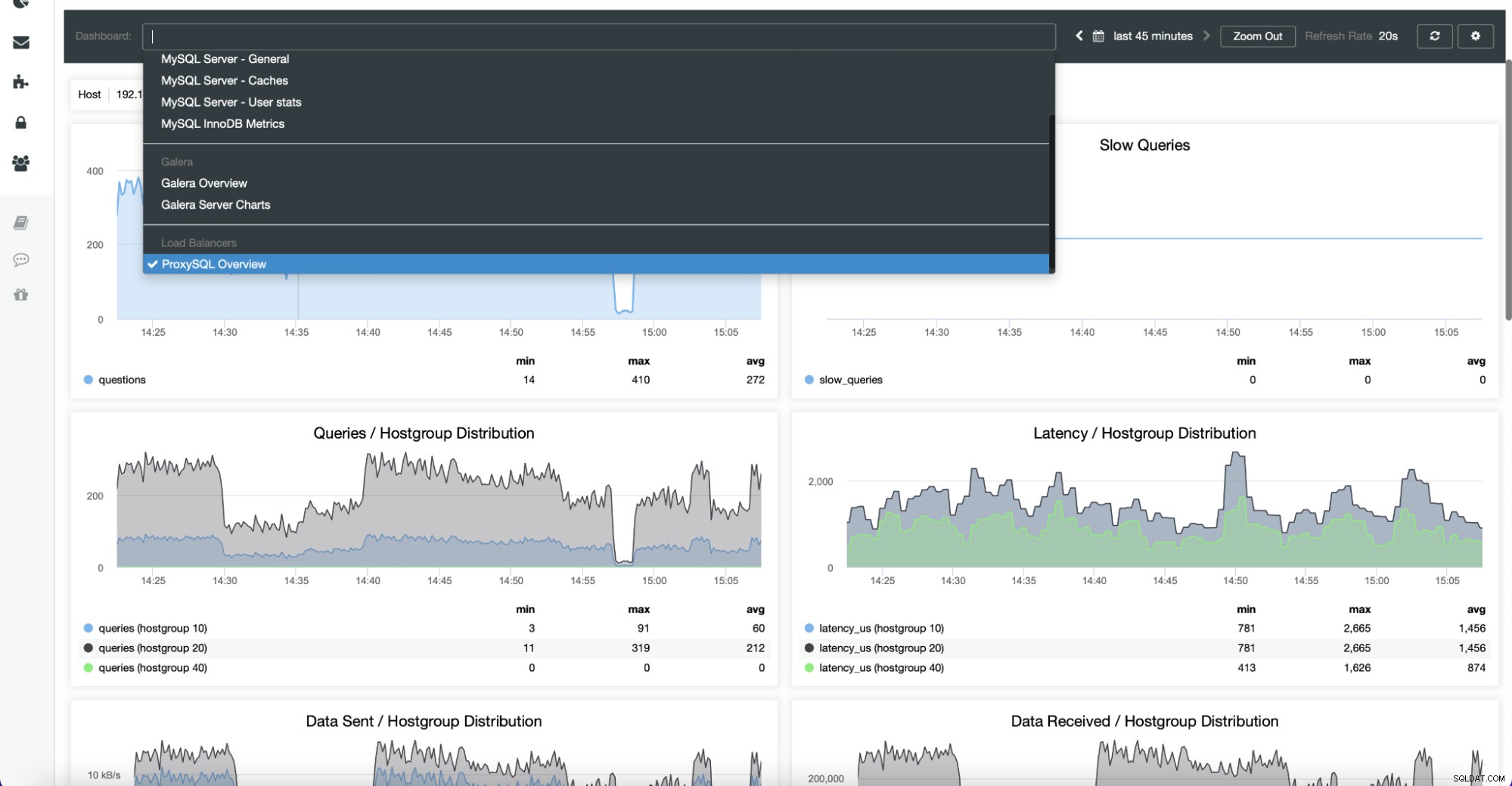
Dashboards enthalten auch Load Balancer, die im Cluster bereitgestellt wurden. Bei Bedarf ist es möglich, die agentenbasierte Überwachung erneut zu aktivieren, was die Neuinstallation und Neukonfiguration der Exporter umfasst:
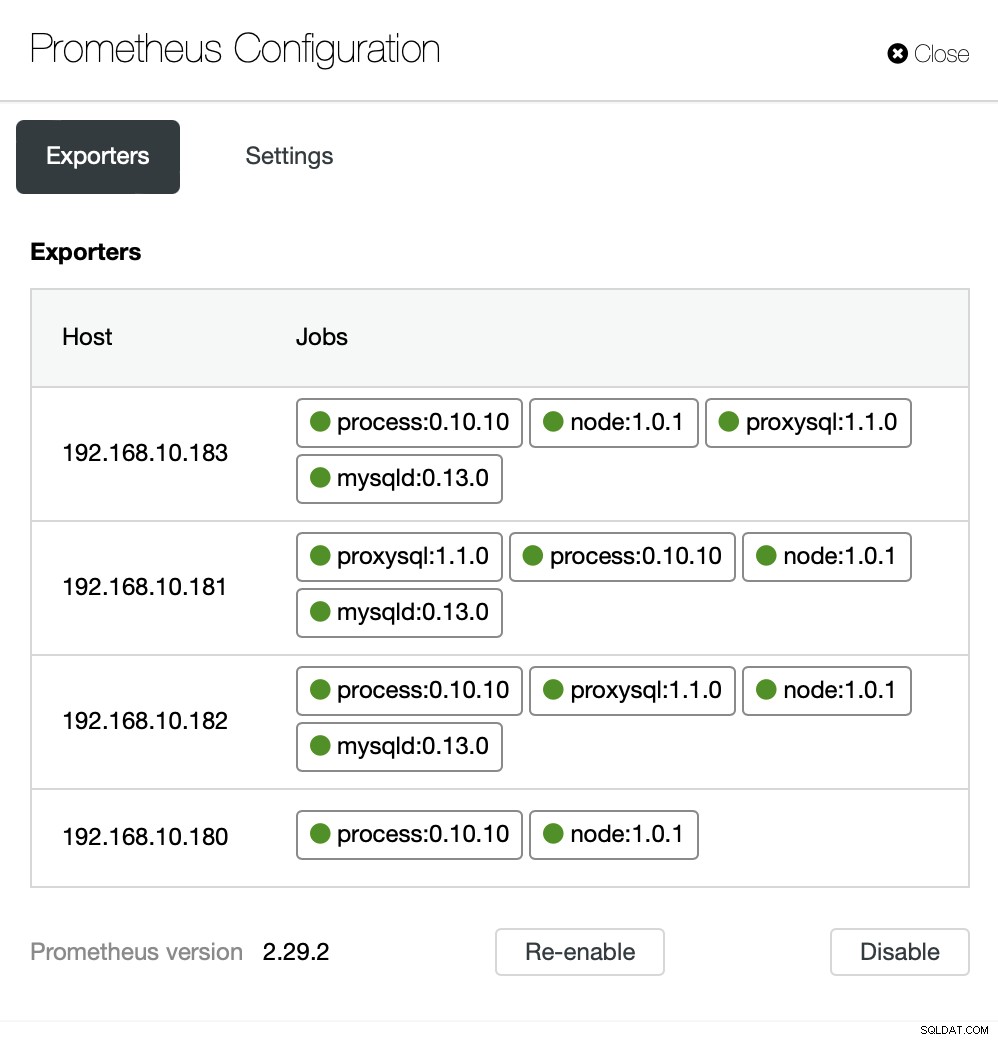
Wenn Sie möchten, können Sie auch die Konfiguration der Agenten und von Prometheus ändern :
Berater
Trenddaten allein reichen nicht aus. Sicher, es ist großartig für Post-Mortem-Analysen oder bei der Arbeit an der Kapazitätsplanung; historische Daten, die in Form von Grafiken gespeichert sind, können von großem Nutzen sein. Um jedoch einen vollständigen Überblick über den Cluster zu erhalten, benötigen Sie Warnungen. Wenn gerade ein Problem auftritt, muss der Benutzer benachrichtigt werden.
ClusterControl stellt eine Liste vordefinierter Advisor bereit, die den Status verschiedener Metriken und den Zustand Ihrer Datenbanken. Bei Bedarf erstellt ClusterControl eine Warnung.
Wie Sie im obigen Screenshot sehen können, geht es nicht nur um Metriken. ClusterControl führt auch Plausibilitätsprüfungen für wichtige Einstellungen durch und liefert einige Vorhersagen. Hinsichtlich der Speicherplatzauslastung versucht ClusterControl beispielsweise, den Benutzer zu warnen, falls die Festplattenauslastung zu schnell ansteigt. Natürlich werden Benachrichtigungen nicht nur über Berater gesendet. Ereignisse wie „Node down“ oder „failed backup“ führen ebenfalls zu einer Benachrichtigung.
Es ist erwähnenswert, dass Ratgeber in einer JavaScript-ähnlichen Sprache geschrieben sind und mit dem Developer Studio innerhalb von ClusterControl wie unten gezeigt bearbeitet werden können:
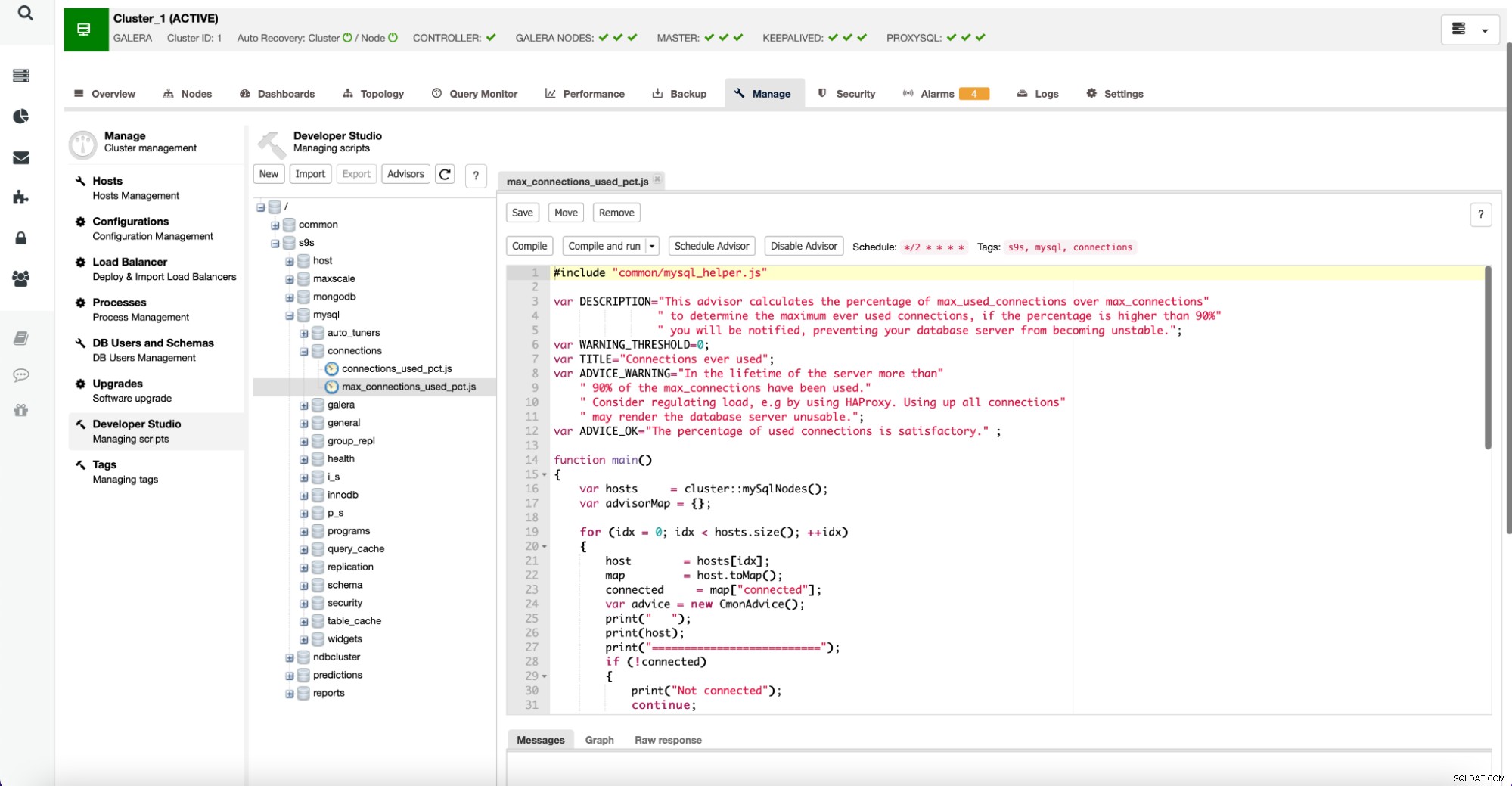
Benutzer können auch neue Advisor erstellen und deren Ausführung durch ClusterControl planen.
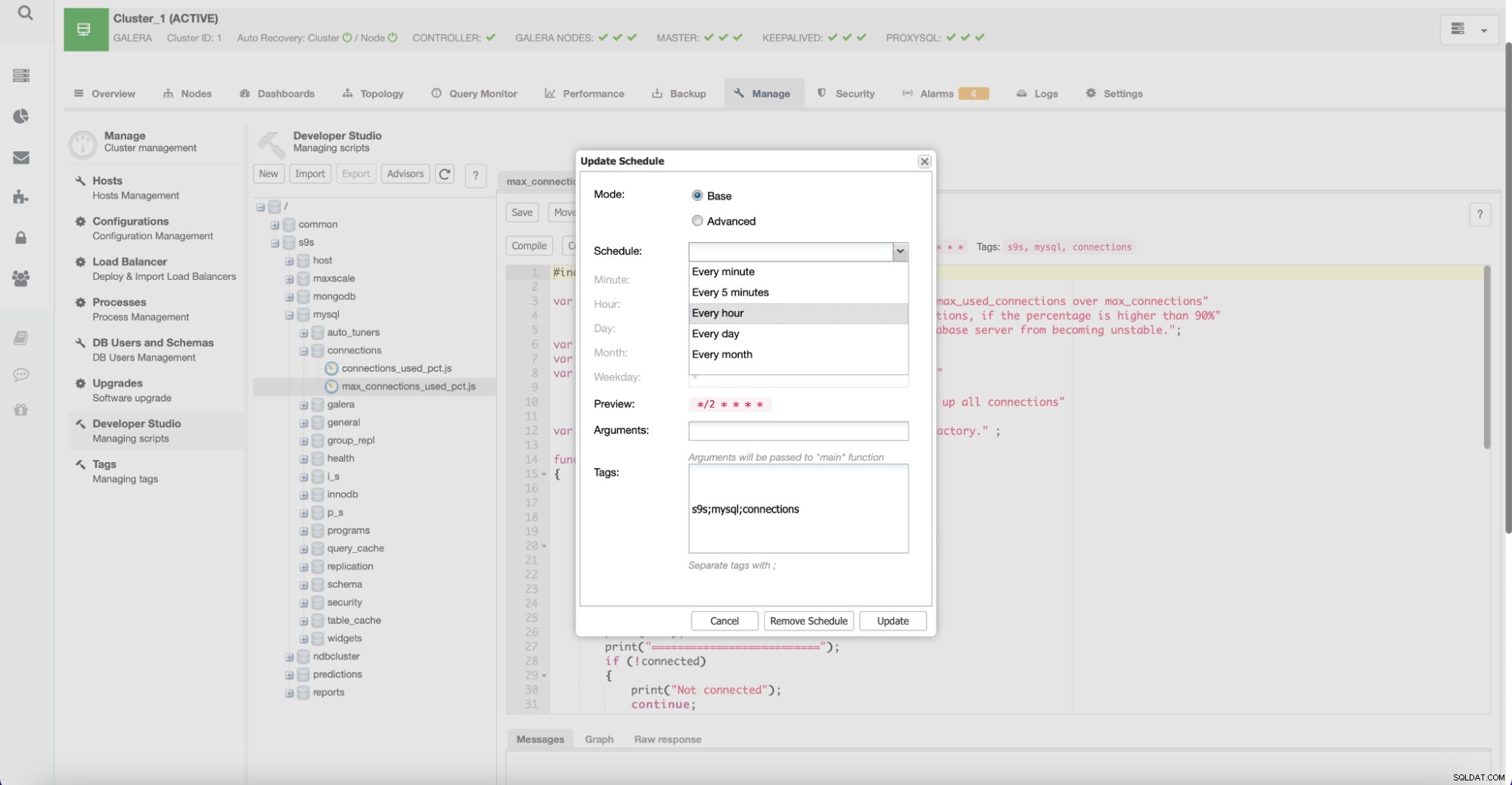
Mit dieser Funktion können Benutzer ihre eigenen Skripts entwickeln, die nach wichtigen Bits suchen spezifisch für die Umgebung. Solche Skripte können auch andere ClusterControl-Funktionen nutzen, beispielsweise wenn Sie eine automatische Skalierung basierend auf dem Wachstum einer Metrik implementieren möchten.
Bereit für die ersten Schritte mit ClusterControl?
Wie Sie sehen können, macht die Fähigkeit von ClusterControl, Überwachungs- und Warnaufgaben zu automatisieren und Ihnen gleichzeitig leicht verständliche und anpassbare Dashboards bereitzustellen, es zu einem unverzichtbaren Tool für DevOps und Systemadministratoren. Tatsächlich können Sie mit ClusterControl schnell und einfach alle Datenbankoperationen von einer einzigen Glasscheibe aus automatisieren. Möchten Sie aus erster Hand sehen, wie ClusterControl Ihnen helfen kann, Ihre Datenbanken effektiv zu überwachen? Laden Sie ClusterControl noch heute herunter, um es 30 Tage lang kostenlos zu testen.



