Im letzten Monat habe ich mit zahlreichen Kunden zusammengearbeitet, die im Zusammenhang mit ihren OLTP-Workloads spaltenseitige implizite Konvertierungsprobleme hatten. Bei zwei Gelegenheiten war der kumulierte Effekt der spaltenseitigen impliziten Konvertierungen die zugrunde liegende Ursache des allgemeinen Leistungsproblems für den überprüften SQL Server, und leider gibt es keine magische Einstellung oder Konfigurationsoption, die wir optimieren können, um die Situation zu verbessern wann dies der Fall ist. Während wir Vorschläge machen können, um andere, weniger hängende Früchte zu beheben, die sich möglicherweise auf die Gesamtleistung auswirken, ist der Effekt der spaltenseitigen impliziten Konvertierungen etwas, das entweder eine Änderung des Schemadesigns zur Behebung oder eine Codeänderung erfordert, um die Spalten- Seitenkonvertierung vollständig gegen das aktuelle Datenbankschema erfolgen.
Implizite Konvertierungen sind das Ergebnis des Datenbankmoduls, der während der Abfrageausführung Werte unterschiedlicher Datentypen vergleicht. Eine Liste der möglichen impliziten Konvertierungen, die innerhalb des Datenbankmoduls auftreten können, finden Sie im Thema Datentypkonvertierung (Datenbankmodul) der Onlinedokumentation. Implizite Konvertierungen erfolgen immer basierend auf der Datentyppriorität für die Datentypen, die während der Operation verglichen werden. Die Rangfolge der Datentypen finden Sie in der Onlinedokumentation zum Thema Rangfolge der Datentypen (Transact-SQL). Ich habe kürzlich über die impliziten Conversions gebloggt, die zu einem Index-Scan führen, und Diagramme bereitgestellt, mit denen auch die problematischsten impliziten Conversions ermittelt werden können.
Einrichten der Tests
Um den Leistungsaufwand zu veranschaulichen, der mit spaltenseitigen impliziten Konvertierungen verbunden ist, die zu einem Indexscan führen, habe ich eine Reihe verschiedener Tests für die AdventureWorks2012-Datenbank ausgeführt, wobei ich die Sales.SalesOrderDetail-Tabelle verwendet habe, um Testtabellen und Datensätze zu erstellen. Die häufigste spaltenseitige implizite Konvertierung, die ich als Berater sehe, tritt auf, wenn der Spaltentyp char oder varchar ist und der Anwendungscode einen Parameter übergibt, der nchar oder nvarchar ist, und nach der char- oder varchar-Spalte filtert. Um diese Art von Szenario zu simulieren, habe ich eine Kopie der Tabelle „SalesOrderDetail“ (mit dem Namen „SalesOrderDetail_ASCII“) erstellt und die Spalte „CarrierTrackingNumber“ von „nvarchar“ in „varchar“ geändert. Außerdem habe ich der ursprünglichen SalesOrderDetail-Tabelle sowie der neuen SalesOrderDetail_ASCII-Tabelle einen Nonclustered-Index für die CarrierTrackingNumber-Spalte hinzugefügt.
USE [AdventureWorks2012]
GO
-- Add CarrierTrackingNumber index to original Sales.SalesOrderDetail table
IF NOT EXISTS
(
SELECT 1 FROM sys.indexes
WHERE [object_id] = OBJECT_ID(N'Sales.SalesOrderDetail')
AND name=N'IX_SalesOrderDetail_CarrierTrackingNumber'
)
BEGIN
CREATE INDEX IX_SalesOrderDetail_CarrierTrackingNumber
ON Sales.SalesOrderDetail (CarrierTrackingNumber);
END
GO
IF OBJECT_ID('Sales.SalesOrderDetail_ASCII') IS NOT NULL
BEGIN
DROP TABLE Sales.SalesOrderDetail_ASCII;
END
GO
CREATE TABLE Sales.SalesOrderDetail_ASCII
(
SalesOrderID int NOT NULL,
SalesOrderDetailID int NOT NULL IDENTITY (1, 1),
CarrierTrackingNumber varchar(25) NULL,
OrderQty smallint NOT NULL,
ProductID int NOT NULL,
SpecialOfferID int NOT NULL,
UnitPrice money NOT NULL,
UnitPriceDiscount money NOT NULL,
LineTotal AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))),
rowguid uniqueidentifier NOT NULL ROWGUIDCOL,
ModifiedDate datetime NOT NULL
);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII ON;
GO
INSERT INTO Sales.SalesOrderDetail_ASCII
(
SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
)
SELECT
SalesOrderID, SalesOrderDetailID, CONVERT(varchar(25), CarrierTrackingNumber),
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
FROM Sales.SalesOrderDetail WITH (HOLDLOCK TABLOCKX);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII OFF;
GO
ALTER TABLE Sales.SalesOrderDetail_ASCII ADD CONSTRAINT
PK_SalesOrderDetail_ASCII_SalesOrderID_SalesOrderDetailID
PRIMARY KEY CLUSTERED (SalesOrderID, SalesOrderDetailID);
CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderDetail_ASCII_rowguid
ON Sales.SalesOrderDetail_ASCII (rowguid);
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_ASCII_ProductID
ON Sales.SalesOrderDetail_ASCII (ProductID);
CREATE INDEX IX_SalesOrderDetail_ASCII_CarrierTrackingNumber
ON Sales.SalesOrderDetail_ASCII (CarrierTrackingNumber);
GO Die neue SalesOrderDetail_ASCII-Tabelle hat 121.317 Zeilen und ist 17,5 MB groß und wird verwendet, um den Overhead einer kleinen Tabelle auszuwerten. Außerdem habe ich mit einer modifizierten Version des Skripts „Enlarging the AdventureWorks Sample Databases“ aus meinem Blog eine zehnmal größere Tabelle erstellt, die 1.334.487 Zeilen enthält und 190 MB groß ist. Der Testserver dafür ist dieselbe 4-vCPU-VM mit 4 GB RAM, auf der Windows Server 2008 R2 und SQL Server 2012 mit Service Pack 1 und kumulativem Update 3 ausgeführt werden, die ich in früheren Artikeln verwendet habe, sodass die Tabellen vollständig in den Arbeitsspeicher passen , wodurch der Festplatten-E/A-Overhead eliminiert wird und die ausgeführten Tests nicht beeinträchtigt werden.
Die Testarbeitslast wurde mithilfe einer Reihe von PowerShell-Skripts generiert, die die Liste der CarrierTrackingNumbers aus der SalesOrderDetail-Tabelle auswählen, um eine ArrayList zu erstellen, und dann zufällig eine CarrierTrackingNumber aus der ArrayList auswählen, um die SalesOrderDetail_ASCII-Tabelle mithilfe eines varchar-Parameters und dann eines nvarchar-Parameters abzufragen, und dann zum Abfragen der SalesOrderDetail-Tabelle mit einem nvarchar-Parameter, um einen Vergleich dafür bereitzustellen, wo die Spalte und der Parameter beide nvarchar sind. Jeder der einzelnen Tests führt die Anweisung 10.000 Mal aus, um den Leistungsaufwand über eine anhaltende Arbeitslast messen zu können.
#No Implicit Conversions
$loop = 10000;
Write-Host "Small table no conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::VarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table no conversion end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table implicit conversions
$loop = 10000;
Write-Host "Small table implicit conversions start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table implicit conversions end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table unicode no implicit conversions
$loop = 10000;
Write-Host "Small table unicode no implicit conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail "
"WHERE CarrierTrackingNumber = @CTNumber;"
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table unicode no implicit conversion end time:"
[DateTime]::Now Eine zweite Reihe von Tests wurde für die Tabellen „SalesOrderDetailEnlarged_ASCII“ und „SalesOrderDetailEnlarged“ mit der gleichen Parametrisierung wie die erste Reihe von Tests ausgeführt, um den Overhead-Unterschied zu zeigen, wenn die Größe der in der Tabelle gespeicherten Daten im Laufe der Zeit zunimmt. Eine abschließende Reihe von Tests wurde auch für die Tabelle „SalesOrderDetail“ ausgeführt, wobei die Spalte „ProductID“ als Filterspalte mit den Parametertypen „int“, „bigint“ und dann „smallint“ verwendet wurde, um einen Vergleich des Overheads impliziter Konvertierungen bereitzustellen, die nicht zu einem Indexscan führen zum Vergleich.
Hinweis:Alle Skripte sind diesem Artikel beigefügt, um die Reproduktion der impliziten Konvertierungstests für weitere Auswertungen und Vergleiche zu ermöglichen.
Testergebnisse
Während jeder Testausführung wurde der Systemmonitor so konfiguriert, dass er einen Datensammlersatz ausführte, der die Leistungsindikatoren „Prozessor\Prozessorzeit in %“ und „SQL Server:SQLStatisitics\Batch-Anforderungen/s“ enthielt, um den Leistungsaufwand für jeden der Tests nachzuverfolgen. Darüber hinaus wurden erweiterte Ereignisse so konfiguriert, dass sie das rpc_completed-Ereignis verfolgen, um die durchschnittliche Dauer, cpu_time und logische Lesevorgänge für jeden der Tests verfolgen zu können.
Kleine Tabelle CarrierTrackingNumber-Ergebnisse
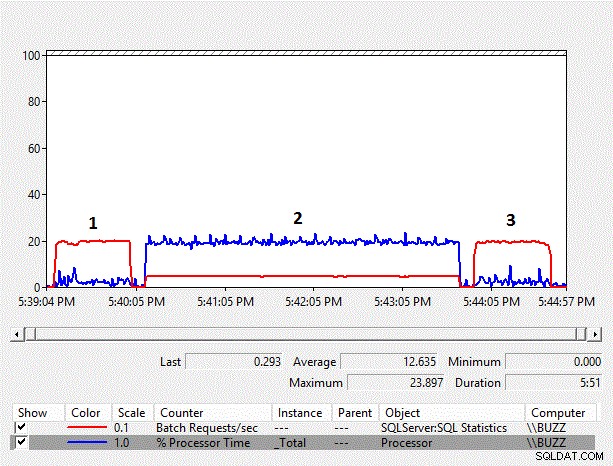
Abbildung 1 – Diagramm der Leistungsindikatoren der Leistungsüberwachung
| TestID | Spaltendatentyp | Parameterdatentyp | Durchschn. % Prozessorzeit | Durchschn. Batch-Anfragen/Sek. | Dauer h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 2.5 | 192.3 | 0:00:51 |
| 2 | Varchar | Nvarchar | 19.4 | 46.7 | 0:03:33 |
| 3 | Nvarchar | Nvarchar | 2.6 | 192.3 | 0:00:51 |
Tabelle 2 – Mittelwerte der Leistungsüberwachungsdaten
Aus den Ergebnissen können wir erkennen, dass die spaltenseitige implizite Konvertierung von varchar nach nvarchar und der daraus resultierende Index-Scan einen erheblichen Einfluss auf die Leistung der Workload hat. Die durchschnittliche prozentuale Prozessorzeit für den spaltenseitigen impliziten Konvertierungstest (TestID =2) ist fast zehnmal so hoch wie bei den anderen Tests, bei denen die spaltenseitige implizite Konvertierung, die zu einem Indexscan führte, nicht stattfand. Darüber hinaus betrug die durchschnittliche Batch-Anforderung/Sekunde für den spaltenseitigen impliziten Konvertierungstest knapp 25 % der anderen Tests. Die Dauer der Tests, bei denen keine impliziten Konvertierungen stattfanden, dauerte jeweils 51 Sekunden, obwohl die Daten in Test Nummer 3 als nvarchar mit einem nvarchar-Datentyp gespeichert wurden, was doppelt so viel Speicherplatz benötigte. Dies ist zu erwarten, da die Tabelle immer noch kleiner als der Pufferpool ist.
| TestID | Durchschn. cpu_time (µs) | Durchschn. Dauer (µs) | Durchschn. logische_Lesezugriffe |
|---|---|---|---|
| 1 | 40.7 | 154,9 | 51.6 |
| 2 | 15.640,8 | 15.760,0 | 385.6 |
| 3 | 45.3 | 169,7 | 52,7 |
Tabelle 3 – Durchschnittswerte für erweiterte Ereignisse
Die vom rpc_completed-Ereignis in Extended Events gesammelten Daten zeigen, dass die durchschnittliche cpu_time, Dauer und logischen Lesevorgänge, die mit den Abfragen verbunden sind, die keine spaltenseitige implizite Konvertierung durchführen, ungefähr gleichwertig sind, wobei die spaltenseitige implizite Konvertierung eine erhebliche CPU verursacht Overhead sowie eine längere durchschnittliche Dauer mit deutlich mehr logischen Lesevorgängen.
Vergrößerte Tabelle CarrierTrackingNumber Ergebnisse
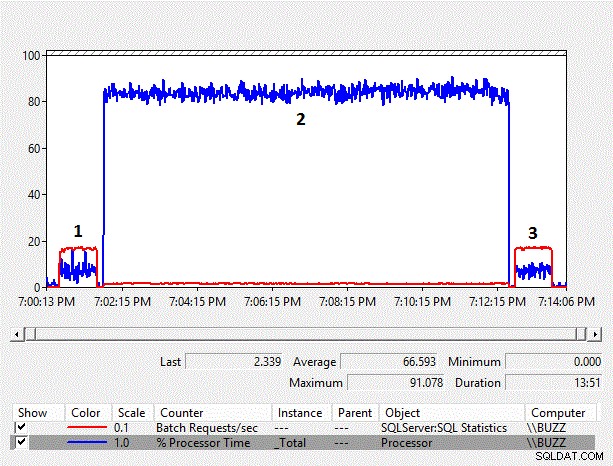
Abbildung 4 – Diagramm der Leistungsindikatoren der Leistungsüberwachung
| TestID | Spaltendatentyp | Parameterdatentyp | Durchschn. % Prozessorzeit | Durchschn. Batch-Anfragen/Sek. | Dauer h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 7.2 | 164,0 | 0:01:00 |
| 2 | Varchar | Nvarchar | 83.8 | 15.4 | 0:10:49 |
| 3 | Nvarchar | Nvarchar | 7.0 | 166,7 | 0:01:00 |
Tabelle 5 – Mittelwerte der Leistungsüberwachungsdaten
Mit zunehmender Datengröße steigt auch der Performance-Overhead der spaltenseitigen impliziten Konvertierung. Die durchschnittliche prozentuale Prozessorzeit für den spaltenseitigen impliziten Konvertierungstest (TestID =2) ist wiederum fast zehnmal so hoch wie bei den anderen Tests, bei denen die spaltenseitige implizite Konvertierung, die zu einem Indexscan führte, nicht auftrat. Darüber hinaus lag die durchschnittliche Batch-Anforderung/Sekunde für den spaltenseitigen impliziten Konvertierungstest knapp unter 10 % der anderen Tests. Die Dauer der Tests, bei denen keine impliziten Konvertierungen stattfanden, dauerte jeweils eine Minute, während die Ausführung des spaltenseitigen impliziten Konvertierungstests fast elf Minuten dauerte.
| TestID | Durchschn. cpu_time (µs) | Durchschn. Dauer (µs) | Durchschn. logische_Lesezugriffe |
|---|---|---|---|
| 1 | 728.5 | 1.036,5 | 569,6 |
| 2 | 214.174,6 | 59.519,1 | 4.358,2 |
| 3 | 821.5 | 1.032,4 | 553,5 |
Tabelle 6 – Durchschnittswerte für erweiterte Ereignisse
Die Ergebnisse der erweiterten Ereignisse beginnen wirklich, den Leistungsaufwand zu zeigen, der durch die spaltenseitigen impliziten Konvertierungen für die Workload verursacht wird. Die durchschnittliche cpu_time pro Ausführung springt auf über 214 ms und ist über das 200-fache der cpu_time für die Anweisungen, die keine spaltenseitigen impliziten Konvertierungen haben. Die Dauer beträgt auch fast das 60-fache der Anweisungen, die keine spaltenseitigen impliziten Konvertierungen haben.
Zusammenfassung
Da die Größe der Daten weiter zunimmt, wird auch der Overhead im Zusammenhang mit spaltenseitigen impliziten Konvertierungen, die zu einem Indexscan für die Workload führen, weiter zunehmen, und es ist wichtig, sich daran zu erinnern, dass irgendwann keine Menge an Hardware erforderlich ist wird in der Lage sein, mit dem Leistungsaufwand fertig zu werden. Implizite Konvertierungen lassen sich leicht verhindern, wenn ein gutes Datenbankschemadesign vorhanden ist und Entwickler gute Anwendungscodierungstechniken anwenden. In Situationen, in denen die Anwendungscodierungspraktiken zu einer Parametrisierung führen, die die nvarchar-Parametrisierung nutzt, ist es besser, das Datenbankschemadesign an die Abfrageparametrisierung anzupassen, als varchar-Spalten im Datenbankdesign zu verwenden und den Leistungsaufwand durch die spaltenseitige implizite Konvertierung zu übernehmen.
Laden Sie die Demoskripte herunter:Implicit_Conversion_Tests.zip (5 KB)