Die Effizienz einer Datenbank hängt nicht nur von der Feinabstimmung der kritischsten Parameter ab, sondern geht auch über die angemessene Datenpräsentation in den zugehörigen Sammlungen hinaus. Kürzlich habe ich an einem Projekt gearbeitet, das eine Social-Chat-Anwendung entwickelt hat, und nach ein paar Testtagen haben wir beim Abrufen von Daten aus der Datenbank eine gewisse Verzögerung festgestellt. Wir hatten nicht so viele Benutzer, also schlossen wir die Optimierung der Datenbankparameter aus und konzentrierten uns auf unsere Abfragen, um der Ursache auf den Grund zu gehen.
Zu unserer Überraschung stellten wir fest, dass unsere Datenstrukturierung nicht ganz angemessen war, da wir mehr als 1 Leseanfragen hatten, um bestimmte Informationen abzurufen.
Das konzeptionelle Modell, wie Anwendungsabschnitte eingerichtet werden, hängt stark von der Datenbanksammlungsstruktur ab. Wenn Sie sich beispielsweise bei einer sozialen App anmelden, werden Daten gemäß dem Anwendungsdesign, wie in der Datenbankpräsentation dargestellt, in die verschiedenen Abschnitte eingespeist.
Kurz gesagt, für eine gut gestaltete Datenbank sind die Schemastruktur und die Sammlungsbeziehungen Schlüsselfaktoren für eine verbesserte Geschwindigkeit und Integrität, wie wir in den folgenden Abschnitten sehen werden.
Wir besprechen die Faktoren, die Sie bei der Modellierung Ihrer Daten berücksichtigen sollten.
Was ist Datenmodellierung
Datenmodellierung ist im Allgemeinen die Analyse von Datenelementen in einer Datenbank und ihrer Beziehung zu anderen Objekten in dieser Datenbank.
In MongoDB können wir beispielsweise eine Benutzersammlung und eine Profilsammlung haben. Die Benutzersammlung listet die Namen von Benutzern für eine bestimmte Anwendung auf, während die Profilsammlung die Profileinstellungen für jeden Benutzer erfasst.
Bei der Datenmodellierung müssen wir eine Beziehung entwerfen, um jeden Benutzer mit dem entsprechenden Profil zu verbinden. Kurz gesagt, die Datenmodellierung ist der grundlegende Schritt im Datenbankdesign und bildet die Architekturbasis für die objektorientierte Programmierung. Es gibt auch einen Hinweis darauf, wie die physische Anwendung während des Entwicklungsfortschritts aussehen wird. Eine Anwendungs-Datenbank-Integrationsarchitektur kann wie folgt dargestellt werden.
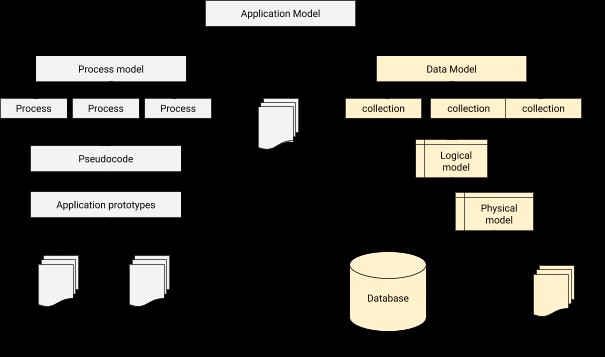
Der Prozess der Datenmodellierung in MongoDB
Die Datenmodellierung geht mit einer verbesserten Datenbankleistung einher, jedoch auf Kosten einiger Überlegungen, darunter:
- Datenabrufmuster
- Ausgleichsbedarf der Anwendung wie:Abfragen, Aktualisierungen und Datenverarbeitung
- Leistungsmerkmale der gewählten Datenbank-Engine
- Die inhärente Struktur der Daten selbst
MongoDB-Dokumentstruktur
Dokumente in MongoDB spielen eine wichtige Rolle bei der Entscheidungsfindung darüber, welche Technik für einen bestimmten Datensatz angewendet werden soll. Es gibt im Allgemeinen zwei Beziehungen zwischen Daten, und zwar:
- Eingebettete Daten
- Referenzdaten
Eingebettete Daten
In diesem Fall werden zugehörige Daten innerhalb eines einzelnen Dokuments entweder als Feldwert oder als Array innerhalb des Dokuments selbst gespeichert. Der Hauptvorteil dieses Ansatzes besteht darin, dass Daten denormalisiert werden und daher die Möglichkeit bieten, die zugehörigen Daten in einem einzigen Datenbankvorgang zu manipulieren. Folglich verbessert dies die Rate, mit der CRUD-Operationen ausgeführt werden, wodurch weniger Abfragen erforderlich sind. Betrachten wir ein Beispiel für ein Dokument unten:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}In diesem Datensatz haben wir einen Studenten mit seinem Namen und einigen anderen zusätzlichen Informationen. Das Feld „Settings“ wurde in ein Objekt eingebettet, und außerdem ist das Feld „placeLocation“ ebenfalls in ein Objekt mit den Breitengrad- und Längengradkonfigurationen eingebettet. Alle Daten für diesen Schüler sind in einem einzigen Dokument enthalten. Wenn wir alle Informationen für diesen Schüler abrufen müssen, führen wir einfach Folgendes aus:
db.students.findOne({StudentName : "George Beckonn"})Stärken der Einbettung
- Erhöhte Datenzugriffsgeschwindigkeit:Für eine verbesserte Zugriffsrate auf Daten ist die Einbettung die beste Option, da ein einziger Abfragevorgang Daten innerhalb des angegebenen Dokuments mit nur einer einzigen Datenbanksuche manipulieren kann.
- Reduzierte Dateninkonsistenz:Wenn während des Betriebs etwas schief geht (z. B. Netzwerktrennung oder Stromausfall), sind möglicherweise nur wenige Dokumente betroffen, da die Kriterien oft ein einzelnes Dokument auswählen.
- Reduzierte CRUD-Operationen. Das heißt, die Leseoperationen werden tatsächlich die Schreiboperationen übersteigen. Außerdem ist es möglich, verwandte Daten in einer einzigen atomaren Schreiboperation zu aktualisieren. Das heißt, für die obigen Daten können wir die Telefonnummer aktualisieren und auch die Entfernung mit dieser einzigen Operation erhöhen:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Schwächen der Einbettung
- Eingeschränkte Dokumentgröße. Alle Dokumente in MongoDB sind auf die BSON-Größe von 16 Megabyte beschränkt. Daher sollte die Gesamtdokumentgröße zusammen mit den eingebetteten Daten diese Grenze nicht überschreiten. Anderenfalls können bei einigen Speicher-Engines wie MMAPv1 die Daten auswachsen und zu einer Datenfragmentierung als Ergebnis einer verschlechterten Schreibleistung führen.
- Datenduplizierung:Mehrere Kopien derselben Daten erschweren die Abfrage der replizierten Daten und es kann länger dauern, eingebettete Dokumente zu filtern, wodurch der Hauptvorteil der Einbettung übertroffen wird.
Punktnotation
Die Punktnotation ist das Erkennungsmerkmal für eingebettete Daten im Programmierteil. Es wird verwendet, um auf Elemente eines eingebetteten Felds oder eines Arrays zuzugreifen. In den obigen Beispieldaten können wir mit dieser Abfrage unter Verwendung der Punktnotation Informationen des Schülers zurückgeben, dessen Standort „Botschaft“ ist.
db.users.find({'Settings.location': 'Embassy'})Referenzdaten
Die Datenbeziehung besteht in diesem Fall darin, dass die verwandten Daten in verschiedenen Dokumenten gespeichert sind, aber ein Verweislink zu diesen verwandten Dokumenten ausgegeben wird. Für die obigen Beispieldaten können wir sie so rekonstruieren, dass:
Benutzerdokument
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Einstellungsdokument
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Es gibt 2 verschiedene Dokumente, aber sie sind durch denselben Wert für die Felder _id und id verknüpft. Das Datenmodell wird somit normalisiert. Damit wir jedoch auf Informationen aus einem verwandten Dokument zugreifen können, müssen wir zusätzliche Abfragen durchführen, was folglich zu einer längeren Ausführungszeit führt. Wenn wir beispielsweise das ParentPhone und die zugehörigen Entfernungseinstellungen aktualisieren möchten, müssen wir mindestens 3 Abfragen haben, d. h.
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Stärken der Referenzierung
- Datenkonsistenz. Für jedes Dokument wird eine kanonische Form beibehalten, daher ist die Wahrscheinlichkeit einer Dateninkonsistenz ziemlich gering.
- Verbesserte Datenintegrität. Aufgrund der Normalisierung ist es einfach, Daten unabhängig von der Dauer der Operation zu aktualisieren und somit korrekte Daten für jedes Dokument sicherzustellen, ohne Verwirrung zu stiften.
- Verbesserte Cache-Nutzung. Kanonische Dokumente, auf die häufig zugegriffen wird, werden im Cache gespeichert und nicht für eingebettete Dokumente, auf die einige Male zugegriffen wird.
- Effiziente Hardwarenutzung. Im Gegensatz zum Einbetten, das zu einem Überwachsen des Dokuments führen kann, fördert das Referenzieren das Dokumentwachstum nicht und reduziert somit die Festplatten- und RAM-Nutzung.
- Verbesserte Flexibilität, insbesondere bei einer großen Anzahl von Filialdokumenten.
- Schnellere Schreibvorgänge.
Schwächen der Referenzierung
- Mehrere Suchen:Da wir in einer Reihe von Dokumenten suchen müssen, die den Kriterien entsprechen, verlängert sich die Lesezeit beim Abrufen von der Festplatte. Außerdem kann dies zu Cache-Fehlern führen.
- Viele Abfragen werden ausgegeben, um einen bestimmten Vorgang auszuführen, daher erfordern normalisierte Datenmodelle mehr Roundtrips zum Server, um einen bestimmten Vorgang abzuschließen.
Datennormalisierung
Datennormalisierung bezieht sich auf die Umstrukturierung einer Datenbank in Übereinstimmung mit einigen normalen Formen, um die Datenintegrität zu verbessern und Datenredundanzen zu reduzieren.
Die Datenmodellierung dreht sich um zwei Hauptnormalisierungstechniken, nämlich:
-
Normalisierte Datenmodelle
Wie bei Referenzdaten angewendet, teilt die Normalisierung Daten in mehrere Sammlungen mit Verweisen zwischen den neuen Sammlungen auf. Eine einzelne Dokumentaktualisierung wird an die andere Sammlung ausgegeben und entsprechend auf das übereinstimmende Dokument angewendet. Dies bietet eine effiziente Datenaktualisierungsdarstellung und wird häufig für Daten verwendet, die sich häufig ändern.
-
Denormalisierte Datenmodelle
Daten enthalten eingebettete Dokumente, wodurch Leseoperationen sehr effizient werden. Dies ist jedoch mit einer höheren Speicherplatznutzung und auch mit Schwierigkeiten bei der Synchronisierung verbunden. Das Denormalisierungskonzept lässt sich gut auf Unterdokumente anwenden, deren Daten sich nicht häufig ändern.
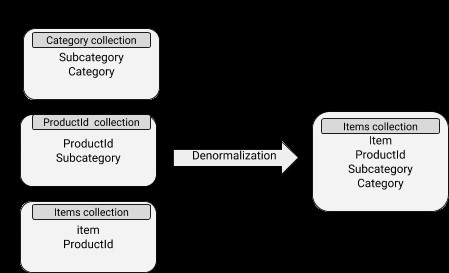
MongoDB-Schema
Ein Schema ist im Grunde ein umrissenes Skelett von Feldern und Datentypen, die jedes Feld für einen bestimmten Datensatz enthalten sollte. Aus SQL-Sicht sind alle Zeilen so konzipiert, dass sie die gleichen Spalten haben, und jede Spalte sollte den definierten Datentyp enthalten. In MongoDB haben wir jedoch standardmäßig ein flexibles Schema, das nicht für alle Dokumente die gleiche Konformität aufweist.
Flexibles Schema
Ein flexibles Schema in MongoDB definiert, dass die Dokumente nicht unbedingt die gleichen Felder oder Datentypen haben müssen, da sich ein Feld zwischen Dokumenten innerhalb einer Sammlung unterscheiden kann. Der Hauptvorteil dieses Konzepts besteht darin, dass man neue Felder hinzufügen, vorhandene entfernen oder die Feldwerte in einen neuen Typ ändern und somit das Dokument in eine neue Struktur aktualisieren kann.
Zum Beispiel können wir diese 2 Dokumente in derselben Sammlung haben:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}Im ersten Dokument haben wir ein Altersfeld, während es im zweiten Dokument kein Altersfeld gibt. Außerdem ist der Datentyp für das ParentPhone-Feld eine Zahl, während er im zweiten Dokument auf „false“ gesetzt wurde, was ein boolescher Typ ist.
Die Schemaflexibilität erleichtert die Zuordnung von Dokumenten zu einem Objekt, und jedes Dokument kann mit Datenfeldern der dargestellten Entität übereinstimmen.
Starres Schema
So sehr wir bereits gesagt haben, dass sich diese Dokumente voneinander unterscheiden können, entscheiden Sie sich manchmal vielleicht dafür, ein starres Schema zu erstellen. Ein starres Schema definiert, dass alle Dokumente in einer Sammlung dieselbe Struktur haben, und dies gibt Ihnen eine bessere Chance, einige Dokumentvalidierungsregeln festzulegen, um die Datenintegrität während Einfüge- und Aktualisierungsvorgängen zu verbessern.
Schemadatentypen
Wenn Sie einige Servertreiber für MongoDB wie Mongoose verwenden, gibt es einige bereitgestellte Datentypen, mit denen Sie eine Datenvalidierung durchführen können. Die grundlegenden Datentypen sind:
- Zeichenfolge
- Nummer
- Boolesch
- Datum
- Puffer
- Objekt-ID
- Array
- Gemischt
- Dezimal128
- Karte
Sehen Sie sich das Beispielschema unten an
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Anwendungsbeispiel
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Schemavalidierung
So sehr Sie die Datenvalidierung von der Anwendungsseite aus durchführen können, ist es immer eine gute Praxis, die Validierung auch vom Serverende aus durchzuführen. Wir erreichen dies, indem wir die Schema-Validierungsregeln anwenden.
Diese Regeln werden während der Einfüge- und Aktualisierungsvorgänge angewendet. Sie werden normalerweise während des Erstellungsprozesses auf Sammlungsbasis deklariert. Sie können die Dokumentenvalidierungsregeln jedoch auch zu einer bestehenden Sammlung hinzufügen, indem Sie den collMod-Befehl mit Validierungsoptionen verwenden, aber diese Regeln werden nicht auf die bestehenden Dokumente angewendet, bis eine Aktualisierung auf sie angewendet wird.
Ebenso können Sie beim Erstellen einer neuen Sammlung mit dem Befehl db.createCollection() die Option validator ausgeben. Sehen Sie sich dieses Beispiel an, wenn Sie eine Sammlung für Schüler erstellen. Ab Version 3.6 unterstützt MongoDB die JSON-Schema-Validierung, sodass Sie lediglich den $jsonSchema-Operator verwenden müssen.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})Wenn wir in diesem Schemaentwurf versuchen, ein neues Dokument einzufügen wie:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})Die Callback-Funktion gibt den folgenden Fehler zurück, da gegen einige Validierungsregeln verstoßen wurde, z. B. dass der angegebene Jahreswert nicht innerhalb der angegebenen Grenzen liegt.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Außerdem können Sie Abfrageausdrücke zu Ihrer Validierungsoption hinzufügen, indem Sie Abfrageoperatoren außer $where, $text, near und $nearSphere verwenden, d. h.:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Schemavalidierungsebenen
Wie bereits erwähnt, wird normalerweise eine Validierung für die Schreiboperationen ausgegeben.
Die Validierung kann jedoch auch auf bereits vorhandene Dokumente angewendet werden.
Es gibt 3 Validierungsstufen:
- Streng:Dies ist die standardmäßige MongoDB-Validierungsebene und wendet Validierungsregeln auf alle Einfügungen und Aktualisierungen an.
- Moderat:Die Validierungsregeln werden nur bei Einfügungen, Aktualisierungen und auf bereits vorhandene Dokumente angewendet, die die Validierungskriterien erfüllen.
- Aus:Diese Ebene setzt die Validierungsregeln für ein bestimmtes Schema auf null, daher wird keine Validierung an den Dokumenten durchgeführt.
Beispiel:
Lassen Sie uns die folgenden Daten in eine Client-Sammlung einfügen.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Wenn wir die moderate Validierungsstufe anwenden mit:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )Die Validierungsregeln werden nur auf das Dokument mit der _id 1 angewendet, da es alle Kriterien erfüllt.
Da die Validierungsregeln für das zweite Dokument nicht mit den ausgestellten Kriterien erfüllt sind, wird das Dokument nicht validiert.
Aktionen zur Schemavalidierung
Nach der Validierung von Dokumenten kann es einige geben, die gegen die Validierungsregeln verstoßen. In diesem Fall ist es immer erforderlich, Maßnahmen zu ergreifen.
MongoDB bietet zwei Aktionen, die für Dokumente ausgeführt werden können, die die Validierungsregeln nicht erfüllen:
- Fehler:Dies ist die Standardaktion von MongoDB, die jede Einfügung oder Aktualisierung ablehnt, falls sie gegen die Validierungskriterien verstößt.
-
Warnen:Diese Aktion zeichnet den Verstoß im MongoDB-Protokoll auf, lässt jedoch zu, dass der Einfüge- oder Aktualisierungsvorgang abgeschlossen wird. Zum Beispiel:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Wenn wir versuchen, ein Dokument wie dieses einzufügen:
db.students.insert( { name: "Amanda", status: "Updated" } );Das gpa fehlt, obwohl es sich um ein erforderliches Feld im Schemadesign handelt, aber da die Validierungsaktion auf warn gesetzt wurde, wird das Dokument gespeichert und eine Fehlermeldung im MongoDB-Protokoll aufgezeichnet.



