Ich bin gerade dabei, mein Haus zu entrümpeln (zu spät im Sommer, um es als Frühjahrsputz abzutun). Du weißt schon, Schränke ausräumen, die Spielsachen der Kinder durchsuchen und den Keller organisieren. Es ist ein schmerzhafter Prozess. Als wir vor 10 Jahren in unser Haus einzogen, hatten wir so viel Platz. Jetzt habe ich das Gefühl, dass es überall Sachen gibt, und es wird schwieriger, das zu finden, wonach ich wirklich suche, und es dauert immer länger, aufzuräumen und zu organisieren.
Klingt das nach irgendeiner Datenbank, die Sie verwalten?
Viele Kunden, mit denen ich zusammengearbeitet habe, beschäftigen sich nachträglich mit dem Löschen von Daten. Zum Zeitpunkt der Umsetzung will jeder alles retten. „Wir wissen nie, wann wir es brauchen.“ Nach ein oder zwei Jahren stellt jemand fest, dass es eine Menge zusätzliches Zeug in der Datenbank gibt, aber jetzt haben die Leute Angst, es loszuwerden. „Wir müssen uns bei der Rechtsabteilung erkundigen, ob wir es löschen können.“ Aber niemand erkundigt sich bei der Rechtsabteilung, oder wenn doch, geht die Rechtsabteilung zurück zu den Geschäftsinhabern, um zu fragen, was sie behalten sollen, und dann kommt das Projekt zum Erliegen. „Wir können uns nicht darüber einigen, was gelöscht werden kann.“ Das Projekt wird vergessen, und dann, zwei oder vier Jahre später, ist die Datenbank plötzlich ein Terabyte groß, schwer zu verwalten, und die Leute machen die Datenbankgröße für alle Leistungsprobleme verantwortlich. Sie hören die Wörter „Partitionierung“ und „Datenbank archivieren“ und manchmal müssen Sie einfach einen Haufen Daten löschen, was seine eigenen Probleme hat.
Idealerweise sollten Sie sich vor der Implementierung oder innerhalb der ersten sechs bis zwölf Monate nach dem Go-Live über Ihre Bereinigungsstrategie entscheiden. Aber da wir dieses Stadium überschritten haben, schauen wir uns an, welche Auswirkungen diese zusätzlichen Daten haben können.
Testmethodik
Um die Voraussetzungen zu schaffen, habe ich eine Kopie der Credit-Datenbank erstellt und sie auf meiner SQL Server 2012-Instanz wiederhergestellt. Ich habe die drei vorhandenen Nonclustered-Indizes gelöscht und zwei eigene hinzugefügt:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
Ich habe dann die Anzahl der Zeilen in der Tabelle auf 14,4 Millionen erhöht, indem ich die ursprünglichen Zeilen mehrmals neu eingefügt und die Daten leicht geändert habe:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Schließlich richtete ich einen Testrahmen ein, um eine Reihe von Anweisungen jeweils viermal gegen die Datenbank auszuführen. Die Anweisungen sind unten:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Vor jeder Anweisung, die ich ausgeführt habe
DBCC DROPCLEANBUFFERS; GO
um den Pufferpool zu löschen. Offensichtlich ist dies nicht etwas, das in einer Produktionsumgebung ausgeführt werden kann. Ich habe es hier gemacht, um einen konsistenten Ausgangspunkt für jeden Test bereitzustellen.
Nach jeder Ausführung habe ich die Größe der Tabelle dbo.charge erhöht, indem ich die 14,4 Millionen Zeilen eingefügt habe, mit denen ich begonnen habe, aber ich habe charge_dt für jede Ausführung um ein Jahr erhöht. Zum Beispiel:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Nach dem Hinzufügen von 14,4 Millionen Zeilen habe ich den Testharness erneut ausgeführt. Ich wiederholte dies sechs Mal und fügte im Wesentlichen sechs „Jahre“ an Daten hinzu. Die Tabelle dbo.charge begann mit Daten aus dem Jahr 1999 und enthielt nach den wiederholten Einfügungen Daten bis 2005.
Ergebnisse
Die Ergebnisse der Hinrichtungen können hier eingesehen werden:
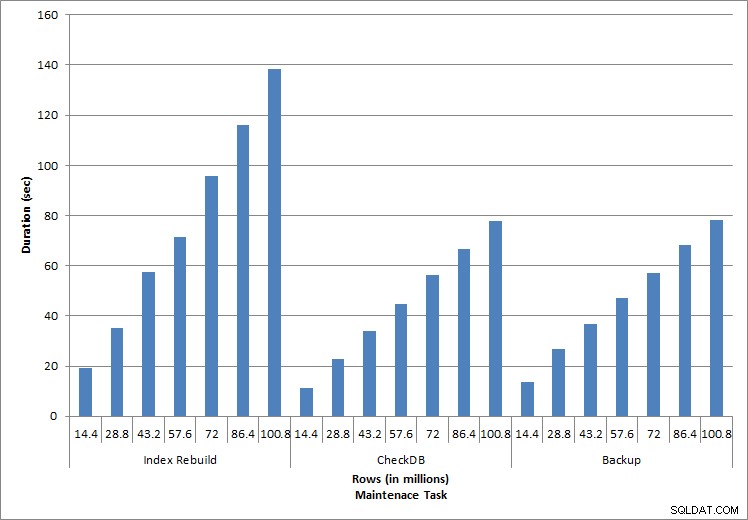
Dauer für Wartungsaufgaben
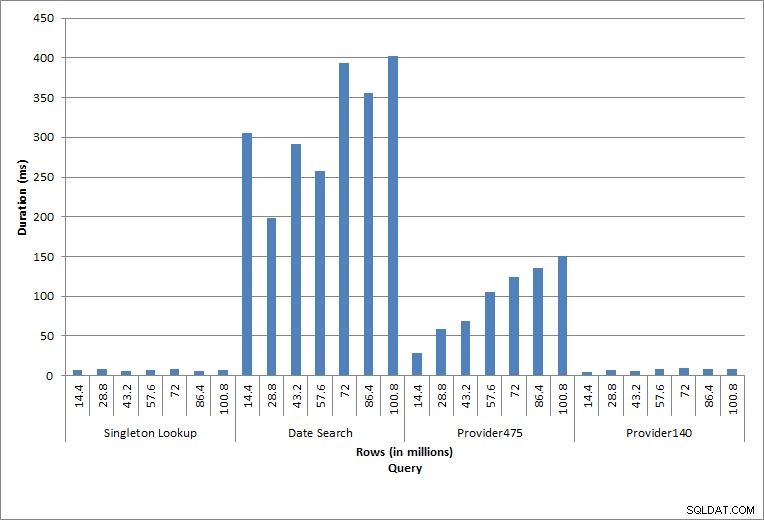
Dauer für Abfragen
Die einzelnen ausgeführten Anweisungen spiegeln typische Datenbankaktivitäten wider. Index-Neuaufbauen, Integritätsprüfungen und Backups sind Teil der regelmäßigen Datenbankwartung. Die Abfragen der Gebührentabelle stellen eine Singleton-Suche sowie drei Variationen von Bereichsscans dar, die für die Daten in der Tabelle spezifisch sind.
Indexneuaufbau, CHECKDB und Backups
Wie für die Wartungsaufgaben erwartet, nahmen die Dauer und die IO-Werte zu, je mehr Zeilen zur Datenbank hinzugefügt wurden. Die Datenbankgröße erhöhte sich um den Faktor 10, und obwohl die Dauer nicht im gleichen Maße zunahm, wurde eine beständige Zunahme beobachtet. Jede Wartungsaufgabe dauerte zunächst weniger als 20 Sekunden, aber als weitere Zeilen hinzugefügt wurden, erhöhte sich die Dauer der Aufgaben auf fast 1 Minute und 20 Sekunden für 100 Millionen Zeilen (und auf über 2 Minuten für die Indexneuerstellung). Dies spiegelt die zusätzliche Zeit wider, die SQL Server benötigt, um die Aufgabe aufgrund zusätzlicher Daten abzuschließen.
Singleton-Suche
Die Abfrage von dbo.charge für eine bestimmte charge_no ergab immer eine Zeile – und hätte unabhängig vom verwendeten Wert eine Zeile erzeugt, da charge_no eine eindeutige Identität ist. Für diese Suche gibt es nur minimale Abweichungen. Da der Tabelle kontinuierlich Zeilen hinzugefügt werden, kann die Tiefe des Index um ein oder zwei Ebenen zunehmen (mehr, wenn die Tabelle breiter wird), wodurch ein paar IOs hinzugefügt werden, aber dies ist eine Singleton-Suche mit sehr wenigen IOs.
Reichweitenscans
Die Abfrage für einen Datumsbereich (charge_dt) wurde nach jeder Einfügung geändert, um die Daten des letzten Jahres für Juli zu suchen (z. B. „2005-07-01“ bis „2005-07-01“ für die letzte Testreihe), aber zurückgegeben etwas mehr als 1,2 Millionen Zeilen jedes Mal. In einem realen Szenario würden wir nicht erwarten, dass Jahr für Jahr dieselbe Anzahl von Zeilen für denselben Monat zurückgegeben wird, und wir würden auch nicht erwarten, dass für jeden Monat in einem Jahr dieselbe Anzahl von Zeilen zurückgegeben wird. Aber die Anzahl der Zeilen könnte zwischen den Monaten im gleichen Bereich bleiben, mit leichten Anstiegen im Laufe der Zeit. Es gibt Schwankungen in der Dauer dieser Abfrage, aber eine Überprüfung der von sys.dm_io_virtual_file_stats erfassten IO-Daten zeigt eine Konsistenz in der Anzahl der Lesevorgänge.
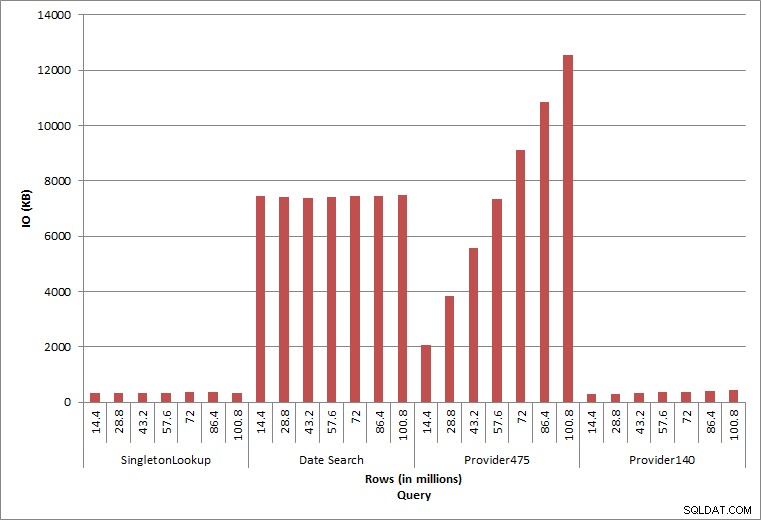
E/A abfragen
Die letzten beiden Abfragen für zwei verschiedene provider_no-Werte zeigen die wahre Auswirkung der Beibehaltung von Daten. In der ursprünglichen Tabelle „dbo.charge“ hatte „provider_no 475“ über 126.000 Zeilen und „provider_no 140“ über 1.700 Zeilen. Für jeweils 14,4 Millionen hinzugefügte Zeilen wurde ungefähr die gleiche Anzahl von Zeilen für jede provider_no hinzugefügt. In einer Produktionsumgebung ist diese Art der Datenverteilung nicht ungewöhnlich, und Abfragen für diese Daten können in den ersten Jahren der Lösung eine gute Leistung erbringen, sich jedoch im Laufe der Zeit verschlechtern, wenn weitere Zeilen hinzugefügt werden. Die Abfragedauer erhöht sich zwischen der anfänglichen und der letzten Ausführung für provider_no 475 um den Faktor fünf (von 31 ms auf 153 ms). Auch wenn diese Auswirkung nicht signifikant erscheint, beachten Sie den parallelen Anstieg von IO (oben). Wenn dies eine Abfrage war, die mit hoher Häufigkeit ausgeführt wurde, und/oder ähnliche Abfragen vorhanden waren, die mit regelmäßiger Häufigkeit ausgeführt wurden, kann sich die zusätzliche Last summieren und die Gesamtressourcennutzung beeinflussen. Berücksichtigen Sie außerdem die Auswirkungen, wenn Sie mit Tabellen arbeiten, die Milliarden von Zeilen enthalten und in Abfragen mit komplexen Verknüpfungen verwendet werden, sowie die Auswirkungen auf Ihre regelmäßigen – und äußerst kritischen – Wartungsaufgaben. Berücksichtigen Sie schließlich die Wiederherstellungszeit. Ihr Notfallwiederherstellungsplan sollte auf Wiederherstellungszeiten basieren, und mit zunehmender Datenbankgröße dauert es länger, bis die Datenbank vollständig wiederhergestellt ist. Wenn Sie Ihre Wiederherstellungen nicht regelmäßig testen und zeitlich planen, kann die Wiederherstellung nach einem Notfall länger dauern, als Sie dachten.
Zusammenfassung
Die hier gezeigten Beispiele sind einfache Veranschaulichungen dessen, was passieren kann, wenn während der Datenbankimplementierung keine Datenarchivierungsstrategie festgelegt wird, und es gibt viele andere Szenarien, die untersucht und getestet werden müssen. Alte Daten, auf die selten, wenn überhaupt, zugegriffen wird, wirken sich auf mehr als nur den Speicherplatz auf der Festplatte aus. Dies kann sich auf die Abfrageleistung und die Dauer von Wartungsaufgaben auswirken. Als DBA, der mehrere Datenbanken auf einer Instanz verwaltet, kann eine Datenbank, die Verlaufsdaten enthält, die Leistung und Wartungsaufgaben anderer Datenbanken beeinträchtigen. Außerdem kann die Ausführung von Berichten anhand historischer Daten verheerende Auswirkungen auf die bereits ausgelastete OLTP-Umgebung haben.
Von Anfang an ist es wichtig, dass die Lebensdauer von Daten in einer Datenbank bestimmt und ein Aktionsplan erstellt wird. Bei einigen Lösungen ist es erforderlich, alle Daten für immer aufzubewahren. Verwenden Sie in diesem Fall Strategien, um die Datenbankgröße überschaubar zu halten, z. B.:Archivieren Sie die Daten regelmäßig in einer separaten Tabelle oder einer separaten Datenbank. Für den Fall, dass Daten nicht jahrelang gespeichert werden müssen, implementieren Sie eine Bereinigungsstrategie, die Daten regelmäßig entfernt. Auf diese Weise können Sie Spielzeug, mit dem nicht mehr gespielt wird, Kleidung, die nicht mehr passt, und zufälligen Müll, den Sie einfach nicht mehr benutzen, alle drei Monate wegwerfen … anstatt einmal alle 10 Jahre.