Mein Kollege Steve Wright (Blog | @SQL_Steve) hat mich kürzlich mit einer Frage zu einem seltsamen Ergebnis, das er gesehen hat, angestachelt. Um einige Funktionen in unserem neuesten Tool, SQL Sentry Plan Explorer PRO, zu testen, hatte er eine breite und große Tabelle erstellt und eine Vielzahl von Abfragen dafür ausgeführt. In einem Fall gab er viele Daten zurück, aber STATISTICS IO zeigte, dass nur sehr wenige Lesevorgänge stattfanden. Ich habe einige Leute auf #sqlhelp angepingt, und da anscheinend niemand dieses Problem gesehen hat, dachte ich, ich würde darüber bloggen.
TL;DR-Version
Kurz gesagt, seien Sie sich bewusst, dass es einige Szenarien gibt, in denen Sie sich nicht auf STATISTICS IO verlassen können um Ihnen die Wahrheit zu sagen. In einigen Fällen (in diesem Fall TOP und Parallelität), wird es logische Lesevorgänge erheblich untermelden. Dies kann dazu führen, dass Sie glauben, Sie hätten eine sehr E/A-freundliche Abfrage, obwohl dies nicht der Fall ist. Es gibt andere, offensichtlichere Fälle – beispielsweise wenn Sie eine Reihe von I/Os durch die Verwendung von skalaren benutzerdefinierten Funktionen versteckt haben. Wir denken, dass Plan Explorer diese Fälle offensichtlicher macht; dieser ist jedoch etwas kniffliger.
Die Problemabfrage
Die Tabelle hat 37 Millionen Zeilen, bis zu 250 Bytes pro Zeile, etwa 1 Million Seiten und eine sehr geringe Fragmentierung (0,42 % auf Ebene 0, 15 % auf Ebene 1 und 0 darüber hinaus). Es gibt keine berechneten Spalten, keine UDFs im Spiel und keine Indizes außer einem gruppierten Primärschlüssel auf dem führenden INT Säule. Eine einfache Abfrage, die 500.000 Zeilen, alle Spalten, mit TOP zurückgibt und SELECT * :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029');
(Und ja, mir ist klar, dass ich gegen meine eigenen Regeln verstoße und SELECT * verwende und TOP ohne ORDER BY , aber der Einfachheit halber versuche ich mein Bestes, um meinen Einfluss auf den Optimierer zu minimieren.)
Ergebnisse:
(500000 Zeile(n) betroffen)Tabelle 'OrderHistory'. Scan-Anzahl 1, logische Lesevorgänge 23, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
Wir geben 500.000 Zeilen zurück und es dauert ungefähr 10 Sekunden. Ich weiß sofort, dass etwas mit der Anzahl der logischen Lesevorgänge nicht stimmt. Auch wenn ich die zugrunde liegenden Daten noch nicht kannte, kann ich anhand der Rasterergebnisse in Management Studio erkennen, dass mehr als 23 Seiten mit Daten abgerufen werden, unabhängig davon, ob sie aus dem Speicher oder dem Cache stammen, und dies sollte sich irgendwo in
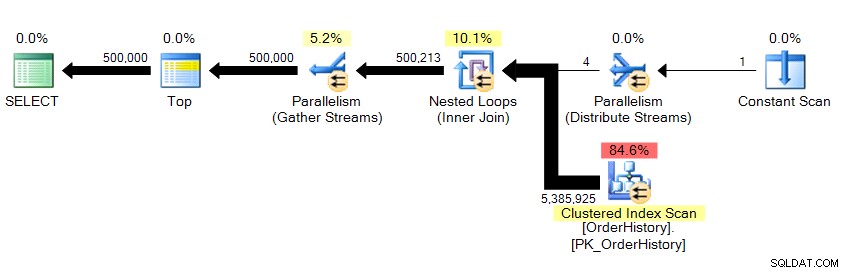
… wir sehen, dass Parallelität darin ist und dass wir die gesamte Tabelle gescannt haben. Wie ist es also möglich, dass es nur 23 logische Lesevorgänge gibt?
Eine weitere "identische" Abfrage
Eine meiner ersten Fragen an Steve war:"Was passiert, wenn Sie die Parallelität eliminieren?" Also habe ich es ausprobiert. Ich habe die ursprüngliche Version der Unterabfrage genommen und MAXDOP 1 hinzugefügt :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029') OPTION (MAXDOP 1);
Ergebnisse und Plan:
(500000 Zeile(n) betroffen)Tabelle 'OrderHistory'. Scan-Anzahl 1, logische Lesevorgänge 149589, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, logische Lob-Reads 0, physische Lob-Reads 0, Lob-Read-Ahead-Reads 0.
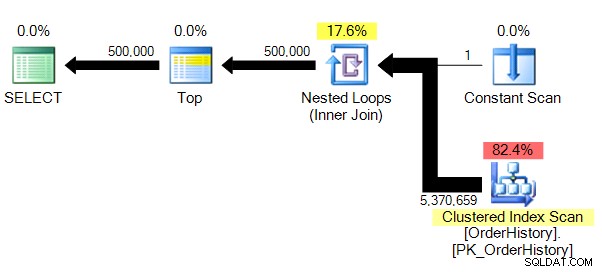
Wir haben einen etwas weniger komplexen Plan und ohne die Parallelität (aus offensichtlichen Gründen) STATISTICS IO zeigt uns viel glaubwürdigere Zahlen für die Anzahl der logischen Lesevorgänge.
Was ist die Wahrheit?
Es ist nicht schwer zu erkennen, dass eine dieser Abfragen nicht die ganze Wahrheit sagt. Während STATISTICS IO erzählt uns vielleicht nicht die ganze Geschichte, vielleicht aber Trace. Wenn wir Laufzeitmetriken abrufen, indem wir einen tatsächlichen Ausführungsplan im Plan-Explorer generieren, sehen wir, dass die magische Low-Read-Abfrage die Daten tatsächlich aus dem Speicher oder der Festplatte und nicht aus einer Wolke magischen Feenstaubs zieht. Tatsächlich hat sie *mehr* Lesezugriffe als die andere Version:

Es ist also klar, dass Lesevorgänge stattfinden, sie erscheinen nur nicht korrekt im STATISTICS IO Ausgabe.
Was ist das Problem?
Nun, ich bin ganz ehrlich:Ich weiß es nicht, abgesehen davon, dass Parallelität definitiv eine Rolle spielt, und es scheint eine Art Race Condition zu sein. STATISTIK IO (und da wir die Daten von dort erhalten, zeigt unsere Registerkarte Table I/O) eine sehr irreführende Anzahl von Lesevorgängen. Es ist klar, dass die Abfrage alle Daten zurückgibt, nach denen wir suchen, und aus den Ablaufverfolgungsergebnissen geht hervor, dass sie dazu Lesevorgänge und keine Osmose verwendet. Ich habe Paul White (Blog | @SQL_Kiwi) danach gefragt und er schlug vor, dass nur einige der I/O-Zählungen vor dem Thread in die Gesamtzahl einbezogen werden (und stimmt zu, dass dies ein Fehler ist).
Wenn Sie dies zu Hause ausprobieren möchten, benötigen Sie lediglich AdventureWorks (dies sollte die Versionen 2008, 2008 R2 und 2012 reproduzieren) und die folgende Abfrage:
SET STATISTICS IO ON; DBCC SETCPUWEIGHT(1000) WITH NO_INFOMSGS; GO SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101'); SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101') OPTION (MAXDOP 1); DBCC SETCPUWEIGHT(1) WITH NO_INFOMSGS;
(Beachten Sie, dass SETCPUWEIGHT wird nur verwendet, um Parallelität zu erreichen. Weitere Informationen finden Sie im Blogbeitrag von Paul White zu Plan Costing.)
Ergebnisse:
Tabelle 'SalesOrderHeader'. Scan-Anzahl 1, logische Lesevorgänge 4, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Reads 0.Tabelle 'SalesOrderHeader'. Scan-Anzahl 1, logische Lesevorgänge 333, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
Paul wies auf eine noch einfachere Repro hin:
SET STATISTICS IO ON; GO SELECT TOP (15000) * FROM Production.TransactionHistory WHERE TransactionDate < (SELECT '20080101') OPTION (QUERYTRACEON 8649, MAXDOP 4); SELECT TOP (15000) * FROM Production.TransactionHistory AS th WHERE TransactionDate < (SELECT '20080101');
Ergebnisse:
Tabelle 'Transaktionsverlauf'. Scan-Zähler 1, logische Lesevorgänge 5, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physische Lesevorgänge 0, Lob-Read-Ahead-Reads 0.Tabelle „TransactionHistory“. Scan-Anzahl 1, logische Lesevorgänge 110, physische Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Lob-Logik-Reads 0, Lob-Physical-Reads 0, Lob-Read-Ahead-Reads 0.
Es scheint also, dass wir dies mit einem TOP leicht nach Belieben reproduzieren können Bediener und einem ausreichend niedrigen DOP. Ich habe einen Fehler gemeldet:
- STATISTICS IO meldet zu wenig logische Lesevorgänge für parallele Pläne
Und Paul hat zwei andere etwas verwandte Bugs eingereicht, die Parallelität betreffen, den ersten als Ergebnis unseres Gesprächs:
- Kardinalitätsschätzungsfehler mit gepushtem Prädikat bei einer Suche [verwandter Blogbeitrag]
- Schlechte Leistung mit Parallelität und bester [verwandter Blogpost]
(Für die Nostalgiker sind hier sechs weitere Parallelitätsfehler, auf die ich vor ein paar Jahren hingewiesen habe.)
Was ist die Lektion?
Seien Sie vorsichtig, wenn Sie einer einzigen Quelle vertrauen. Wenn Sie sich nur STATISTICS IO ansehen Nachdem Sie eine Abfrage wie diese geändert haben, könnten Sie versucht sein, sich auf den wundersamen Rückgang der Lesevorgänge statt auf die Verlängerung der Dauer zu konzentrieren. An diesem Punkt können Sie sich auf die Schulter klopfen, die Arbeit früher verlassen und Ihr Wochenende genießen, weil Sie denken, dass Sie gerade einen enormen Einfluss auf die Leistung Ihrer Abfrage hatten. Wobei natürlich nichts weiter von der Wahrheit entfernt sein könnte.