Verschaffen Sie sich einen Überblick über die verfügbaren Mechanismen zum Sichern von in Apache HBase gespeicherten Daten und wie Sie diese Daten im Falle verschiedener Datenwiederherstellungs-/Failover-Szenarien wiederherstellen können
Mit der zunehmenden Einführung und Integration von HBase in kritische Geschäftssysteme müssen viele Unternehmen dieses wichtige Geschäftsgut schützen, indem sie robuste Backup- und Disaster-Recovery-Strategien (BDR) für ihre HBase-Cluster entwickeln. So entmutigend es auch klingen mag, potenzielle Petabytes an Daten schnell und einfach zu sichern und wiederherzustellen, HBase und das Apache Hadoop-Ökosystem bieten viele integrierte Mechanismen, um genau das zu erreichen.
In diesem Beitrag erhalten Sie einen allgemeinen Überblick über die verfügbaren Mechanismen zum Sichern von in HBase gespeicherten Daten und wie Sie diese Daten im Falle verschiedener Datenwiederherstellungs-/Failover-Szenarien wiederherstellen können. Nachdem Sie diesen Beitrag gelesen haben, sollten Sie in der Lage sein, eine fundierte Entscheidung darüber zu treffen, welche BDR-Strategie für Ihre Geschäftsanforderungen am besten geeignet ist. Sie sollten auch die Vor- und Nachteile sowie die Auswirkungen auf die Leistung jedes Mechanismus verstehen. (Die hierin enthaltenen Details gelten für CDH 4.3.0/HBase 0.94.6 und höher.)
Hinweis:Zum Zeitpunkt der Erstellung dieses Artikels bietet Cloudera Enterprise 4 produktionsbereite Backup- und Disaster-Recovery-Funktionen für HDFS und den Hive Metastore über Cloudera BDR 1.0 als einzeln lizenzierte Funktion. HBase ist in dieser GA-Version nicht enthalten; Daher sind die verschiedenen in diesem Blog beschriebenen Mechanismen erforderlich. (Cloudera Enterprise 5, derzeit in der Beta-Phase, bietet HBase-Snapshot-Management über Cloudera BDR.)
Sicherung
HBase ist ein verteilter Merge-Tree-Datenspeicher mit Protokollstruktur und komplexen internen Mechanismen, um Datengenauigkeit, Konsistenz, Versionierung usw. sicherzustellen. Wie in aller Welt können Sie also eine konsistente Sicherungskopie dieser Daten erhalten, die sich in einer Kombination aus HFiles und Write-Ahead-Logs (WALs) auf HDFS und im Speicher auf Dutzenden von Regionsservern befinden?
Beginnen wir mit dem am wenigsten störenden, kleinsten Daten-Fußabdruck und dem am wenigsten leistungsbeeinträchtigenden Mechanismus und arbeiten uns bis zum störendsten Tool im Forklift-Stil vor:
- Schnappschüsse
- Replikation
- Exportieren
- CopyTable
- HTable-API
- Offline-Sicherung von HDFS-Daten
Die folgende Tabelle bietet eine Übersicht für einen schnellen Vergleich dieser Ansätze, die ich im Folgenden ausführlich beschreibe.
| Auswirkung auf die Leistung | Datenfußabdruck | Ausfallzeit | Inkrementelle Sicherungen | Einfache Implementierung | Mean Time To Recovery (MTTR) | |
| Schnappschüsse | Minimal | Winzig | Kurz (nur bei Wiederherstellung) | Nein | Einfach | Sekunden |
| Replikation | Minimal | Groß | Keine | Intrinsisch | Mittel | Sekunden |
| Exportieren | Hoch | Groß | Keine | Ja | Einfach | Hoch |
| CopyTable | Hoch | Groß | Keine | Ja | Einfach | Hoch |
| API | Mittel | Groß | Keine | Ja | Schwierig | Bis zu Ihnen |
| Handbuch | Nicht zutreffend | Groß | Lang | Nein | Mittel | Hoch |
Schnappschüsse
Ab CDH 4.3.0 sind HBase-Snapshots voll funktionsfähig, reich an Funktionen und erfordern während ihrer Erstellung keine Cluster-Ausfallzeit. Mein Kollege Matteo Bertozzi hat Schnappschüsse in seinem Blogeintrag und anschließendem Deep Dive sehr gut behandelt. Hier werde ich nur einen groben Überblick geben.
Snapshots erfassen einfach einen Moment für Ihre Tabelle, indem sie das Äquivalent von UNIX-Hardlinks zu den Speicherdateien Ihrer Tabelle auf HDFS erstellen (Abbildung 1). Diese Snapshots werden innerhalb von Sekunden abgeschlossen, belasten den Cluster fast nicht und verursachen nur einen winzigen Datenbedarf. Ihre Daten werden überhaupt nicht dupliziert, sondern lediglich in kleinen Metadatendateien katalogisiert, wodurch das System zu diesem Zeitpunkt zurückkehren kann, falls Sie diesen Snapshot wiederherstellen müssen.
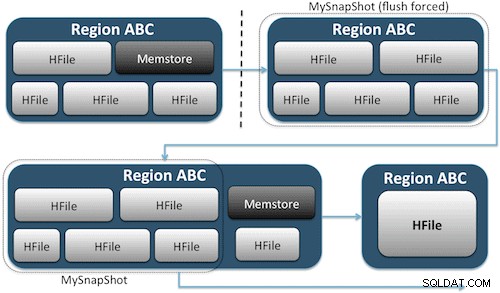
Das Erstellen eines Snapshots einer Tabelle ist so einfach wie das Ausführen dieses Befehls in der HBase-Shell:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Nachdem Sie diesen Befehl ausgegeben haben, finden Sie einige kleine Datendateien in /hbase/.snapshot/myTable (CDH4) oder /hbase/.hbase-snapshots (Apache 0.94.6.1) in HDFS, die die notwendigen Informationen zum Wiederherstellen Ihres Snapshots enthalten . Die Wiederherstellung ist so einfach wie die Eingabe dieser Befehle von der Shell:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Hinweis:Wie Sie sehen können, erfordert das Wiederherstellen eines Snapshots einen kurzen Ausfall, da die Tabelle offline sein muss. Alle Daten, die hinzugefügt/aktualisiert wurden, nachdem der wiederhergestellte Snapshot erstellt wurde, gehen verloren.
Wenn Sie aufgrund Ihrer geschäftlichen Anforderungen eine Offsite-Sicherung Ihrer Daten benötigen, können Sie den Befehl exportSnapshot verwenden, um die Daten einer Tabelle in Ihrem lokalen HDFS-Cluster oder einem Remote-HDFS-Cluster Ihrer Wahl zu duplizieren.
Schnappschüsse sind jedes Mal ein vollständiges Bild Ihrer Tabelle; Derzeit ist keine inkrementelle Snapshot-Funktion verfügbar.
HBase-Replikation
Die HBase-Replikation ist ein weiteres Backup-Tool mit sehr geringem Overhead. (Mein Kollege Himanshu Vashishtha behandelt die Replikation in diesem Blogbeitrag ausführlich.) Zusammenfassend lässt sich sagen, dass die Replikation auf der Ebene der Spaltenfamilie definiert werden kann, im Hintergrund arbeitet und alle Änderungen zwischen den Clustern in der Replikationskette synchron hält.
Die Replikation hat drei Modi:Master->Slave, Master<->Master und zyklisch. Dieser Ansatz gibt Ihnen die Flexibilität, Daten aus jedem Rechenzentrum aufzunehmen, und stellt sicher, dass sie über alle Kopien dieser Tabelle in anderen Rechenzentren hinweg repliziert werden. Im Falle eines katastrophalen Ausfalls in einem Rechenzentrum können Clientanwendungen mithilfe von DNS-Tools an einen anderen Speicherort für die Daten umgeleitet werden.
Die Replikation ist ein robuster, fehlertoleranter Prozess, der „eventuelle Konsistenz“ bietet, was bedeutet, dass kürzlich vorgenommene Änderungen an einer Tabelle möglicherweise nicht in allen Repliken dieser Tabelle verfügbar sind, aber garantiert irgendwann dort ankommen.
Hinweis:Bei vorhandenen Tabellen müssen Sie zunächst die Quelltabelle manuell in die Zieltabelle kopieren, und zwar über eine der anderen in diesem Beitrag beschriebenen Methoden. Die Replikation wirkt nur auf neue Schreibvorgänge/Bearbeitungen, nachdem Sie sie aktiviert haben.

(Von der Replikationsseite von Apache)
Exportieren
Das Export-Tool von HBase ist ein integriertes HBase-Dienstprogramm, das den einfachen Export von Daten aus einer HBase-Tabelle in einfache SequenceFiles in einem HDFS-Verzeichnis ermöglicht. Es erstellt einen MapReduce-Job, der eine Reihe von HBase-API-Aufrufen an Ihren Cluster durchführt und nacheinander jede Datenzeile aus der angegebenen Tabelle abruft und diese Daten in Ihr angegebenes HDFS-Verzeichnis schreibt. Dieses Tool ist für Ihren Cluster leistungsintensiver, da es MapReduce und die HBase-Client-API verwendet, aber es ist funktionsreich und unterstützt das Filtern von Daten nach Version oder Datumsbereich – wodurch inkrementelle Sicherungen ermöglicht werden.
Hier ist ein Beispiel des Befehls in seiner einfachsten Form:
hbase org.apache.hadoop.hbase.mapreduce.Export
Sobald Ihre Tabelle exportiert ist, können Sie die resultierenden Datendateien an eine beliebige Stelle kopieren (z. B. Offsite-/Off-Cluster-Speicher). Sie können auch einen Remote-HDFS-Cluster/-Verzeichnis als Ausgabespeicherort des Befehls angeben, und Export schreibt den Inhalt direkt in den Remote-Cluster. Bitte beachten Sie, dass dieser Ansatz ein Netzwerkelement in den Schreibpfad des Exports einfügt, daher sollten Sie sicherstellen, dass Ihre Netzwerkverbindung zum Remote-Cluster zuverlässig und schnell ist.
CopyTable
Das Dienstprogramm CopyTable wird in Jon Hsiehs Blogeintrag gut behandelt, aber ich werde die Grundlagen hier zusammenfassen. Ähnlich wie bei Export erstellt CopyTable einen MapReduce-Job, der die HBase-API verwendet, um aus einer Quelltabelle zu lesen. Der Hauptunterschied besteht darin, dass CopyTable seine Ausgabe direkt in eine Zieltabelle in HBase schreibt, die sich lokal in Ihrem Quellcluster oder auf einem Remotecluster befinden kann.
Ein Beispiel für die einfachste Form des Befehls ist:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Dieser Befehl kopiert den Inhalt einer Tabelle mit dem Namen „test“ in eine Tabelle im selben Cluster mit dem Namen „testCopy“.
Beachten Sie, dass CopyTable einen erheblichen Leistungsaufwand verursacht, da es einzelne „Puts“ verwendet, um die Daten Zeile für Zeile in die Zieltabelle zu schreiben. Wenn Ihre Tabelle sehr groß ist, kann CopyTable dazu führen, dass sich der Speicher auf den Servern der Zielregion füllt, was eine Leerung des Speichers erforderlich macht, die schließlich zu Komprimierungen, Garbage Collection usw. führt.
Darüber hinaus müssen Sie die Leistungsauswirkungen der Ausführung von MapReduce über HBase berücksichtigen. Bei großen Datensätzen ist dieser Ansatz möglicherweise nicht ideal.
HTable API (z. B. eine benutzerdefinierte Java-Anwendung)
Wie immer bei Hadoop können Sie jederzeit Ihre eigene benutzerdefinierte Anwendung schreiben, die die öffentliche API verwendet und die Tabelle direkt abfragt. Sie können dies über MapReduce-Jobs tun, um die Vorteile der verteilten Stapelverarbeitung dieses Frameworks zu nutzen, oder über andere Mittel Ihres eigenen Designs. Dieser Ansatz erfordert jedoch ein tiefes Verständnis der Hadoop-Entwicklung und aller APIs und Auswirkungen auf die Leistung, wenn diese in Ihrem Produktionscluster verwendet werden.
Offline-Backup von HDFS-Rohdaten
Der brachialste Backup-Mechanismus – auch der störendste – erfordert den größten Datenverbrauch. Sie können Ihren HBase-Cluster sauber herunterfahren und alle Daten und Verzeichnisstrukturen, die sich in /hbase in Ihrem HDFS-Cluster befinden, manuell kopieren. Da HBase ausgefallen ist, wird dadurch sichergestellt, dass alle Daten in HFiles in HDFS gespeichert wurden und Sie eine genaue Kopie der Daten erhalten. Es ist jedoch fast unmöglich, inkrementelle Sicherungen zu erhalten, da Sie bei zukünftigen Sicherungsversuchen nicht feststellen können, welche Daten geändert oder hinzugefügt wurden.
Es ist auch wichtig zu beachten, dass das Wiederherstellen Ihrer Daten eine Offline-Meta-Reparatur erfordern würde, da die .META. Die Tabelle würde zum Zeitpunkt der Wiederherstellung möglicherweise ungültige Informationen enthalten. Dieser Ansatz erfordert auch ein schnelles, zuverlässiges Netzwerk, um die Daten extern zu übertragen und bei Bedarf später wiederherzustellen.
Aus diesen Gründen rät Cloudera von diesem Ansatz für HBase-Sicherungen dringend ab.
Notfallwiederherstellung
HBase ist als extrem fehlertolerantes verteiltes System mit nativer Redundanz konzipiert, wobei davon ausgegangen wird, dass Hardware häufig ausfällt. Disaster Recovery in HBase gibt es normalerweise in mehreren Formen:
- Katastrophaler Ausfall auf Rechenzentrumsebene, der ein Failover zu einem Backup-Standort erfordert
- Sie müssen aufgrund eines Benutzerfehlers oder versehentlichen Löschens eine vorherige Kopie Ihrer Daten wiederherstellen
- Die Möglichkeit, eine Point-in-Time-Kopie Ihrer Daten zu Prüfzwecken wiederherzustellen
Wie bei jedem Notfallwiederherstellungsplan bestimmen die geschäftlichen Anforderungen, wie der Plan aufgebaut ist und wie viel Geld in ihn investiert werden soll. Nachdem Sie die Sicherungen Ihrer Wahl erstellt haben, nimmt die Wiederherstellung je nach Art der erforderlichen Wiederherstellung unterschiedliche Formen an:
- Failover zum Backup-Cluster
- Tabelle importieren/Snapshot wiederherstellen
- HBase-Stammverzeichnis auf Backup-Speicherort verweisen
Wenn Ihre Sicherungsstrategie so aussieht, dass Sie Ihre HBase-Daten auf einen Sicherungscluster in einem anderen Rechenzentrum repliziert haben, ist ein Failover so einfach wie das Verweisen Ihrer Endbenutzeranwendungen auf den Sicherungscluster mit DNS-Techniken.
Denken Sie jedoch daran, dass Sie, wenn Sie zulassen möchten, dass Daten während des Ausfallzeitraums in Ihren Backup-Cluster geschrieben werden, sicherstellen müssen, dass die Daten nach Ende des Ausfalls wieder in den primären Cluster gelangen. Die Master-zu-Master- oder zyklische Replikation übernimmt diesen Prozess automatisch für Sie, aber ein Master-Slave-Replikationsschema führt dazu, dass Ihr Master-Cluster nicht mehr synchron ist, sodass nach dem Ausfall ein manueller Eingriff erforderlich ist.
Neben der zuvor beschriebenen Export-Funktion gibt es ein entsprechendes Import-Tool, das die zuvor durch Export gesicherten Daten übernehmen und in einer HBase-Tabelle wiederherstellen kann. Die gleichen Auswirkungen auf die Leistung wie beim Export gelten auch für den Import. Wenn Ihr Backup-Schema das Erstellen von Snapshots umfasste, ist das Zurücksetzen auf eine frühere Kopie Ihrer Daten so einfach wie das Wiederherstellen dieses Snapshots.
Sie können sich auch nach einem Notfall erholen, indem Sie einfach die Eigenschaft hbase.root.dir in hbase-site.xml ändern und auf eine Sicherungskopie Ihres /hbase-Verzeichnisses verweisen, wenn Sie die Brute-Force-Offline-Kopie der HDFS-Datenstrukturen erstellt haben . Dies ist jedoch auch die am wenigsten wünschenswerte Wiederherstellungsoption, da sie einen längeren Ausfall erfordert, während Sie die gesamte Datenstruktur zurück in Ihren Produktionscluster kopieren, und wie bereits erwähnt, .META. könnte nicht synchron sein.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass die Wiederherstellung von Daten nach irgendeiner Form von Verlust oder Ausfall einen gut konzipierten BDR-Plan erfordert. Ich empfehle dringend, dass Sie Ihre Geschäftsanforderungen in Bezug auf Betriebszeit, Datengenauigkeit/-verfügbarkeit und Notfallwiederherstellung gründlich verstehen. Ausgestattet mit detaillierten Kenntnissen Ihrer Geschäftsanforderungen können Sie sorgfältig die Tools auswählen, die diese Anforderungen am besten erfüllen.
Die Auswahl der Werkzeuge ist jedoch nur der Anfang. Sie sollten groß angelegte Tests Ihrer BDR-Strategie durchführen, um sicherzustellen, dass sie in Ihrer Infrastruktur funktioniert, Ihren Geschäftsanforderungen entspricht und dass Ihre Betriebsteams mit den erforderlichen Schritten vor einem Ausfall bestens vertraut sind, und Sie finden das auf die harte Tour heraus Ihr BDR-Plan wird nicht funktionieren.
Wenn Sie dieses Thema kommentieren oder weiter diskutieren möchten, nutzen Sie unser Community-Forum für HBase.
Weiterführende Literatur:
- Jon Hsiehs Strata + Hadoop World 2012-Präsentation
- HBase:Der endgültige Leitfaden (Lars George)
- HBase in Aktion (Nick Dimiduk/Amandeep Khurana)



