Jedes Produkt hat Fehler, und SQL Server ist keine Ausnahme. Die Verwendung von Produktfunktionen auf etwas ungewöhnliche Weise (oder die Kombination relativ neuer Funktionen) ist eine großartige Möglichkeit, sie zu finden. Fehler können interessant und sogar lehrreich sein, aber vielleicht gehen einige der Freuden verloren, wenn die Entdeckung dazu führt, dass Ihr Pager um 4 Uhr morgens klingelt, vielleicht nach einem besonders geselligen Abend mit Freunden …
Der Fehler, um den es in diesem Beitrag geht, ist in freier Wildbahn wahrscheinlich ziemlich selten, aber es ist kein klassischer Grenzfall. Ich kenne mindestens einen Berater, der in einem Produktionssystem darauf gestoßen ist. Zu einem völlig anderen Thema sollte ich diese Gelegenheit nutzen, um dem Grumpy Old DBA (Blog) "Hallo" zu sagen.
Ich beginne mit einigen relevanten Hintergrundinformationen zu Merge-Joins. Wenn Sie sicher sind, dass Sie bereits alles wissen, was es über Merge-Join zu wissen gibt, oder einfach nur auf den Punkt kommen möchten, können Sie nach unten zum Abschnitt „Der Fehler“ scrollen.
Join zusammenführen
Merge Join ist keine besonders komplizierte Sache und kann unter den richtigen Umständen sehr effizient sein. Es erfordert, dass seine Eingaben nach den Join-Schlüsseln sortiert sind, und funktioniert am besten im Eins-zu-viele-Modus (wobei mindestens eine seiner Eingaben auf den Join-Schlüsseln eindeutig ist). Für Eins-zu-Viele-Joins mittlerer Größe ist ein serieller Merge-Join überhaupt keine schlechte Wahl, vorausgesetzt, die Sortieranforderungen für die Eingabe können erfüllt werden, ohne dass eine explizite Sortierung durchgeführt wird.
Das Vermeiden einer Sortierung wird am häufigsten erreicht, indem die durch einen Index bereitgestellte Reihenfolge ausgenutzt wird. Merge Join kann auch die beibehaltene Sortierreihenfolge einer früheren, unvermeidlichen Sortierung nutzen. Eine coole Sache am Merge-Join ist, dass es die Verarbeitung von Eingabezeilen stoppen kann, sobald eine der Eingaben keine Zeilen mehr hat. Eine letzte Sache:Merge Join kümmert sich nicht darum, ob die Sortierreihenfolge der Eingaben aufsteigend oder absteigend ist (obwohl beide Eingaben gleich sein müssen). Das folgende Beispiel verwendet eine standardmäßige Numbers-Tabelle, um die meisten der obigen Punkte zu veranschaulichen:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Beachten Sie, dass die Indizes, die die Primärschlüssel für diese beiden Tabellen erzwingen, als absteigend definiert sind. Der Abfrageplan für INSERT hat eine Reihe interessanter Funktionen:
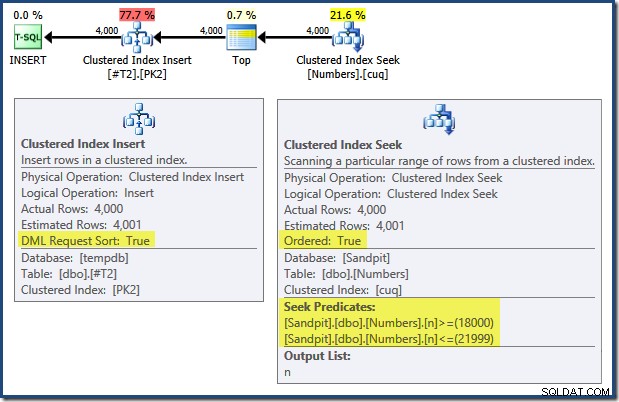
Von links nach rechts gelesen (was nur sinnvoll ist!) hat das Clustered Index Insert die Eigenschaft "DML Request Sort". Das bedeutet, dass der Operator Zeilen in der Reihenfolge der Clustered-Index-Schlüssel benötigt. Der gruppierte Index (der in diesem Fall den Primärschlüssel erzwingt) ist als DESC definiert , daher müssen Zeilen mit höheren Werten zuerst ankommen. Der gruppierte Index in meiner Numbers-Tabelle ist ASC , sodass der Abfrageoptimierer eine explizite Sortierung vermeidet, indem er zuerst nach der höchsten Übereinstimmung in der Numbers-Tabelle (21.999) sucht und dann in umgekehrter Indexreihenfolge nach der niedrigsten Übereinstimmung (18.000) sucht. Die "Plan Tree"-Ansicht im SQL Sentry Plan Explorer zeigt den umgekehrten (rückwärtigen) Scan deutlich:
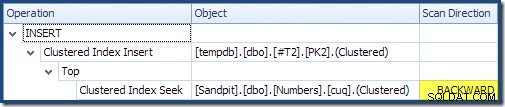
Beim Rückwärtsscannen wird die natürliche Reihenfolge des Indexes umgekehrt. Ein Rückwärtsscan eines ASC Indexschlüssel gibt Zeilen in absteigender Schlüsselreihenfolge zurück; ein Rückwärtsscan eines DESC Indexschlüssel gibt Zeilen in aufsteigender Schlüsselreihenfolge zurück. Die "Scan-Richtung" zeigt nicht die zurückgegebene Schlüsselreihenfolge an – Sie müssen wissen, ob der Index ASC ist oder DESC um diese Entscheidung zu treffen.
Unter Verwendung dieser Testtabellen und -daten (T1 hat 10.000 Zeilen, die von 10.000 bis einschließlich 19.999 nummeriert sind; T2 hat 4.000 Zeilen, die von 18.000 bis 21.999 nummeriert sind), fügt die folgende Abfrage die beiden Tabellen zusammen und gibt Ergebnisse in absteigender Reihenfolge beider Schlüssel zurück:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; Die Abfrage gibt erwartungsgemäß die richtigen übereinstimmenden 2.000 Zeilen zurück. Der Nachausführungsplan sieht wie folgt aus:
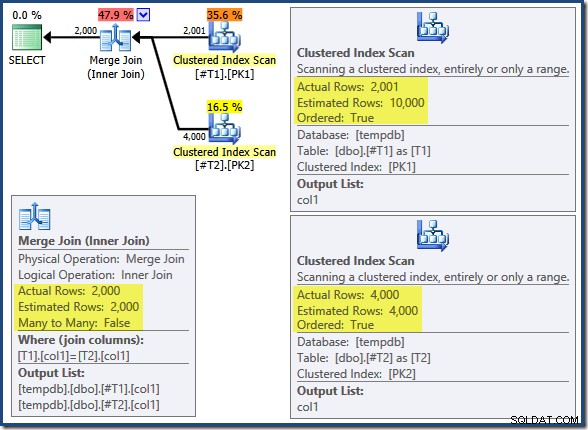
Der Merge Join wird nicht im Many-to-Many-Modus ausgeführt (die obere Eingabe ist auf den Join-Schlüsseln eindeutig), und die Kardinalitätsschätzung von 2.000 Zeilen ist genau richtig. Der Clustered Index Scan der Tabelle T2 geordnet ist (obwohl wir einen Moment warten müssen, um herauszufinden, ob diese Reihenfolge vorwärts oder rückwärts ist) und die Kardinalitätsschätzung von 4.000 Zeilen ist auch genau richtig. Der Clustered Index Scan der Tabelle T1 wird ebenfalls bestellt, aber es wurden nur 2.001 Zeilen gelesen, während 10.000 geschätzt wurden. Die Planbaumansicht zeigt, dass beide Clustered Index Scans vorwärts geordnet sind:
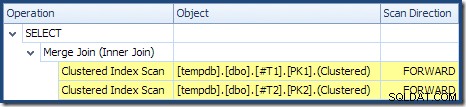
Erinnern Sie sich an das Lesen eines DESC Index FORWARD erzeugt Zeilen in umgekehrter Schlüsselreihenfolge. Genau das wird von ORDER BY T1.col DESC, T2.col1 DESC gefordert -Klausel, sodass keine explizite Sortierung erforderlich ist. Pseudo-Code für One-to-Many Merge Join (reproduziert aus Craig Freedmans Merge Join-Blog) ist:

Der Scan in absteigender Reihenfolge von T1 gibt Zeilen zurück, die bei 19.999 beginnen und auf 10.000 herunterarbeiten. Der Scan in absteigender Reihenfolge von T2 gibt Zeilen zurück, die bei 21.999 beginnen und auf 18.000 herunterarbeiten. Alle 4.000 Zeilen in T2 werden schließlich gelesen, aber der iterative Zusammenführungsprozess stoppt, wenn der Schlüsselwert 17.999 aus T1 gelesen wird , weil T2 läuft aus Reihen. Die Mischverarbeitung wird daher abgeschlossen, ohne T1 vollständig zu lesen . Es liest Zeilen von 19.999 bis einschließlich 17.999; insgesamt 2.001 Zeilen, wie im Ausführungsplan oben gezeigt.
Fühlen Sie sich frei, den Test mit ASC erneut auszuführen Indizes stattdessen, wobei auch ORDER BY geändert wird Klausel aus DESC zu ASC . Der erstellte Ausführungsplan wird sehr ähnlich sein und es werden keine Sortierungen benötigt.
Um die gleich wichtigen Punkte zusammenzufassen, erfordert Merge Join nach Join-Schlüsseln sortierte Eingaben, aber es spielt keine Rolle, ob die Schlüssel aufsteigend oder absteigend sortiert sind.
Der Fehler
Um den Fehler zu reproduzieren, muss mindestens eine unserer Tabellen partitioniert werden. Um die Ergebnisse überschaubar zu halten, verwendet dieses Beispiel nur eine kleine Anzahl von Zeilen, sodass die Partitionierungsfunktion auch kleine Grenzen benötigt:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
Die erste Tabelle enthält zwei Spalten und ist nach PRIMARY KEY partitioniert:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
Die zweite Tabelle ist nicht partitioniert. Sie enthält einen Primärschlüssel und eine Spalte, die mit der ersten Tabelle verknüpft wird:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); Die Beispieldaten
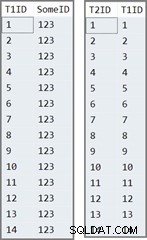
Die erste Tabelle hat 14 Zeilen, alle mit demselben Wert in SomeID Säule. SQL Server weist die IDENTITY zu Spaltenwerte, nummeriert von 1 bis 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
Die zweite Tabelle wird einfach mit der IDENTITY gefüllt Werte aus Tabelle eins:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
Die Daten in den beiden Tabellen sehen folgendermaßen aus:
Die Testabfrage
Die erste Abfrage verbindet einfach beide Tabellen und wendet ein einziges WHERE-Klausel-Prädikat an (das in diesem stark vereinfachten Beispiel zufällig mit allen Zeilen übereinstimmt):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; Das Ergebnis enthält wie erwartet alle 14 Zeilen:

Aufgrund der geringen Anzahl von Zeilen wählt der Optimierer für diese Abfrage einen Join-Plan mit verschachtelten Schleifen aus:
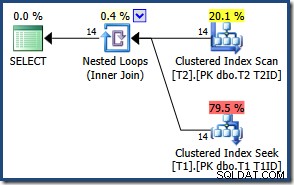
Die Ergebnisse sind die gleichen (und immer noch korrekt), wenn wir einen Hash- oder Merge-Join erzwingen:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
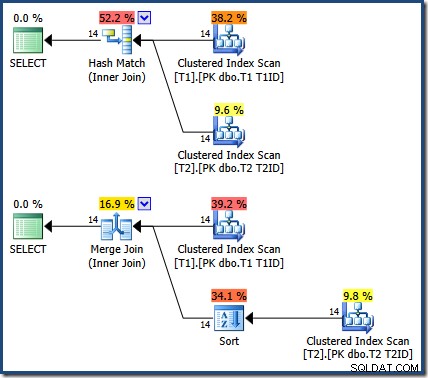
Der Merge-Join dort ist Eins-zu-Viele, mit einer expliziten Sortierung nach T1ID erforderlich für Tabelle T2 .
Das Problem des absteigenden Index
Alles ist gut, bis eines Tages (aus guten Gründen, die uns hier nicht interessieren müssen) ein anderer Administrator einen absteigenden Index auf der SomeID hinzufügt Spalte von Tabelle 1:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Unsere Abfrage liefert weiterhin korrekte Ergebnisse, wenn der Optimierer einen Nested Loops- oder Hash-Join auswählt, aber es ist eine andere Geschichte, wenn ein Merge-Join verwendet wird. Im Folgenden wird immer noch ein Abfragehinweis verwendet, um den Merge Join zu erzwingen, aber dies ist nur eine Folge der niedrigen Zeilenanzahl im Beispiel. Der Optimierer würde natürlich denselben Merge-Join-Plan mit unterschiedlichen Tabellendaten wählen.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); Der Ausführungsplan ist:
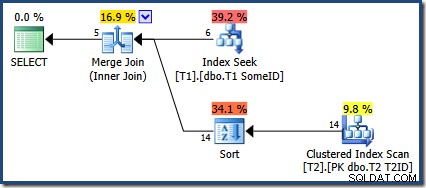
Der Optimierer hat sich entschieden, den neuen Index zu verwenden, aber die Abfrage erzeugt jetzt nur fünf Ausgabezeilen:

Was ist mit den anderen 9 Reihen passiert? Um es klarzustellen, dieses Ergebnis ist falsch. Die Daten haben sich nicht geändert, daher sollten alle 14 Zeilen zurückgegeben werden (wie sie es immer noch mit einem Nested Loops- oder Hash Join-Plan sind).
Ursache und Erklärung
Der neue nicht gruppierte Index auf SomeID wird nicht als eindeutig deklariert, sodass der Clustered-Indexschlüssel stillschweigend zu allen Nonclustered-Indexebenen hinzugefügt wird. SQL Server fügt die T1ID hinzu -Spalte (der gruppierte Schlüssel) in den nicht gruppierten Index, so als ob wir den Index folgendermaßen erstellt hätten:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Beachten Sie das Fehlen eines DESC Qualifizierer für die stillschweigend hinzugefügte T1ID Schlüssel. Indexschlüssel sind ASC standardmäßig. Dies ist an sich kein Problem (obwohl es dazu beiträgt). Das zweite, was automatisch mit unserem Index passiert, ist, dass er genauso partitioniert wird wie die Basistabelle. Die vollständige Indexspezifikation wäre also, wenn wir sie explizit ausschreiben würden:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Das ist jetzt eine recht komplexe Struktur mit Schlüsseln in allen möglichen unterschiedlichen Reihenfolgen. Es ist komplex genug für den Abfrageoptimierer, sich zu irren, wenn er über die vom Index bereitgestellte Sortierreihenfolge nachdenkt. Betrachten Sie zur Veranschaulichung die folgende einfache Abfrage:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
Die zusätzliche Spalte zeigt uns nur, in welche Partition die aktuelle Zeile gehört. Andernfalls ist es nur eine einfache Abfrage, die T1ID zurückgibt Werte in aufsteigender Reihenfolge, WHERE SomeID = 123 . Leider entsprechen die Ergebnisse nicht den Angaben der Abfrage:
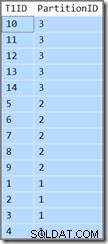
Die Abfrage erfordert diese T1ID Werte sollten in aufsteigender Reihenfolge zurückgegeben werden, aber das bekommen wir nicht. Wir erhalten Werte in aufsteigender Reihenfolge pro Partition , aber die Partitionen selbst werden in umgekehrter Reihenfolge zurückgegeben! Wenn die Partitionen in aufsteigender Reihenfolge zurückgegeben wurden (und die T1ID Werte blieben wie gezeigt innerhalb jeder Partition sortiert), wäre das Ergebnis korrekt.
Der Abfrageplan zeigt, dass der Optimierer durch das führende DESC verwirrt wurde Schlüssel des Indexes und dachte, es müsse die Partitionen in umgekehrter Reihenfolge lesen, um korrekte Ergebnisse zu erhalten:
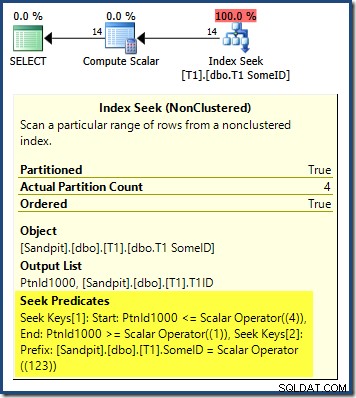
Die Partitionssuche beginnt bei der Partition ganz rechts (4) und fährt rückwärts mit Partition 1 fort. Sie könnten denken, wir könnten das Problem beheben, indem wir explizit nach Partitionsnummer ASC sortieren im Feld ORDER BY Klausel:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Diese Abfrage gibt dieselben Ergebnisse zurück (Dies ist kein Druckfehler oder ein Kopier-/Einfügefehler):
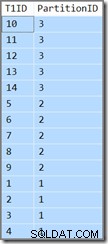
Die Partitions-ID ist immer noch absteigend Reihenfolge (nicht aufsteigend, wie angegeben) und T1ID wird nur innerhalb jeder Partition aufsteigend sortiert. Die Verwirrung des Optimierers ist so groß, dass er wirklich glaubt (atmen Sie jetzt tief durch), dass das Scannen des partitionierten Index für führende und absteigende Schlüssel in Vorwärtsrichtung, aber mit umgekehrten Partitionen, zu der durch die Abfrage angegebenen Reihenfolge führen wird.
Um ehrlich zu sein, mache ich mir keine Vorwürfe, die verschiedenen Überlegungen zur Sortierreihenfolge tun mir auch weh.
Betrachten Sie als letztes Beispiel:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; Die Ergebnisse sind:

Wieder die T1ID Sortierreihenfolge innerhalb jeder Partition ist korrekt absteigend, aber die Partitionen selbst werden rückwärts aufgelistet (sie gehen von 1 bis 3 die Zeilen hinunter). Wenn die Partitionen in umgekehrter Reihenfolge zurückgegeben würden, wären die Ergebnisse korrekterweise 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Zurück zum Merge-Join
Die Ursache für die falschen Ergebnisse bei der Merge-Join-Abfrage ist jetzt offensichtlich:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
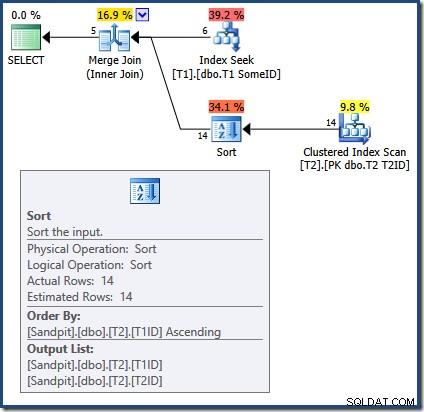
Der Merge Join erfordert sortierte Eingaben. Die Eingabe von T2 wird explizit nach T1TD sortiert also ist das ok. Der Optimierer begründet fälschlicherweise, dass der Index auf T1 kann Zeilen in T1ID bereitstellen Befehl. Wie wir gesehen haben, ist dies nicht der Fall. Der Index Seek erzeugt dieselbe Ausgabe wie eine Abfrage, die wir bereits gesehen haben:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Nur die ersten 5 Zeilen befinden sich in T1ID Befehl. Der nächste Wert (5) ist sicherlich nicht in aufsteigender Reihenfolge, und der Merge Join interpretiert dies als Stream-Ende, anstatt einen Fehler zu erzeugen (persönlich habe ich hier eine Retail-Assertion erwartet). Jedenfalls führt dies dazu, dass die Merge Join-Verarbeitung fälschlicherweise vorzeitig beendet wird. Zur Erinnerung, die (unvollständigen) Ergebnisse sind:

Schlussfolgerung
Dies ist aus meiner Sicht ein sehr schwerwiegender Fehler. Eine einfache Indexsuche kann Ergebnisse zurückgeben, die ORDER BY nicht berücksichtigen Klausel. Genauer gesagt ist die interne Argumentation des Optimierers völlig kaputt für partitionierte, nicht eindeutige, nicht gruppierte Indizes mit einem absteigenden führenden Schlüssel.
Ja, das ist ein etwas ungewöhnliche Anordnung. Aber wie wir gesehen haben, können korrekte Ergebnisse plötzlich durch falsche Ergebnisse ersetzt werden, nur weil jemand einen absteigenden Index hinzugefügt hat. Denken Sie daran, dass der hinzugefügte Index unschuldig genug aussah:kein explizites ASC/DESC Schlüsselkonflikt und keine explizite Partitionierung.
Der Fehler ist nicht auf Merge Joins beschränkt. Potenziell könnte jede Abfrage zum Opfer fallen, die eine partitionierte Tabelle beinhaltet und die auf der Indexsortierreihenfolge (explizit oder implizit) beruht. Dieser Fehler ist in allen Versionen von SQL Server von 2008 bis einschließlich 2014 CTP 1 vorhanden. Die Windows SQL Azure-Datenbank unterstützt keine Partitionierung, daher tritt das Problem nicht auf. SQL Server 2005 verwendete ein anderes Implementierungsmodell für die Partitionierung (basierend auf APPLY ) und leidet auch nicht unter diesem Problem.
Wenn Sie einen Moment Zeit haben, erwägen Sie bitte, über mein Connect-Element für diesen Fehler abzustimmen.
Auflösung
Die Lösung für dieses Problem ist jetzt verfügbar und in einem Knowledge Base-Artikel dokumentiert. Bitte beachten Sie, dass der Fix eine Codeaktualisierung und das Trace-Flag 4199 erfordert , wodurch eine Reihe anderer Änderungen am Abfrageprozessor aktiviert werden. Es ist ungewöhnlich, dass ein Fehler mit falschen Ergebnissen unter 4199 behoben wird. Ich bat darum, dies zu klären, und die Antwort lautete:
Obwohl dieses Problem wie andere Hotfixes, die den Abfrageprozessor betreffen, zu falschen Ergebnissen führt, haben wir diesen Fix nur unter Ablaufverfolgungsflag 4199 für SQL Server 2008, 2008 R2 und 2012 aktiviert. Dieser Fix ist jedoch von aktiviert standardmäßig ohne das Trace-Flag in SQL Server 2014 RTM.