FILESTREAM wurde 2008 von Microsoft eingeführt. Der Zweck bestand darin, unstrukturierte Dateien effektiver zu speichern und zu verwalten. Vor der Einführung von FILESTREAM wurden die folgenden Ansätze verwendet, um die Daten im SQL-Server zu speichern:
- Unstrukturierte Dateien können in der VARBINARY- oder IMAGE-Spalte einer SQL Server-Tabelle gespeichert werden. Dieser Ansatz ist effektiv, um die Transaktionskonsistenz aufrechtzuerhalten und die Komplexität der Dateiverwaltung zu reduzieren, aber wenn die Client-Anwendung Daten aus der SQL-Tabelle liest, verwendet sie SQL-Speicher, was zu einer schlechten Leistung führt.
- Anstatt die gesamte Datei in der SQL-Tabelle zu speichern, speichern Sie den physischen Speicherort der unstrukturierten Datei in der SQL-Tabelle. Dieser Ansatz führt zu einer enormen Leistungssteigerung, stellt jedoch nicht die Transaktionskonsistenz sicher, außerdem war die Dateiverwaltung auch schwierig.
Die FILESTREAM-Funktion ist sehr effektiv, da sie das Speichern von BLOB-Dateien im NT-Dateisystem ermöglicht und die Transaktionskonsistenz aufrechterhält. Wenn eine Clientanwendung Daten aus dem FILESTREAM-Container liest, verwendet sie anstelle des Speichers des SQL Server-Puffers den T-Systemcache, wodurch die Leistung verbessert wird.
FILESTREAM ist kein Datentyp. Es ist ein Attribut, das der Spalte VARBINARY(MAX) zugewiesen werden kann. Wenn die VARBINARY(MAX)-Spalte dem FILESTREAM-Attribut zugewiesen wird, wird sie als FILESTREAM-Spalte bezeichnet. In der FILESTREAM-Spalte gespeicherte Daten werden im NT-System als Plattendatei gespeichert, und der Zeiger der Datei wird in der Tabelle gespeichert. Die Spalte VARBINARY(max) mit dem zugewiesenen FILESTREAM-Attribut hat keine Beschränkung auf 2 GB in der Tabelle. Daher können wir auch große Dateien speichern.
In diesem Artikel werde ich Folgendes demonstrieren:
- So aktivieren Sie die FILESTREAM-Funktion.
- Erstellen und Konfigurieren von FILESTREAM-Dateigruppen und FILESTREAM-Datencontainern.
- So speichern und greifen Sie auf Daten aus den FILESTREAM-fähigen Tabellen zu.
Demo:
In dieser Demo verwende ich:
- Datenbankserver :SQL-Server 2017
- Software :SQL Server Management Studio
- Datenbank :FileStream_Demo
Konfigurieren Sie den FILESTREAM-Zugriff in der SQL Server-Datenbank
Um FileStream in SQL Server zu konfigurieren, nehmen Sie die folgenden Änderungen an SQL Server vor.
- Aktivieren Sie die FILESTREAM-Funktion im SQL Server-Konfigurations-Manager.
- Aktivieren Sie die FILESTREAM-Zugriffsebene auf der SQL Server-Instanz.
- Erstellen Sie eine FILESTREAM-Dateigruppe und einen FileStream-Container zum Speichern von BLOB-Daten.
FILESTREAM-Funktion aktivieren
Um FileStream für eine beliebige Datenbank zu aktivieren, aktivieren Sie zunächst die FileStream-Funktion auf der SQL Server-Instanz. Öffnen Sie dazu den SQL Server-Konfigurationsmanager, klicken Sie mit der rechten Maustaste auf die SQL-Instanz und wählen Sie Eigenschaften aus , wie im folgenden Bild gezeigt:
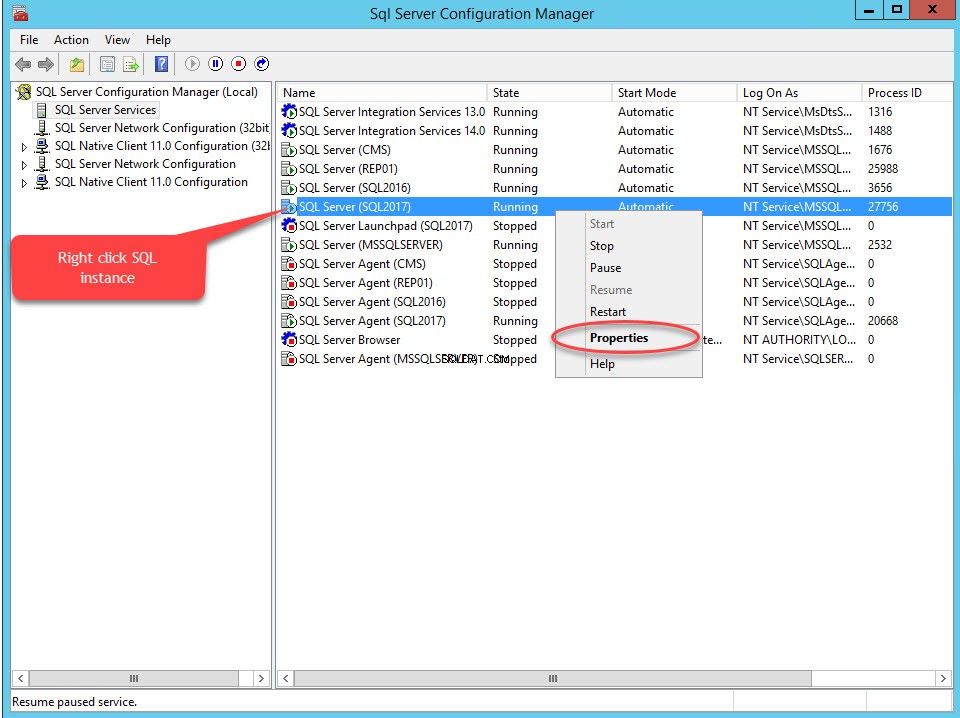
Ein Dialogfeld zum Konfigurieren der Servereigenschaften wird geöffnet. Wechseln Sie zum FILESTREAM Tab. Wählen Sie FILESTREAM für T-SQL-Zugriff aktivieren aus . Wählen Sie FILESTREAM für E/A-Zugriff aktivieren aus und wählen Sie dann Remote-Client-Zugriff auf FILESTREAM-Daten zulassen . Im Windows-Freigabenamen Geben Sie im Textfeld einen Namen für das Verzeichnis an, in dem die Dateien gespeichert werden sollen. Siehe folgendes Bild:
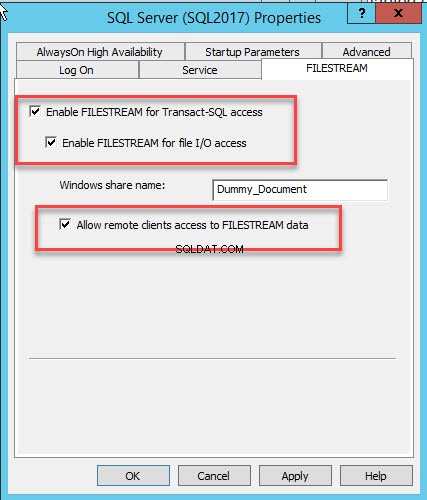
Klicken Sie auf OK und starten Sie den SQL-Dienst neu.
Aktivieren Sie die FILESTREAM-Zugriffsebene auf der SQL Server-Instanz
Sobald die FILESTREAM-Funktion aktiviert ist, ändern Sie die FILESTREAM-Zugriffsebene. Um die FileStream-Zugriffsebene zu ändern, führen Sie die folgende Abfrage aus:
EXEC sp_configure filestream_access_level, 2 RECONFIGURE
In der obigen Abfrage sind die folgenden Parameter gültige Werte:
0 bedeutet die FILESTREAM-Unterstützung für die SQL-Instanz ist deaktiviert.
1 bedeutet die FILESTREAM-Unterstützung für T-SQL ist aktiviert.
2 bedeutet die FILESTREAM-Unterstützung für T-SQL- und Win32-Streamingzugriff ist aktiviert.
Sie können die FILESTREAM-Zugriffsebene mit SQL Server Management Studio ändern. Klicken Sie dazu mit der rechten Maustaste auf eine SQL Server-Verbindung>> wählen Sie Eigenschaften>> Wählen Sie im Dialogfeld „Servereigenschaften“ FileStream-Zugriffsebene aus aus dem Dropdown-Feld und wählen Sie Vollzugriff aktiviert aus , wie im folgenden Bild gezeigt:
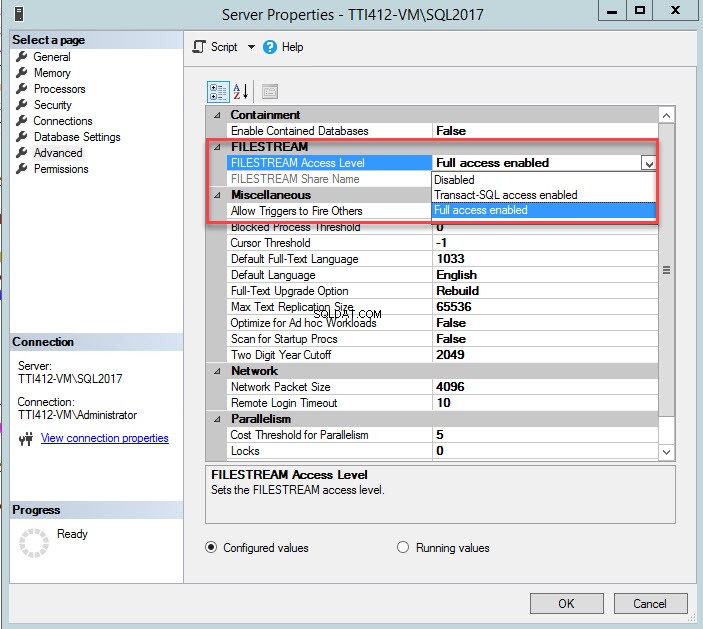
Sobald der Parameter geändert wurde, starten Sie die SQL Server-Dienste neu.
FILESTREAM-Dateigruppe und Datendateien hinzufügen
Sobald FILESTREAM aktiviert ist, fügen Sie die FILESTREAM-Dateigruppe und den FILESTREAM-Container hinzu.
Klicken Sie dazu mit der rechten Maustaste auf die FileStream-Demo Datenbank>> Eigenschaften auswählen>> In einem linken Bereich der Datenbankeigenschaften Wählen Sie im Dialogfeld Dateigruppen aus>> Klicken Sie im FILESTREAM-Raster auf Dateigruppe hinzufügen Schaltfläche>> Benennen Sie die Dateigruppe als Dummy-Dokument . Siehe folgendes Bild:
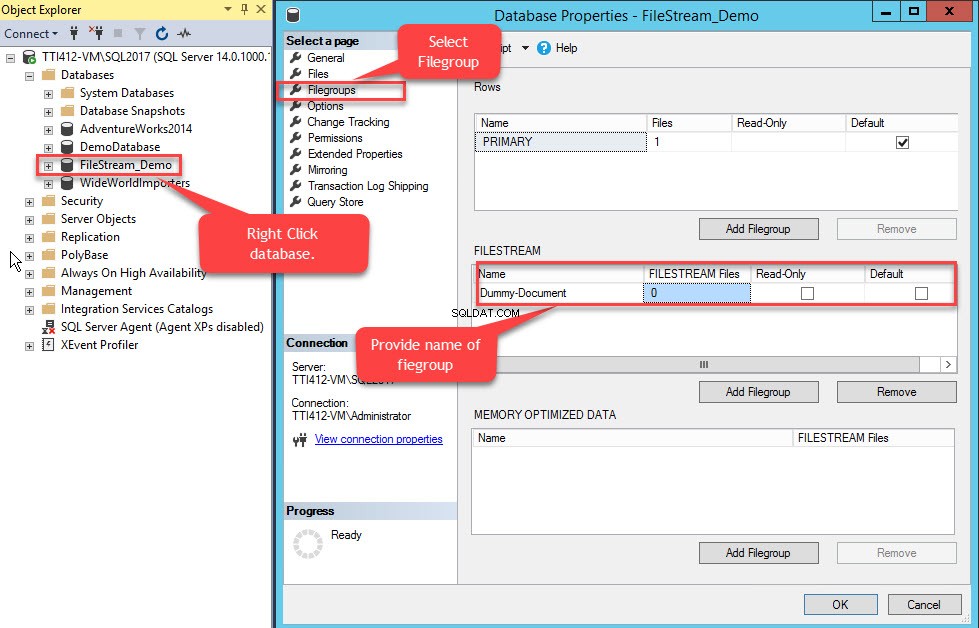
Nachdem die Dateigruppe erstellt wurde, wählen Sie im Dialogfeld „Datenbankeigenschaften“ Dateien aus und klicken Sie auf die Schaltfläche Hinzufügen. Das Raster Datenbankdateien aktiviert. Geben Sie in der Spalte Logischer Name den Namen an – Dummy-Document . Wählen Sie FILESTREAM-Daten als Dateityp aus Dropdown-Feld. Wählen Sie Dummy-Dokument aus in der Dateigruppe Säule. Im Pfad Geben Sie in der Spalte das Verzeichnis an, in dem die Dateien gespeichert werden (E:\Dummy-Documents). Siehe folgendes Bild:
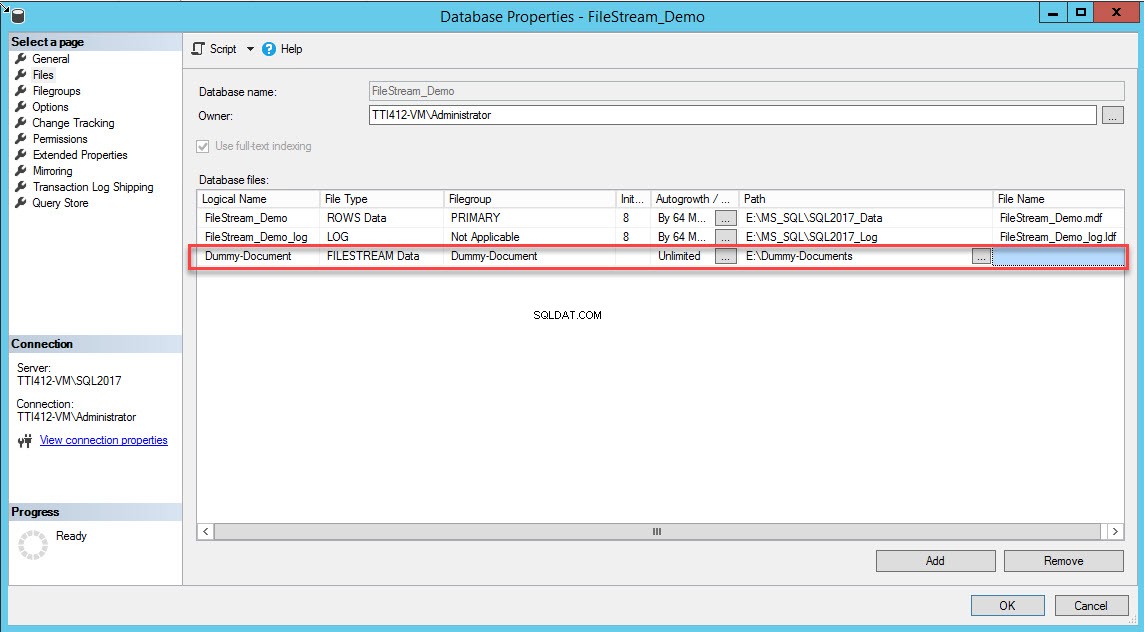
Alternativ können Sie die FILESTREAM-Dateigruppe und Container hinzufügen, indem Sie die folgende T-SQL-Abfrage ausführen:
USE [master] GO ALTER DATABASE [FileStream_Demo] ADD FILEGROUP [Dummy-Documents] CONTAINS FILESTREAM GO ALTER DATABASE [FileStream_Demo] ADD FILE ( NAME = N'Dummy-Documents', FILENAME = N'E:\Dummy-Documents' ) TO FILEGROUP [Dummy-Documents] GO
Um zu überprüfen, ob der FileStream-Container erstellt wurde, öffnen Sie den Windows Explorer und navigieren Sie zum Verzeichnis „E:\Dummy-Document“.
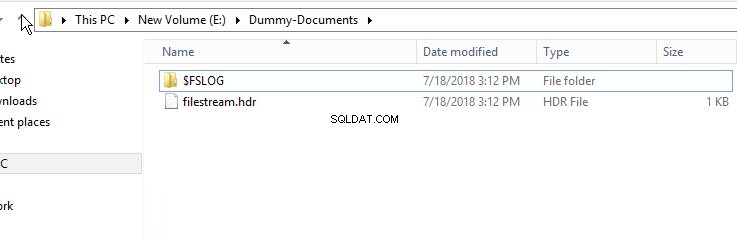
Wie im obigen Bild gezeigt, das $FSLOG-Verzeichnis und die filestream.hdr Datei erstellt wurden. $FSLOG ist wie SQL Server T-Log und filestream.hdr enthält Metadaten von FILESTREAM. Stellen Sie sicher, dass Sie diese Dateien nicht ändern oder bearbeiten.
Dateien in SQL-Tabelle speichern
In dieser Demo erstellen wir eine Tabelle, um verschiedene Dateien vom Computer zu speichern. Die Tabelle hat folgende Spalten:
- Das „RootDirectory ”-Spalte zum Speichern des Dateispeicherorts.
- Der „Dateiname ”-Spalte, um den Namen der Datei zu speichern.
- Das „FileAttribute ”-Spalte zum Speichern des Dateiattributs (Raw/Directory.
- Das „FileCreateDate ”-Spalte zum Speichern der Dateierstellungszeit.
- Die „Dateigröße ”-Spalte, um die Größe der Datei zu speichern.
- Die Datei „FileStreamCol ”-Spalte, um den Inhalt der Datei im Binärformat zu speichern.
Erstellen Sie eine SQL-Tabelle mit einer FILESTREAM-Spalte
Erstellen Sie nach der Konfiguration von FILESTREAM eine SQL-Tabelle mit den FILESTREAM-Spalten, um verschiedene Dateien in der SQL-Servertabelle zu speichern. Wie ich oben erwähnt habe, ist FILESTREAM kein Datentyp. Es ist ein Attribut, das wir der Spalte varbinary(max) in der FILESTREAM-fähigen Tabelle hinzufügen. Stellen Sie beim Erstellen einer FILESTREAM-fähigen Tabelle sicher, dass Sie einen UNIQUEIDENTIFIER hinzufügen Spalte mit ROWGUIDCOL und EINZIGARTIG Attribute.
Führen Sie das folgende Skript aus, um eine FILESTREAM-fähige Tabelle zu erstellen:
Use [FileStream_Demo]
go
Create Table [DummyDocuments]
(
ID uniqueidentifier ROWGUIDCOL unique NOT NULL,
RootDirectory varchar(max),
FileName varchar(max),
FileAttribute varchar(150),
FileCreateDate datetime,
FileSize numeric(10,5),
FileStreamCol varbinary (max) FILESTREAM
) Daten in Tabelle einfügen
Ich habe die WorldWide_Importors.xls Dokument, das auf dem Computer am Speicherort „E:\Documents“ gespeichert ist. Verwenden Sie OPENROWSET(Bulk) um seinen Inhalt von der Festplatte in VARBINARY(max) zu laden Variable. Speichern Sie dann die Variable in FileStreamCol (VARBINARY(max))-Spalte des DummyDocumen t-Tabelle. Führen Sie dazu das folgende Skript aus:
Use [FileStream-Demo]
Go
DECLARE @Document AS VARBINARY(MAX)
-- Load the image data
SELECT @Document = CAST(bulkcolumn AS VARBINARY(MAX))
FROM OPENROWSET(
BULK
'E:\Documents\WorldWide_Importors.xls',
SINGLE_BLOB ) AS Doc
-- Insert the data to the table
INSERT INTO [DummyDocuments] (ID, RootDirectory,FileName, FileAttribute, FileCreateDate,FileSize,FileStreamCol)
SELECT NEWID(), 'E:\Documents','WorldWide_Importors.xls','Raw',getdate(),10, @Document Zugriff auf FILESTREAM-Daten
Auf die FILESTREAM-Daten kann über T-SQL und Managed API zugegriffen werden. Wenn auf die FILESTREAM-Spalte mit einer T-SQL-Abfrage zugegriffen wird, verwendet sie den SQL-Speicher, um den Inhalt der Datendatei zu lesen und die Daten an die Clientanwendung zu senden. Wenn auf die FILESTREAM-Spalte über die verwaltete Win32-API zugegriffen wird, wird kein SQL Server-Speicher verwendet. Es nutzt die Streaming-Fähigkeit des NT-Dateisystems, was zu Leistungsvorteilen führt.
Zugriff auf FILESTREAM-Daten mit T-SQL
Wie ich am Anfang des Artikels erwähnt habe, ist FILESTREAM ein Attribut, das einer Tabellenspalte mit dem Datentyp varbinary(max) zugewiesen ist, daher kann darauf wie auf jede andere Spalte der Tabelle zugegriffen werden. Um FILESTREAM-Daten zusammen mit allen Informationen der Tabelle abzurufen, führen Sie die folgende Abfrage aus
Use [FileStream-Demo] go select RootDirectory,FileName,FileAttribute,FileCreateDate,FileSize,FileStreamCol from DummyDocuments
Unten ist die Ausgabe der Abfrage:

Wie im obigen Bild gezeigt, wurde das Dokument „WorldWide_Importors.xls“ in ein BLOB konvertiert, das in der Spalte „FileStreamCol“ gespeichert wird.
Zugriff auf FILESTREAM-Daten mit verwalteter API
Der Zugriff auf FILESTREAM über die Win32-API bietet zwar Leistung und andere Vorteile, aber es hat andere und schwierige Syntaxen als T-SQL-Syntaxen, was den Zugriff auf Daten erschwert. Um die Datei im FILESTREAM-Datenspeicher zu finden, müssen wir zunächst den logischen Pfad identifizieren, um die Datei im FILESTREAM-Datenspeicher eindeutig zu identifizieren. Wir können dies tun, indem wir Pathname() verwenden Methode der FILESTREAM-Spalte. Es wird zwischen Groß- und Kleinschreibung unterschieden.
Nach dem Abrufen des Dateipfads müssen wir für den Zugriff den Transaktionskontext abrufen, indem wir Begin Transaction verwenden Methode. Sobald der Transaktionskontext abgerufen wurde, können wir mit SQLFileStream darauf zugreifen Klasse.
Der folgende Code erhält den lokalen Pfad zu WorldWide_Importors.xls Dokument im FILESTREAM-Datenspeicher.
SELECT
RootDirectory,
FileName,
FileAttribute,
FileCreateDate,
FileSize,
FileStreamCol.PathName() AS FilePath
FROM DummyDocuments Abfrageausgabe:

Dateien aus dem FILESTREAM-Container löschen
Das Löschen von Dateien ist unkompliziert. Sie müssen die Löschabfrage ausführen, um die Datei aus der FILESTREAM-fähigen SQL-Tabelle zu entfernen. Auch wenn der Datensatz aus den Tabellen gelöscht wurde, ist die Datei physisch im FILSTREAM-Datenspeicher verfügbar. Es wird vom Garbage Collector gelöscht. Der Garbage Collector-Prozess wird ausgeführt, wenn das Checkpoint-Ereignis eintritt. Indem Sie einen expliziten Prüfpunkt angeben, können Sie ihn sofort nach dem Löschen aus der Tabelle löschen.
Abfrage zum Löschen von Dateien aus der SQL-Tabelle:
Use [FileStream_Demo] go delete from DummyDocuments where ID='0D640ABC-8CF1-41E0-9FA8-28171047129F'
Zusammenfassung
In diesem Artikel habe ich behandelt:
- Einführung von FILESTREAM und was sind die Vorteile.
- So aktivieren Sie die FILESTREAM-Funktion auf einer SQL Server-Instanz.
- Erstellen und konfigurieren Sie den FILESTREAM-Datenspeicher und Dateigruppen.
- Führen Sie das Einfügen und Löschen von Dateien aus dem FILESTREAM-Datenspeicher durch.
In zukünftigen Artikeln werde ich erklären:
- So sichern und wiederherstellen Sie eine FILESTREAM-fähige Datenbank.
- Einrichten von Replikation und Tabellenportionierung in FILESTREAM-Tabellen.
Bleiben Sie dran!