Sie wissen wahrscheinlich, wie man Datensätze mit einzelnen oder mehreren VALUES-Klauseln in eine Tabelle einfügt. Sie wissen auch, wie Masseneinfügungen mit SQL INSERT INTO SELECT durchgeführt werden. Aber Sie haben trotzdem auf den Artikel geklickt. Geht es um den Umgang mit Duplikaten?
Viele Artikel behandeln SQL INSERT INTO SELECT. Google oder Bing und wähle die Überschrift, die dir am besten gefällt – das reicht. Ich werde auch keine grundlegenden Beispiele dafür behandeln, wie es gemacht wird. Stattdessen sehen Sie Beispiele dafür, wie Sie es verwenden UND gleichzeitig mit Duplikaten umgehen können . So können Sie diese vertraute Nachricht aus Ihren INSERT-Bemühungen machen:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Aber der Reihe nach.

[sendpulse-form id=”12989″]
Testdaten für SQL INSERT INTO SELECT-Codebeispiele vorbereiten
Diesmal denke ich an Pasta. Also werde ich Daten über Nudelgerichte verwenden. Ich habe in Wikipedia eine gute Liste von Nudelgerichten gefunden, die wir verwenden und in Power BI mithilfe einer Webdatenquelle extrahieren können. Ich habe die Wikipedia-URL eingegeben. Dann habe ich die 2-Tabellen-Daten von der Seite angegeben. Etwas aufgeräumt und Daten nach Excel kopiert.
Jetzt haben wir die Daten – Sie können sie hier herunterladen. Es ist roh, weil wir zwei relationale Tabellen daraus machen werden. Die Verwendung von INSERT INTO SELECT hilft uns bei dieser Aufgabe,
Importieren Sie die Daten in SQL Server
Sie können entweder SQL Server Management Studio oder dbForge Studio für SQL Server verwenden, um 2 Blätter in die Excel-Datei zu importieren.
Erstellen Sie eine leere Datenbank, bevor Sie die Daten importieren. Ich habe die Tische dbo.ItalianPastaDishes genannt und dbo.NonItalianPastaDishes .
Erstellen Sie 2 weitere Tabellen
Lassen Sie uns die beiden Ausgabetabellen mit dem Befehl SQL Server ALTER TABLE.
definierenCREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Hinweis:Es gibt eindeutige Indizes, die für zwei Tabellen erstellt wurden. Dadurch wird verhindert, dass wir später doppelte Datensätze einfügen. Einschränkungen werden diese Reise etwas schwieriger, aber aufregender machen.
Jetzt, da wir bereit sind, tauchen wir ein.
5 einfache Möglichkeiten zum Umgang mit Duplikaten mit SQL INSERT INTO SELECT
Der einfachste Weg, mit Duplikaten umzugehen, ist das Entfernen von Eindeutigkeitsbeschränkungen, richtig?
Falsch!
Da die eindeutigen Einschränkungen wegfallen, ist es leicht, einen Fehler zu machen und die Daten zweimal oder öfter einzufügen. Das wollen wir nicht. Und was wäre, wenn wir eine Benutzeroberfläche mit einer Dropdown-Liste zur Auswahl der Herkunft des Nudelgerichts hätten? Werden die Duplikate Ihre Benutzer glücklich machen?
Daher ist das Entfernen der eindeutigen Einschränkungen keine der fünf Möglichkeiten, doppelte Datensätze in SQL zu behandeln oder zu löschen. Wir haben bessere Optionen.
1. Verwenden von INSERT INTO SELECT DISTINCT
Die erste Option zum Identifizieren von SQL-Datensätzen in SQL ist die Verwendung von DISTINCT in Ihrem SELECT. Um den Fall zu untersuchen, füllen wir den Ursprung Tisch. Aber zuerst verwenden wir die falsche Methode:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
Dies löst die folgenden doppelten Fehler aus:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
Es gibt ein Problem, wenn Sie versuchen, doppelte Zeilen in SQL auszuwählen. Um die zuvor vorhandene SQL-Prüfung auf Duplikate zu starten, habe ich den SELECT-Teil der INSERT INTO SELECT-Anweisung ausgeführt:
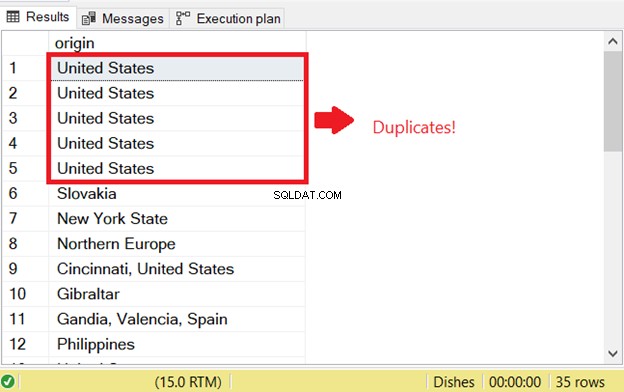
Das ist der Grund für den ersten SQL-Duplikatfehler. Um dies zu verhindern, fügen Sie das Schlüsselwort DISTINCT hinzu, um die Ergebnismenge eindeutig zu machen. Hier ist der richtige Code:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Es fügt die Datensätze erfolgreich ein. Und wir sind mit dem Ursprung fertig Tabelle.
Die Verwendung von DISTINCT macht eindeutige Datensätze aus der SELECT-Anweisung. Es garantiert jedoch nicht, dass in der Zieltabelle keine Duplikate vorhanden sind. Es ist gut, wenn Sie sicher sind, dass die Zieltabelle nicht die Werte enthält, die Sie einfügen möchten.
Führen Sie diese Anweisungen also nicht mehr als einmal aus.
2. Verwendung von WHERE NOT IN
Als nächstes füllen wir die PastaDishes Tisch. Dazu müssen wir zuerst Datensätze aus den ItalianPastaDishes einfügen Tisch. Hier ist der Code:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Seit ItalianPastaDishes Rohdaten enthält, müssen wir dem Origin beitreten Text anstelle der OriginID . Versuchen Sie nun, denselben Code zweimal auszuführen. Bei der zweiten Ausführung werden keine Datensätze eingefügt. Dies geschieht aufgrund der WHERE-Klausel mit dem NOT IN-Operator. Es filtert Datensätze heraus, die bereits in der Zieltabelle vorhanden sind.
Als nächstes müssen wir die PastaDishes füllen Tisch aus den NonItalianPastaDishes Tisch. Da wir erst beim zweiten Punkt dieses Posts sind, werden wir nicht alles einfügen.
Wir haben Nudelgerichte aus den USA und den Philippinen ausgesucht. Hier geht's:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
Aus dieser Anweisung wurden 9 Datensätze eingefügt – siehe Abbildung 2 unten:
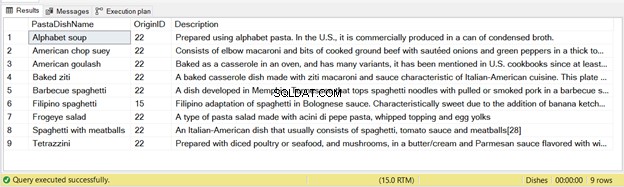
Auch hier gilt:Wenn Sie den obigen Code zweimal ausführen, werden beim zweiten Durchlauf keine Datensätze eingefügt.
3. Verwendung von WHERE NOT EXISTS
Eine andere Möglichkeit, Duplikate in SQL zu finden, ist die Verwendung von NOT EXISTS in der WHERE-Klausel. Versuchen wir es mit denselben Bedingungen aus dem vorherigen Abschnitt:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
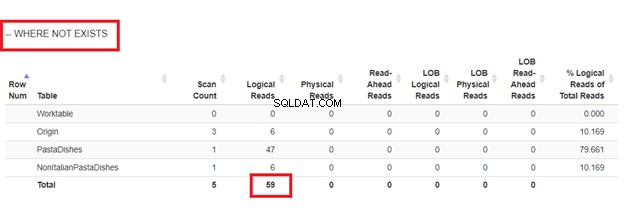
Der obige Code fügt dieselben 9 Datensätze ein, die Sie in Abbildung 2 gesehen haben. Dadurch wird vermieden, dass dieselben Datensätze mehr als einmal eingefügt werden.
4. Verwendung von IF NOT EXISTS
Manchmal müssen Sie möglicherweise eine Tabelle in der Datenbank bereitstellen und prüfen, ob bereits eine Tabelle mit demselben Namen vorhanden ist, um Duplikate zu vermeiden. In diesem Fall kann der SQL-Befehl DROP TABLE IF EXISTS eine große Hilfe sein. Eine weitere Möglichkeit, um sicherzustellen, dass Sie keine Duplikate einfügen, ist die Verwendung von IF NOT EXISTS. Wieder verwenden wir dieselben Bedingungen aus dem vorherigen Abschnitt:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
Der obige Code prüft zunächst, ob 9 Datensätze vorhanden sind. Wenn es true zurückgibt, wird INSERT fortgesetzt.
5. Verwendung von COUNT(*) =0
Schließlich kann die Verwendung von COUNT(*) in der WHERE-Klausel auch sicherstellen, dass Sie keine Duplikate einfügen. Hier ist ein Beispiel:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
Um Duplikate zu vermeiden, sollte die Anzahl der von der obigen Unterabfrage zurückgegebenen Datensätze Null sein.
Hinweis :Mit dem Query Builder-Feature von dbForge Studio for SQL Server können Sie jede Abfrage visuell in einem Diagramm entwerfen.
Vergleich verschiedener Methoden zur Behandlung von Duplikaten mit SQL INSERT INTO SELECT
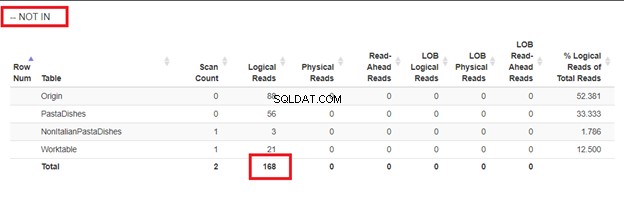
4 Abschnitte verwendeten dieselbe Ausgabe, aber unterschiedliche Ansätze zum Einfügen von Massendatensätzen mit einer SELECT-Anweisung. Sie fragen sich vielleicht, ob der Unterschied nur an der Oberfläche liegt. Wir können ihre logischen Lesevorgänge von STATISTICS IO überprüfen, um zu sehen, wie unterschiedlich sie sind.
Verwendung von WHERE NOT IN:
Verwendung von NOT EXISTS:
Verwendung von IF NOT EXISTS:
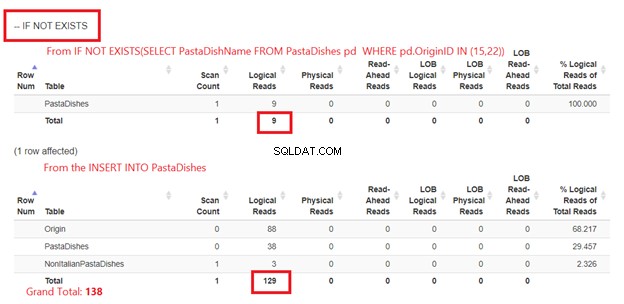
Bild 5 ist etwas anders. 2 logische Lesevorgänge erscheinen für die PastaDishes Tisch. Der erste stammt von IF NOT EXISTS(SELECT PastaDishName von PastaDishes WHERE OriginID EIN (15,22)). Der zweite stammt aus der INSERT-Anweisung.
Schließlich mit COUNT(*) =0
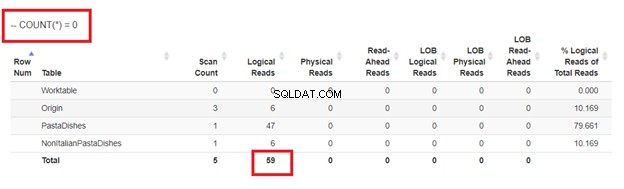
Aus den logischen Lesevorgängen von 4 Ansätzen, die wir hatten, ist die beste Wahl WHERE NOT EXISTS oder COUNT(*) =0. Wenn wir ihre Ausführungspläne untersuchen, sehen wir, dass sie denselben QueryHashPlan haben . Sie haben also ähnliche Pläne. Am wenigsten effizient ist die Verwendung von NOT IN.
Bedeutet das, dass WHERE NOT EXISTS immer besser ist als NOT IN? Überhaupt nicht.
Überprüfen Sie immer die logischen Lesevorgänge und den Ausführungsplan Ihrer Abfragen!
Aber bevor wir zum Schluss kommen, müssen wir die anstehende Aufgabe erledigen. Dann fügen wir die restlichen Datensätze ein und prüfen die Ergebnisse.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Das Stöbern in der Liste mit 179 Nudelgerichten von Asien bis Europa macht hungrig. Sehen Sie sich unten einen Teil der Liste aus Italien, Russland und mehr an:

Schlussfolgerung
Das Vermeiden von Duplikaten in SQL INSERT INTO SELECT ist schließlich nicht so schwer. Sie haben Operatoren und Funktionen zur Hand, um Sie auf diese Ebene zu bringen. Es ist auch eine gute Angewohnheit, den Ausführungsplan und die logischen Reads zu überprüfen, um zu vergleichen, was besser ist.
Wenn Sie glauben, dass jemand anderes von diesem Beitrag profitieren wird, teilen Sie ihn bitte auf Ihren bevorzugten Social-Media-Plattformen. Und wenn Sie etwas hinzuzufügen haben, das wir vergessen haben, lassen Sie es uns im Kommentarbereich unten wissen.