Die Tabellenpartitionierung in SQL Server ist im Wesentlichen eine Möglichkeit, mehrere physische Tabellen (Rowsets) wie eine einzelne Tabelle aussehen zu lassen. Diese Abstraktion wird vollständig vom Abfrageprozessor durchgeführt, ein Design, das die Dinge für Benutzer einfacher macht, aber komplexe Anforderungen an den Abfrageoptimierer stellt. Dieser Beitrag befasst sich mit zwei Beispielen, die die Fähigkeiten des Optimierers in SQL Server 2008 und höher übersteigen.
Kolumnenreihenfolgeangelegenheiten beitreten
Dieses erste Beispiel zeigt die textuelle Reihenfolge von ON -Klauselbedingungen können sich auf den beim Join partitionierter Tabellen erstellten Abfrageplan auswirken. Zunächst benötigen wir ein Partitionierungsschema, eine Partitionierungsfunktion und zwei Tabellen:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); Als nächstes laden wir beide Tabellen mit 150.000 Zeilen. Die Daten spielen keine große Rolle; In diesem Beispiel wird eine standardmäßige Numbers-Tabelle mit allen ganzzahligen Werten von 1 bis 150.000 als Datenquelle verwendet. Beide Tabellen werden mit denselben Daten geladen.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
Unsere Testabfrage führt eine einfache innere Verknüpfung dieser beiden Tabellen durch. Auch hier ist die Abfrage nicht wichtig oder soll besonders realistisch sein, sie wird verwendet, um einen seltsamen Effekt beim Verbinden von partitionierten Tabellen zu demonstrieren. Die erste Form der Abfrage verwendet ein ON Klausel in der Spaltenreihenfolge c3, c2, c1 geschrieben:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1; Der für diese Abfrage erstellte Ausführungsplan (auf SQL Server 2008 und höher) bietet einen parallelen Hash-Join mit geschätzten Kosten von 2,6953 :
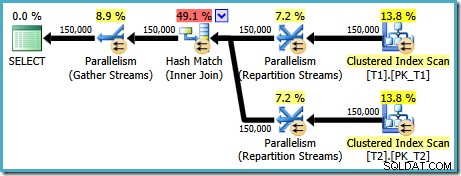
Das ist etwas unerwartet. Beide Tabellen haben einen gruppierten Index in der Reihenfolge (c1, c2, c3), partitioniert durch c1, also würden wir einen Merge-Join erwarten, der die Indexreihenfolge nutzt. Versuchen wir, den ON zu schreiben stattdessen in der Reihenfolge (c1, c2, c3):
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; Der Ausführungsplan verwendet jetzt den erwarteten Merge-Join mit geschätzten Kosten von 1,64119 (nach unten von 2,6953 ). Der Optimierer entscheidet auch, dass es sich nicht lohnt, die parallele Ausführung zu verwenden:
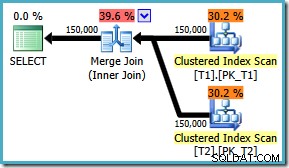
Da der Merge-Join-Plan eindeutig effizienter ist, können wir versuchen, einen Merge-Join für das ursprüngliche ON zu erzwingen Klauselreihenfolge mit einem Abfragehinweis:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); Der resultierende Plan verwendet wie gewünscht einen Merge-Join, bietet aber auch Sortierungen für beide Eingaben und geht zurück auf die Verwendung von Parallelität. Die geschätzten Kosten für diesen Plan betragen satte 8,71063 :
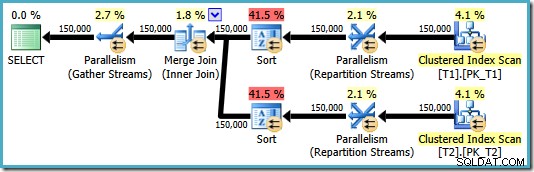
Beide Sortieroperatoren haben dieselben Eigenschaften:
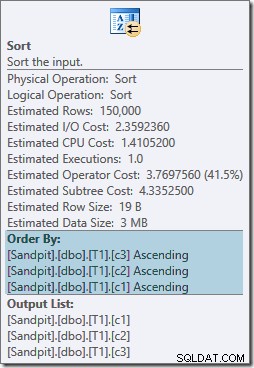
Der Optimierer denkt, dass der Merge-Join seine Eingaben in der strikten schriftlichen Reihenfolge des ON sortiert haben muss -Klausel, wodurch explizite Sortierungen eingeführt werden. Der Optimierer ist sich bewusst, dass ein Merge-Join erfordert, dass seine Eingaben auf die gleiche Weise sortiert werden, aber er weiß auch, dass die Spaltenreihenfolge keine Rolle spielt. Merge Join on (c1, c2, c3) ist mit Eingaben, die nach (c3, c2, c1) sortiert sind, genauso zufrieden wie mit Eingaben, die nach (c2, c1, c3) oder einer beliebigen anderen Kombination sortiert sind.
Leider wird diese Argumentation im Abfrageoptimierer gebrochen, wenn es um Partitionierung geht. Dies ist ein Optimiererfehler das wurde in SQL Server 2008 R2 und höher behoben, obwohl das Ablaufverfolgungsflag 4199 wird benötigt, um den Fix zu aktivieren:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
Normalerweise würden Sie dieses Ablaufverfolgungsflag mit DBCC TRACEON aktivieren oder als Startoption, weil der QUERYTRACEON Hinweis ist für die Verwendung mit 4199 nicht dokumentiert. Das Ablaufverfolgungsflag ist in SQL Server 2008 R2, SQL Server 2012 und SQL Server 2014 CTP1 erforderlich.
Unabhängig davon, wie das Flag aktiviert ist, erzeugt die Abfrage jetzt den optimalen Merge-Join, unabhängig von ON Klauselreihenfolge:
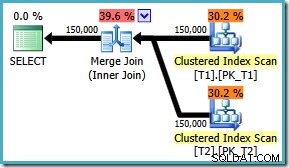
Es gibt keine Lösung für SQL Server 2008 , besteht die Problemumgehung darin, ON zu schreiben Satz in der „richtigen“ Reihenfolge! Wenn Sie auf SQL Server 2008 auf eine solche Abfrage stoßen, versuchen Sie, einen Merge-Join zu erzwingen, und sehen Sie sich die Sortierungen an, um die „richtige“ Schreibweise für ON Ihrer Abfrage zu bestimmen Klausel.
Dieses Problem tritt in SQL Server 2005 nicht auf, da diese Version partitionierte Abfragen mit APPLY implementiert hat Modell:

Der SQL Server 2005-Abfrageplan fügt jeweils eine Partition aus jeder Tabelle hinzu, wobei eine In-Memory-Tabelle (der konstante Scan) verwendet wird, die zu verarbeitende Partitionsnummern enthält. Jede Partition wird separat auf der inneren Seite des Joins zusammengeführt, und der Optimierer von 2005 ist intelligent genug, um zu erkennen, dass ON Die Spaltenreihenfolge der Klausel spielt keine Rolle.
Dieser neueste Plan ist ein Beispiel für einen verbundenen Merge-Join , eine Funktion, die beim Wechsel von SQL Server 2005 zur neuen Partitionierungsimplementierung in SQL Server 2008 verloren ging. Ein Vorschlag zu Verbinden, um verbundene Zusammenführungsverknüpfungen wiederherzustellen, wurde als Won’t Fix geschlossen.
Gruppieren nach Reihenfolge ist wichtig
Die zweite Besonderheit, die ich betrachten möchte, folgt einem ähnlichen Thema, bezieht sich aber auf die Reihenfolge der Spalten in einem GROUP BY -Klausel anstelle von ON Klausel eines inneren Joins. Wir brauchen eine neue Tabelle, um Folgendes zu demonstrieren:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; Die Tabelle hat einen ausgerichteten Nonclustered-Index, wobei "ausgerichtet" einfach bedeutet, dass sie auf die gleiche Weise partitioniert ist wie der Clustered-Index (oder Heap):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
Unsere Testabfrage gruppiert Daten über die drei Nonclustered-Indexspalten und gibt eine Anzahl für jede Gruppe zurück:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
Der Abfrageplan scannt den Nonclustered-Index und verwendet ein Hash-Match-Aggregat, um Zeilen in jeder Gruppe zu zählen:
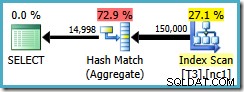
Es gibt zwei Probleme mit Hash Aggregate:
- Es ist ein blockierender Operator. Es werden keine Zeilen an den Client zurückgegeben, bis alle Zeilen aggregiert wurden.
- Es erfordert eine Speicherzuteilung, um die Hash-Tabelle zu halten.
In vielen realen Szenarien würden wir hier ein Stream Aggregate bevorzugen, da dieser Operator nur pro Gruppe blockiert und keine Speicherzuweisung erfordert. Mit dieser Option würde die Client-Anwendung früher anfangen, Daten zu empfangen, müsste nicht warten, bis Speicher gewährt wird, und der SQL-Server kann den Speicher für andere Zwecke verwenden.
Wir können verlangen, dass der Abfrageoptimierer ein Stream-Aggregat für diese Abfrage verwendet, indem wir eine OPTION (ORDER GROUP) hinzufügen Abfragehinweis. Daraus ergibt sich folgender Ausführungsplan:

Der Sort-Operator blockiert vollständig und erfordert auch eine Speicherzuweisung, sodass dieser Plan schlechter zu sein scheint als die einfache Verwendung eines Hash-Aggregats. Aber warum wird die Sorte benötigt? Die Eigenschaften zeigen, dass die Zeilen in der von unserem GROUP BY angegebenen Reihenfolge sortiert werden Klausel:
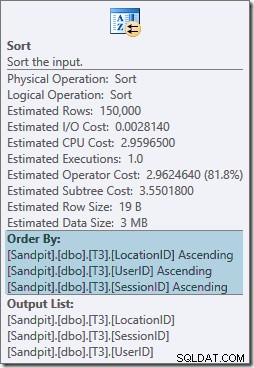
Diese Sortierung wird erwartet weil die Partitionsausrichtung des Index (ab SQL Server 2008) bedeutet, dass die Partitionsnummer als führende Spalte des Index hinzugefügt wird. Tatsächlich sind die nicht gruppierten Indexschlüssel (Partition, Benutzer, Sitzung, Speicherort) aufgrund der Partitionierung. Zeilen im Index werden weiterhin nach Benutzer, Sitzung und Ort sortiert, aber nur innerhalb jeder Partition.
Wenn wir die Abfrage auf eine einzelne Partition beschränken, sollte der Optimierer in der Lage sein, den Index zu verwenden, um ein Stream-Aggregat ohne Sortierung zu füttern. Falls dies eine Erklärung erfordert, bedeutet die Angabe einer einzelnen Partition, dass der Abfrageplan alle anderen Partitionen aus dem Nonclustered-Index-Scan eliminieren kann, was zu einem Strom von Zeilen führt, die nach (Benutzer, Sitzung, Speicherort) geordnet sind.
Wir können diese Partitionsentfernung explizit mit $PARTITION erreichen Funktion:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
Leider verwendet diese Abfrage immer noch ein Hash-Aggregat mit geschätzten Plankosten von 0,287878 :
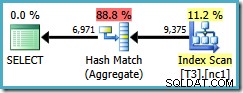
Der Scan erstreckt sich jetzt nur über eine Partition, aber die Reihenfolge (Benutzer, Sitzung, Standort) hat dem Optimierer nicht geholfen, ein Stream-Aggregat zu verwenden. Sie könnten einwenden, dass die Sortierung (Benutzer, Sitzung, Ort) nicht hilfreich ist, weil GROUP BY -Klausel ist (location, user, session), aber die Schlüsselreihenfolge spielt für eine Gruppierungsoperation keine Rolle.
Lassen Sie uns einen ORDER BY hinzufügen Klausel in der Reihenfolge der Indexschlüssel, um den Punkt zu beweisen:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Beachten Sie, dass ORDER BY -Klausel stimmt mit der Schlüsselreihenfolge des nicht gruppierten Index überein, obwohl die GROUP BY Klausel nicht. Der Ausführungsplan für diese Abfrage ist:
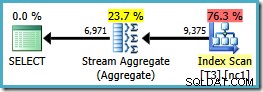
Jetzt haben wir das Stream-Aggregat, nach dem wir gesucht haben, mit geschätzten Plankosten von 0,0423925 (im Vergleich zu 0,287878 für den Hash Aggregate-Plan – fast 7-mal mehr).
Die andere Möglichkeit, hier ein Stream-Aggregat zu erreichen, besteht darin, GROUP BY neu zu ordnen Spalten, die mit den nicht gruppierten Indexschlüsseln übereinstimmen:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
Diese Abfrage erzeugt denselben Stream Aggregate-Plan, der direkt oben gezeigt wird, mit genau denselben Kosten. Diese Empfindlichkeit gegenüber GROUP BY Die Spaltenreihenfolge ist spezifisch für partitionierte Tabellenabfragen in SQL Server 2008 und höher.
Sie können erkennen, dass die Hauptursache des Problems hier dem vorherigen Fall mit einem Merge Join ähnelt. Sowohl Merge Join als auch Stream Aggregate erfordern Eingaben, die nach den Join- oder Aggregationsschlüsseln sortiert sind, aber keiner kümmert sich um die Reihenfolge dieser Schlüssel. Ein Merge-Join auf (x, y, z) empfängt genauso gerne Zeilen, die nach (y, z, x) oder (z, y, x) geordnet sind, und das Gleiche gilt für Stream Aggregate.
Diese Einschränkung des Optimierers gilt auch für DISTINCT unter den gleichen Umständen. Die folgende Abfrage führt zu einem Hash Aggregate-Plan mit geschätzten Kosten von 0,286539 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
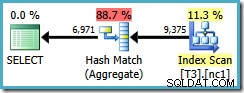
Wenn wir den DISTINCT schreiben Spalten in der Reihenfolge der Nonclustered-Indexschlüssel…
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
… werden wir mit einem Stream Aggregate-Plan mit Kosten von 0,041455 belohnt :

Zusammenfassend ist dies eine Einschränkung des Abfrageoptimierers in SQL Server 2008 und höher (einschließlich SQL Server 2014 CTP 1), die nicht durch die Verwendung des Ablaufverfolgungsflags 4199 behoben wird wie es beim Merge-Join-Beispiel der Fall war. Das Problem tritt nur bei partitionierten Tabellen mit einem GROUP BY auf oder DISTINCT über drei oder mehr Spalten mit einem ausgerichteten partitionierten Index, wobei eine einzelne Partition verarbeitet wird.
Wie beim Merge Join-Beispiel stellt dies einen Rückschritt gegenüber dem Verhalten von SQL Server 2005 dar. SQL Server 2005 fügte keinen impliziten führenden Schlüssel zu partitionierten Indizes hinzu, indem ein APPLY verwendet wurde Technik statt. In SQL Server 2005 verwenden alle hier dargestellten Abfragen $PARTITION um ein einzelnes Partitionsergebnis in Abfrageplänen anzugeben, die eine Partitionseliminierung durchführen, und Stream-Aggregate ohne Neuordnung des Abfragetexts zu verwenden.
Die Änderungen an der Verarbeitung von partitionierten Tabellen in SQL Server 2008 verbesserten die Leistung in mehreren wichtigen Bereichen, hauptsächlich im Zusammenhang mit der effizienten parallelen Verarbeitung von Partitionen. Leider hatten diese Änderungen Nebenwirkungen, die in späteren Versionen nicht alle behoben wurden.



