In diesem Artikel untersuche ich weiterhin Lösungen für die Herausforderung, Angebot und Nachfrage aufeinander abzustimmen. Danke an Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie, Ian und Peter Larsson für die Zusendung Ihrer Lösungen.
Letzten Monat habe ich Lösungen behandelt, die auf einem überarbeiteten Intervallschnittansatz im Vergleich zum klassischen Ansatz basieren. Die schnellste dieser Lösungen kombinierte Ideen von Kamil, Luca und Daniel. Es vereinte zwei Abfragen mit disjunkten Sargable-Prädikaten. Es dauerte 1,34 Sekunden, bis die Lösung gegen eine 400.000-Zeilen-Eingabe abgeschlossen war. Das ist nicht allzu schäbig, wenn man bedenkt, dass die Lösung, die auf dem klassischen Interval-Cutting-Ansatz basiert, 931 Sekunden benötigte, um mit derselben Eingabe fertig zu werden. Denken Sie auch daran, dass Joe eine brillante Lösung entwickelt hat, die auf dem klassischen Intervallschnittansatz basiert, aber die Matching-Logik optimiert, indem Intervalle basierend auf der größten Intervalllänge in Buckets unterteilt werden. Mit der gleichen 400.000-Zeilen-Eingabe benötigte Joes Lösung 0,9 Sekunden, um sie abzuschließen. Das Schwierige an dieser Lösung ist, dass ihre Leistung mit zunehmender Länge des größten Intervalls abnimmt.
Diesen Monat untersuche ich faszinierende Lösungen, die schneller sind als die Kamil/Luca/Daniel Revised Intersections-Lösung und neutral zur Intervalllänge sind. Die Lösungen in diesem Artikel wurden von Brian Walker, Ian, Peter Larsson, Paul White und mir erstellt.
Ich habe alle Lösungen in diesem Artikel mit der Eingabetabelle Auctions mit 100.000, 200.000, 300.000 und 400.000 Zeilen und mit den folgenden Indizes getestet:
-- Index zur Unterstützung der Lösung CREATE UNIQUE NOCLLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Aktivieren Sie Window Aggregate im Stapelmodus. CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID =-1 AND ID =-2;
Bei der Beschreibung der Logik hinter den Lösungen gehe ich davon aus, dass die Tabelle „Auktionen“ mit den folgenden kleinen Beispieldaten gefüllt ist:
ID-Code Menge ---- ---------1 D 5.0000002 D 3.0000003 D 8.0000005 D 2.0000006 D 8.0000007 D 4.0000008 D 2.0000001000 S 8.0000002000 S 6.0000003000 S 2.0000004000 S 2.0000005000 S 4.0000006000 S 3.0000007000 S 2.000000
Nachfolgend das gewünschte Ergebnis für diese Beispieldaten:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Brian Walkers Lösung
Outer Joins werden ziemlich häufig in SQL-Abfragelösungen verwendet, aber wenn Sie diese verwenden, verwenden Sie bei weitem einseitige Joins. Wenn ich über äußere Verknüpfungen unterrichte, bekomme ich oft Fragen, in denen nach Beispielen für praktische Anwendungsfälle vollständiger äußerer Verknüpfungen gefragt wird, und es gibt nicht so viele. Brians Lösung ist ein schönes Beispiel für einen praktischen Anwendungsfall von Full Outer Joins.
Hier ist Brians vollständiger Lösungscode:
ABFALLTABELLE, WENN VORHANDEN #MyPairings; CREATE TABLE #MyPairings (DemandID INT NOT NULL, SupplyID INT NOT NULL, TradeQuantity DECIMAL(19,06) NOT NULL); WITH D AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTITION BY A.Code ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running FROM dbo.Auctions AS A WHERE A.Code ='D'),S AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTITION BY A.Code ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running FROM dbo.Auctions AS A WHERE A.Code ='S'),W AS( SELECT D.ID AS DemandID, S.ID AS SupplyID, ISNULL(D.Running, S.Running) AS Running FROM D FULL JOIN S ON D.Running =S.Running),Z AS( SELECT CASE WHEN W.DemandID IS NOT NULL THEN W.DemandID ELSE MIN(W.DemandID) OVER (ORDER BY W.Running ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) END AS DemandID, FALL WENN W.SupplyID NICHT NULL IST, DANN W.SupplyID ELSE MIN(W.SupplyID ) OVER (ORDER BY W.Running ROWS ZWISCHEN DER AKTUELLEN REIHE UND UNBEGRENZTEN FOLGENDEN) END AS SupplyID, W.Running FROM W)INSERT #MyPair ings( DemandID, SupplyID, TradeQuantity ) SELECT Z.DemandID, Z.SupplyID, Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) AS TradeQuantity FROM Z WO Z.DemandID NICHT IST NULL UND Z.SupplyID IST NICHT NULL;
Ich habe Brians ursprüngliche Verwendung von abgeleiteten Tabellen mit CTEs aus Gründen der Klarheit überarbeitet.
Der CTE D berechnet die laufenden Gesamtnachfragemengen in einer Ergebnisspalte namens D.Running, und der CTE S berechnet die laufenden Gesamtangebotsmengen in einer Ergebnisspalte namens S.Running. Der CTE W führt dann eine vollständige äußere Verknüpfung zwischen D und S durch, wobei D.Running mit S.Running abgeglichen wird, und gibt den ersten Nicht-NULL-Wert unter D.Running und S.Running als W.Running zurück. Hier ist das Ergebnis, das Sie erhalten, wenn Sie alle Zeilen von W abfragen, sortiert nach Running:
DemandID SupplyID Running----------- ----------- ----------1 NULL 5.0000002 1000 8.000000NULL 2000 14.0000003 3000 16.0000005 4000 18.000000 NULL 5000 22,000000NULL 6000 25,0000006 NULL 26,000000NULL 7000 27,0000007 NULL 30,0000008 NULL 32,000000
Die Idee, einen Full Outer Join basierend auf einem Prädikat zu verwenden, das die laufenden Summen von Nachfrage und Angebot vergleicht, ist ein Geniestreich! Die meisten Zeilen in diesem Ergebnis – in unserem Fall die ersten 9 – stellen Ergebnispaarungen dar, bei denen einige zusätzliche Berechnungen fehlen. Zeilen mit nachgestellten NULL-IDs einer der Arten stellen Einträge dar, die nicht abgeglichen werden können. In unserem Fall stellen die letzten beiden Zeilen Bedarfseinträge dar, die nicht mit Angebotseinträgen abgeglichen werden können. Was hier also übrig bleibt, ist, die DemandID, SupplyID und TradeQuantity der Ergebnispaare zu berechnen und die Einträge herauszufiltern, die nicht abgeglichen werden können.
Die Logik, die das Ergebnis DemandID und SupplyID berechnet, wird im CTE Z wie folgt ausgeführt (unter der Annahme, dass in W durch Ausführen sortiert wird):
- DemandID:wenn DemandID nicht NULL ist, dann DemandID, ansonsten die minimale DemandID beginnend mit der aktuellen Zeile
- SupplyID:wenn SupplyID nicht NULL ist, dann SupplyID, ansonsten die minimale SupplyID beginnend mit der aktuellen Zeile
Hier ist das Ergebnis, das Sie erhalten, wenn Sie Z abfragen und die Zeilen nach Running:
sortierenDemandID SupplyID Running----------- ----------- ----------1 1000 5.0000002 1000 8.0000003 2000 14.0000003 3000 16.0000005 4000 18.0000006 5000 22,0000006 6000 25,0000006 7000 26,0000007 7000 27,0000007 NULL 30,0000008 NULL 32,000000
Die äußere Abfrage filtert Zeilen aus Z heraus, die Einträge einer Art darstellen, die nicht mit Einträgen der anderen Art abgeglichen werden können, indem sichergestellt wird, dass sowohl DemandID als auch SupplyID nicht NULL sind. Die Handelsmenge der Ergebnispaare wird mithilfe einer LAG-Funktion als aktueller laufender Wert abzüglich des vorherigen laufenden Werts berechnet.
Folgendes wird in die Tabelle #MyPairings geschrieben, was das gewünschte Ergebnis ist:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Der Plan für diese Lösung ist in Abbildung 1 dargestellt.
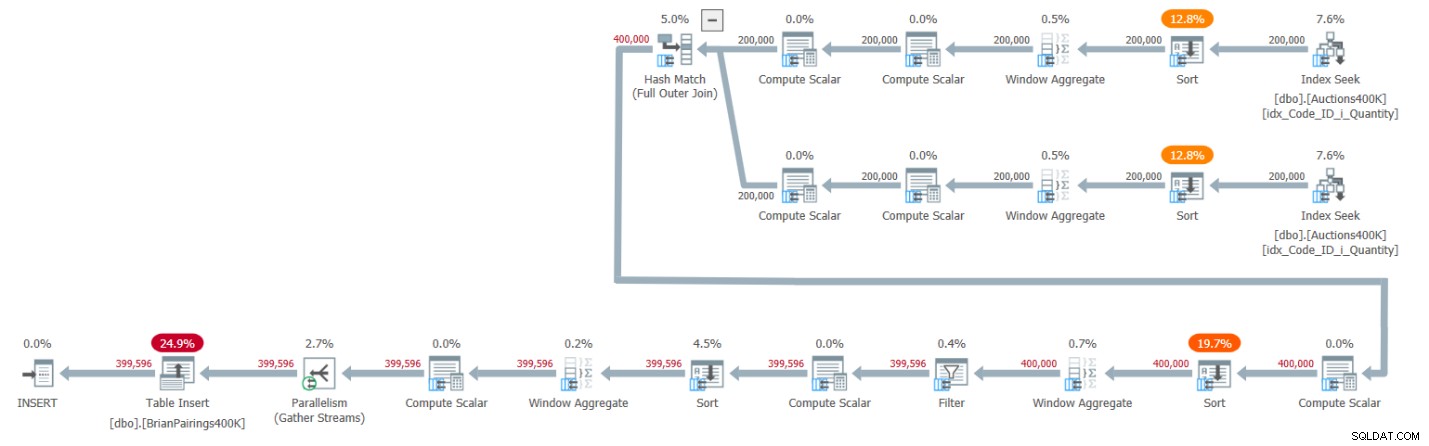 Abbildung 1:Abfrageplan für Brians Lösung
Abbildung 1:Abfrageplan für Brians Lösung
Die beiden obersten Zweige des Plans berechnen die laufenden Bedarfs- und Angebotssummen unter Verwendung eines Window-Aggregate-Operators im Stapelmodus, jeweils nachdem die entsprechenden Einträge aus dem unterstützenden Index abgerufen wurden. Wie ich in früheren Artikeln dieser Serie erklärt habe, sollten Sie denken, dass explizite Sort-Operatoren nicht erforderlich sein sollten, da der Index bereits die Zeilen so geordnet hat, wie es die Window Aggregate-Operatoren benötigen. Aber SQL Server unterstützt derzeit keine effiziente Kombination von parallelen reihenfolgeerhaltenden Indexoperationen vor einem parallelen Window Aggregate-Operator im Batch-Modus, daher wird jedem der parallelen Window Aggregate-Operatoren ein expliziter paralleler Sort-Operator vorangestellt. P>
Der Plan verwendet einen Hash-Join im Stapelmodus, um den vollständigen äußeren Join zu verarbeiten. Der Plan verwendet außerdem zwei zusätzliche Window Aggregate-Operatoren im Stapelmodus, denen explizite Sort-Operatoren vorangestellt sind, um die MIN- und LAG-Fensterfunktionen zu berechnen.
Das ist ein ziemlich effizienter Plan!
Hier sind die Laufzeiten, die ich für diese Lösung bei Eingabegrößen von 100.000 bis 400.000 Zeilen in Sekunden erhalten habe:
100K:0,368200K:0,845300K:1,255400K:1,315
Itziks Lösung
Die nächste Lösung für die Herausforderung ist einer meiner Versuche, sie zu lösen. Hier ist der vollständige Lösungscode:
ABFALLTABELLE, WENN VORHANDEN #MyPairings; WITH C1 AS( SELECT *, SUM(Quantity) OVER(PARTITION BY Code ORDER BY ID ROWS UNBOUNDED PRECEDING) AS SumMenge FROM dbo.Auctions),C2 AS( SELECT *, SUM(Menge * CASE Code WHEN 'D' THEN -1 WHEN 'S' THEN 1 END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS StockLevel, LAG(SumMenge, 1, 0.0) OVER(ORDER BY SumMenge, Code) AS PrevSumQty, MAX(CASE WHEN Code ='D' THEN ID END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS PrevDemandID, MAX(CASE WHEN Code ='S' THEN ID END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS PrevSupplyID, MIN(CASE WHEN Code ='D' THEN ID END) OVER(ORDER BY SumQty, Code ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS NextDemandID, MIN(CASE WHEN Code ='S' THEN ID END) OVER(ORDER BY SumQty, Code ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS NextSupplyID FROM C1),C3 AS( SELECT *, CASE Code WHEN 'D ' THEN ID WHEN 'S' THEN CASE WHEN StockLevel> 0 THEN NextDemandID ELSE PrevDemandID END END AS DemandID, CASE Code WHEN 'S' THEN ID WHEN 'D' THEN CASE WHEN StockLevel <=0 THEN NextSupplyID ELSE PrevSupplyID END END AS SupplyID, SumQty - PrevSumQty AS TradeQuantity FROM C2)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM C3WHERE TradeQuantity> 0.0 AND DemandID IS NOT NULL AND SupplyID IS NOT NULL;
Der CTE C1 fragt die Auktionstabelle ab und verwendet eine Fensterfunktion, um die laufenden Gesamtbedarfs- und Angebotsmengen zu berechnen, wobei die Ergebnisspalte SumQty aufgerufen wird.
Der CTE C2 fragt C1 ab und berechnet eine Reihe von Attributen unter Verwendung von Fensterfunktionen basierend auf der SumQty- und Code-Reihenfolge:
- StockLevel:Der aktuelle Lagerbestand nach der Bearbeitung jedes Eintrags. Dies wird berechnet, indem den Bedarfsmengen ein negatives Vorzeichen und den Liefermengen ein positives Vorzeichen zugewiesen wird und diese Mengen bis einschließlich des aktuellen Eintrags summiert werden.
- PrevSumQty:SumQty-Wert der vorherigen Zeile.
- PrevDemandID:Letzte Anforderungs-ID, die nicht NULL ist.
- PrevSupplyID:Letzte Angebots-ID, die nicht NULL ist.
- NextDemandID:Nächste Anforderungs-ID, die nicht NULL ist.
- NextSupplyID:Nächste Angebots-ID, die nicht NULL ist.
Hier ist der Inhalt von C2, geordnet nach SumQty und Code:
ID-Code Menge SumQty StockLevel PrevSumQty PrevDemandID PrevSupplyID NextDemandID NextSupplyID----- ---- --------- ---------- --------- -- ----------- ------------ ------------ ------------ - . D 8.000000 16.000000 -2.000000 14.000000 3 2000 3 30003000 S 2.000000 16.000000 0.000000 16.000000 3 3000 5 30005 D 2.000000 18.000000 -2.000000 16.000000 5 3000 5 40004000 S 2.000000 18.000000 0.000000 18.000000 5 4000 6 40005000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 50006000 S 3.000000 25.000000 7.000000 22.000000 5 6000 6 60006 D 8.000000 26.000000 -1.000000 25.000000 6 6000 6 70007000 S 2.000000 27.000000 1.000000 26.000000 6 7000 7 70007 D 4.000000 30.000000 -3.000000 27.000000 7 7000 7 NULL8 D 2.000000 32.000000 -5.000000 30.000000 8 7000 8 NULL
Der CTE C3 fragt C2 ab und berechnet die Ergebnispaare DemandID, SupplyID und TradeQuantity, bevor er einige überflüssige Zeilen entfernt.
Die Ergebnisspalte C3.DemandID wird wie folgt berechnet:
- Wenn der aktuelle Eintrag ein Bedarfseintrag ist, gebe NachfrageID zurück.
- Wenn der aktuelle Eintrag ein Angebotseintrag ist und der aktuelle Lagerbestand positiv ist, wird NextDemandID zurückgegeben.
- Wenn der aktuelle Eintrag ein Vorratseintrag ist und der aktuelle Lagerbestand nicht positiv ist, wird PrevDemandID zurückgegeben.
Die Ergebnisspalte C3.SupplyID wird wie folgt berechnet:
- Wenn der aktuelle Eintrag ein Versorgungseintrag ist, Liefer-ID zurückgeben.
- Wenn der aktuelle Eintrag ein Bedarfseintrag ist und der aktuelle Lagerbestand nicht positiv ist, wird NextSupplyID zurückgegeben.
- Wenn der aktuelle Eintrag ein Bedarfseintrag ist und der aktuelle Lagerbestand positiv ist, wird PrevSupplyID zurückgegeben.
Das Ergebnis TradeQuantity wird als SumQty der aktuellen Zeile minus PrevSumQty berechnet.
Hier sind die Inhalte der Spalten, die für das Ergebnis von C3 relevant sind:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000002 1000 0.0000003 2000 6.0000003 3000 2.0000003 3000 0,0000005 4000 2.0000005 4000 0,0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 NULL 3.0000008 NULL 2.000000
Was der äußeren Abfrage noch übrig bleibt, ist, überflüssige Zeilen aus C3 herauszufiltern. Dazu gehören zwei Fälle:
- Wenn die laufenden Summen beider Arten gleich sind, hat der Angebotseintrag eine Handelsmenge von Null. Denken Sie daran, dass die Bestellung auf SumMenge und Code basiert. Wenn also die laufenden Summen gleich sind, erscheint der Bedarfseintrag vor dem Angebotseintrag.
- Nachfolgende Einträge einer Art, die nicht mit Einträgen der anderen Art abgeglichen werden können. Solche Einträge werden durch Zeilen in C3 dargestellt, in denen entweder die DemandID NULL ist oder die SupplyID NULL ist.
Der Plan für diese Lösung ist in Abbildung 2 dargestellt.
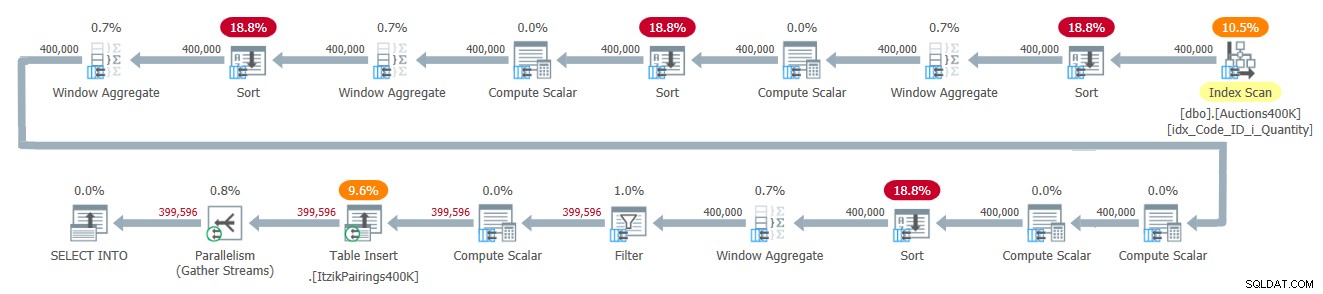 Abbildung 2:Abfrageplan für Itziks Lösung
Abbildung 2:Abfrageplan für Itziks Lösung
Der Plan wendet einen Durchlauf auf die Eingabedaten an und verwendet vier Window Aggregate-Operatoren im Stapelmodus, um die verschiedenen Fensterberechnungen zu verarbeiten. Allen Window Aggregate-Operatoren gehen explizite Sort-Operatoren voraus, obwohl hier nur zwei davon unvermeidlich sind. Die anderen beiden haben mit der aktuellen Implementierung des parallelen Batchmodus-Operators Window Aggregate zu tun, der sich nicht auf eine parallele reihenfolgeerhaltende Eingabe verlassen kann. Eine einfache Möglichkeit, um zu sehen, welche Sort-Operatoren auf diesen Grund zurückzuführen sind, besteht darin, einen seriellen Plan zu erzwingen und zu sehen, welche Sort-Operatoren verschwinden. Wenn ich mit dieser Lösung einen seriellen Plan erzwinge, verschwinden der erste und der dritte Sort-Operator.
Hier sind die Laufzeiten in Sekunden, die ich für diese Lösung erhalten habe:
100K:0,246200K:0,427300K:0,616400K:0,841>
Ians Lösung
Ians Lösung ist kurz und effizient. Hier ist der vollständige Lösungscode:
ABFALLTABELLE, WENN VORHANDEN #MyPairings; WITH A AS ( SELECT *, SUM(Menge) OVER (PARTITION BY Code ORDER BY ID ROWS UNBOUNDED PRECEDING) AS CumulativeQuantity FROM dbo.Auctions), B AS ( SELECT CumulativeQuantity, CumulativeQuantity - LAG(CumulativeQuantity, 1, 0) OVER (ORDER BY CumulativeQuantity) AS TradeQuantity, MAX(CASE WHEN Code ='D' THEN ID END) AS DemandID, MAX(CASE WHEN Code ='S' THEN ID END) AS SupplyID FROM A GROUP BY CumulativeQuantity, ID/ID -- falsche Gruppierung um die Zeilenschätzung zu verbessern -- (Zeilenanzahl von Auktionen anstelle von 2 Zeilen)), C AS ( -- füllen Sie NULLen mit dem nächsten Angebot / Nachfrage aus -- FIRST_VALUE (ID) IGNORE NULLS OVER ... -- wäre besser, aber Dies funktioniert, weil die IDs in der Reihenfolge CumulativeQuantity sind. SELECT MIN(DemandID) OVER (ORDER BY CumulativeQuantity ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID, MIN(SupplyID) OVER (ORDER BY CumulativeQ Menge ZEILEN ZWISCHEN DER AKTUELLEN REIHE UND UNBEGRENZT FOLGEND) AS SupplyID, TradeQuantity FROM B)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM CWHERE SupplyID IS NOT NULL -- kürze unerfüllte Anforderungen UND DemandID IS NOT NULL; -- Schneiden Sie unbenutzte Vorräte ab
Der Code im CTE A fragt die Tabelle Auctions ab und berechnet die laufenden Gesamtnachfrage- und Angebotsmengen unter Verwendung einer Fensterfunktion, wobei die Ergebnisspalte CumulativeQuantity.
genannt wirdDer Code in CTE B fragt CTE A ab und gruppiert die Zeilen nach CumulativeQuantity. Diese Gruppierung erzielt einen ähnlichen Effekt wie Brians Outer Join, basierend auf den laufenden Summen von Nachfrage und Angebot. Ian fügte dem Gruppierungssatz auch den Dummy-Ausdruck ID/ID hinzu, um die ursprüngliche Kardinalität der Gruppierung unter Schätzung zu verbessern. Auf meiner Maschine führte dies auch dazu, dass ein paralleler Plan anstelle eines seriellen Plans verwendet wurde.
In der SELECT-Liste berechnet der Code DemandID und SupplyID, indem er die ID des jeweiligen Eintragstyps in der Gruppe unter Verwendung des MAX-Aggregats und eines CASE-Ausdrucks abruft. Wenn die ID in der Gruppe nicht vorhanden ist, ist das Ergebnis NULL. Der Code berechnet auch eine Ergebnisspalte namens TradeQuantity als aktuelle kumulierte Menge minus der vorherigen, die mit der LAG-Fensterfunktion abgerufen wird.
Hier sind die Inhalte von B:
Kumulierte Menge TradeQuantity DemandId SupplyId------------------- -------------- --------- - .>Der Code im CTE C fragt dann den CTE B ab und füllt NULL-Nachfrage- und Angebots-IDs mit den nächsten Nicht-NULL-Nachfrage- und Angebots-IDs unter Verwendung der MIN-Fensterfunktion mit dem Rahmen ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING.
Hier ist der Inhalt von C:
DemandID SupplyID TradeQuantity --------- --------- --------------1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2,000000 6 5000 4,000000 6 6000 3,000000 6 7000 1,000000 7 7000 1,000000 7 NULL 3,000000 8 NULL 2,000000Der letzte Schritt, der von der äußeren Abfrage an C behandelt wird, besteht darin, Einträge einer Art zu entfernen, die nicht mit Einträgen der anderen Art abgeglichen werden können. Dazu werden Zeilen herausgefiltert, in denen entweder SupplyID NULL oder DemandID NULL ist.
Der Plan für diese Lösung ist in Abbildung 3 dargestellt.
Abbildung 3:Abfrageplan für Ians Lösung
Dieser Plan führt einen Scan der Eingabedaten durch und verwendet drei parallele Fensteraggregatoperatoren im Stapelmodus, um die verschiedenen Fensterfunktionen zu berechnen, denen alle parallele Sortieroperatoren vorangehen. Zwei davon sind unvermeidlich, wie Sie überprüfen können, indem Sie einen seriellen Plan erzwingen. Der Plan verwendet auch einen Hash-Aggregat-Operator, um die Gruppierung und Aggregation im CTE B zu handhaben.
Hier sind die Laufzeiten in Sekunden, die ich für diese Lösung erhalten habe:
100K:0,214200K:0,363300K:0,546400K:0,701
Peter Larssons Lösung
Die Lösung von Peter Larsson ist erstaunlich kurz, knackig und hocheffizient. Hier ist Peters vollständiger Lösungscode:
ABFALLTABELLE, WENN VORHANDEN #MyPairings; WITH cteSource(ID, Code, RunningQuantity)AS( SELECT ID, Code, SUM(Menge) OVER (PARTITION BY Code ORDER BY ID) AS RunningQuantity FROM dbo.Auctions)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM ( SELECT MIN(CASE WHEN Code ='D' THEN ID ELSE 2147483648 END) OVER (ORDER BY RunningQuantity, Code ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID, MIN(CASE WHEN Code ='S' THEN ID ELSE 2147483648 END) OVER (ORDER BY RunningQuantity, Codieren Sie ZEILEN ZWISCHEN DER AKTUELLEN REIHE UND UNBEGRENZTEN FOLGENDEN) AS SupplyID, RunningQuantity - COALESCE(LAG(RunningQuantity) OVER (ORDER BY RunningQuantity, Code), 0.0) AS TradeQuantity FROM cteSource ) AS dWHERE DemandID <2147483648 AND SupplyID <2147483648 AND TradeQuantity> 0.0;CTE cteSource fragt die Auktionstabelle ab und verwendet eine Fensterfunktion, um die laufenden Gesamtbedarfs- und Angebotsmengen zu berechnen, wobei die Ergebnisspalte RunningQuantity aufgerufen wird.
Der Code, der die abgeleitete Tabelle d definiert, fragt cteSource ab und berechnet die Ergebnispaare DemandID, SupplyID und TradeQuantity, bevor einige überflüssige Zeilen entfernt werden. Alle in diesen Berechnungen verwendeten Fensterfunktionen basieren auf der RunningQuantity- und Code-Reihenfolge.
Die Ergebnisspalte d.DemandID wird als minimale Bedarfs-ID berechnet, beginnend mit dem aktuellen oder 2147483648, wenn keine gefunden wird.
Die Ergebnisspalte d.SupplyID wird als minimale Angebots-ID berechnet, beginnend mit dem aktuellen oder 2147483648, wenn keine gefunden wird.
Das Ergebnis TradeQuantity wird als RunningQuantity-Wert der aktuellen Zeile minus dem RunningQuantity-Wert der vorherigen Zeile berechnet.
Hier sind die Inhalte von d:
DemandID SupplyID TradeQuantity--------- ----------- --------------1 1000 5.0000002 1000 3.0000003 1000 0.0000003 2000 6.0000003 3000 2.0000005 3000 0,0000005 4000 2.0000006 4000 0,0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 2147483648 3.0000008 2147483648 2.00000000Was der äußeren Abfrage noch übrig bleibt, ist, überflüssige Zeilen aus d herauszufiltern. Das sind Fälle, in denen die Handelsmenge Null ist, oder Einträge der einen Art, die nicht mit Einträgen der anderen Art (mit ID 2147483648) abgeglichen werden können.
Der Plan für diese Lösung ist in Abbildung 4 dargestellt.
Abbildung 4:Abfrageplan für Peters Lösung
Wie Ians Plan basiert Peters Plan auf einem Scan der Eingabedaten und verwendet drei parallele Fensteraggregatoperatoren im Stapelmodus, um die verschiedenen Fensterfunktionen zu berechnen, denen alle parallele Sortieroperatoren vorangehen. Zwei davon sind unvermeidlich, wie Sie überprüfen können, indem Sie einen seriellen Plan erzwingen. In Peters Plan ist kein gruppierter Aggregatoperator wie in Ians Plan erforderlich.
Peters entscheidende Erkenntnis, die eine so kurze Lösung ermöglichte, war die Erkenntnis, dass für einen relevanten Eintrag einer der beiden Arten die passende ID der anderen Art immer später erscheint (basierend auf RunningQuantity und Code-Reihenfolge). Nachdem ich Peters Lösung gesehen hatte, fühlte es sich wirklich so an, als hätte ich die Dinge in meiner zu kompliziert gemacht!
Hier sind die Laufzeiten in Sekunden, die ich für diese Lösung erhalten habe:
100K:0,197200K:0,412300K:0,558400K:0,696
Lösung von Paul White
Unsere letzte Lösung wurde von Paul White entwickelt. Hier ist der vollständige Lösungscode:
ABFALLTABELLE, WENN VORHANDEN #MyPairings; CREATE TABLE #MyPairings( DemandID integer NOT NULL, SupplyID integer NOT NULL, TradeQuantity decimal(19, 6) NOT NULL);GO INSERT #MyPairings WITH (TABLOCK)( DemandID, SupplyID, TradeQuantity)SELECT Q3.DemandID, Q3.SupplyID, Q3.TradeQuantityFROM ( SELECT Q2.DemandID, Q2.SupplyID, TradeQuantity =-- Intervallüberlappung CASE WHEN Q2.Code ='S' THEN CASE WHEN Q2.CumDemand>=Q2.IntEnd THEN Q2.IntLength WHEN Q2.CumDemand> Q2. IntStart THEN Q2.CumDemand – Q2.IntStart ELSE 0.0 END WHEN Q2.Code ='D' THEN CASE WENN Q2.CumSupply>=Q2.IntEnd DANN Q2.IntLength WENN Q2.CumSupply> Q2.IntStart DANN Q2.CumSupply - Q2. IntStart ELSE 0.0 END END FROM ( SELECT Q1.Code, Q1.IntStart, Q1.IntEnd, Q1.IntLength, DemandID =MAX(IIF(Q1.Code ='D', Q1.ID, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), SupplyID =MAX(IIF(Q1.Code ='S', Q1.ID, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), CumSupply =SUM(IIF(Q1.Code ='S', Q1.IntLength, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), CumDemand =SUM(IIF(Q1.Code ='D', Q1.IntLength, 0)) OVER ( ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING) FROM ( -- Bedarfsintervalle SELECT A.ID, A.Code, IntStart =SUM(A.Quantity) OVER ( ORDER BY A.ID ROWS UNBOUNDED PRECEDING) - A. Menge, IntEnd =SUM(A.Quantity) OVER ( ORDER BY A.ID ROWS UNBOUNDED PRECEDING), IntLength =A.Quantity FROM dbo.Auctions AS A WHERE A.Code ='D' UNION ALL -- Versorgungsintervalle SELECT A.ID, A.Code, IntStart =SUM(A.Quantity) OVER (ORDER BY A.ID ROWS UNBOUNDED PRECEDING) – A.Quantity, IntEnd =SUM(A.Quantity) OVER (ORDER BY A.ID ROWS UNBOUNDED PRECEDING), IntLength =A.Quantity FROM dbo.Auctions AS A WHERE A.Code ='S' ) AS Q1 ) AS Q2) AS Q3WHERE Q3.TradeQuantity> 0;Der Code, der die abgeleitete Tabelle Q1 definiert, verwendet zwei separate Abfragen, um Bedarfs- und Angebotsintervalle basierend auf laufenden Summen zu berechnen, und vereinheitlicht die beiden. Für jedes Intervall berechnet der Code den Start (IntStart), das Ende (IntEnd) und die Länge (IntLength). Hier sind die Inhalte von Q1, geordnet nach IntStart und ID:
ID-Code IntStart IntEnd IntLength ----- ---- ---------- ---------- ----------1 D 0.000000 5.000000 5.0000001000 S 0.000000 8.000000 8.0000002 D 5.000000 8.000000 3.0000003 D 8.000000 16.000000 8.0000002000 S 8.000000 14.000000 6.0000003000 S 14.000000 16.000000 2.0000005 D 16.000000 18.000000 2.0000004000 S 16.000000 18.000000 2.0000006 D 18.000000 26.000000 8.0000005000 S 18.000000 22.000000 4.0000006000 S 22.000000 25.000000 3.0000007000 S 25.000000 27.000000 2.0000007 D 26.000000 30.000000 4.0000008 D 30.000000 32.000000 2.000000Der Code, der die abgeleitete Tabelle Q2 definiert, fragt Q1 ab und berechnet Ergebnisspalten namens DemandID, SupplyID, CumSupply und CumDemand. Alle von diesem Code verwendeten Fensterfunktionen basieren auf der IntStart- und ID-Reihenfolge und dem Frame ROWS UNBOUNDED PRECEDING (alle Zeilen bis zur aktuellen).
DemandID ist die maximale Anforderungs-ID bis zur aktuellen Zeile oder 0, wenn keine vorhanden ist.
SupplyID ist die maximale Angebots-ID bis zur aktuellen Zeile oder 0, wenn keine vorhanden ist.
CumSupply ist die kumulierte Liefermenge (Lieferintervalllänge) bis zur aktuellen Zeile.
CumDemand sind die kumulierten Bedarfsmengen (Bedarfsintervalllängen) bis zur aktuellen Zeile.
Hier sind die Inhalte von Q2:
Code IntStart IntEnd IntLength DemandID SupplyID CumSupply CumDemand---- ---------- ---------- ---------- ----- ---- --------- ---------- ----------D 0,000000 5,000000 5,000000 1 0 0,000000 5,000000S 0,000000 8,000000 8,000000 1 1000 8,000000 5,000000D 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000D 18.000000 26.000000 8.000000 6 4000 18.000000 26.000000S 18.000000 22.000000 4.000000 6 5000 22.000000 26.000000S 22.000000 25.000000 3.000000 6 6 25.000000 26.000000S 25.000000 27.000000 2.000000 6 7000 27.000000 26.000000D 26.000000 30.000000 4.000000 7 7000 27.000000 30.000000D 30.000000 32.000000 2.000000 8 7000 27.000000 32.000000Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K:0.187200K:0.331300K:0.369400K:0.425These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
Schlussfolgerung
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]



