Eine der vielen Verbesserungen von Ausführungsplänen in SQL Server 2012 war das Hinzufügen von Threadreservierungs- und Nutzungsinformationen für parallele Ausführungspläne. Dieser Beitrag befasst sich genau mit der Bedeutung dieser Zahlen und bietet zusätzliche Einblicke in das Verständnis der parallelen Ausführung.
Betrachten Sie die folgende Abfrage, die für eine erweiterte Version der AdventureWorks-Datenbank ausgeführt wird:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; Der Abfrageoptimierer wählt einen parallelen Ausführungsplan:
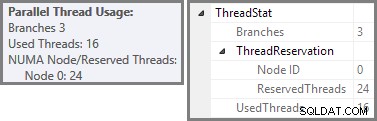
Der Plan-Explorer zeigt Details zur Nutzung paralleler Threads im Tooltip des Stammknotens an. Um dieselben Informationen in SSMS anzuzeigen, klicken Sie auf den Stammknoten des Plans, öffnen Sie das Eigenschaftenfenster und erweitern Sie ThreadStat Knoten. Unter Verwendung eines Computers mit acht logischen Prozessoren, die SQL Server zur Verfügung stehen, werden die Threadnutzungsinformationen einer typischen Ausführung dieser Abfrage unten angezeigt, Plan-Explorer links, SSMS-Ansicht rechts:
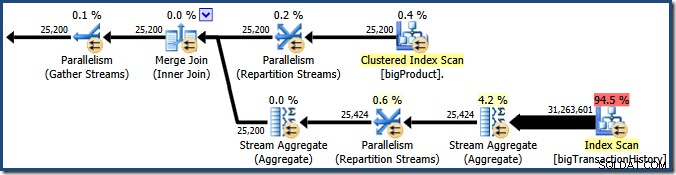
Der Screenshot zeigt, dass die Ausführungs-Engine 24 Threads für diese Abfrage reserviert und am Ende 16 davon verwendet hat. Es zeigt auch, dass der Abfrageplan drei Zweige hat , obwohl es nicht genau sagt, was ein Zweig ist. Wenn Sie meinen Simple Talk-Artikel zur parallelen Abfrageausführung gelesen haben, wissen Sie, dass Verzweigungen Abschnitte eines parallelen Abfrageplans sind, die durch Austauschoperatoren begrenzt sind. Das folgende Diagramm zeigt die Grenzen und nummeriert die Zweige (zum Vergrößern anklicken):

Zweig zwei (Orange)
Schauen wir uns zunächst den zweiten Zweig etwas genauer an:
Bei einem Parallelitätsgrad (DOP) von acht gibt es acht Threads, die diesen Zweig des Abfrageplans ausführen. Es ist wichtig zu verstehen, dass dies der gesamte Ausführungsplan ist was diese acht Threads anbelangt – sie haben keine Kenntnis von dem umfassenderen Plan.
In einem seriellen Ausführungsplan liest ein einzelner Thread Daten aus einer Datenquelle, verarbeitet die Zeilen durch eine Reihe von Planoperatoren und gibt Ergebnisse an das Ziel zurück (das beispielsweise ein SSMS-Abfrageergebnisfenster oder eine Datenbanktabelle sein kann).
In einer Filiale Bei einem parallelen Ausführungsplan ist die Situation sehr ähnlich:Jeder Thread liest Daten aus einer Quelle, verarbeitet die Zeilen durch eine Reihe von Planoperatoren und gibt Ergebnisse an das Ziel zurück. Die Unterschiede bestehen darin, dass das Ziel ein Austausch-(Parallelitäts-)Operator ist und die Datenquelle auch ein Austausch sein kann.
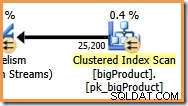
Im orangefarbenen Zweig ist die Datenquelle ein Clustered Index Scan, und das Ziel ist die rechte Seite eines Repartition Streams-Austauschs. Die rechte Seite einer Börse wird als Produzentenseite bezeichnet , weil es sich mit einem Zweig verbindet, der Daten zum Austausch hinzufügt.
Die acht Threads im orangefarbenen Zweig arbeiten zusammen, um die Tabelle zu scannen und dem Austausch Zeilen hinzuzufügen. Die Vermittlungsstelle fügt Reihen zu seitengroßen Paketen zusammen. Sobald ein Paket voll ist, wird es über die Vermittlungsstelle auf die andere Seite geschoben. Wenn die Vermittlungsstelle ein weiteres leeres Paket zum Füllen zur Verfügung hat, wird der Prozess fortgesetzt, bis alle Datenquellenzeilen verarbeitet wurden (oder die Vermittlungsstelle keine leeren Pakete mehr hat).
Wir können die Anzahl der Zeilen sehen, die in jedem Thread verarbeitet werden, indem wir die Plan-Strukturansicht im Plan-Explorer verwenden:
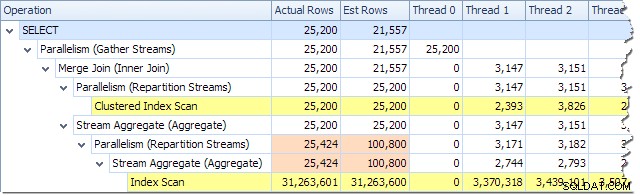
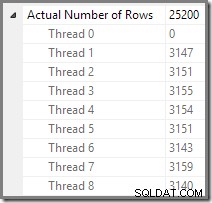
Plan Explorer macht es einfach zu sehen, wie Zeilen für alle auf Threads verteilt sind die physischen Operationen im Plan. In SSMS sind Sie darauf beschränkt, die Zeilenverteilung für einen einzelnen Planoperator anzuzeigen. Klicken Sie dazu auf ein Operatorsymbol, öffnen Sie das Eigenschaftenfenster und erweitern Sie dann den Knoten Tatsächliche Zeilenanzahl. Die folgende Grafik zeigt SSMS-Informationen für den Repartition Streams-Knoten an der Grenze zwischen den orangefarbenen und violetten Zweigen:
Zweig Drei (Grün)
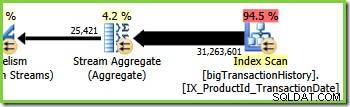
Zweig drei ähnelt Zweig zwei, enthält jedoch einen zusätzlichen Stream Aggregate-Operator. Der grüne Zweig hat auch acht Fäden, insgesamt sind es bisher sechzehn. Die acht Green-Branch-Threads lesen Daten aus einem Nonclustered Index Scan, führen eine Art Aggregation durch und leiten die Ergebnisse an die Produzentenseite eines anderen Repartition Streams-Austauschs weiter.
Die Kurzinfo des Plan-Explorers für das Stream-Aggregat zeigt, dass es nach Produkt-ID gruppiert und einen Ausdruck mit der Bezeichnung partialagg1005 berechnet :
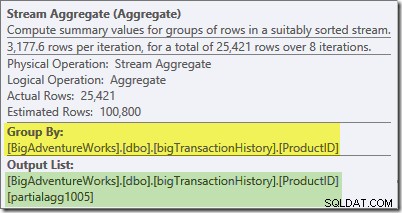
Die Registerkarte „Ausdrücke“ zeigt, dass der Ausdruck das Ergebnis der Zählung der Zeilen in jeder Gruppe ist:

Das Stream-Aggregat berechnet einen Teil (auch bekannt als „lokales“) Aggregat. Der partielle (oder lokale) Qualifizierer bedeutet einfach, dass jeder Thread das Aggregat auf den Zeilen berechnet, die er sieht. Zeilen aus dem Index-Scan werden unter Verwendung eines bedarfsbasierten Schemas zwischen Threads verteilt:Es gibt keine feste Verteilung von Zeilen im Voraus; Threads erhalten eine Reihe von Zeilen aus dem Scan, wenn sie danach fragen. Welche Zeilen in welchen Threads landen, ist im Wesentlichen zufällig, da dies von Timing-Problemen und anderen Faktoren abhängt.
Jeder Thread sieht unterschiedliche Zeilen aus dem Scan, aber Zeilen mit gleicher Produkt-ID kann von mehr als einem Thread gesehen werden. Das Aggregat ist „teilweise“, da Zwischensummen für eine bestimmte Produkt-ID-Gruppe in mehr als einem Thread erscheinen können; es ist 'lokal', weil jeder Thread sein Ergebnis nur basierend auf den Zeilen berechnet, die er zufällig erhält. Angenommen, die Tabelle enthält 1.000 Zeilen für die Produkt-ID Nr. 1. Ein Thread könnte zufällig 432 dieser Zeilen sehen, während ein anderer 568 sehen könnte. Beide Threads haben einen Teil Anzahl der Zeilen für Produkt-ID #1 (432 in einem Thread, 568 in dem anderen).
Die teilweise Aggregation ist eine Leistungsoptimierung, da sie die Anzahl der Zeilen früher reduziert, als dies sonst möglich wäre. Im grünen Zweig führt die frühe Aggregation dazu, dass weniger Zeilen zu Paketen zusammengesetzt und über den Repartition Stream-Austausch geschoben werden.
Zweig 1 (lila)

Der violette Zweig hat acht weitere Fäden, also bisher vierundzwanzig. Jeder Thread in diesem Zweig liest Zeilen aus den beiden Repartition Streams-Austauschvorgängen und schreibt Zeilen in einen Gather Streams-Austauschvorgang. Dieser Zweig mag kompliziert und ungewohnt erscheinen, aber er liest nur Zeilen aus einer Datenquelle und sendet Ergebnisse an ein Ziel, wie jeder andere Abfrageplan auch.
Die rechte Seite des Plans zeigt Daten, die von der anderen Seite der beiden Repartition Streams-Austausche gelesen werden, die in den orangefarbenen und grünen Zweigen zu sehen sind. Diese (linke) Seite der Börse wird als Verbraucher bezeichnet Seite, da hier angehängte Threads Zeilen lesen (verbrauchen). Die acht violetten Zweigfäden sind Verbraucher von Daten an den beiden Repartition Streams-Börsen.
Die linke Seite des violetten Zweigs zeigt Zeilen, die an den Produzenten geschrieben werden Seite einer Gather Streams-Börse. Die gleichen acht Threads (das sind Verbraucher an den Repartition Streams-Börsen) führen einen Produzenten aus Rolle hier.
Jeder Thread im violetten Zweig führt jeden Operator im Zweig aus, so wie ein einzelner Thread jede Operation in einem seriellen Ausführungsplan ausführt. Der Hauptunterschied besteht darin, dass acht Threads gleichzeitig ausgeführt werden, von denen jeder zu einem bestimmten Zeitpunkt an einer anderen Zeile arbeitet und verschiedene Instanzen verwendet der Abfrageplanoperatoren.
Das Stream-Aggregat in diesem Zweig ist ein globales Aggregat. Es kombiniert die partiellen (lokalen) Aggregate, die im grünen Zweig berechnet wurden (denken Sie an das Beispiel einer Zählung von 432 in einem Thread und 568 in dem anderen), um eine kombinierte Summe für jede Produkt-ID zu erzeugen. Die Kurzinfo des Plan-Explorers zeigt den globalen Ergebnisausdruck mit der Bezeichnung Expr1004:
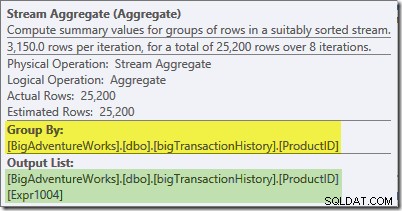
Das korrekte globale Ergebnis pro Produkt-ID wird berechnet, indem die partiellen Aggregate summiert werden, wie die Registerkarte „Ausdrücke“ zeigt:
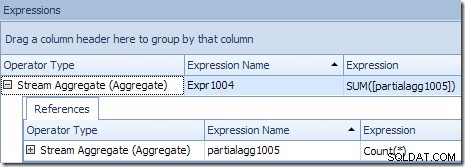
Um unser (imaginäres) Beispiel fortzusetzen, das korrekte Ergebnis von 1.000 Zeilen für die Produkt-ID Nr. 1 wird durch Summieren der beiden Zwischensummen von 432 und 568 erhalten.
Jeder der acht violetten Zweig-Threads liest Daten von der Verbraucherseite der beiden Gather Streams-Börsen, berechnet die globalen Aggregate, führt den Merge Join für die Produkt-ID aus und fügt dem Gather Streams-Austausch ganz links vom violetten Zweig Zeilen hinzu. Der Kernprozess unterscheidet sich nicht sehr von einem gewöhnlichen Serienplan; die Unterschiede liegen darin, wo Zeilen gelesen werden, wohin sie gesendet werden und wie Zeilen zwischen den Threads verteilt werden…
Zeilenverteilung austauschen
Der aufmerksame Leser wird sich an dieser Stelle über ein paar Details wundern. Wie schafft es der lila Zweig, korrekte Ergebnisse pro Produkt-ID zu berechnen aber der grüne Zweig konnte dies nicht (Ergebnisse für dieselbe Produkt-ID wurden über viele Threads verteilt)? Außerdem, wenn es acht separate Zusammenführungsverknüpfungen gibt (eine pro Thread), wie garantiert SQL Server, dass Zeilen, die verknüpft werden, in derselben Instanz enden des Joins?
Diese beiden Fragen können beantwortet werden, indem man sich ansieht, wie die beiden Repartition Streams-Börsen Zeilen von der Erzeugerseite (im grünen und orangefarbenen Zweig) zur Verbraucherseite (im violetten Zweig) leiten. Wir werden uns zuerst den Repartition Streams-Austausch ansehen, der an die orangefarbenen und violetten Zweige grenzt:
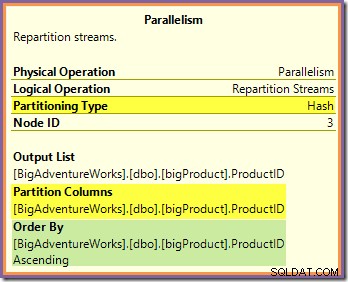
Dieser Austausch leitet eingehende Zeilen (vom orangefarbenen Zweig) mithilfe einer Hash-Funktion weiter, die auf die Produkt-ID-Spalte angewendet wird. Der Effekt ist, dass alle Zeilen für eine bestimmte Produkt-ID garantiert sind an denselben Purple-Branch-Thread geroutet werden. Die orangefarbenen und violetten Fäden wissen nichts von dieser Führung; all dies wird intern von der Börse gehandhabt.
Alles, was die orangefarbenen Threads wissen, ist, dass sie Zeilen an den übergeordneten Iterator zurückgeben, der sie angefordert hat (die Erzeugerseite des Austauschs). Ebenso „wissen“ die violetten Threads nur, dass sie Zeilen aus einer Datenquelle lesen. Der Austausch bestimmt, in welches Paket eine eingehende Orange-Thread-Reihe geht, und es könnte eines von acht Kandidatenpaketen sein. In ähnlicher Weise bestimmt der Austausch, aus welchem Paket eine Zeile gelesen werden soll, um eine Leseanforderung von einem lila Thread zu erfüllen.
Achten Sie darauf, sich kein mentales Bild von einem bestimmten orangefarbenen (Erzeuger-) Faden zu machen, der direkt mit einem bestimmten violetten (Verbraucher-) Faden verbunden ist. So funktioniert dieser Abfrageplan nicht. Ein Orangenproduzent darf Am Ende werden Zeilen an alle violetten Verbraucher gesendet – das Routing hängt vollständig vom Wert der Produkt-ID-Spalte in jeder verarbeiteten Zeile ab.
Beachten Sie auch, dass ein Zeilenpaket an der Vermittlungsstelle nur dann übertragen wird, wenn es voll ist (oder wenn auf der Produzentenseite die Daten ausgehen). Stellen Sie sich vor, der Austausch füllt Pakete zeilenweise, wobei Zeilen für ein bestimmtes Paket aus einem beliebigen (orangefarbenen) Thread der Herstellerseite stammen können. Sobald ein Paket voll ist, wird es an die Verbraucherseite weitergeleitet, wo ein bestimmter (lila) Verbraucher-Thread mit dem Lesen beginnen kann.
Der Repartition Streams-Austausch, der an die grünen und violetten Zweige grenzt, funktioniert auf sehr ähnliche Weise:
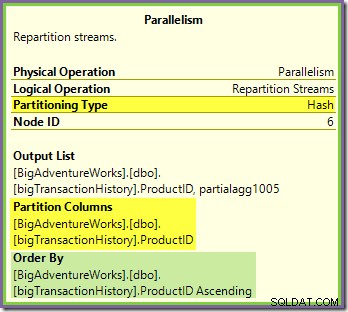
Zeilen werden in diesem Austausch unter Verwendung der gleichen Hash-Funktion zu Paketen geleitet auf der gleichen Partitionierungsspalte wie für den zuvor gesehenen orange-violetten Austausch. Das bedeutet, dass beides Repartition Streams tauscht Routenzeilen mit derselben Produkt-ID mit demselben Purple-Branch-Thread aus.
Dies erklärt, wie das Stream-Aggregat im lila Zweig globale Aggregate berechnen kann – wenn eine Zeile mit einer bestimmten Produkt-ID in einem bestimmten lila-Zweig-Thread gesehen wird, sieht dieser Thread garantiert alle Zeilen für diese Produkt-ID (und Nr anderer Thread wird).
Die Common-Exchange-Partitionierungsspalte ist auch der Join-Schlüssel für den Merge-Join, sodass alle Zeilen, die möglicherweise verknüpft werden können, garantiert vom selben (violetten) Thread verarbeitet werden.
Eine letzte Sache, die zu beachten ist, ist, dass beide Börsen ordnungserhaltend sind (auch bekannt als „Zusammenführen“), wie im Attribut „Ordnen nach“ in den QuickInfos gezeigt. Dies erfüllt die Merge-Join-Anforderung, dass Eingabezeilen nach den Join-Schlüsseln sortiert werden. Beachten Sie, dass Börsen niemals Zeilen selbst sortieren, sie können einfach so konfiguriert werden, dass sie beibehalten werden bestehende Bestellung.
Thread Null
Der letzte Teil des Ausführungsplans liegt links neben der Gather Streams-Börse. Es läuft immer auf einem einzigen Thread – dem gleichen Thread, der verwendet wird, um den gesamten regulären seriellen Plan auszuführen. Dieser Thread wird in Ausführungsplänen immer als 'Thread 0' bezeichnet und wird manchmal als 'Koordinator'-Thread bezeichnet (eine Bezeichnung, die ich nicht besonders hilfreich finde).
Thread null liest Zeilen von der Consumer-Seite (links) des Gather Streams-Austauschs und gibt sie an den Client zurück. Abgesehen vom Austausch gibt es in diesem Beispiel keine Thread-Null-Iteratoren, aber wenn es welche gäbe, würden sie alle auf demselben einzelnen Thread laufen. Beachten Sie, dass Gather Streams auch ein Zusammenführungsaustausch ist (es hat ein Order By-Attribut):

Komplexere parallele Pläne können andere serielle Ausführungszonen als die links vom endgültigen Gather Streams-Austausch enthalten. Diese seriellen Zonen werden nicht in Thread Null ausgeführt, aber das ist ein Detail, das ein anderes Mal untersucht werden sollte.
Reservierte und verwendete Threads erneut besucht
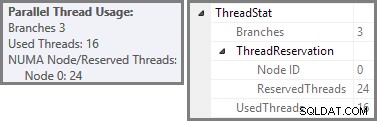
Wir haben gesehen, dass dieser parallele Plan drei Zweige enthält. Dies erklärt, warum SQL Server reserviert 24 Threads (drei Zweige bei DOP 8). Die Frage ist, warum im Screenshot oben nur 16 Threads als 'benutzt' gemeldet werden.
Die Antwort besteht aus zwei Teilen. Der erste Teil gilt nicht für diesen Plan, aber es ist trotzdem wichtig, ihn zu kennen. Die Anzahl der gemeldeten Verzweigungen ist die maximale Anzahl, die gleichzeitig ausgeführt werden kann .
Wie Sie vielleicht wissen, „blockieren“ bestimmte Planoperatoren – was bedeutet, dass sie alle ihre Eingabezeilen verbrauchen müssen, bevor sie die erste Ausgabezeile erzeugen können. Das deutlichste Beispiel für einen Blockierungsoperator (auch bekannt als Stop-and-Go-Operator) ist Sort. Eine Sortierung kann die erste Zeile in der sortierten Reihenfolge nicht zurückgeben, bevor sie alle Eingabezeilen gesehen hat, da die letzte Eingabezeile möglicherweise zuerst sortiert wird.
Operatoren mit mehreren Eingaben (z. B. Joins und Unions) können in Bezug auf eine Eingabe blockieren, in Bezug auf die andere jedoch nicht blockieren („pipelined“). Ein Beispiel hierfür ist ein Hash-Join – die Build-Eingabe blockiert, aber die Sondeneingabe wird per Pipeline verarbeitet. Die Build-Eingabe blockiert, weil sie die Hash-Tabelle erstellt, gegen die Prüfzeilen getestet werden.
Das Vorhandensein von blockierenden Operatoren bedeutet, dass ein oder mehrere parallele Zweige möglicherweise abgeschlossen werden, bevor andere beginnen können. In diesem Fall kann SQL Server wiederverwenden die Threads, die verwendet werden, um eine abgeschlossene Verzweigung für eine spätere Verzweigung in der Sequenz zu verarbeiten. SQL Server ist bei der Thread-Reservierung sehr konservativ, also nur Zweige, die garantiert sind um abzuschließen, bevor ein anderer beginnt, nutzen Sie diese Thread-Reservierungs-Optimierung. Unser Abfrageplan enthält keine blockierenden Operatoren, daher ist die gemeldete Verzweigungszahl nur die Gesamtzahl der Verzweigungen.
Der zweite Teil der Antwort ist, dass Threads immer noch wiederverwendet werden können, wenn sie vorkommen abgeschlossen werden, bevor ein Thread in einem anderen Zweig gestartet wird. In diesem Fall ist immer noch die volle Anzahl Threads reserviert, die tatsächliche Nutzung kann jedoch geringer sein. Wie viele Threads ein paralleler Plan tatsächlich verwendet, hängt unter anderem von Timing-Problemen ab und kann zwischen Ausführungen variieren.
Parallele Threads beginnen nicht alle gleichzeitig mit der Ausführung, aber auch hier müssen die Details auf eine andere Gelegenheit warten. Sehen wir uns noch einmal den Abfrageplan an, um zu sehen, wie Threads trotz fehlender Blockierungsoperatoren wiederverwendet werden können:
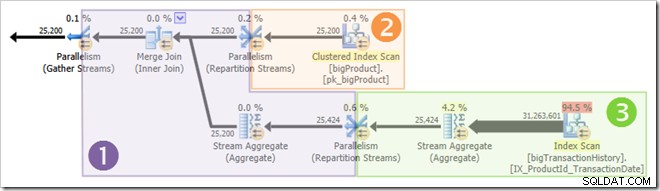
Es ist klar, dass Threads in Verzweigung eins nicht abgeschlossen werden können, bevor Threads in Verzweigungen zwei oder drei gestartet werden, sodass es dort keine Möglichkeit einer Wiederverwendung von Threads gibt. Zweig drei ist auch unwahrscheinlich abgeschlossen werden, bevor entweder Zweig eins oder Zweig zwei gestartet wird, weil es so viel Arbeit zu erledigen gibt (fast 32 Millionen zu aggregierende Zeilen).
Zweig zwei ist eine andere Sache. Aufgrund der relativ geringen Größe der Produkttabelle besteht eine gute Chance, dass die Zweigstelle ihre Arbeit vorher abschließen kann Zweig drei startet. Wenn das Lesen der Produkttabelle zu keinen physischen E/A-Vorgängen führt, dauert es nicht lange, bis acht Threads die 25.200 Zeilen gelesen und an den Repartition Streams-Austausch mit orange-violetter Grenze gesendet haben.
Genau das passierte in den Testläufen, die für die bisher in diesem Beitrag gezeigten Screenshots verwendet wurden:Die acht orangefarbenen Zweigfäden schlossen schnell genug ab, um sie für den grünen Zweig wiederzuverwenden. Insgesamt wurden sechzehn eindeutige Threads verwendet, so berichtet der Ausführungsplan.
Wenn die Abfrage mit einem kalten Cache erneut ausgeführt wird, reicht die durch die physische E/A eingeführte Verzögerung aus, um sicherzustellen, dass grüne Zweigthreads gestartet werden, bevor orangefarbene Zweigthreads abgeschlossen sind. Es werden keine Threads wiederverwendet, daher meldet der Ausführungsplan, dass tatsächlich alle 24 reservierten Threads verwendet wurden:
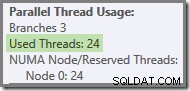
Allgemeiner gesagt ist jede Anzahl von 'benutzten Threads' zwischen den beiden Extremen (16 und 24 für diesen Abfrageplan) möglich:
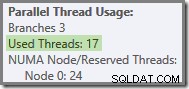
Beachten Sie schließlich, dass der Thread, der den seriellen Teil des Plans links von den letzten Gather Streams ausführt, nicht gezählt wird in den parallelen Thread-Gesamtzahlen. Es ist kein zusätzlicher Thread, der hinzugefügt wird, um eine parallele Ausführung zu ermöglichen.
Abschließende Gedanken
Das Schöne an dem Austauschmodell, das von SQL Server zum Implementieren der parallelen Ausführung verwendet wird, besteht darin, dass die gesamte Komplexität des Pufferns und Verschiebens von Zeilen zwischen Threads in Austauschoperatoren (Parallelismus) verborgen ist. Der Rest des Plans ist in ordentliche "Zweige" aufgeteilt, die durch Börsen begrenzt sind. Innerhalb einer Verzweigung verhält sich jeder Operator genauso wie in einem seriellen Plan – in fast allen Fällen wissen die Verzweigungsoperatoren nicht, dass der umfassendere Plan überhaupt eine parallele Ausführung verwendet.
Der Schlüssel zum Verständnis der parallelen Ausführung besteht darin, den parallelen Plan (mental) an den Austauschgrenzen auseinanderzubrechen und sich jeden Zweig als DOP-separate serielle vorzustellen Pläne, die alle Parallelität auf einer bestimmten Teilmenge von Zeilen ausführen. Denken Sie insbesondere daran, dass jeder dieser seriellen Pläne alle Operatoren in diesem Zweig ausführt – SQL Server tut dies nicht Führen Sie jeden Operator in einem eigenen Thread aus!
Das detaillierteste Verhalten zu verstehen, erfordert ein wenig Nachdenken, insbesondere darüber, wie Zeilen innerhalb des Austauschs geroutet werden und wie die Engine korrekte Ergebnisse garantiert, aber dann erfordern die meisten wissenswerten Dinge ein wenig Nachdenken, nicht wahr?