MongoDB-Zonen
Um MongoDB-Zonen zu verstehen, müssen wir zunächst verstehen, was eine Zone ist:eine Gruppe von Shards, die auf einem bestimmten Satz von Tags basiert.
MongoDB-Zonen helfen bei der Verteilung von Chunks basierend auf Tags über Shards hinweg. Alle Arbeiten (Lese- und Schreibvorgänge) im Zusammenhang mit Dokumenten innerhalb einer Zone werden auf Shards ausgeführt, die mit dieser Zone übereinstimmen.
Es kann verschiedene Szenarien geben, in denen sich fragmentierte Cluster (zonenbasiert) als sehr nützlich erweisen können. Sagen wir:
- Eine geografisch verteilte Anwendung kann sowohl das Frontend als auch den Datenspeicher erfordern
- Eine Anwendung hat eine n-Tier-Architektur, sodass einige Datensätze von einer Hardware höherer Stufe (niedrige Latenz) abgerufen werden, während andere von einer Hardware niedriger Stufe (hohe Latenz) abgerufen werden könnten
Vorteile der Verwendung von MongoDB-Zonen
Mithilfe von MongoDB-Zonen können Datenbankadministratoren Tiered-Storage-Lösungen erstellen, die den Datenlebenszyklus unterstützen, wobei häufig verwendete Daten im Arbeitsspeicher gespeichert, weniger verwendete Daten auf dem Server gespeichert und zum richtigen Zeitpunkt archivierte Daten offline genommen werden.
So richten Sie Zonen ein
In Sharding-Clustern können Sie Zonen erstellen, die eine Gruppe von Shards darstellen, und dieser Zone einen oder mehrere Bereiche von Shard-Schlüsselwerten zuordnen. MongoDB leitet alle Lese- und Schreibvorgänge, die in einen Zonenbereich gelangen, nur an die Shards innerhalb der Zone weiter. Sie können jede Zone mit einem oder mehreren Shards im Cluster verknüpfen und ein Shard kann mit einer beliebigen Anzahl von Zonen verknüpft werden.
Einige der häufigsten Bereitstellungsmuster, bei denen Zonen angewendet werden können, lauten wie folgt:
- Isolieren Sie eine bestimmte Teilmenge von Daten auf einem bestimmten Satz von Shards.
- Indem sichergestellt wird, dass sich die relevantesten Daten auf Shards befinden, die den Anwendungsservern geografisch am nächsten sind.
- Leiten Sie Daten basierend auf der Leistung der Shard-Hardware an die Shards weiter.
Das folgende Bild zeigt einen Sharding-Cluster mit drei Shards und zwei Zonen. Die A-Zone stellt einen Bereich mit einer Untergrenze von 0 und einer Obergrenze von 10 dar. Die B-Zone zeigt einen Bereich mit einer Untergrenze von 10 und einer Obergrenze von 20. Die Shards ROT und BLAU haben die A-Zone. Shard BLUE hat auch die B-Zone. Mit Shard GREEN sind keine Zonen verbunden. Der Cluster befindet sich in einem stabilen Zustand und keine Chunks verletzen eine der Zonen
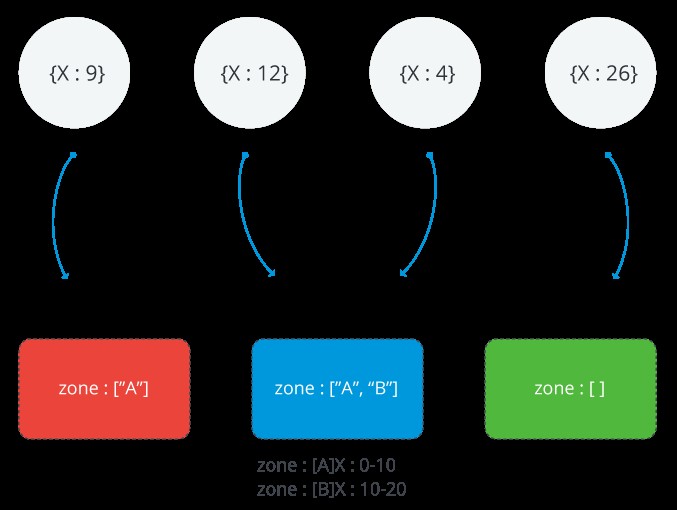
Reichweite einer MongoDB-Zone
Jede einzelne Zone deckt einen oder mehrere Bereiche von Shard-Schlüsselwerten ab. Jeder Bereich, den eine Zone abdeckt, schließt immer seine Untergrenze ein und schließt seine Obergrenze aus.
Denken Sie daran: Zonen können sich keine Bereiche teilen und sie dürfen keine sich überschneidenden Bereiche haben.
Hinzufügen von Shards zu einer Zone
Die Methode sh.addShardTag() wird verwendet, um einem Shard Zonen hinzuzufügen. Ein einzelner Shard kann mehrere Zonen haben, und mehrere Shards können auch dieselbe Zone haben. Das folgende Beispiel fügt die Zone A einem Shard hinzu.
sh.addShardTag("shard0000", "A")Fragmente aus einer Zone entfernen
Um eine Zone aus einem Shard zu entfernen, wird die Methode sh.removeShardTag() verwendet. Das folgende Beispiel entfernt die Zone A aus einem Shard.
sh.removeShardTag("shard0002", "A")Tipps für MongoDB-Zonen
Dokumente einfach halten
MongoDB ist eine schemafreie Datenbank. Das bedeutet, dass standardmäßig kein vordefiniertes Schema vorhanden ist. Wir können in neueren Versionen ein vordefiniertes Schema hinzufügen, aber es ist nicht zwingend erforderlich. Unterschätzen Sie nicht die Schwierigkeiten, die beim Arbeiten mit Dokumenten und Arrays auftreten, da es sehr schwierig werden kann, Ihre Daten im anwendungsseitigen/ETL-Prozess zu parsen. Außerdem können Arrays die Replikationsleistung beeinträchtigen:Für jede Änderung im Array werden alle Array-Werte repliziert.
Die beste Hardware ist nicht immer die beste Option
Die Verwendung guter Hardware trägt definitiv zu einer guten Leistung bei. Aber was könnte in einer Umgebung passieren, wenn eine Instanz einer großen Maschine stirbt? Die Antwort lautet „Failover“.
Mehrere kleine Maschinen (anstelle von einer oder zwei) in einer verteilten Umgebung zu haben, kann sicherstellen, dass Ausfälle nur wenige Teile des Shards betreffen und von der Anwendung kaum oder gar nicht wahrgenommen werden. Aber gleichzeitig implizieren mehr Maschinen eine hohe Ausfallwahrscheinlichkeit. Berücksichtigen Sie diesen Kompromiss beim Entwerfen Ihrer Umgebung. Die richtigen Entscheidungen wirken sich auf die Leistung aus.
Arbeitssatz
Wie groß ist das Workingset? Normalerweise verwendet eine Anwendung nicht alle Daten. Manche Daten werden oft aktualisiert, andere nicht. Passt Ihr Arbeitsdatensatz in den Arbeitsspeicher? Eine optimale Leistung wird erreicht, wenn sich der gesamte Arbeitsdatensatz im RAM befindet.



