Das Entfernen und Verhindern der Indexfragmentierung ist seit langem Teil der normalen Datenbankwartungsvorgänge, nicht nur in SQL Server, sondern auf vielen Plattformen. Die Indexfragmentierung wirkt sich aus vielen Gründen auf die Leistung aus, und die meisten Leute sprechen von den Auswirkungen zufälliger kleiner E/A-Blöcke, die physisch auf festplattenbasiertem Speicher auftreten können, als etwas, das vermieden werden sollte. Die allgemeine Sorge in Bezug auf die Indexfragmentierung besteht darin, dass sie die Leistung von Scans beeinträchtigt, indem sie die Größe von Read-Ahead-I/Os begrenzt. Aufgrund dieses begrenzten Verständnisses der Probleme, die die Indexfragmentierung verursacht, haben einige Leute begonnen, die Idee zu verbreiten, dass die Indexfragmentierung bei Solid-State-Speichergeräten (SSDs) keine Rolle spielt und dass Sie die Indexfragmentierung in Zukunft einfach ignorieren können.
Dies ist jedoch aus mehreren Gründen nicht der Fall. In diesem Artikel wird einer dieser Gründe erläutert und demonstriert:dass die Indexfragmentierung die Wahl des Ausführungsplans für Abfragen beeinträchtigen kann. Dies liegt daran, dass die Indexfragmentierung im Allgemeinen dazu führt, dass ein Index mehr Seiten hat (diese zusätzlichen Seiten stammen von Seitenaufteilung Vorgänge, wie in diesem Beitrag auf dieser Website beschrieben), und daher wird die Verwendung dieses Index vom Abfrageoptimierer von SQL Server als teurer angesehen.
Sehen wir uns ein Beispiel an.
Als Erstes müssen wir eine geeignete Testdatenbank und einen Datensatz erstellen, um zu untersuchen, wie sich die Indexfragmentierung auf die Auswahl des Abfrageplans in SQL Server auswirken kann. Das folgende Skript erstellt eine Datenbank mit zwei Tabellen mit identischen Daten, eine stark fragmentierte und eine minimal fragmentierte.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Nachdem wir den Index neu erstellt haben, können wir uns die Fragmentierungsgrade mit der folgenden Abfrage ansehen:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Ergebnisse:

Hier können wir sehen, dass unsere GuidHighFragmentation Die Tabelle ist zu 99 % fragmentiert und benötigt 31 % mehr Platz auf der Seite als die GuidLowFragmentation Tabelle in der Datenbank, obwohl sie dieselben 7.000.000 Datenzeilen haben. Wenn wir eine grundlegende Aggregationsabfrage für jede der Tabellen durchführen und die Ausführungspläne auf einer Standardinstallation (mit Standardkonfigurationsoptionen und -werten) von SQL Server mit SentryOne Plan Explorer vergleichen:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


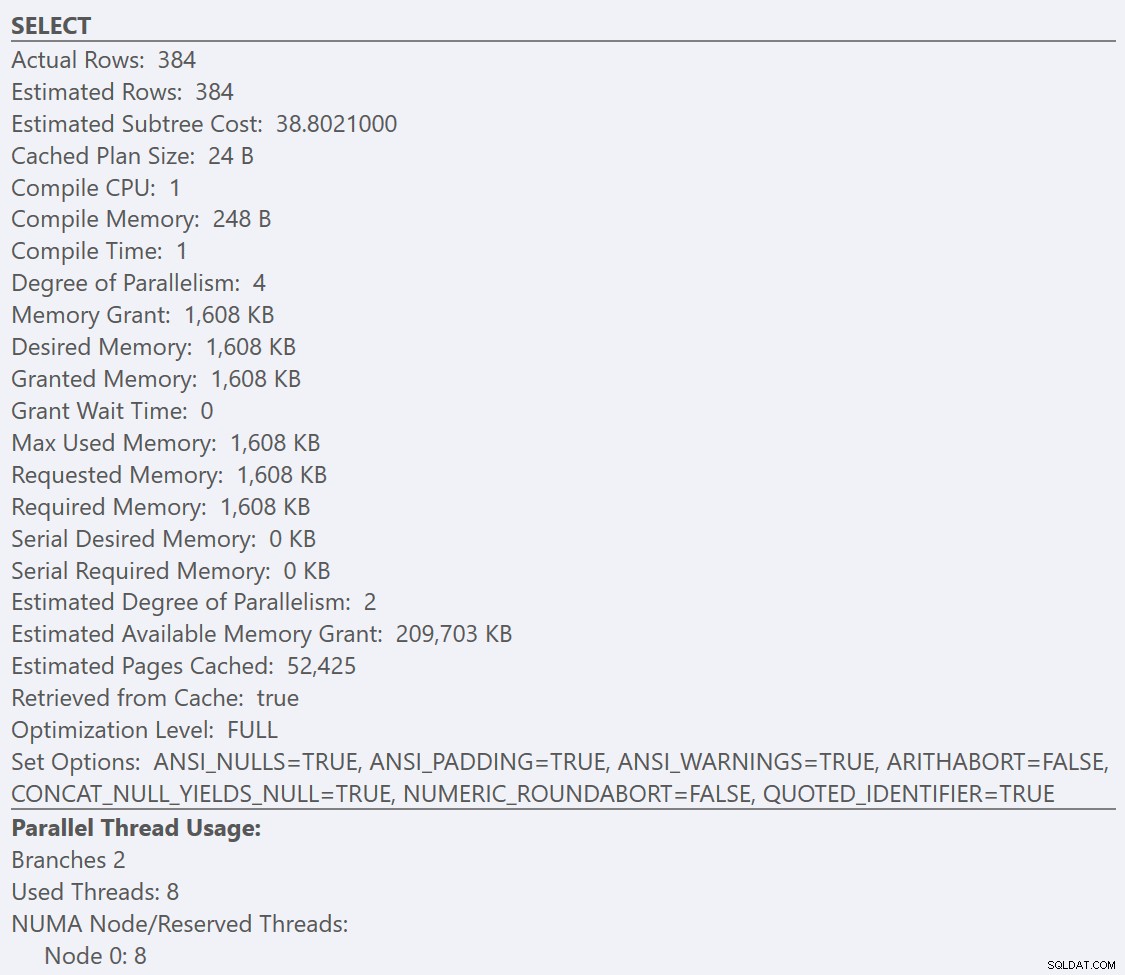

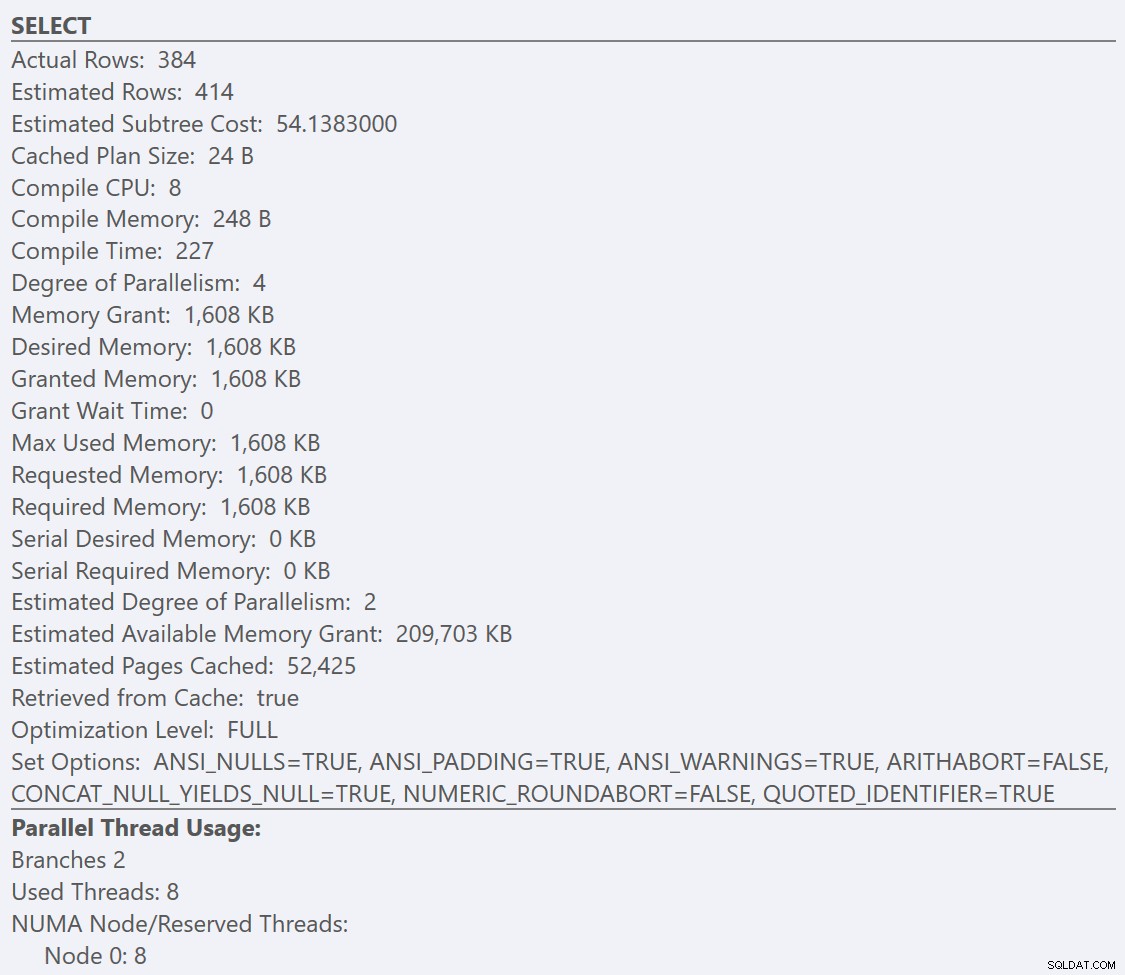
Betrachten wir die Tooltips der SELECT Operator für jeden Plan, der Plan für die GuidLowFragmentation Die Tabelle hat Abfragekosten von 38,80 (die dritte Zeile von oben nach unten in der QuickInfo) gegenüber Abfragekosten von 54,14 für den Plan für den GuidHighFragmentation-Plan.
Bei einer Standardkonfiguration für SQL Server erzeugen beide Abfragen am Ende einen parallelen Ausführungsplan, da die geschätzten Abfragekosten höher sind als der Standardwert der sp_configure-Option „Kostenschwelle für Parallelität“ von 5. Dies liegt daran, dass der Abfrageoptimierer zuerst eine Serie erstellt plan (der nur von einem einzelnen Thread ausgeführt werden kann) beim Kompilieren des Plans für eine Abfrage. Wenn die geschätzten Kosten dieses seriellen Plans den konfigurierten Wert „Kostenschwelle für Parallelität“ überschreiten, wird stattdessen ein paralleler Plan generiert und zwischengespeichert.
Was ist jedoch, wenn die sp_configure-Option „Kostenschwelle für Parallelität“ nicht auf den Standardwert von 5 und höher eingestellt ist? Es ist eine bewährte (und richtige) Vorgehensweise, diese Option vom niedrigen Standardwert von 5 auf einen beliebigen Wert zwischen 25 und 50 (oder sogar viel höher) zu erhöhen, um zu verhindern, dass kleine Abfragen den zusätzlichen Overhead einer parallelen Ausführung verursachen.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Nachdem Sie die Best-Practice-Richtlinien befolgt und den „Kostenschwellenwert für Parallelität“ auf 50 erhöht haben, führt die erneute Ausführung der Abfragen zu demselben Ausführungsplan für die GuidHighFragmentation Tabelle, aber die GuidLowFragmentation Die seriellen Kosten der Abfrage, 44,68, liegen jetzt unter dem Wert „Kostenschwelle für Parallelität“ (denken Sie daran, dass die geschätzten parallelen Kosten 38,80 betrugen), sodass wir einen seriellen Ausführungsplan erhalten:
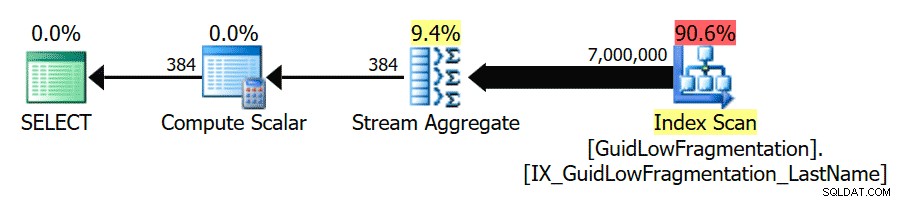
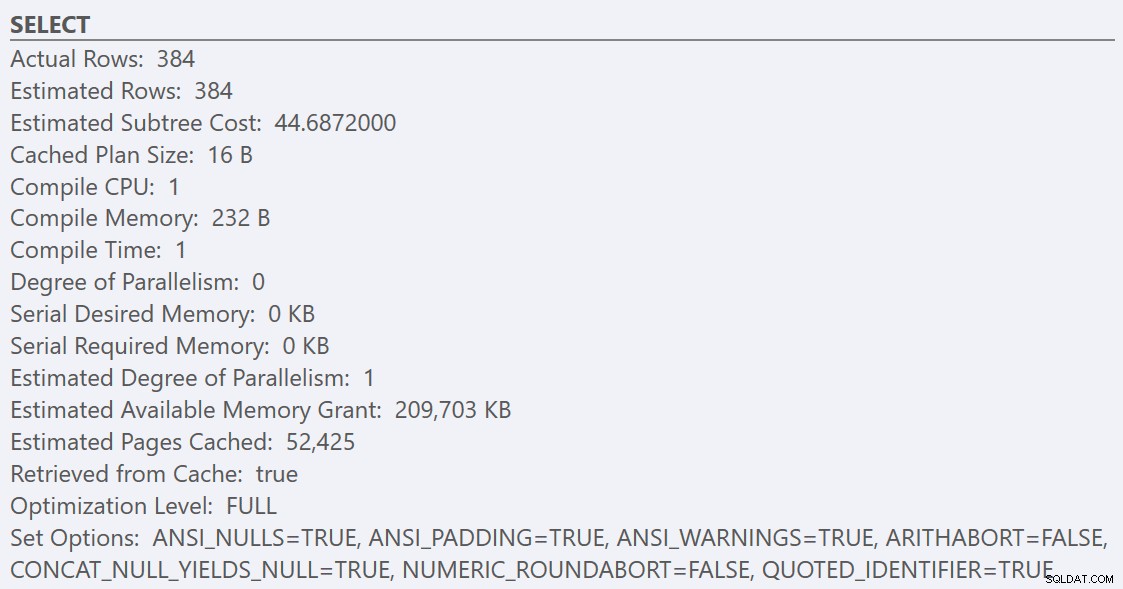
Der zusätzliche Seitenbereich in der GuidHighFragmentation Clustered-Index hielt die Kosten über der Best-Practice-Einstellung für „Kostenschwelle für Parallelität“ und führte zu einem parallelen Plan.
Stellen Sie sich nun vor, dies wäre ein System, bei dem Sie die Best-Practice-Anleitung befolgt und zunächst den „Kostenschwellenwert für Parallelität“ auf einen Wert von 50 konfiguriert haben. Später sind Sie dann dem fehlgeleiteten Rat gefolgt, die Indexfragmentierung einfach vollständig zu ignorieren.
Anstatt dass dies eine einfache Abfrage ist, ist sie komplexer, aber wenn sie auch sehr häufig auf Ihrem System ausgeführt wird und aufgrund der Indexfragmentierung die Seitenzahl die Kosten auf einen parallelen Plan umleitet, verbraucht sie mehr CPU und Auswirkungen auf die Gesamtworkloadleistung als Ergebnis.
Wie geht's? Erhöhen Sie den „Kostenschwellenwert für Parallelität“, damit die Abfrage einen seriellen Ausführungsplan beibehält? Geben Sie der Abfrage einen Hinweis mit OPTION(MAXDOP 1) und erzwingen Sie einfach einen seriellen Ausführungsplan?
Denken Sie daran, dass die Indexfragmentierung wahrscheinlich nicht nur eine Tabelle in Ihrer Datenbank betrifft, da Sie sie jetzt vollständig ignorieren; Es ist wahrscheinlich, dass viele geclusterte und nicht geclusterte Indizes fragmentiert sind und eine höhere Anzahl von Seiten als nötig haben, sodass die Kosten vieler E/A-Vorgänge als Folge der weit verbreiteten Indexfragmentierung steigen, was möglicherweise zu vielen ineffizienten Abfragen führt Pläne.
Zusammenfassung
Sie können die Indexfragmentierung nicht einfach vollständig ignorieren, wie manche Sie vielleicht glauben machen wollen. Neben anderen Nachteilen werden Sie dadurch von den angesammelten Kosten der Abfrageausführung eingeholt, da sich der Abfrageplan ändert, da der Abfrageoptimierer ein kostenbasierter Optimierer ist und diese fragmentierten Indizes daher zu Recht als teurer in der Verwendung einstuft.
Die Abfragen und Szenarien hier sind offensichtlich erfunden, aber wir haben Änderungen des Ausführungsplans gesehen, die durch Fragmentierung im wirklichen Leben auf Client-Systemen verursacht wurden.
Sie müssen sicherstellen, dass Sie die Indexfragmentierung für die Indizes angehen, bei denen die Fragmentierung Workload-Leistungsprobleme verursacht, unabhängig davon, welche Hardware Sie verwenden.