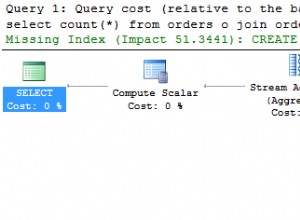
Datenbanken werden unterschiedlich gestaltet. Meistens können wir „Schulbeispiele“ verwenden:Normalisieren Sie die Datenbank und alles wird gut funktionieren. Aber es gibt Situationen, die einen anderen Ansatz erfordern. Wir können Verweise entfernen, um mehr Flexibilität zu erhalten. Aber was ist, wenn wir die Leistung verbessern müssen, wenn alles nach Vorschrift gemacht wurde? In diesem Fall ist die Denormalisierung eine Technik, die wir in Betracht ziehen sollten. In diesem Artikel besprechen wir die Vor- und Nachteile der Denormalisierung und welche Situationen sie rechtfertigen können.
Was ist Denormalisierung?
Denormalisierung ist eine Strategie, die für eine zuvor normalisierte Datenbank verwendet wird, um die Leistung zu steigern. Die Idee dahinter ist, redundante Daten dort hinzuzufügen, wo wir glauben, dass sie uns am meisten helfen. Wir können zusätzliche Attribute in einer bestehenden Tabelle verwenden, neue Tabellen hinzufügen oder sogar Instanzen bestehender Tabellen erstellen. Das übliche Ziel besteht darin, die Laufzeit ausgewählter Abfragen zu verkürzen, indem Daten für die Abfragen besser zugänglich gemacht werden oder zusammengefasste Berichte in separaten Tabellen generiert werden. Dieser Prozess kann einige neue Probleme mit sich bringen, und wir werden sie später besprechen.
Eine normalisierte Datenbank ist der Ausgangspunkt für den Denormalisierungsprozess. Es ist wichtig, zwischen der nicht normalisierten Datenbank und der zuerst normalisierten und später denormalisierten Datenbank zu unterscheiden. Der zweite ist in Ordnung; Die erste ist oft das Ergebnis eines schlechten Datenbankdesigns oder eines Mangels an Wissen.
Beispiel:Ein normalisiertes Modell für ein sehr einfaches CRM
Das folgende Modell dient als unser Beispiel:
Werfen wir einen kurzen Blick auf die Tabellen:
- Das
user_accountTabelle speichert Daten über Benutzer, die sich bei unserer Anwendung anmelden (zur Vereinfachung des Modells sind Rollen und Benutzerrechte davon ausgeschlossen). - Der
clientTabelle enthält einige grundlegende Daten über unsere Kunden. - Das
productTabelle listet Produkte auf, die unseren Kunden angeboten werden. - Die
taskTabelle enthält alle Aufgaben, die wir erstellt haben. Sie können sich jede Aufgabe als eine Reihe verwandter Aktionen gegenüber Kunden vorstellen. Jede Aufgabe hat ihre zugehörigen Anrufe, Besprechungen und Listen mit angebotenen und verkauften Produkten. - Der
callundmeetingTabellen speichern Daten über alle Anrufe und Besprechungen und verknüpfen sie mit Aufgaben und Benutzern. - Die Wörterbücher
task_outcome,meeting_outcomeundcall_outcomeenthalten alle möglichen Optionen für den Endzustand einer Aufgabe, Besprechung oder eines Anrufs. - Der
product_offeredspeichert eine Liste aller Produkte, die Kunden bei bestimmten Aufgaben angeboten wurden, währendproduct_soldenthält eine Liste aller Produkte, die der Kunde tatsächlich gekauft hat. - Der
supply_orderTabelle speichert Daten über alle Bestellungen, die wir aufgegeben haben, und denproducts_on_orderTabelle listet Produkte und ihre Menge für bestimmte Bestellungen auf. - Die
writeoffTabelle ist eine Liste von Produkten, die aufgrund von Unfällen oder ähnlichem (z. B. zerbrochene Spiegel) abgeschrieben wurden.
Die Datenbank ist vereinfacht, aber perfekt normalisiert. Sie werden keine Redundanzen finden und es sollte die Arbeit erledigen. Wir sollten auf keinen Fall Performance-Probleme bekommen, solange wir mit einer relativ geringen Datenmenge arbeiten.
Wann und warum Denormalisierung verwendet werden sollte
Wie bei fast allem müssen Sie sicher sein, warum Sie die Denormalisierung anwenden möchten. Sie müssen auch sicher sein, dass der Gewinn aus der Verwendung den Schaden überwiegt. Es gibt ein paar Situationen, in denen Sie unbedingt an Denormalisierung denken sollten:
- Verlauf pflegen: Daten können sich im Laufe der Zeit ändern, und wir müssen Werte speichern, die gültig waren, als ein Datensatz erstellt wurde. Welche Veränderungen meinen wir? Nun, der Vor- und Nachname einer Person kann sich ändern; Ein Kunde kann auch seinen Firmennamen oder andere Daten ändern. Aufgabendetails sollten Werte enthalten, die zum Zeitpunkt der Erstellung einer Aufgabe aktuell waren. Wir könnten vergangene Daten nicht korrekt wiederherstellen, wenn dies nicht geschehen wäre. Wir könnten dieses Problem lösen, indem wir eine Tabelle hinzufügen, die den Verlauf dieser Änderungen enthält. In diesem Fall würde eine Auswahlabfrage, die die Aufgabe und einen gültigen Clientnamen zurückgibt, komplizierter. Vielleicht ist ein zusätzlicher Tisch nicht die beste Lösung.
- Verbesserung der Abfrageleistung: Einige der Abfragen verwenden möglicherweise mehrere Tabellen, um auf Daten zuzugreifen, die wir häufig benötigen. Stellen Sie sich eine Situation vor, in der wir 10 Tische zusammenstellen müssten, um den Namen des Kunden und die an ihn verkauften Produkte zurückzugeben. Einige Tabellen entlang des Pfads können auch große Datenmengen enthalten. In diesem Fall wäre es vielleicht sinnvoll, eine
client_idhinzuzufügen direkt demproducts_soldTabelle. - Berichterstellung beschleunigen: Bestimmte Statistiken benötigen wir sehr häufig. Sie aus Live-Daten zu erstellen, ist ziemlich zeitaufwändig und kann die Gesamtleistung des Systems beeinträchtigen. Nehmen wir an, wir möchten Kundenverkäufe über bestimmte Jahre für einige oder alle Kunden verfolgen. Das Generieren solcher Berichte aus Live-Daten würde fast die gesamte Datenbank „durchwühlen“ und sie stark verlangsamen. Und was passiert, wenn wir diese Statistik oft verwenden?
- Berechnung häufig benötigter Werte im Voraus: Wir möchten einige Werte fertig berechnet haben, damit wir sie nicht in Echtzeit generieren müssen.
Es ist wichtig darauf hinzuweisen, dass Sie keine Denormalisierung verwenden müssen, wenn keine Leistungsprobleme vorliegen in der Bewerbung. Aber wenn Sie bemerken, dass das System langsamer wird – oder wenn Sie sich bewusst sind, dass dies passieren könnte – dann sollten Sie über die Anwendung dieser Technik nachdenken. Bevor Sie damit beginnen, sollten Sie jedoch andere Optionen wie Abfrageoptimierung und ordnungsgemäße Indizierung in Betracht ziehen. Sie können die Denormalisierung auch verwenden, wenn Sie bereits in der Produktion sind, aber es ist besser, Probleme in der Entwicklungsphase zu lösen.
Was sind die Nachteile der Denormalisierung?
Offensichtlich ist der größte Vorteil des Denormalisierungsprozesses die gesteigerte Leistung. Aber wir müssen dafür einen Preis zahlen, und dieser Preis kann bestehen aus:
- Speicherplatz: Dies ist zu erwarten, da wir doppelte Daten haben werden.
- Datenanomalien: Wir müssen uns sehr bewusst sein, dass Daten jetzt an mehr als einer Stelle geändert werden können. Wir müssen alle doppelten Daten entsprechend anpassen. Das gilt auch für berechnete Werte und Berichte. Wir können dies erreichen, indem wir Trigger, Transaktionen und/oder Prozeduren für alle Vorgänge verwenden, die zusammen ausgeführt werden müssen.
- Dokumentation: Wir müssen jede Denormalisierungsregel, die wir angewendet haben, ordnungsgemäß dokumentieren. Wenn wir das Datenbankdesign später ändern, müssen wir uns alle unsere Ausnahmen ansehen und erneut berücksichtigen. Vielleicht brauchen wir sie nicht mehr, weil wir das Problem gelöst haben. Oder vielleicht müssen wir bestehende Denormalisierungsregeln ergänzen. (Zum Beispiel:Wir haben der Client-Tabelle ein neues Attribut hinzugefügt und möchten seinen Verlaufswert zusammen mit allem speichern, was wir bereits speichern. Dazu müssen wir bestehende Denormalisierungsregeln ändern).
- Andere Vorgänge verlangsamen: Wir können davon ausgehen, dass wir das Einfügen, Ändern und Löschen von Daten verlangsamen werden. Wenn diese Operationen relativ selten vorkommen, könnte dies ein Vorteil sein. Grundsätzlich würden wir eine langsame Auswahl in eine größere Anzahl langsamerer Einfüge-/Aktualisierungs-/Löschabfragen aufteilen. Während eine sehr komplexe Auswahlabfrage technisch gesehen das gesamte System merklich verlangsamen könnte, sollte die Verlangsamung mehrerer „kleinerer“ Operationen die Benutzerfreundlichkeit unserer Anwendung nicht beeinträchtigen.
- Mehr Codierung: Die Regeln 2 und 3 erfordern zusätzliche Codierung, vereinfachen aber gleichzeitig einige ausgewählte Abfragen erheblich. Wenn wir eine vorhandene Datenbank denormalisieren, müssen wir diese ausgewählten Abfragen ändern, um die Vorteile unserer Arbeit nutzen zu können. Wir müssen auch Werte in neu hinzugefügten Attributen für vorhandene Datensätze aktualisieren. Auch dies erfordert etwas mehr Codierung.
Das Beispielmodell, denormalisiert
Im folgenden Modell habe ich einige der oben genannten Denormalisierungsregeln angewendet. Die rosafarbenen Tische wurden modifiziert, während der hellblaue Tisch komplett neu ist.
Welche Änderungen werden angewendet und warum?

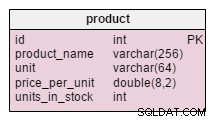
Die einzige Änderung am product Tabelle ist die Hinzufügung von units_in_stock Attribut. In einem normalisierten Modell könnten wir diese Daten als bestellte Einheiten – verkaufte Einheiten – (angebotene Einheiten) – abgeschriebene Einheiten berechnen . Wir würden die Berechnung jedes Mal wiederholen, wenn ein Kunde nach diesem Produkt fragt, was extrem zeitaufwändig wäre. Stattdessen berechnen wir den Wert im Voraus; Wenn ein Kunde uns fragt, haben wir es bereit. Dies vereinfacht natürlich die Auswahlabfrage erheblich. Andererseits die units_in_stock -Attribut muss nach jedem Einfügen, Aktualisieren oder Löschen im products_on_order , writeoff , product_offered und product_sold Tabellen.
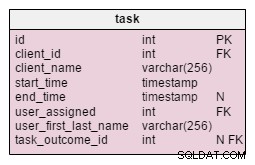
In der geänderten task Tabelle finden wir zwei neue Attribute:client_name und user_first_last_name . Beide speichern Werte, wenn die Aufgabe erstellt wurde. Der Grund dafür ist, dass sich diese beiden Werte im Laufe der Zeit ändern können. Wir bewahren auch einen Fremdschlüssel auf, der sie mit der ursprünglichen Kunden- und Benutzer-ID in Beziehung setzt. Es gibt noch weitere Werte, die wir speichern möchten, wie z. B. Kundenadresse, Umsatzsteuer-Identifikationsnummer usw.




Der denormalisierte product_offered Tabelle hat zwei neue Attribute, price_per_unit und price . Der price_per_unit Das Attribut wird gespeichert, weil wir den tatsächlichen Preis speichern müssen, als das Produkt angeboten wurde . Das normalisierte Modell würde nur seinen aktuellen Zustand anzeigen, wenn sich also der Produktpreis ändert, würden sich auch unsere „historischen“ Preise ändern. Unsere Änderung lässt die Datenbank nicht nur schneller laufen, sondern auch besser funktionieren. Der price -Attribut ist der berechnete Wert units_sold * price_per_unit . Ich habe es hier hinzugefügt, um diese Berechnung nicht jedes Mal durchführen zu müssen, wenn wir uns eine Liste der angebotenen Produkte ansehen möchten. Es ist ein geringer Preis, aber es verbessert die Leistung.
Die am product_sold Tabelle sind sehr ähnlich. Die Tabellenstruktur ist dieselbe, speichert jedoch eine Liste der verkauften Artikel.
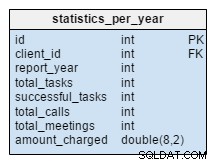
Die statistics_per_year Tabelle ist völlig neu für unser Modell. Wir sollten sie als denormalisierte Tabelle betrachten, da alle ihre Daten aus den anderen Tabellen berechnet werden können. Die Idee hinter dieser Tabelle ist, die Anzahl der Aufgaben, erfolgreichen Aufgaben, Besprechungen und Anrufe im Zusammenhang mit einem bestimmten Kunden zu speichern. Es verarbeitet auch die Gesamtsumme, die pro Jahr berechnet wird. Nach dem Einfügen, Aktualisieren oder Löschen von Elementen in der task , meeting , call und product_sold Tabellen, sollten wir die Daten dieser Tabelle für diesen Kunden und das entsprechende Jahr neu berechnen. Wir können davon ausgehen, dass wir Änderungen hauptsächlich nur für das laufende Jahr haben werden. Berichte für frühere Jahre sollten nicht geändert werden müssen.
Die Werte in dieser Tabelle werden im Voraus berechnet, sodass wir in dem Moment, in dem wir das Berechnungsergebnis benötigen, weniger Zeit und Ressourcen aufwenden. Denken Sie an die Werte, die Sie häufig benötigen. Vielleicht brauchen Sie sie nicht regelmäßig alle und können es riskieren, einige davon live zu berechnen.
Denormalisierung ist ein sehr interessantes und mächtiges Konzept. Obwohl es nicht das erste ist, an das Sie denken sollten, um die Leistung zu verbessern, kann es in manchen Situationen die beste oder sogar die einzige Lösung sein.
Bevor Sie sich für die Verwendung der Denormalisierung entscheiden, vergewissern Sie sich, dass Sie dies möchten. Führen Sie einige Analysen durch und verfolgen Sie die Leistung. Sie werden sich wahrscheinlich für die Denormalisierung entscheiden, nachdem Sie bereits live gegangen sind. Haben Sie keine Angst, es zu verwenden, aber verfolgen Sie Änderungen und Sie sollten keine Probleme haben (d. h. die gefürchteten Datenanomalien).