Die Bewertung, welches Streaming-Architekturmuster am besten zu Ihrem Anwendungsfall passt, ist eine Voraussetzung für eine erfolgreiche Produktionsbereitstellung.
Das Apache Hadoop-Ökosystem hat sich zu einer bevorzugten Plattform für Unternehmen entwickelt, die große Datenmengen in Echtzeit verarbeiten und verstehen möchten. Technologien wie Apache Kafka, Apache Flume, Apache Spark, Apache Storm und Apache Samza gehen zunehmend an die Grenzen des Möglichen. Es ist oft verlockend, große Streaming-Anwendungsfälle zusammenzufassen, aber in Wirklichkeit neigen sie dazu, in einige wenige unterschiedliche Architekturmuster zu zerfallen, wobei unterschiedliche Komponenten des Ökosystems besser für unterschiedliche Probleme geeignet sind.
In diesem Beitrag werde ich die vier wichtigsten Streaming-Muster skizzieren, die uns bei Kunden begegnet sind, die Enterprise Data Hubs in der Produktion betreiben, und erklären, wie diese Muster architektonisch auf Hadoop implementiert werden können.
Streaming-Muster
Die vier grundlegenden Streaming-Muster (oft zusammen verwendet) sind:
- Streamaufnahme: Umfasst das Persistieren von Ereignissen mit niedriger Latenzzeit in HDFS, Apache HBase und Apache Solr.
- Near-Real-Time (NRT)-Ereignisverarbeitung mit externem Kontext: Ergreift Aktionen wie Warnen, Markieren, Transformieren und Filtern von Ereignissen, sobald sie eintreffen. Maßnahmen können basierend auf ausgeklügelten Kriterien wie Anomalieerkennungsmodellen ergriffen werden. Gängige Anwendungsfälle wie NRT-Betrugserkennung und -empfehlung erfordern oft niedrige Latenzen von unter 100 Millisekunden.
- Partitionierte NRT-Ereignisverarbeitung: Ähnlich wie die NRT-Ereignisverarbeitung, aber Vorteile aus der Partitionierung der Daten – wie das Speichern relevanterer externer Informationen im Speicher. Dieses Muster erfordert außerdem Verarbeitungslatenzen von weniger als 100 Millisekunden.
- Komplexe Topologie für Aggregationen oder ML: Der heilige Gral der Stream-Verarbeitung:erhält Echtzeit-Antworten aus Daten mit einem komplexen und flexiblen Satz von Operationen. Da die Ergebnisse häufig von Fensterberechnungen abhängen und mehr aktive Daten erfordern, verlagert sich der Fokus hier von extrem niedriger Latenz auf Funktionalität und Genauigkeit.
In den folgenden Abschnitten gehen wir auf empfohlene Methoden ein, um solche Muster auf getestete, bewährte und wartbare Weise zu implementieren.
Streamingaufnahme
Traditionell war Flume das empfohlene System für die Streaming-Aufnahme. Seine große Bibliothek von Quellen und Senken deckt alle Grundlagen dessen ab, was zu konsumieren und wo zu schreiben ist. (Einzelheiten zum Konfigurieren und Verwalten von Flume finden Sie unter Flume verwenden , das O’Reilly Media-Buch von Cloudera Software Engineer/Flume PMC-Mitglied Hari Shreedharan, ist eine großartige Ressource.)
Innerhalb des letzten Jahres ist Kafka auch wegen leistungsstarker Funktionen wie Wiedergabe und Replikation populär geworden. Aufgrund der Überschneidung zwischen den Zielen von Flume und Kafka ist ihre Beziehung oft verwirrend. Wie passen sie zusammen? Die Antwort ist einfach:Kafka ist eine Pipe, die der Channel-Abstraktion von Flume ähnelt, obwohl sie aufgrund ihrer Unterstützung der oben genannten Funktionen eine bessere Pipe ist. Ein gängiger Ansatz ist die Verwendung von Flume für Quelle und Senke und Kafka für die Verbindung zwischen ihnen.
Das folgende Diagramm veranschaulicht, wie Kafka als Upstream-Datenquelle für Flume, als Downstream-Ziel von Flume oder als Flume-Kanal dienen kann.
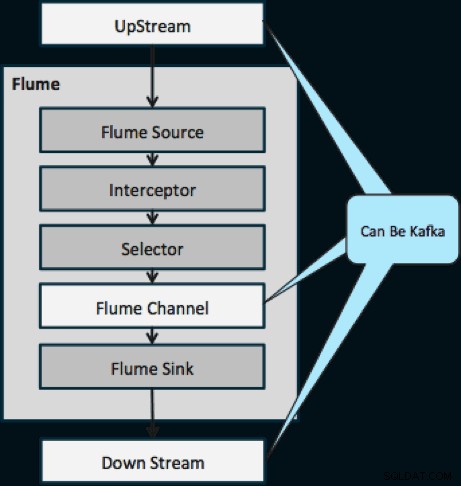
Das unten abgebildete Design ist massiv skalierbar, kampferprobt, zentral über Cloudera Manager überwacht, fehlertolerant und unterstützt die Wiedergabe.
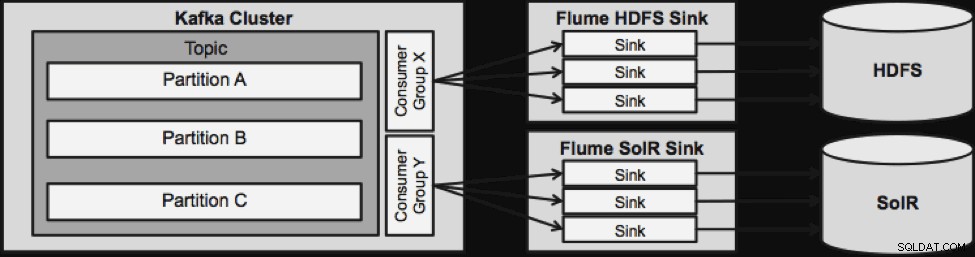
Eine Sache, die zu beachten ist, bevor wir zur nächsten Streaming-Architektur übergehen, ist, wie dieses Design mit Fehlern elegant umgeht. Die Flume Sinks stammen von einer Kafka Consumer Group. Die Verbrauchergruppe verfolgt den Versatz des Themas mit Hilfe von Apache ZooKeeper. Wenn eine Flume Sink verloren geht, verteilt der Kafka-Verbraucher die Last auf die verbleibenden Senken. Wenn der Flume Sink wieder auftaucht, wird die Verbrauchergruppe erneut umverteilen.
NRT-Ereignisverarbeitung mit externem Kontext
Um es noch einmal zu wiederholen:Ein häufiger Anwendungsfall für dieses Muster besteht darin, eingehende Ereignisse zu betrachten und sofortige Entscheidungen zu treffen, entweder um die Daten zu transformieren oder eine Art externe Aktion zu ergreifen. Die Entscheidungslogik hängt oft von externen Profilen oder Metadaten ab. Eine einfache und skalierbare Möglichkeit, diesen Ansatz zu implementieren, besteht darin, Ihrer Kafka/Flume-Architektur einen Source- oder Sink-Flume-Interceptor hinzuzufügen. Mit bescheidener Abstimmung ist es nicht schwierig, Latenzen in den niedrigen Millisekunden zu erreichen.
Flume Interceptors nehmen Ereignisse oder Batches von Ereignissen und ermöglichen es dem Benutzercode, diese zu ändern oder darauf basierende Aktionen durchzuführen. Der Benutzercode kann mit dem lokalen Speicher oder einem externen Speichersystem wie HBase interagieren, um Profilinformationen zu erhalten, die für Entscheidungen benötigt werden. HBase kann uns unsere Informationen normalerweise in etwa 4 bis 25 Millisekunden liefern, je nach Netzwerk, Schemadesign und Konfiguration. Sie können HBase auch so einrichten, dass es nie ausfällt oder unterbrochen wird, selbst im Falle eines Ausfalls.
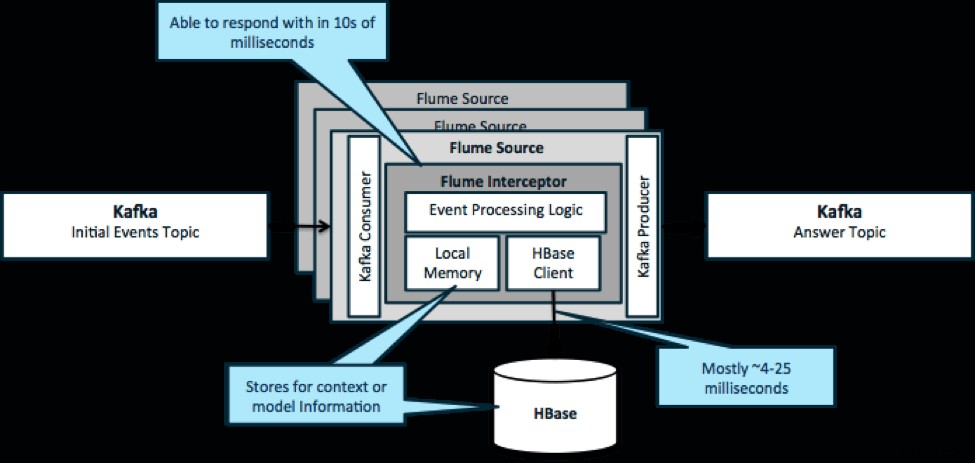
Die Implementierung erfordert fast keine Codierung über die anwendungsspezifische Logik im Interceptor hinaus. Cloudera Manager bietet eine intuitive Benutzeroberfläche zum Bereitstellen dieser Logik über Pakete sowie zum Verbinden, Konfigurieren und Überwachen der Dienste.
NRT-partitionierte Ereignisverarbeitung mit externem Kontext
In der unten abgebildeten Architektur (nicht partitionierte Lösung) müssten Sie HBase häufig aufrufen, da externer Kontext, der für bestimmte Ereignisse relevant ist, nicht in den lokalen Speicher der Flume-Abfangjäger passt.
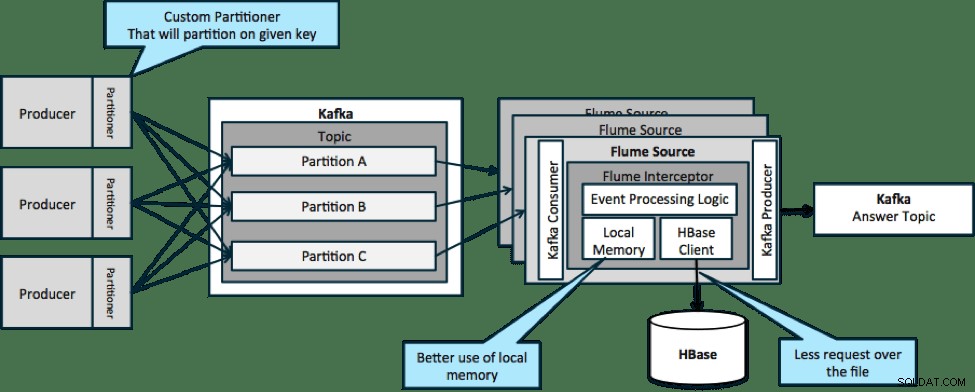
Wenn Sie jedoch einen Schlüssel zum Partitionieren Ihrer Daten definieren, können Sie eingehende Daten mit der für sie relevanten Teilmenge der Kontextdaten abgleichen. Wenn Sie die Daten 10-mal partitionieren, müssen Sie nur 1/10 der Profile im Speicher halten. HBase ist schnell, aber der lokale Speicher ist schneller. Mit Kafka können Sie einen benutzerdefinierten Partitionierer definieren, der zum Aufteilen Ihrer Daten verwendet wird.
Beachten Sie, dass Flume hier nicht unbedingt erforderlich ist; Die Wurzellösung hier ist nur ein Kafka-Konsument. Sie könnten also nur einen Verbraucher in YARN oder eine Nur-Karten-MapReduce-Anwendung verwenden.
Komplexe Topologie für Aggregationen oder ML
Bis zu diesem Punkt haben wir Vorgänge auf Ereignisebene untersucht. Manchmal benötigen Sie jedoch komplexere Operationen wie Zählungen, Mittelwerte, Sessionisierung oder Modellerstellung für maschinelles Lernen, die mit Datenstapeln arbeiten. In diesem Fall ist Spark Streaming aus mehreren Gründen das ideale Werkzeug:
- Es ist im Vergleich zu anderen Tools einfach zu entwickeln. Die reichhaltigen und prägnanten APIs von Spark erleichtern den Aufbau komplexer Topologien.
- Ähnlicher Code für Streaming und Stapelverarbeitung. Mit wenigen Änderungen kann der Code für kleine Chargen in Echtzeit für riesige Chargen offline verwendet werden. Dieser Ansatz reduziert nicht nur die Codegröße, sondern auch die für Tests und Integration benötigte Zeit.
- Es gibt eine Engine, die man kennen sollte. Es entstehen Kosten für die Schulung des Personals über die Macken und Interna von Distributed-Processing-Engines. Die Standardisierung auf Spark konsolidiert diese Kosten für Streaming und Batch.
- Mikro-Batching hilft Ihnen, zuverlässig zu skalieren. Die Bestätigung auf Batch-Ebene ermöglicht einen höheren Durchsatz und ermöglicht Lösungen ohne die Angst vor Doppelsendungen. Micro-Batching hilft auch beim Senden von Änderungen an HDFS oder HBase in Bezug auf die Leistung im großen Maßstab.
- Integration des Hadoop-Ökosystems ist integriert. Spark verfügt über eine umfassende Integration mit HDFS, HBase und Kafka.
- Kein Risiko von Datenverlust. Dank WAL und Kafka vermeidet Spark Streaming Datenverlust im Fehlerfall.
- Es ist einfach zu debuggen und auszuführen. Sie können Ihren Code Spark Streaming in einer lokalen IDE ohne Cluster debuggen und schrittweise durchlaufen. Außerdem sieht der Code wie normaler funktionaler Programmiercode aus, sodass ein Java- oder Scala-Entwickler nicht viel Zeit braucht, um den Sprung zu schaffen. (Python wird ebenfalls unterstützt.)
- Streaming ist nativ zustandsbehaftet. In Spark Streaming ist der Zustand ein erstklassiger Bürger, was bedeutet, dass es einfach ist, zustandsbehaftete Streaming-Anwendungen zu schreiben, die gegen Knotenausfälle widerstandsfähig sind.
- Als De-facto-Standard erhält Spark langfristige Investitionen aus dem gesamten Ökosystem.
Zum Zeitpunkt des Verfassens dieses Artikels gab es in den letzten 30 Tagen ungefähr 700 Commits für Spark als Ganzes – im Vergleich zu anderen Streaming-Frameworks wie Storm mit 15 Commits während der gleichen Zeit. - Sie haben Zugriff auf ML-Bibliotheken.
Die MLlib von Spark wird immer beliebter und ihr Funktionsumfang wird weiter zunehmen. - Sie können bei Bedarf SQL verwenden.
Mit Spark SQL können Sie Ihrer Streaming-Anwendung SQL-Logik hinzufügen, um die Codekomplexität zu reduzieren.
Schlussfolgerung
Streaming hat viel Kraft und mehrere mögliche Muster, aber wie Sie in diesem Beitrag gelernt haben, können Sie mit minimalem Programmieraufwand wirklich leistungsstarke Dinge tun, wenn Sie wissen, welches Muster am besten zu Ihrem Anwendungsfall passt.
Ted Malaska ist Lösungsarchitekt bei Cloudera, Mitwirkender bei Spark, Flume und HBase und Mitautor des O'Reilly-Buchs Hadoop-Anwendungsarchitektur.



