Heutzutage ist die Replikation in einer hochverfügbaren und fehlertoleranten Umgebung für so ziemlich jede Datenbanktechnologie, die Sie verwenden, selbstverständlich. Es ist ein Thema, das wir immer wieder gesehen haben, aber das nie alt wird.
Wenn Sie TimescaleDB verwenden, ist die gebräuchlichste Art der Replikation die Streaming-Replikation, aber wie funktioniert sie?
In diesem Blog werden wir einige Konzepte im Zusammenhang mit der Replikation besprechen und uns auf die Streaming-Replikation für TimescaleDB konzentrieren, eine Funktionalität, die von der zugrunde liegenden PostgreSQL-Engine geerbt wird. Dann werden wir sehen, wie uns ClusterControl bei der Konfiguration helfen kann.
Die Streaming-Replikation basiert also darauf, dass die WAL-Datensätze versendet und auf den Standby-Server angewendet werden. Sehen wir uns also zuerst an, was WAL ist.
WAL
Write Ahead Log (WAL) ist eine Standardmethode zur Sicherstellung der Datenintegrität, sie ist standardmäßig automatisch aktiviert.
Die WALs sind die REDO-Protokolle in TimescaleDB. Aber was sind die REDO-Protokolle?
REDO-Protokolle enthalten alle Änderungen, die in der Datenbank vorgenommen wurden, und sie werden von Replikation, Wiederherstellung, Online-Sicherung und Point-in-Time-Recovery (PITR) verwendet. Alle Änderungen, die nicht auf die Datenseiten angewendet wurden, können aus den REDO-Protokollen wiederhergestellt werden.
Die Verwendung von WAL führt zu einer erheblich reduzierten Anzahl von Schreibvorgängen auf der Festplatte, da nur die Protokolldatei auf die Festplatte geleert werden muss, um sicherzustellen, dass eine Transaktion festgeschrieben wird, und nicht jede Datendatei, die durch die Transaktion geändert wird.
Ein WAL-Datensatz gibt Stück für Stück die an den Daten vorgenommenen Änderungen an. Jeder WAL-Datensatz wird an eine WAL-Datei angehängt. Die Einfügeposition ist eine Protokollsequenznummer (LSN), die ein Byte-Offset in den Protokollen ist und mit jedem neuen Datensatz ansteigt.
Die WALs werden im Verzeichnis pg_wal unterhalb des Datenverzeichnisses gespeichert. Diese Dateien haben eine Standardgröße von 16 MB (die Größe kann geändert werden, indem die Konfigurationsoption --with-wal-segsize beim Erstellen des Servers geändert wird). Sie haben einen eindeutigen inkrementellen Namen im folgenden Format:"00000001 00000000 00000000".
Die Anzahl der in pg_wal enthaltenen WAL-Dateien hängt von dem Wert ab, der den Parametern min_wal_size und max_wal_size in der Konfigurationsdatei postgresql.conf zugewiesen wurde.
Ein Parameter, den wir bei der Konfiguration all unserer TimescaleDB-Installationen einrichten müssen, ist wal_level. Es bestimmt, wie viele Informationen in die WAL geschrieben werden. Der Standardwert ist minimal, wodurch nur die Informationen geschrieben werden, die zur Wiederherstellung nach einem Absturz oder sofortigen Herunterfahren erforderlich sind. Archive fügt die für die WAL-Archivierung erforderliche Protokollierung hinzu; hot_standby fügt weitere Informationen hinzu, die zum Ausführen von Nur-Lese-Abfragen auf einem Standby-Server erforderlich sind; und schließlich fügt logisch Informationen hinzu, die notwendig sind, um logisches Decodieren zu unterstützen. Dieser Parameter erfordert einen Neustart, daher kann es schwierig sein, ihn in laufenden Produktionsdatenbanken zu ändern, wenn wir das vergessen haben.
Streaming-Replikation
Die Streamingreplikation basiert auf der Protokollversandmethode. Die WAL-Datensätze werden zur Anwendung direkt von einem Datenbankserver auf einen anderen verschoben. Wir können sagen, dass es sich um ein kontinuierliches PITR handelt.
Diese Übertragung wird auf zwei verschiedene Arten durchgeführt, durch Übertragung von WAL-Datensätzen jeweils eine Datei (WAL-Segment) (dateibasierter Protokollversand) und durch Übertragung von WAL-Datensätzen (eine WAL-Datei besteht aus WAL-Datensätzen) im laufenden Betrieb (datensatzbasiert log shipping), zwischen einem Master-Server und einem oder mehreren Slave-Servern, ohne darauf zu warten, dass die WAL-Datei gefüllt wird.
In der Praxis verbindet sich ein Prozess namens WAL-Empfänger, der auf dem Slave-Server läuft, über eine TCP/IP-Verbindung mit dem Master-Server. Auf dem Master-Server existiert ein weiterer Prozess namens WAL-Sender, der für das Senden der WAL-Registrierungen an den Slave-Server zuständig ist, während sie auftreten.
Die Streaming-Replikation kann wie folgt dargestellt werden:
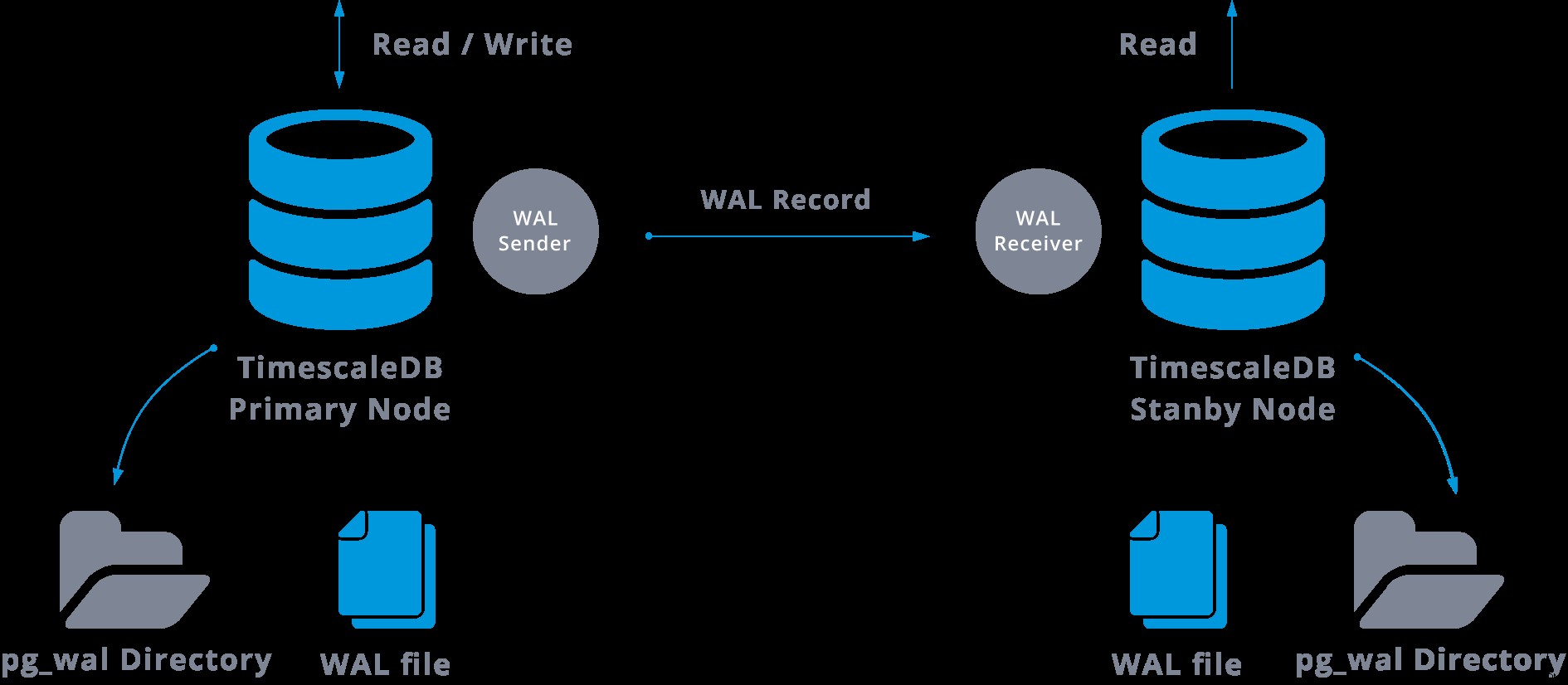
Wenn wir uns das obige Diagramm ansehen, können wir uns überlegen, was passiert, wenn die Kommunikation zwischen dem WAL-Sender und dem WAL-Empfänger fehlschlägt?
Beim Konfigurieren der Streaming-Replikation haben wir die Möglichkeit, die WAL-Archivierung zu aktivieren.
Dieser Schritt ist eigentlich nicht obligatorisch, aber für ein robustes Replikations-Setup äußerst wichtig, da verhindert werden muss, dass der Hauptserver alte WAL-Dateien recycelt, die noch nicht auf den Slave angewendet wurden. In diesem Fall müssen wir die Replik von Grund auf neu erstellen.
Bei der Konfiguration der Replikation mit kontinuierlicher Archivierung gehen wir von einem Backup aus und müssen, um den Synchronisierungsstatus mit dem Master zu erreichen, alle Änderungen anwenden, die in der WAL gehostet werden und nach dem Backup vorgenommen wurden. Während dieses Vorgangs stellt der Standby-Modus zunächst alle am Archivspeicherort verfügbaren WAL wieder her (durch Aufrufen von restore_command). Der restore_command schlägt fehl, wenn wir den letzten archivierten WAL-Eintrag erreichen, also wird der Standby im pg_wal-Verzeichnis nachsehen, ob die Änderung dort vorhanden ist (dies wird eigentlich gemacht, um Datenverlust zu vermeiden, wenn der Master-Server abstürzt und einige Änderungen, die bereits in das Replikat verschoben und dort angewendet wurden, wurden noch nicht archiviert).
Wenn dies fehlschlägt und der angeforderte Datensatz dort nicht vorhanden ist, beginnt die Kommunikation mit dem Master durch Streaming-Replikation.
Wenn die Streaming-Replikation fehlschlägt, kehrt sie zu Schritt 1 zurück und stellt die Datensätze erneut aus dem Archiv wieder her. Diese Schleife des Abrufens aus dem Archiv, pg_wal, und über die Streaming-Replikation wird fortgesetzt, bis der Server gestoppt oder ein Failover durch eine Triggerdatei ausgelöst wird.
Dies ist ein Diagramm einer solchen Konfiguration:
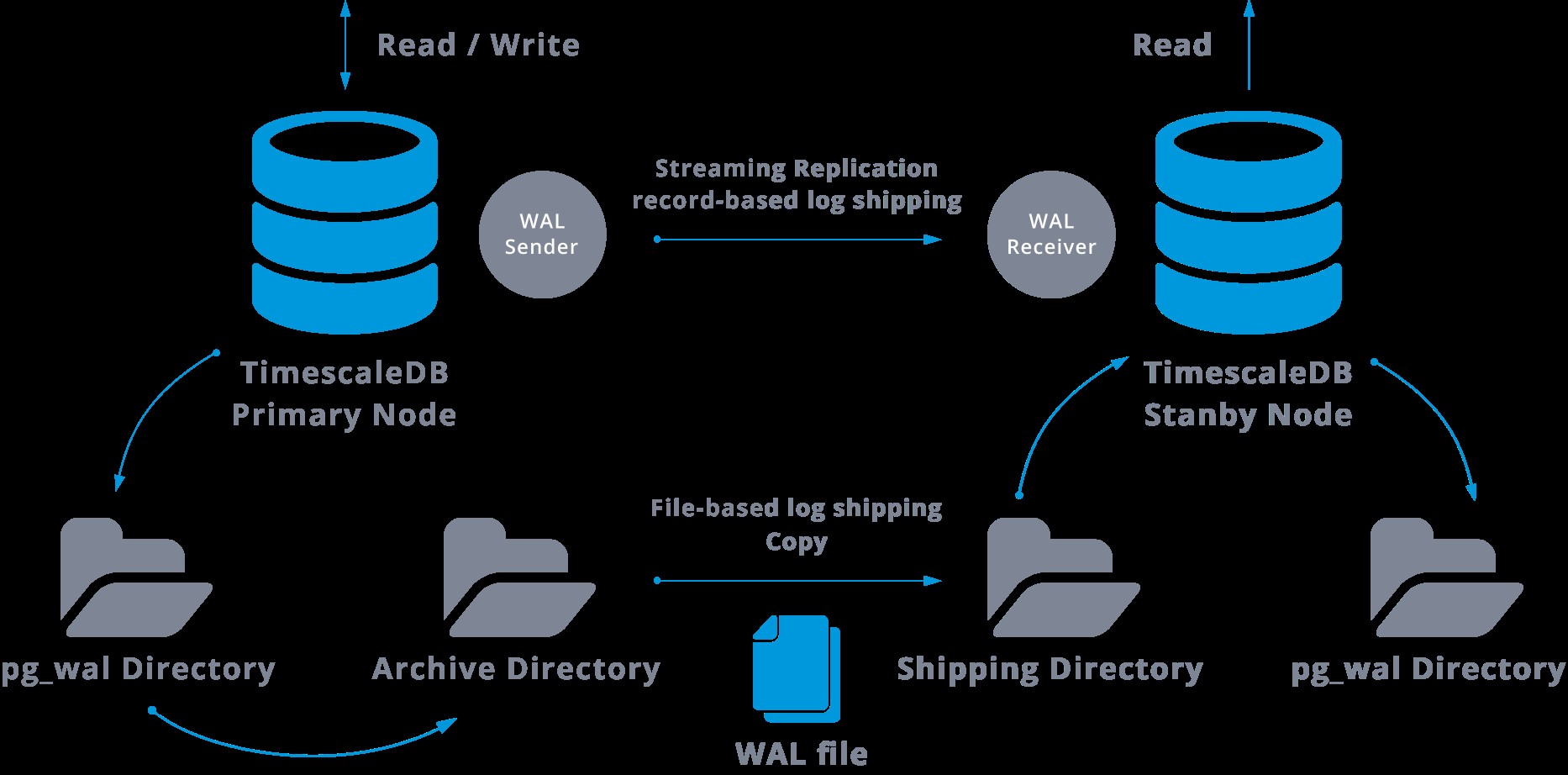
Die Streaming-Replikation ist standardmäßig asynchron, sodass wir zu einem bestimmten Zeitpunkt einige Transaktionen haben können, die im Master festgeschrieben und noch nicht auf den Standby-Server repliziert werden können. Dies impliziert einen potenziellen Datenverlust.
Diese Verzögerung zwischen dem Commit und der Auswirkung der Änderungen in der Replik soll jedoch sehr gering sein (einige Millisekunden), vorausgesetzt natürlich, dass der Replikationsserver leistungsfähig genug ist, um mit der Last Schritt zu halten.
Für die Fälle, in denen selbst das Risiko eines kleinen Datenverlusts nicht tolerierbar ist, können wir die synchrone Replikationsfunktion verwenden.
Bei der synchronen Replikation wartet jeder Commit einer Schreibtransaktion, bis eine Bestätigung empfangen wird, dass der Commit auf die Write-Ahead-Log-On-Festplatte des Primär- und des Standby-Servers geschrieben wurde.
Diese Methode minimiert die Möglichkeit eines Datenverlusts, da dazu sowohl der Master als auch der Standby gleichzeitig ausfallen müssen.
Der offensichtliche Nachteil dieser Konfiguration besteht darin, dass sich die Antwortzeit für jede Schreibtransaktion erhöht, da wir warten müssen, bis alle Parteien geantwortet haben. Die Zeit für einen Commit ist also mindestens die Hin- und Rückfahrt zwischen dem Master und dem Replikat. Nur-Lese-Transaktionen sind davon nicht betroffen.
Um die synchrone Replikation einzurichten, müssen wir für jeden der Standby-Server einen Anwendungsnamen in der primary_conninfo der Datei recovery.conf angeben:primary_conninfo ='...aplication_name=slaveX' .
Wir müssen auch die Liste der Standby-Server spezifizieren, die an der synchronen Replikation teilnehmen werden:synchron_standby_name ='slaveX,slaveY'.
Wir können einen oder mehrere synchrone Server einrichten, und dieser Parameter gibt auch an, welche Methode (FIRST und ANY) aus den aufgelisteten synchronen Standbys ausgewählt werden soll.
Um TimescaleDB mit Streaming-Replikations-Setups (synchron oder asynchron) bereitzustellen, können wir ClusterControl verwenden, wie wir hier sehen können.
Nachdem wir unsere Replikation konfiguriert haben und sie ausgeführt wird, benötigen wir einige zusätzliche Funktionen für die Überwachung und das Backup-Management. ClusterControl ermöglicht es uns, Backups/Aufbewahrung unseres TimescaleDB-Clusters vom selben Ort aus ohne externe Tools zu überwachen und zu verwalten.
So konfigurieren Sie die Streaming-Replikation auf TimescaleDB
Das Einrichten der Streaming-Replikation ist eine Aufgabe, bei der einige Schritte sorgfältig befolgt werden müssen. Wenn Sie es manuell konfigurieren möchten, können Sie unserem Blog zu diesem Thema folgen.
Sie können jedoch Ihre aktuelle TimescaleDB auf ClusterControl bereitstellen oder importieren und dann die Streaming-Replikation mit wenigen Klicks konfigurieren. Mal sehen, wie wir das machen können.
Für diese Aufgabe gehen wir davon aus, dass Ihr TimescaleDB-Cluster von ClusterControl verwaltet wird. Gehen Sie zu ClusterControl -> Cluster auswählen -> Clusteraktionen -> Replikations-Slave hinzufügen.
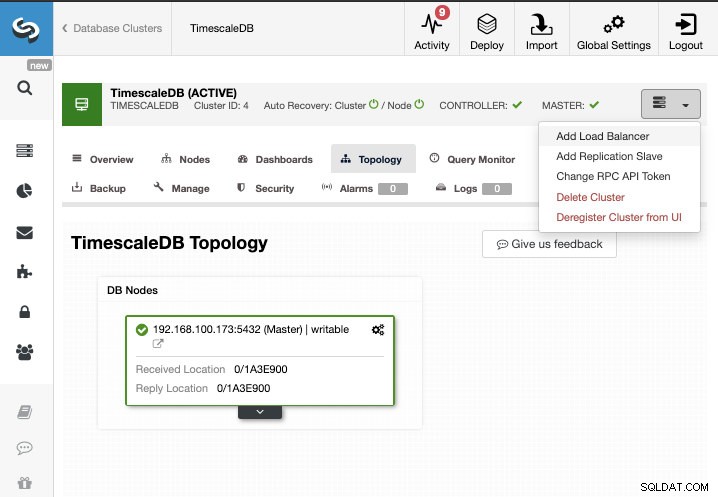
Wir können einen neuen Replikations-Slave erstellen (Standby) oder einen vorhandenen importieren. In diesem Fall erstellen wir einen neuen.
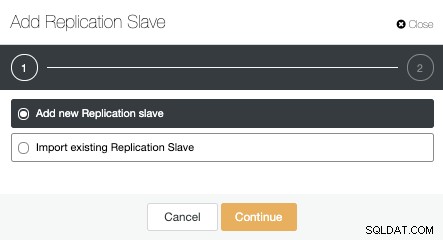
Jetzt müssen wir den Master-Knoten auswählen, die IP-Adresse oder den Hostnamen für den neuen Standby-Server und den Datenbankport hinzufügen. Wir können auch angeben, ob ClusterControl die Software installieren soll und ob wir synchrone oder asynchrone Streaming-Replikation konfigurieren möchten.
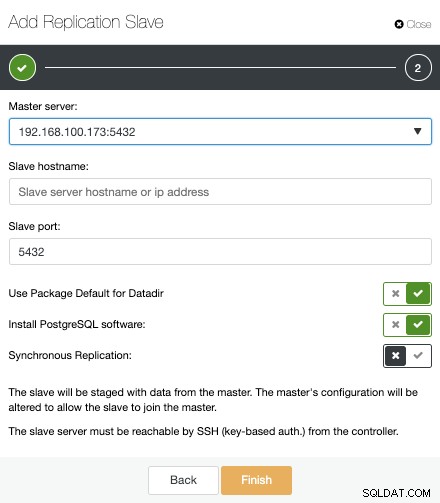
Das ist alles. Wir müssen nur warten, bis ClusterControl den Job beendet hat. Wir können den Status im Aktivitätsbereich überwachen.
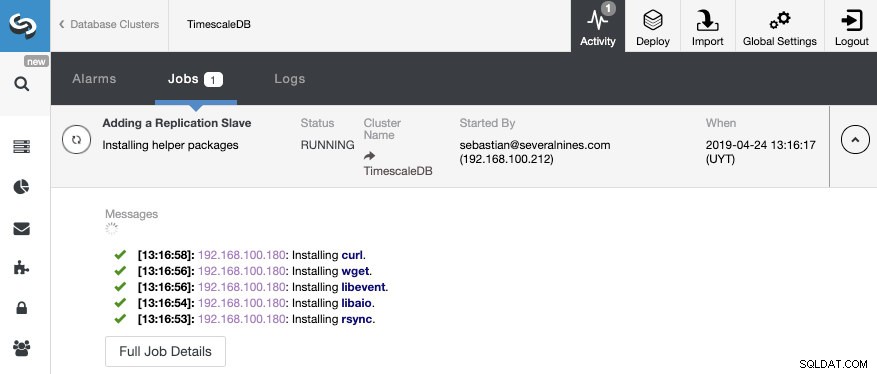
Nachdem der Job abgeschlossen ist, sollte die Streaming-Replikation konfiguriert sein und wir können die neue Topologie im Abschnitt ClusterControl Topology View überprüfen.
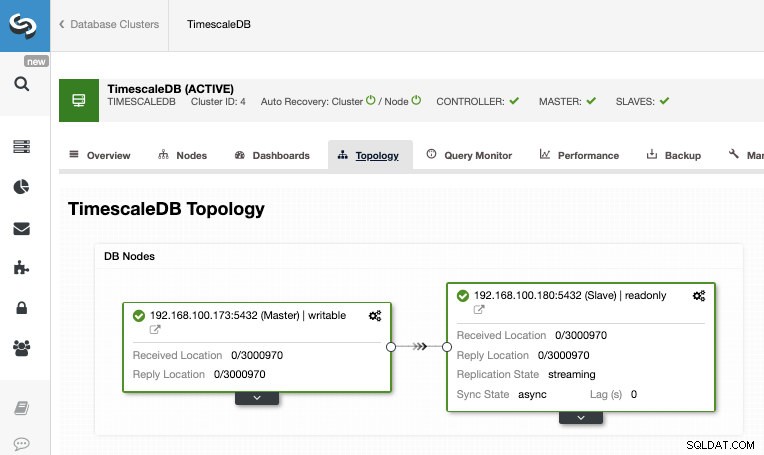
Durch die Verwendung von ClusterControl können Sie auch mehrere Verwaltungsaufgaben für Ihre TimescaleDB ausführen, wie z. B. Sicherung, Überwachung und Warnung, automatisches Failover, Hinzufügen von Knoten, Hinzufügen von Lastausgleichsfunktionen und noch mehr.
Failover
Wie wir sehen konnten, verwendet TimescaleDB einen Strom von Write-Ahead-Log-Einträgen (WAL), um die Standby-Datenbanken synchron zu halten. Fällt der Hauptserver aus, enthält der Standby fast alle Daten des Hauptservers und kann schnell zum neuen Master-Datenbankserver gemacht werden. Dies kann synchron oder asynchron erfolgen und kann nur für den gesamten Datenbankserver durchgeführt werden.
Um Hochverfügbarkeit effektiv zu gewährleisten, reicht eine Master-Standby-Architektur nicht aus. Wir müssen auch eine automatische Form von Failover aktivieren, damit wir im Falle eines Fehlers die kleinstmögliche Verzögerung bei der Wiederaufnahme der normalen Funktionalität haben können.
TimescaleDB enthält keinen automatischen Failover-Mechanismus, um Fehler in der Master-Datenbank zu identifizieren und den Slave zu benachrichtigen, den Besitz zu übernehmen, so dass dies ein wenig Arbeit auf der Seite des DBA erfordert. Sie werden auch nur einen Server haben, der arbeitet, also muss die Master-Standby-Architektur neu erstellt werden, damit wir zu der gleichen normalen Situation zurückkehren, die wir vor dem Problem hatten.
ClusterControl enthält eine automatische Failover-Funktion für TimescaleDB, um die mittlere Reparaturzeit (MTTR) in Ihrer Hochverfügbarkeitsumgebung zu verbessern. Im Falle eines Fehlers befördert ClusterControl den fortschrittlichsten Slave zum Master und konfiguriert die verbleibenden Slaves neu, um sich mit dem neuen Master zu verbinden. HAProxy kann auch automatisch bereitgestellt werden, um Anwendungen einen einzigen Datenbank-Endpunkt anzubieten, sodass sie nicht von einer Änderung des Master-Servers betroffen sind.
Einschränkungen
Zugehörige Ressourcen ClusterControl für TimescaleDB Wie man TimescaleDB einfach bereitstellt PostgreSQL-Streaming-Replikation - ein tiefer EinblickWir haben einige bekannte Einschränkungen bei der Verwendung der Streaming-Replikation:
- Wir können nicht in eine andere Version oder Architektur replizieren
- Auf dem Standby-Server können wir nichts ändern
- Wir wissen nicht genau, was wir replizieren können
Um diese Einschränkungen zu überwinden, haben wir also die logische Replikationsfunktion. Weitere Informationen zu diesem Replikationstyp finden Sie im folgenden Blog.
Schlussfolgerung
Eine Master-Standby-Topologie hat viele verschiedene Verwendungszwecke wie Analyse, Backup, Hochverfügbarkeit, Failover. In jedem Fall ist es notwendig zu verstehen, wie die Streaming-Replikation auf TimescaleDB funktioniert. Es ist auch nützlich, ein System zur Verwaltung des gesamten Clusters zu haben und Ihnen die Möglichkeit zu geben, diese Topologie auf einfache Weise zu erstellen. In diesem Blog haben wir gesehen, wie dies mit ClusterControl erreicht werden kann, und wir haben einige grundlegende Konzepte zur Streaming-Replikation besprochen.