In unserem vorherigen Hadoop-Tutorial haben wir uns mit Hadoop Partitioner beschäftigt im Detail. Jetzt werden wir InputSplit in Hadoop MapReduce besprechen.
Hier behandeln wir, was Hadoop InputSplit ist, die Notwendigkeit von InputSplit in MapReduce. Wir werden auch ausführlich besprechen, wie diese InputSplits in Hadoop MapReduce erstellt werden.
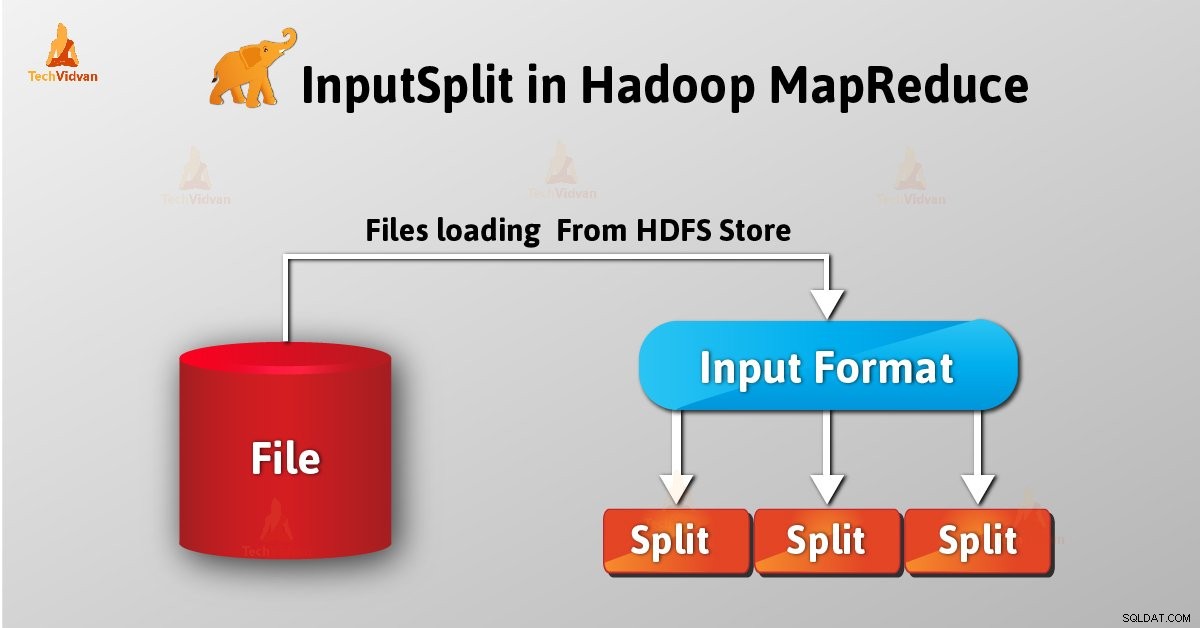
Einführung in InputSplit in Hadoop
InputSplit ist die logische Darstellung von Daten in Hadoop MapReduce. Es stellt die Daten dar, die der einzelne Mapper hat Prozesse. Somit ist die Anzahl der Map-Tasks gleich der Anzahl der InputSplits. Framework teilt Split in Datensätze auf, die der Mapper verarbeitet.
Die Länge von MapReduce InputSplit wurde in Bytes gemessen. Jeder InputSplit hat Speicherorte (Hostnamen-Strings). Das MapReduce-System platziert Kartenaufgaben mithilfe von Speicherorten so nah wie möglich an den Split-Daten.
Framework verarbeitet Map-Aufgaben in der Reihenfolge der Größe der Splits, sodass der größte zuerst verarbeitet wird (gieriger Approximationsalgorithmus). Dadurch wird die Joblaufzeit minimiert.
Die Hauptsache ist, dass Inputsplit die Eingabedaten nicht enthält; es ist nur ein Verweis auf die Daten.
Wie werden InputSplits in Hadoop MapReduce erstellt?
Als Benutzer behandeln wir InputSplit in Hadoop nicht direkt als InputFormat (da InputFormat für die Erstellung des Inputsplit und die Aufteilung in die Datensätze verantwortlich ist) erstellt es. FileInputFormat zerlegt eine Datei in 128-MB-Blöcke.
Auch durch Setzen von mapred .min .aufteilen .Größe Parameter in mapred-site .xml Der Benutzer kann den Wert nach Bedarf ändern. Auch dadurch können wir den Parameter im Job-Objekt überschreiben, das zum Senden eines bestimmten MapReduce-Jobs verwendet wird.
Indem wir ein benutzerdefiniertes InputFormat schreiben, können wir auch steuern, wie die Datei in Splits aufgeteilt wird.
InputSplit ist benutzerdefiniert. Der Benutzer kann die Aufteilungsgröße auch basierend auf der Größe der Daten im MapReduce-Programm steuern. Daher ist bei der Ausführung eines MapReduce-Jobs die Anzahl der Map-Tasks gleich der Anzahl der InputSplits.
Durch Aufruf von ‘getSplit()’ , berechnet der Client die Splits für den Job. Dann werden sie an den Anwendungsmaster gesendet, der ihre Speicherorte verwendet, um Zuordnungsaufgaben zu planen, die sie auf dem Cluster verarbeiten.
Danach übergibt die Zuordnungsaufgabe die Teilung an createRecordReader() Methode. Daraus erhält es RecordReader für die Trennung. Dann generiert RecordReader den Datensatz (Schlüssel-Wert-Paar) , die an die map-Funktion übergeben wird.
Schlussfolgerung
Zusammenfassend können wir sagen, dass InputSplit die Daten darstellt, die einzelne Mapper verarbeiten. Für jeden Split wird eine Kartenaufgabe erstellt. Daher erzeugt InputFormat den InputSplit.
Wenn Sie Fragen zu InputSplit in MapReduce haben, hinterlassen Sie bitte einen Kommentar in einem der unten angegebenen Abschnitte.



