Vor einigen Wochen habe ich begonnen, eine Demoumgebung mit mehreren Konfigurationen von AlwaysOn-Verfügbarkeitsgruppen zu konfigurieren. Ich hatte einen WSFC-Cluster mit 5 Knoten – jeder Knoten hatte eine eigenständige benannte Instanz von SQL Server 2012, und es gab auch zwei Failover-Cluster-Instanzen (FCIs), die auf diesen Knoten eingerichtet wurden. Ein kurzes Diagramm:
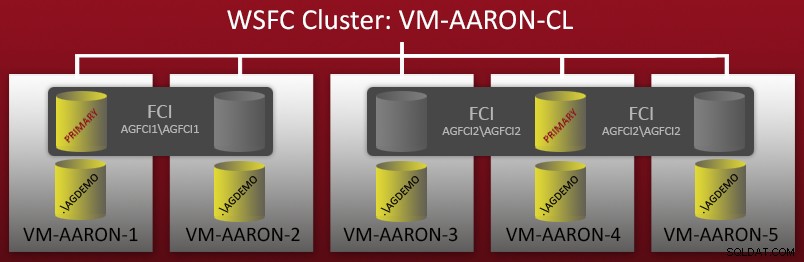
Sie können also sehen, dass es 5 eigenständige benannte Instanzen gibt (.\AGDEMO auf jedem Knoten) und dann zwei FCIs – eine mit möglichen Eigentümern VM-AARON-1 und VM-AARON-2 (AGFCI1\AGFCI1 ) und dann eine mit möglichen Besitzern VM-AARON-3, VM-AARON-4 und VM-AARON-5 (AGFCI2\AGFCI2 ). Nun, die manuelle Diagrammerstellung müsste erheblich komplexer werden (dazu später mehr), also werde ich es aus offensichtlichen Gründen vermeiden. Im Wesentlichen bestand die Anforderung darin, mehrere Arten von AG-Konfigurationen zu haben:
- Primär auf einer FCI mit einem Replikat auf einer oder mehreren eigenständigen Instanzen
- Primary auf einer FCI mit einem Replikat auf einer anderen FCI
- Primär auf einer eigenständigen Instanz mit einem Replikat auf einer oder mehreren FCIs
- Primär auf einer eigenständigen Instanz mit einem Replikat auf einer oder mehreren eigenständigen Instanzen
- Primär auf einer eigenständigen Instanz mit Replikaten auf eigenständigen Instanzen und FCIs
Und dann Kombinationen (wo möglich) aus synchronem vs. asynchronem Commit, manuellem vs. automatischem Failover und schreibgeschützten Secondaries. Es gibt einige technische Einschränkungen, die die hier möglichen Permutationen einschränken würden, zum Beispiel:
- Manuelles Failover ist bei jedem Replikat erforderlich, das sich auf einer FCI befindet
- Kein WSFC-Knoten kann mehrere eigenständige oder geclusterte Instanzen hosten – oder auch nur möglicher Eigentümer sein –, die an derselben Verfügbarkeitsgruppe beteiligt sind. Sie erhalten diese Fehlermeldung:Fehler beim Erstellen, Beitreten oder Hinzufügen des Replikats zur Verfügbarkeitsgruppe „MyGroup“, da der Knoten „VM-AARON-1“ ein möglicher Besitzer sowohl für das Replikat „AGFCI1\AGFCI1“ als auch für „VM-AARON-1“ ist. AGDEMO'. Wenn ein Replikat eine Failoverclusterinstanz ist, entfernen Sie den überlappenden Knoten von seinen möglichen Besitzern und versuchen Sie es erneut. (Microsoft SQL Server, Fehler:19405)
Die meisten Szenarien, die ich darstellen wollte, sind in realen Szenarien nicht praktikabel, aber sie sind größtenteils und theoretisch möglich . Falls Sie es noch nicht erraten haben, wird diese Umgebung explizit eingerichtet, um neue Funktionen rund um Verfügbarkeitsgruppen zu testen, die wir in einer zukünftigen Version von SQL Sentry anbieten möchten. Wir haben während unserer Keynote mit Fusion-io auf der jüngsten SQL Intersection-Konferenz in Las Vegas einen kleinen Einblick in einige dieser Technologien gegeben.
Hindernis Nr. 1
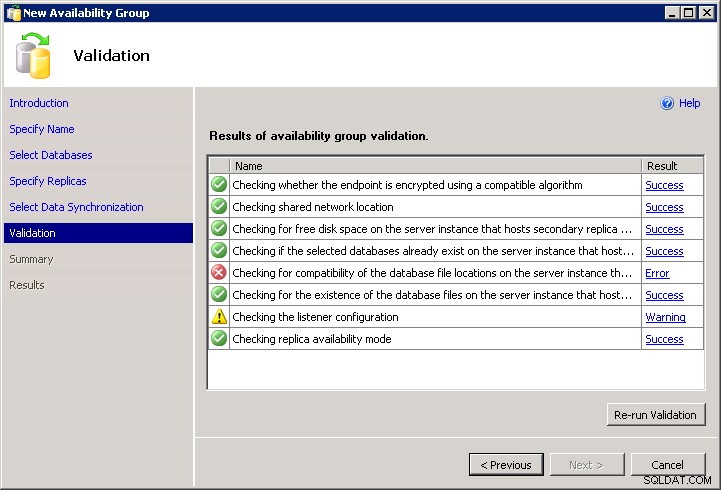
Das Einrichten von Verfügbarkeitsgruppen mit dem Assistenten in SSMS ist ziemlich einfach. Es sei denn, Sie haben beispielsweise heterogene Dateipfade. Der Assistent verfügt über eine Validierung, die sicherstellt, dass auf allen Replikaten dieselben Daten- und Protokollpfade vorhanden sind. Dies kann ein Problem sein, wenn Sie den Standarddatenpfad für zwei unterschiedlich benannte Instanzen verwenden oder wenn Sie unterschiedliche Laufwerksbuchstabenkonfigurationen haben (was häufig der Fall ist, wenn FCIs beteiligt sind).
Die Überprüfung der Kompatibilität des Speicherorts der Datenbankdatei auf dem sekundären Replikat führte zu einem Fehler. (Microsoft.SqlServer.Management.HadrTasks)Die folgenden Ordnerspeicherorte sind auf der Serverinstanz, die das sekundäre Replikat VM-AARON-1\AGDEMO hostet, nicht vorhanden:
P:\MSSQL11.AGFCI2\MSSQL\DATA;
(Microsoft.SqlServer.Management.HadrTasks)
Nun sollte es selbstverständlich sein, dass Sie dieses Szenario nicht in einer Umgebung einrichten möchten, die sich über die Zeit bewähren muss. Sehr schnell geht es schief, wenn Sie beispielsweise später eine neue Datei zu einer der Datenbanken hinzufügen. Aber für eine Test-/Demoumgebung, Proof of Concept oder eine Umgebung, von der Sie erwarten, dass sie für eine beträchtliche Zeit stabil bleibt, machen Sie sich keine Sorgen:Sie können dies immer noch ohne den Assistenten tun.
Um das Ganze noch schlimmer zu machen, lässt Sie der Assistent leider kein Skript schreiben. Sie kommen nicht über den Validierungsfehler hinaus und es gibt kein Script Schaltfläche:
Das bedeutet also, dass Sie es selbst codieren müssen (da die DDL keine "hilfreiche" Validierung für Sie durchführt). Wenn Sie andere Instanzen haben, in denen dieselben Pfade vorhanden sind, können Sie dies tun, indem Sie demselben Assistenten folgen, den Validierungsbildschirm passieren und dann auf Script klicken statt Finish , und den/die Servernamen ändern und mit WITH MOVE hinzufügen Optionen für die anfängliche Wiederherstellung. Oder Sie können einfach Ihre eigenen von Grund auf neu schreiben, etwa so (das Skript geht davon aus, dass Sie die Endpunkte und Berechtigungen bereits konfiguriert haben und dass für alle Instanzen die Funktion „Verfügbarkeitsgruppen“ aktiviert ist):
-- Use SQLCMD mode and uncomment the :CONNECT commands
-- or just run the two segments separately / change connection
-- :CONNECT Server1
CREATE AVAILABILITY GROUP [GroupName]
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY)
FOR DATABASE [Database1] --, ...
REPLICA ON -- primary:
N'Server1' WITH (ENDPOINT_URL = N'TCP://Server1:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),
-- secondary:
N'Server2' WITH (ENDPOINT_URL = N'TCP://Server2:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));
ALTER AVAILABILITY GROUP [GroupName]
ADD LISTENER N'ListenerName'
(WITH IP ((N'10.x.x.x', N'255.255.255.0')), PORT=1433);
BACKUP DATABASE Database1 TO DISK = '\\Server1\Share\db1.bak'
WITH INIT, COPY_ONLY, COMPRESSION;
BACKUP LOG Database1 TO DISK = '\\Server1\Share\db1.trn'
WITH INIT, COMPRESSION;
-- :CONNECT Server2
ALTER AVAILABILITY GROUP [GroupName] JOIN;
RESTORE DATABASE Database1 FROM DISK = '\\Server1\Share\db1.bak'
WITH REPLACE, NORECOVERY, NOUNLOAD,
MOVE 'data_file_name' TO 'P:\path\file.mdf',
MOVE 'log_file_name' TO 'P:\path\file.ldf';
RESTORE LOG Database1 FROM DISK = '\\Server1\Share\db1.trn'
WITH NORECOVERY, NOUNLOAD;
ALTER DATABASE Database1 SET HADR AVAILABILITY GROUP = [GroupName]; Hindernis #2
Wenn Sie mehrere Instanzen auf demselben Server haben, stellen Sie möglicherweise fest, dass beide Instanzen Port 5022 nicht für ihren Endpunkt für die Datenbankspiegelung freigeben können (derselbe Endpunkt, der von Verfügbarkeitsgruppen verwendet wird). Das bedeutet, dass Sie den Endpunkt löschen und neu erstellen müssen, um ihn stattdessen auf einen verfügbaren Port festzulegen.
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (ROLE = ALL);
Jetzt könnte ich eine Instanz mit einem Endpunkt auf ServerName:5023 angeben .
Hindernis Nr. 3
Sobald ich dies jedoch tat, wenn ich zum letzten Schritt im obigen Skript kam, erhielt ich nach genau 48 Sekunden – jedes Mal – diese nicht hilfreiche Fehlermeldung:
Msg 35250, Level 16, State 7, Line 2Die Verbindung zum primären Replikat ist nicht aktiv. Der Befehl kann nicht verarbeitet werden.
Dies veranlasste mich, allen möglichen potenziellen Problemen nachzujagen – zum Beispiel Firewalls und den SQL Server-Konfigurationsmanager auf alles zu überprüfen, was die Ports zwischen Instanzen blockieren würde. Nada. Ich habe verschiedene Fehler im Fehlerprotokoll von SQL Server gefunden:
Der Anmeldeversuch bei der Datenbankspiegelung ist mit folgendem Fehler fehlgeschlagen:„Verbindungshandshake fehlgeschlagen. Es gibt keinen kompatiblen Verschlüsselungsalgorithmus. Zustand 22.'.Der Anmeldeversuch bei der Datenbankspiegelung ist mit folgendem Fehler fehlgeschlagen:„Verbindungshandshake fehlgeschlagen. Ein Betriebssystemaufruf ist fehlgeschlagen:(80090303) 0x80090303 (Das angegebene Ziel ist unbekannt oder nicht erreichbar). Zustand 66.'.
Beim Versuch, eine Verbindung zum Verfügbarkeitsreplikat „VM-AARON-1\AGDEMO“ mit der ID [5AF5B58D-BBD5-40BB-BE69-08AC50010BE0] herzustellen, ist ein Verbindungstimeout aufgetreten. Entweder liegt ein Netzwerk- oder Firewall-Problem vor, oder die für das Replikat angegebene Endpunktadresse ist nicht der Datenbankspiegelungs-Endpunkt der Hostserverinstanz.
Es stellt sich heraus (und danke an Thomas Stringer (@SQLife)), dass dieses Problem durch eine Kombination von Symptomen verursacht wurde:(a) Kerberos wurde nicht richtig eingerichtet, und (b) der Verschlüsselungsalgorithmus für den von mir erstellten hadr_endpoint war fehlerhaft zu RC4. Dies wäre in Ordnung, wenn alle eigenständigen Instanzen auch RC4 verwenden würden, aber das war nicht der Fall. Um es kurz zu machen, ich habe die Endpunkte erneut gelöscht und neu erstellt , in allen Fällen. Da dies eine Laborumgebung war und ich Kerberos-Unterstützung nicht wirklich benötigte (und weil ich bereits genug Zeit in diese Probleme investiert hatte, wollte ich Kerberos-Problemen nicht nachjagen), richtete ich alle Endpunkte ein, mit denen Negotiate verwendet werden soll AES:
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES,
ROLE = ALL); (Ted Krueger (@onpnt) hat kürzlich ebenfalls über ein ähnliches Problem gebloggt.)
Jetzt konnte ich endlich Verfügbarkeitsgruppen mit all den verschiedenen Anforderungen erstellen, die ich hatte, zwischen Knoten mit heterogenen Dateipfaden und unter Verwendung mehrerer Instanzen auf demselben Knoten (nur nicht in derselben Gruppe). Hier sehen Sie, wie eine unserer AlwaysOn-Verwaltungsansichten aussehen wird (zum Vergrößern anklicken, um einen besseren Überblick zu erhalten):
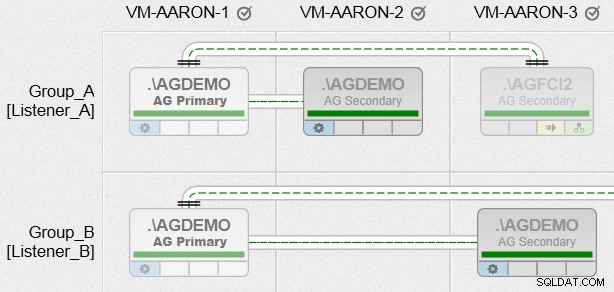
Nun, das ist nur ein bisschen necken, und es ist voll und ganz beabsichtigt. Ich werde in den kommenden Wochen mehr über diese Funktion bloggen!
Schlussfolgerung
Wenn Sie lange genug damit verbringen, ein Problem zu betrachten, können Sie einige ziemlich offensichtliche Dinge übersehen. In diesem Fall gab es einige offensichtliche Probleme, die von einigen geradezu unintuitiven Fehlermeldungen verdeckt wurden. Ich möchte Joe Sack (@JosephSack), Allan Hirt (@SQLHA) und Thomas Stringer (@SQLife) dafür danken, dass sie alles fallen gelassen haben, um einem anderen Community-Mitglied in Not zu helfen.