Hintergrund
Eines der ersten Dinge, auf die ich schaue, wenn ich ein Leistungsproblem behebe, sind Wartestatistiken über die DMV sys.dm_os_wait_stats. Um zu sehen, worauf SQL Server wartet, verwende ich die Abfrage aus Glenn Berrys aktuellem Satz von SQL Server-Diagnoseabfragen. Abhängig von der Ausgabe fange ich an, in bestimmte Bereiche innerhalb von SQL Server einzudringen.
Wenn ich beispielsweise hohe CXPACKET-Wartezeiten sehe, überprüfe ich die Anzahl der Kerne auf dem Server, die Anzahl der NUMA-Knoten und die Werte für den maximalen Parallelitätsgrad und den Kostenschwellenwert für Parallelität. Dies sind Hintergrundinformationen, die ich verwende, um die Konfiguration zu verstehen. Bevor ich überhaupt daran denke, Änderungen vorzunehmen, sammle ich mehr quantitative Daten, da ein System mit CXPACKET-Wartezeiten nicht unbedingt eine falsche Einstellung für den maximalen Grad an Parallelität haben muss.
Ebenso hat ein System mit hohen Wartezeiten für E/A-bezogene Wartetypen wie PAGEIOLATCH_XX, WRITELOG und IO_COMPLETION nicht unbedingt ein minderwertiges Speichersubsystem. Wenn ich E/A-bezogene Wartetypen als die wichtigsten Wartevorgänge sehe, möchte ich sofort mehr über den zugrunde liegenden Speicher erfahren. Handelt es sich um Direct Attached Storage oder um ein SAN? Was ist das RAID-Level, wie viele Festplatten sind im Array vorhanden und wie hoch ist die Geschwindigkeit der Festplatten? Ich möchte auch wissen, ob andere Dateien oder Datenbanken den Speicher teilen. Und obwohl es wichtig ist, die Konfiguration zu verstehen, ist ein logischer nächster Schritt, sich die Statistiken virtueller Dateien über die DMV sys.dm_io_virtual_file_stats anzusehen.
Diese DMV wurde in SQL Server 2005 eingeführt und ist ein Ersatz für die Funktion fn_virtualfilestats, die diejenigen von Ihnen, die SQL Server 2000 und früher ausgeführt haben, wahrscheinlich kennen und lieben. Die DMV enthält kumulative E/A-Informationen für jede Datenbankdatei, aber die Daten werden beim Neustart der Instanz zurückgesetzt, wenn eine Datenbank geschlossen, offline geschaltet, getrennt und wieder verbunden wird usw. Es ist wichtig zu verstehen, dass die Statistikdaten der virtuellen Datei nicht repräsentativ für die aktuelle sind Performance – es ist ein Schnappschuss, der eine Aggregation von E/A-Daten seit der letzten Löschung durch eines der oben genannten Ereignisse darstellt. Auch wenn die Daten nicht zeitpunktbezogen sind, können sie dennoch nützlich sein. Wenn die höchsten Wartezeiten für eine Instanz E/A-bezogen sind, die durchschnittliche Wartezeit jedoch weniger als 10 ms beträgt, ist die Speicherung wahrscheinlich kein Problem – aber die Korrelation der Ausgabe mit dem, was Sie in sys.dm_io_virtual_stats sehen, lohnt sich immer noch, um niedrig zu bestätigen Latenzen. Selbst wenn Sie hohe Latenzen in sys.dm_io_virtual_stats sehen, haben Sie immer noch nicht bewiesen, dass die Speicherung ein Problem darstellt.
Die Einrichtung
Um mir die Statistiken virtueller Dateien anzusehen, habe ich zwei Kopien der AdventureWorks2012-Datenbank eingerichtet, die Sie von Codeplex herunterladen können. Für die erste Kopie, die im Folgenden als EX_AdventureWorks2012 bezeichnet wird, habe ich das Skript von Jonathan Kehayias ausgeführt, um die Tabellen „Sales.SalesOrderHeader“ und „Sales.SalesOrderDetail“ auf 1,2 Millionen bzw. 4,9 Millionen Zeilen zu erweitern. Für die zweite Datenbank, BIG_AdventureWorks2012, habe ich das Skript aus meinem vorherigen Post zur Partitionierung verwendet, um eine Kopie der Sales.SalesOrderHeader-Tabelle mit 123 Millionen Zeilen zu erstellen. Beide Datenbanken wurden auf einem externen USB-Laufwerk (Seagate Slim 500 GB) gespeichert, mit tempdb auf meiner lokalen Festplatte (SSD).
Vor dem Testen habe ich vier benutzerdefinierte gespeicherte Prozeduren in jeder Datenbank erstellt (Create_Custom_SPs.zip), die als meine „normale“ Arbeitslast dienen würden. Mein Testprozess war für jede Datenbank wie folgt:
- Starten Sie die Instanz neu.
- Erfassen Sie virtuelle Dateistatistiken.
- Führen Sie die "normale" Arbeitslast für zwei Minuten aus (Prozeduren, die wiederholt über ein PowerShell-Skript aufgerufen werden).
- Erfassen Sie virtuelle Dateistatistiken.
- Erstellen Sie alle Indizes für die entsprechende(n) SalesOrder-Tabelle(n) neu.
- Erfassen Sie virtuelle Dateistatistiken.
Die Daten
Um virtuelle Dateistatistiken zu erfassen, habe ich eine Tabelle mit historischen Informationen erstellt und dann eine Variation von Jimmy Mays Abfrage aus seinem DMV All-Stars-Skript für den Schnappschuss verwendet:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Ich habe die Instanz neu gestartet und dann sofort die Dateistatistiken erfasst. Als ich die Ausgabe so filterte, dass nur die Datenbankdateien EX_AdventureWorks2012 und tempdb angezeigt wurden, wurden nur tempdb-Daten erfasst, da keine Daten von der Datenbank EX_AdventureWorks2012 angefordert wurden:

Ausgabe der anfänglichen Erfassung von sys.dm_os_virtual_file_stats
Ich habe dann die "normale" Arbeitslast zwei Minuten lang ausgeführt (die Anzahl der Ausführungen jeder gespeicherten Prozedur variierte leicht), und nachdem sie die erfassten Dateistatistiken erneut abgeschlossen hatte:

Ausgabe von sys.dm_os_virtual_file_stats nach normaler Arbeitslast
Wir sehen eine Latenz von 57 ms für die EX_AdventureWorks2012-Datendatei. Nicht ideal, aber mit der Zeit würde sich das bei meiner normalen Arbeitsbelastung wahrscheinlich ausgleichen. Es gibt eine minimale Latenzzeit für tempdb, was zu erwarten ist, da die von mir ausgeführte Arbeitslast nicht viel tempdb-Aktivität generiert. Als Nächstes habe ich alle Indizes für die Tabellen Sales.SalesOrderHeaderEnlarged und Sales.SalesOrderDetailEnlarged neu erstellt:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Die Neuerstellungen dauerten weniger als eine Minute, und beachten Sie die Spitzen bei der Leselatenz für die EX_AdventureWorks2012-Datendatei und die Spitzen bei der Schreiblatenz für die EX_AdventureWorks2012-Daten und Protokolldateien:

Ausgabe von sys.dm_os_virtual_file_stats nach Indexneuerstellung
Laut dieser Momentaufnahme der Dateistatistiken ist die Latenz schrecklich; über 600 ms für Schreibvorgänge! Wenn ich diesen Wert für ein Produktionssystem sehen würde, wäre es einfach, Probleme mit der Speicherung sofort zu vermuten. Es ist jedoch auch erwähnenswert, dass AvgBPerWrite ebenfalls gestiegen ist und größere Blockschreibvorgänge länger dauern. Die AvgBPerWrite-Erhöhung wird für die Indexneuerstellungsaufgabe erwartet.
Beachten Sie, dass Sie beim Betrachten dieser Daten kein vollständiges Bild erhalten. Eine bessere Möglichkeit, Latenzen mithilfe virtueller Dateistatistiken zu betrachten, besteht darin, Snapshots zu erstellen und dann die Latenz für den verstrichenen Zeitraum zu berechnen. Das folgende Skript verwendet beispielsweise zwei Snapshots (Current und Previous) und berechnet dann die Anzahl der Lese- und Schreibvorgänge in diesem Zeitraum, die Differenz zwischen den Werten io_stall_read_ms und io_stall_write_ms und dividiert dann io_stall_read_ms delta durch die Anzahl der Lesevorgänge und io_stall_write_ms delta durch Anzahl der Schreibvorgänge. Mit dieser Methode berechnen wir die Zeit, die SQL Server auf E/A-Vorgänge für Lese- oder Schreibvorgänge gewartet hat, und dividieren sie dann durch die Anzahl der Lese- oder Schreibvorgänge, um die Latenz zu bestimmen.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Wenn wir dies ausführen, um die Latenz während der Indexneuerstellung zu berechnen, erhalten wir Folgendes:

Latenz berechnet aus sys.dm_io_virtual_file_stats während der Indexneuerstellung für EX_AdventureWorks2012
Jetzt können wir sehen, dass die tatsächliche Latenz während dieser Zeit hoch war – was wir erwarten würden. Und wenn wir dann zu unserer normalen Arbeitslast zurückkehren und sie einige Stunden laufen lassen würden, würden die aus virtuellen Dateistatistiken berechneten Durchschnittswerte mit der Zeit abnehmen. Wenn wir uns die PerfMon-Daten ansehen, die während des Tests erfasst (und dann über PAL verarbeitet) wurden, sehen wir deutliche Spitzen in Avg. Disk sec/Read und Avg. Disk sec/Write, die mit der Zeit korreliert, zu der die Indexneuerstellung ausgeführt wurde. Aber zu anderen Zeiten liegen die Latenzwerte weit unter akzeptablen Werten:
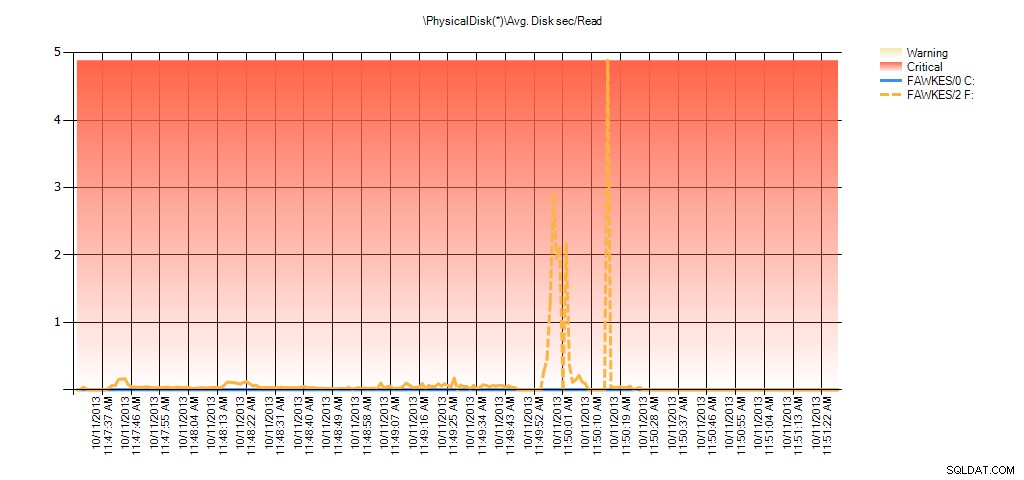
Zusammenfassung von Avg Disk Sec/Read von PAL für EX_AdventureWorks2012 während des Tests
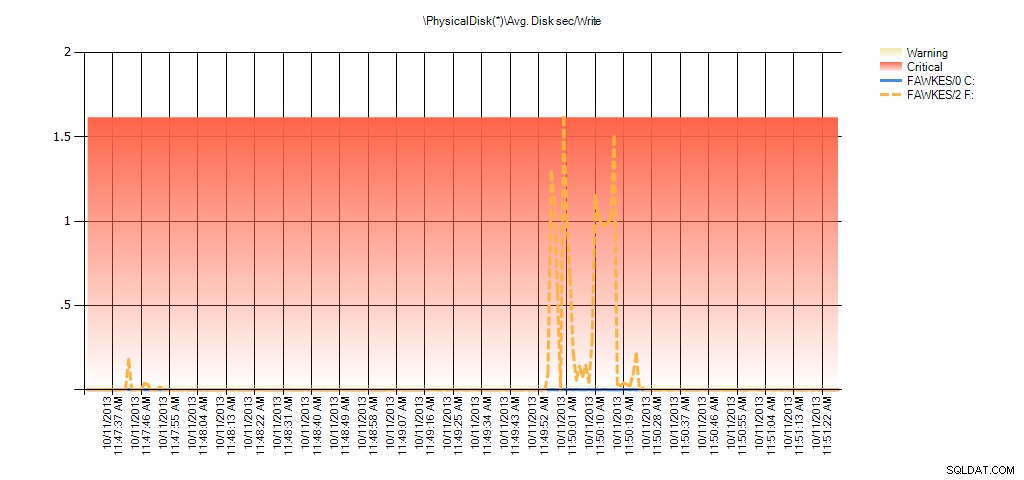
Zusammenfassung von Avg Disk Sec/Write von PAL für EX_AdventureWorks2012 während des Tests
Sie können das gleiche Verhalten für die BIG_AdventureWorks 2012-Datenbank sehen. Hier sind die Latenzinformationen basierend auf dem Snapshot der virtuellen Dateistatistik vor und nach der Indexneuerstellung:

Latenz berechnet aus sys.dm_io_virtual_file_stats während der Indexneuerstellung für BIG_AdventureWorks2012
Und die Leistungsüberwachungsdaten zeigen während der Neuerstellung dieselben Spitzen:
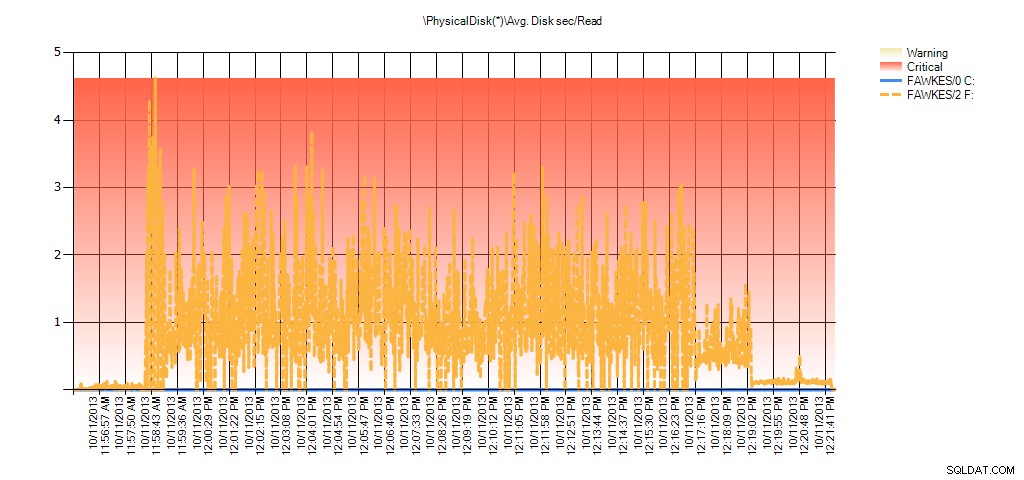
Zusammenfassung von Avg Disk Sec/Read from PAL für BIG_AdventureWorks2012 während des Tests
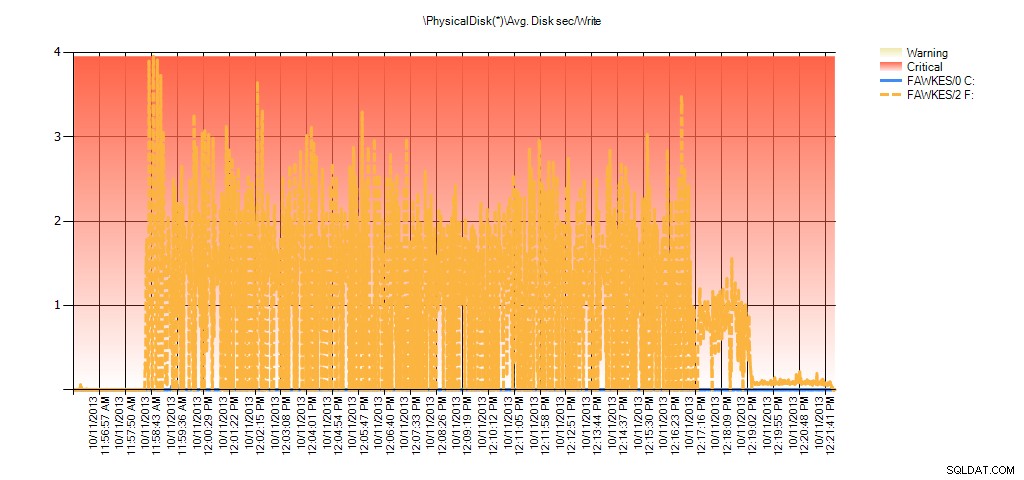
Zusammenfassung von Avg Disk Sec/Write von PAL für BIG_AdventureWorks2012 während des Tests
Schlussfolgerung
Statistiken zu virtuellen Dateien sind ein guter Ausgangspunkt, wenn Sie die E/A-Leistung einer SQL Server-Instanz verstehen möchten. Wenn Sie beim Betrachten der Wartestatistik E/A-bezogene Wartezeiten sehen, ist ein Blick auf sys.dm_io_virtual_file_stats ein logischer nächster Schritt. Beachten Sie jedoch, dass es sich bei den angezeigten Daten um eine Gesamtheit handelt seit die Statistik zuletzt durch eines der zugehörigen Ereignisse (Neustart der Instanz, Offline der Datenbank usw.) gelöscht wurde. Wenn Sie niedrige Latenzen sehen, hält das I/O-Subsystem mit der Leistungslast Schritt. Wenn Sie jedoch hohe Latenzen sehen, ist es keine ausgemachte Sache, dass die Speicherung ein Problem darstellt. Um wirklich zu wissen, was vor sich geht, können Sie, wie hier gezeigt, Schnappschüsse von Dateistatistiken erstellen, oder Sie können einfach den Systemmonitor verwenden, um die Latenz in Echtzeit anzuzeigen. Es ist sehr einfach, ein Data Collector Set in PerfMon zu erstellen, das die Zähler der physischen Festplatte Avg erfasst. Disk Sek./Lesen und Durchschn. Disk Sec/Read für alle Festplatten, die Datenbankdateien hosten. Planen Sie den Data Collector so, dass er regelmäßig startet und stoppt, und nehmen Sie alle n Proben Sekunden (z. B. 15) und sobald Sie PerfMon-Daten für eine angemessene Zeit erfasst haben, lassen Sie sie durch PAL laufen, um die Latenz im Laufe der Zeit zu untersuchen.
Wenn Sie feststellen, dass E/A-Latenz während Ihrer normalen Arbeitslast auftritt und nicht nur während Wartungsaufgaben, die E/A antreiben, immer noch kann nicht auf die Speicherung als zugrundeliegendes Problem hinweisen. Speicherlatenz kann aus verschiedenen Gründen bestehen, wie z. B.:
- SQL Server muss aufgrund ineffizienter Abfragepläne oder fehlender Indizes zu viele Daten lesen
- Der Instanz wird zu wenig Arbeitsspeicher zugewiesen und dieselben Daten werden immer wieder von der Festplatte gelesen, weil sie nicht im Arbeitsspeicher bleiben können
- Implizite Konvertierungen verursachen Index- oder Tabellenscans
- Abfragen führen SELECT * aus, wenn nicht alle Spalten erforderlich sind
- Weitergeleitete Datensatzprobleme in Heaps verursachen zusätzliche E/A
- Geringe Seitendichten aufgrund von Indexfragmentierung, Seitenteilungen oder falschen Füllfaktoreinstellungen verursachen zusätzliche I/O
Was auch immer die Grundursache ist, wichtig ist, dass Sie die Leistung verstehen – insbesondere in Bezug auf E/A – dass es selten einen Datenpunkt gibt, mit dem Sie das Problem lokalisieren können. Um das wahre Problem zu finden, sind mehrere Fakten erforderlich, die Ihnen, wenn sie zusammengesetzt sind, dabei helfen, das Problem aufzudecken.
Beachten Sie schließlich, dass die Speicherlatenz in einigen Fällen völlig akzeptabel sein kann. Bevor Sie schnelleren Speicher oder Änderungen am Code fordern, überprüfen Sie die Workload-Muster und das Service Level Agreement (SLA) für die Datenbank. Im Fall eines Data Warehouse, das den Benutzern Berichte liefert, entspricht die SLA für Abfragen wahrscheinlich nicht den Sekundenbruchteilen, die Sie für ein OLTP-System mit hohem Volumen erwarten würden. In der DW-Lösung können E/A-Latenzen von mehr als einer Sekunde vollkommen akzeptabel und erwartet werden. Verstehen Sie die Erwartungen des Unternehmens und seiner Benutzer und legen Sie dann fest, welche Maßnahmen gegebenenfalls zu ergreifen sind. Und wenn Änderungen erforderlich sind, sammeln Sie die quantitativen Daten, die Sie benötigen, um Ihre Argumentation zu untermauern, nämlich Wartestatistiken, virtuelle Dateistatistiken und Latenzen von Performance Monitor.