Dies ist Teil 2 dieser Blogserie. Teil 1 können Sie hier lesen: Die digitale Transformation ist eine Datenreise von Edge zu Insight
Diese Blog-Serie verfolgt die Herstellungs-, Betriebs- und Verkaufsdaten für einen Hersteller vernetzter Fahrzeuge, während die Daten Phasen und Transformationen durchlaufen, die typischerweise in einem großen Fertigungsunternehmen auf dem neuesten Stand der Technik auftreten. Der erste Blog stellte ein fiktives Herstellerunternehmen für vernetzte Fahrzeuge, The Electric Car Company (ECC), vor, um den Weg der Herstellungsdaten durch den Datenlebenszyklus zu veranschaulichen. Um dies zu erreichen, nutzt ECC die Cloudera Data Platform (CDP), um Ereignisse vorherzusagen und einen Top-Down-Überblick über den Herstellungsprozess des Autos in seinen Werken auf der ganzen Welt zu erhalten.
Nachdem der Schritt der Datenerfassung im vorherigen Blog abgeschlossen wurde, ist der nächste Schritt des ECC im Datenlebenszyklus die Datenanreicherung. Das ECC reichert die gesammelten Daten an und stellt sie später im Datenlebenszyklus für die Analyse und Modellerstellung zur Verfügung. Unten ist der gesamte Satz von Schritten im Datenlebenszyklus aufgeführt, und jeder Schritt im Lebenszyklus wird durch einen eigenen Blogbeitrag unterstützt (siehe Abb. 1):
- Datenerhebung – Datenaufnahme und -überwachung am Edge (unabhängig davon, ob es sich bei dem Edge um Industriesensoren oder Personen in einem Fahrzeugausstellungsraum handelt)
- Datenanreicherung – Verarbeitung, Aggregation und Verwaltung von Datenpipelines, um die Daten für die weitere Analyse vorzubereiten
- Berichte – Bereitstellung von Geschäftseinblicken (Verkaufsanalysen und -prognosen, Budgetierung als Beispiele)
- Servieren – Steuerung und Ausführung wesentlicher Geschäftsvorgänge (Händlerbetrieb, Produktionsüberwachung)
- Predictive Analytics – Predictive Analytics basierend auf KI und maschinellem Lernen (Predictive Maintenance, bedarfsorientierte Bestandsoptimierung als Beispiele)
- Sicherheit und Verwaltung – ein integriertes Set von Sicherheits-, Management- und Governance-Technologien über den gesamten Datenlebenszyklus

Abb. 1 Der Lebenszyklus von Unternehmensdaten
Herausforderung zur Datenanreicherung
ECC benötigt einen umfassenden Überblick und ein solides Verständnis aller Daten im Zusammenhang mit der Herstellung, dem Händlerbetrieb und dem Versand ihrer Fahrzeuge. Sie müssen auch Probleme mit den Daten schnell identifizieren, z. B. Betriebssensoren, die Daten ausgeben, die falsche Temperaturspitzen enthalten können, die durch ungeplante Maschinenstopps oder abrupte Starts verursacht werden. Daten, die keinen Bezug zum Prozess haben, wenn beispielsweise Wartungsarbeiter bei Routineinspektionen einen Sensor aus einem Säuretauchbecken entfernen, sollten in der Analyse nicht berücksichtigt werden.
Darüber hinaus steht ECC vor den folgenden Datenherausforderungen, die angegangen werden müssen, um die Motorenherstellung erfolgreich durch ihre Lieferkette zu führen. Zu diesen Datenherausforderungen gehören die folgenden:
- Abrufen von Daten in verschiedenen Formaten aus verschiedenen Quellen: Data-Engineering-Pipelines erfordern, dass Daten aus verschiedenen Quellen und in vielen verschiedenen Formaten eingebracht werden. Unabhängig davon, ob Daten von Sensoren an der Produktionslinie stammen, die Fertigungsabläufe unterstützen, oder ERP-Daten, die die Lieferkette steuern, sie alle müssen für die weitere Analyse zusammengeführt werden.
- Redundante oder irrelevante Daten herausfiltern: Das Entfernen doppelter oder ungültiger Daten und das Sicherstellen der Genauigkeit der verbleibenden Daten ist ein wichtiger Schritt bei der Vorbereitung der Daten für die weitere Verwendung in erweiterten prädiktiven Analysen.
- Fähigkeit, ineffiziente Prozesse zu identifizieren: ECC erfordert die Fähigkeit zu erkennen, welche Datenprozesse die meiste Zeit und Ressourcen in Anspruch nehmen, sodass es einfach ist, auf leistungsschwache Teile der Pipeline abzuzielen, um den Gesamtprozess zu beschleunigen.
- Fähigkeit, alle Prozesse von einem einzigen Bereich aus zu überwachen: ECC benötigt ein zentralisiertes System, das es ihnen ermöglicht, alle laufenden Datenprozesse zu überwachen, sowie eine Möglichkeit, ihre aktuelle Infrastruktur zu erweitern und gleichzeitig die Transparenz zu wahren.
Kuratierte, qualitativ hochwertige Datensätze sind das Rückgrat jeder Advanced-Analytics-Initiative. Um dies zu erreichen, muss ein Data-Engineering-Framework verwendet werden, um den Bau aller Rohrleitungen und Leitungen zu ermöglichen, die zum Verschieben, Bearbeiten und Verwalten von Daten der verschiedenen Fahrzeugteile im Datenlebenszyklus erforderlich sind.
Aufbau einer Pipeline mit Cloudera Data Engineering
Bevor die Daten im ersten Blog angereichert und diskutiert werden, werden die in der Fabrik gesammelten IT- und OT-Datenströme bereinigt, manipuliert und modifiziert. Fabrik-ID, Maschinen-ID, Zeitstempel, Teilenummer und Seriennummer könnten von einem QR-Code erfasst werden, der auf dem Elektromotor aufgedruckt ist. Beim Einbau des Motors in das vernetzte Fahrzeug werden Daten wie Modelltyp, Fahrgestellnummer und Basisfahrzeugkosten erfasst.
Nach dem Verkauf des Fahrzeugs werden die Verkaufsinformationen wie Kundenname, Kontaktinformationen, endgültiger Verkaufspreis und Kundenstandort separat erfasst. Diese Daten sind entscheidend für die Kontaktaufnahme mit dem Kunden für mögliche Rückrufe oder gezielte vorbeugende Wartung. Es werden auch Geolokalisierungsdaten gespeichert, die dabei helfen, Kundenstandorte auf Längen- und Breitengraden abzubilden, um besser zu verstehen, wo sich diese Motoren nach dem Verkauf in einem Fahrzeug befinden.
ECC wird Cloudera Data Engineering (CDE) verwenden, um die oben genannten Datenherausforderungen anzugehen (siehe Abb. 2). CDE stellt die Daten dann Cloudera Data Warehouse (CDW) zur Verfügung, wo sie für erweiterte Analysen und Business-Intelligence-Berichte zur Verfügung gestellt werden. Die CDE-Schritte sind unten aufgeführt.
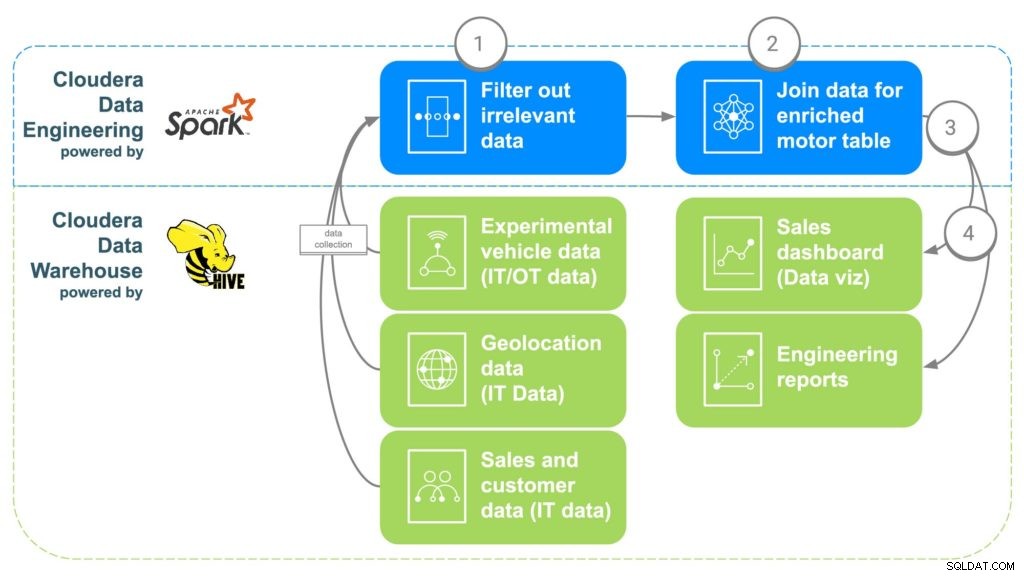
Abb. 2 ECC-Datenanreicherungspipeline
SCHRITT 1:Filtern und trennen Sie die Daten
Der erste Schritt bei der Verwendung von CDE besteht darin, einen PySpark-Job zu erstellen, der die Daten aus diesen verschiedenen „rohen“ Quellen aus Schritt 1 einbringt. Dies ist eine Gelegenheit, seitdem alle irrelevanten Daten wie beispielsweise Kunden unter 16 Jahren herauszufiltern ist in der Regel das Mindestalter zum Fahren. Doppelte Daten und andere irrelevante Daten können ebenfalls gefiltert oder aussortiert werden.
SCHRITT 2:Kombinieren Sie die Daten
Um alle Daten zu kombinieren, korreliert CDE gemeinsame Links miteinander. Zunächst werden die Autoverkaufsdaten mit dem Kunden verknüpft, der das Auto gekauft hat, um die Kundenmetadaten wie Kontaktinformationen, Alter, Gehalt usw. zu erhalten. Geolokalisierungsdaten werden dann verwendet, um genauere Standortinformationen für den Kunden zu erhalten , die später bei der Zuordnung der Motoren helfen. Teileinstallationsdaten werden verwendet, um die Seriennummern für jeden Motor zu identifizieren, der in das Auto des Kunden eingebaut wurde. Schließlich werden die Werksdaten mit der Seriennummer des Motors abgeglichen, die angibt, welches Werk, welche Maschine und wann jeder spezifische Motor erstellt wurde.
SCHRITT 3:Daten an Cloudera Data Warehouse senden
Sobald alle Daten in einer angereicherten Tabelle zusammengeführt wurden, schreibt ein einfacher Apache Spark-Befehl die Daten in eine neue Tabelle in Cloudera Data Warehouse. Dadurch werden die Daten allen Data Scientists zugänglich, die darauf zugreifen möchten, um zusätzliche Analysen durchzuführen.
SCHRITT 4:Generieren Sie Dashboards und Berichte zur Datenvisualisierung
Mit den Daten an einem Ort können jetzt Berichte erstellt werden, die es den Mitarbeitern ermöglichen, fundiertere Entscheidungen zu treffen und Möglichkeiten zu eröffnen, die es nicht gab. Heatmaps können erstellt werden, um den Motorstandort zu verfolgen und Probleme mit potenziellen geografischen Standorten zu korrelieren, z. B. Ausfall aufgrund extremer Kälte oder Hitze. Diese Daten könnten auch verwendet werden, um genau nachzuverfolgen, welche Kunden möglicherweise betroffen sind, wenn in einem bestimmten Werk über einen bestimmten Zeitraum hinweg ein Problem auftritt, wodurch es einfach wird, Kunden aufzuspüren, die möglicherweise einen Rückruf oder eine vorbeugende Wartung benötigen.
Schlussfolgerung
Cloudera Data Engineering ermöglicht ECC den Aufbau einer Pipeline, die Herstellungs- und Teiledaten, Kundennutzungstyp, Umgebungsbedingungen, Verkaufsinformationen und mehr korrelieren kann, um die Kundenzufriedenheit und Fahrzeugzuverlässigkeit zu verbessern. ECC hat seine Ziele erreicht und seine Herausforderungen gemeistert, indem es die Daten im Zusammenhang mit der Herstellung seiner Motoren verfolgt und auf folgende Weise davon profitiert:
- ECC beschleunigte die Amortisierungszeit durch die Orchestrierung und Automatisierung von Datenpipelines, um kuratierte, hochwertige Datensätze sicher und transparent aus verschiedenen Datenquellen bereitzustellen.
- ECC konnte relevante Daten identifizieren und redundante und doppelte Daten herausfiltern.
- ECC war in der Lage, die Überwachung der Datenpipeline von einem einzigen Fenster aus zu erreichen, während es gleichzeitig in der Lage war, durch visuelle Fehlerbehebung frühzeitig auf Probleme aufmerksam gemacht zu werden, um Probleme schnell zu lösen, bevor das Geschäft beeinträchtigt wurde.
Suchen Sie nach dem nächsten Blog, der sich mit der Berichterstellung befasst und zeigt, wie ECC-Ingenieure Ad-hoc-Abfragen in CDW gegen diese kuratierten Daten ausführen und die Daten mit anderen relevanten Quellen innerhalb eines Unternehmens-Data Warehouse verknüpfen. CDW erleichtert das Zusammenführen aller Daten und bietet ein integriertes Datenvisualisierungstool, um von abgefragten Ergebnissen zu Dashboards zu gelangen. Seien Sie gespannt auf den nächsten!
Weitere Ressourcen zur Datenerfassung
Um all dies in Aktion zu sehen, klicken Sie bitte auf die entsprechenden Links unten, um mehr über die Datenanreicherung zu erfahren:
- Video – Wenn Sie sehen und hören möchten, wie dies gebaut wurde, sehen Sie sich das Video unter dem Link an.
- Tutorials – Wenn Sie dies in Ihrem eigenen Tempo tun möchten, sehen Sie sich eine detaillierte Anleitung mit Screenshots und zeilenweisen Anweisungen an, wie Sie dies einrichten und ausführen. Tutorials li>
- Meetup – Wenn Sie direkt mit Experten von Cloudera sprechen möchten, nehmen Sie bitte an einem virtuellen Meetup teil, um eine Live-Stream-Präsentation zu sehen. Am Ende ist Zeit für direkte Fragen und Antworten.
- Benutzer – Klicken Sie auf den Link, um weitere technische Inhalte speziell für Benutzer anzuzeigen.



