In einem aktuellen Thread auf StackExchange hatte ein Benutzer das folgende Problem:
Ich möchte eine Abfrage, die die erste Person in der Tabelle mit einer GroupID =2 zurückgibt. Wenn niemand mit einer GroupID =2 existiert, möchte ich die erste Person mit einer RoleID =2.
Lassen Sie uns vorerst die Tatsache verwerfen, dass „zuerst“ schrecklich definiert ist. In Wirklichkeit war es dem Benutzer egal, welche Person er bekam, ob sie zufällig, willkürlich oder durch eine explizite Logik zusätzlich zu seinen Hauptkriterien kam. Nehmen wir an, Sie haben eine einfache Tabelle:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
In der realen Welt gibt es wahrscheinlich andere Spalten, zusätzliche Einschränkungen, vielleicht Fremdschlüssel zu anderen Tabellen und sicherlich andere Indizes. Aber lassen Sie es uns einfach halten und uns eine Abfrage einfallen lassen.
Wahrscheinliche Lösungen
Mit diesem Tabellendesign scheint die Lösung des Problems einfach zu sein, oder? Der erste Versuch, den Sie wahrscheinlich machen würden, ist:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Dies verwendet TOP und ein bedingtes ORDER BY Benutzer mit einer GroupID =2 mit höherer Priorität zu behandeln. Der Plan für diese Abfrage ist ziemlich einfach, wobei die meisten Kosten in einer Sortieroperation anfallen. Hier sind Laufzeitmetriken für eine leere Tabelle:
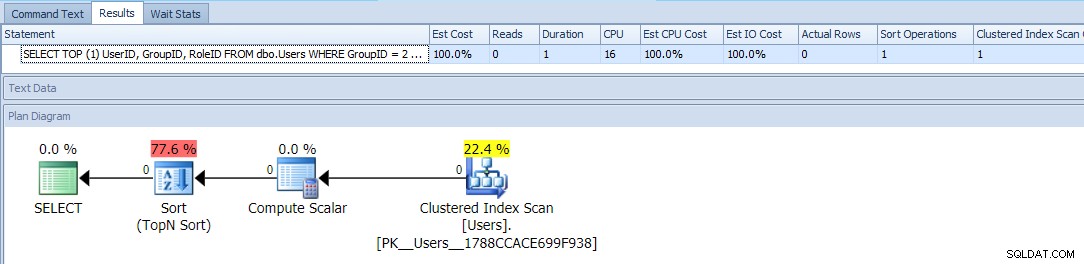
Das sieht so gut aus, wie Sie es können – ein einfacher Plan, der den Tisch nur einmal scannt, und abgesehen von einer lästigen Sorte, mit der Sie leben können sollten, kein Problem, oder?
Nun, eine andere Antwort im Thread bot diese komplexere Variante an:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
Auf den ersten Blick würden Sie wahrscheinlich denken, dass diese Abfrage extrem ineffizient ist, da sie zwei Clustered-Index-Scans erfordert. Damit haben Sie definitiv Recht; Hier sind die Plan- und Laufzeitmetriken für eine leere Tabelle:
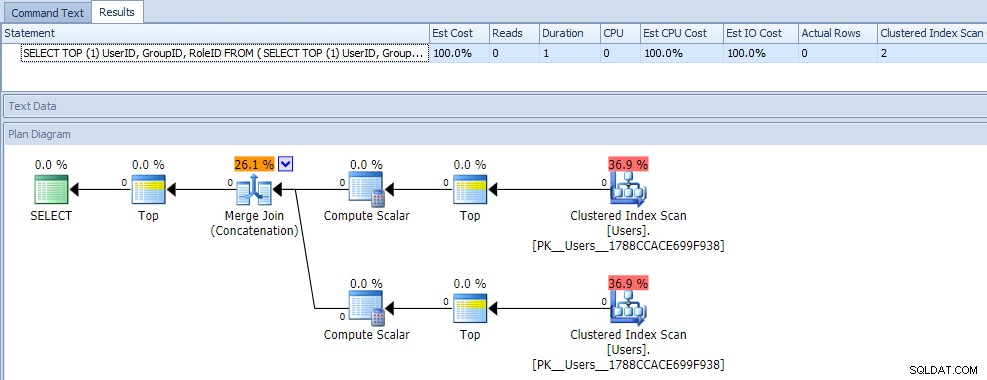
Aber jetzt fügen wir Daten hinzu
Um diese Abfragen zu testen, wollte ich einige realistische Daten verwenden. Also habe ich zuerst 1.000 Zeilen aus sys.all_objects gefüllt, mit Modulo-Operationen gegen die object_id, um eine anständige Verteilung zu erhalten:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Wenn ich jetzt die beiden Abfragen ausführe, sind hier die Laufzeitmetriken:

Die UNION ALL-Version kommt mit etwas weniger E/A (4 Lesevorgänge gegenüber 5), geringerer Dauer und niedrigeren geschätzten Gesamtkosten, während die bedingte ORDER BY-Version niedrigere geschätzte CPU-Kosten hat. Die Daten hier sind ziemlich klein, um irgendwelche Schlussfolgerungen zu ziehen; Ich wollte es nur als Pfahl im Boden. Ändern wir nun die Verteilung so, dass die meisten Zeilen mindestens eines der Kriterien (und manchmal beide) erfüllen:
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Dieses Mal hat die bedingte Bestellung nach die höchsten geschätzten Kosten sowohl in CPU als auch in E/A:

Aber noch einmal, bei dieser Datengröße gibt es relativ unbedeutende Auswirkungen auf die Dauer und die Lesevorgänge, und abgesehen von den geschätzten Kosten (die sowieso größtenteils gedeckt sind) ist es schwierig, hier einen Gewinner zu nennen.
Also fügen wir noch viel mehr Daten hinzu
Obwohl ich lieber Beispieldaten aus den Katalogansichten erstelle, da jeder diese hat, werde ich dieses Mal auf die Tabelle Sales.SalesOrderHeaderEnlarged von AdventureWorks2012 zurückgreifen, die mit diesem Skript von Jonathan Kehayias erweitert wurde. Auf meinem System hat diese Tabelle 1.258.600 Zeilen. Das folgende Skript fügt eine Million dieser Zeilen in unsere dbo.Users-Tabelle ein:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
Okay, wenn wir jetzt die Abfragen ausführen, sehen wir ein Problem:Die ORDER BY-Variante ist parallel gelaufen und hat sowohl Lesevorgänge als auch CPU ausgelöscht, was zu einem fast 120-fachen Unterschied in der Dauer führt:
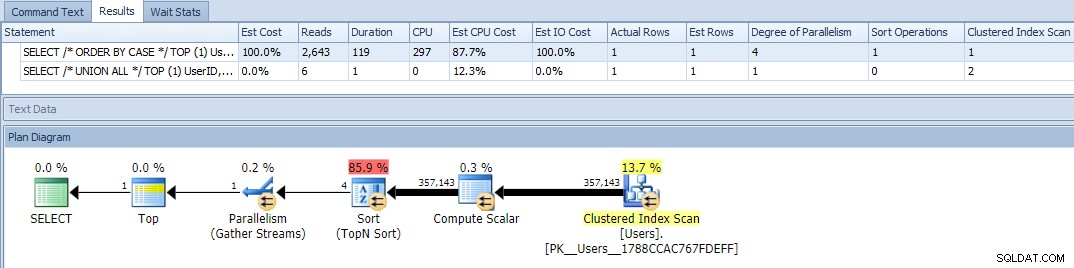
Das Eliminieren der Parallelität (mithilfe von MAXDOP) hat nicht geholfen:
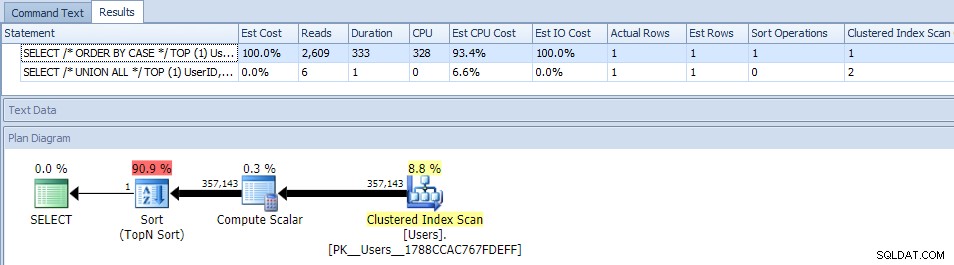
(Der Plan UNION ALL sieht immer noch gleich aus.)
Und wenn wir die Schiefe so ändern, dass sie gerade ist, wobei 95 % der Zeilen mindestens ein Kriterium erfüllen:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Die Abfragen zeigen immer noch, dass die Sortierung unerschwinglich teuer ist:

Und mit MAXDOP =1 war es viel schlimmer (siehe Dauer):

Wie wäre es schließlich mit 95 % Schräglage in beide Richtungen (z. B. die meisten Zeilen erfüllen die GroupID-Kriterien oder die meisten Zeilen die RoleID-Kriterien)? Dieses Skript stellt sicher, dass mindestens 95 % der Daten GroupID =2:
haben-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Die Ergebnisse sind ziemlich ähnlich (ich werde von nun an aufhören, das MAXDOP-Ding auszuprobieren):

Und wenn wir es in die andere Richtung drehen, wo mindestens 95 % der Daten RoleID =2 haben:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Ergebnisse:

Schlussfolgerung
In keinem einzigen Fall, den ich herstellen konnte, übertraf die „einfachere“ ORDER BY-Abfrage – sogar mit einem Clustered-Index-Scan weniger – die komplexere UNION ALL-Abfrage. Manchmal müssen Sie sehr vorsichtig sein, was SQL Server tun muss, wenn Sie Operationen wie Sortierungen in Ihre Abfragesemantik einführen, und sich nicht allein auf die Einfachheit des Plans verlassen (ganz zu schweigen von etwaigen Vorurteilen, die Sie aufgrund früherer Szenarien haben könnten). P>
Ihr erster Instinkt mag oft richtig sein, aber ich wette, es gibt Zeiten, in denen es eine bessere Option gibt, die oberflächlich betrachtet so aussieht, als könnte sie unmöglich besser funktionieren. Wie in diesem Beispiel. Ich werde ein bisschen besser darin, Annahmen zu hinterfragen, die ich aus Beobachtungen gemacht habe, und keine pauschalen Aussagen wie „Scans funktionieren nie gut“ und „einfachere Abfragen laufen immer schneller“ zu machen. Wenn Sie die Wörter niemals und immer aus Ihrem Vokabular streichen, stellen Sie möglicherweise mehr dieser Annahmen und pauschalen Aussagen auf die Probe und sind am Ende viel besser dran.