Der allererste Blogbeitrag auf dieser Seite, weit zurück im Juli 2012, sprach über die besten Ansätze für laufende Gesamtsummen. Seitdem wurde ich mehrfach gefragt, wie ich das Problem angehen würde, wenn die laufenden Summen komplexer wären – insbesondere, wenn ich die laufenden Summen für mehrere Entitäten berechnen müsste – sagen wir die Bestellungen jedes Kunden.
Das ursprüngliche Beispiel verwendete einen fiktiven Fall einer Stadt, die Strafzettel für zu schnelles Fahren ausstellt; Die laufende Summe bestand einfach darin, die Anzahl der Strafzettel für zu schnelles Fahren pro Tag zu aggregieren und zu zählen (unabhängig davon, für wen der Strafzettel ausgestellt wurde oder für wie viel er war). Ein komplexeres (aber praktisches) Beispiel könnte die Zusammenfassung des laufenden Gesamtwerts von Strafzetteln für zu schnelles Fahren, gruppiert nach Führerschein, pro Tag sein. Stellen wir uns folgende Tabelle vor:
CREATE TABLE dbo.SpeedingTickets ( IncidentID INT IDENTITY(1,1) PRIMARY KEY, LicenseNumber INT NOT NULL, IncidentDate DATE NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL ); CREATE UNIQUE INDEX x ON dbo.SpeedingTickets(LicenseNumber, IncidentDate) INCLUDE(TicketAmount);
Sie könnten fragen, DECIMAL(7,2) , Ja wirklich? Wie schnell fahren diese Leute? Nun, in Kanada zum Beispiel ist es gar nicht so schwer, ein Bußgeld von 10.000 $ zu bekommen.
Lassen Sie uns nun die Tabelle mit einigen Beispieldaten füllen. Ich werde hier nicht auf alle Einzelheiten eingehen, aber dies sollte ungefähr 6.000 Zeilen ergeben, die mehrere Fahrer und mehrere Ticketbeträge über einen Zeitraum von einem Monat darstellen:
;WITH TicketAmounts(ID,Value) AS
(
-- 10 arbitrary ticket amounts
SELECT i,p FROM
(
VALUES(1,32.75),(2,75), (3,109),(4,175),(5,295),
(6,68.50),(7,125),(8,145),(9,199),(10,250)
) AS v(i,p)
),
LicenseNumbers(LicenseNumber,[newid]) AS
(
-- 1000 random license numbers
SELECT TOP (1000) 7000000 + number, n = NEWID()
FROM [master].dbo.spt_values
WHERE number BETWEEN 1 AND 999999
ORDER BY n
),
JanuaryDates([day]) AS
(
-- every day in January 2014
SELECT TOP (31) DATEADD(DAY, number, '20140101')
FROM [master].dbo.spt_values
WHERE [type] = N'P'
ORDER BY number
),
Tickets(LicenseNumber,[day],s) AS
(
-- match *some* licenses to days they got tickets
SELECT DISTINCT l.LicenseNumber, d.[day], s = RTRIM(l.LicenseNumber)
FROM LicenseNumbers AS l CROSS JOIN JanuaryDates AS d
WHERE CHECKSUM(NEWID()) % 100 = l.LicenseNumber % 100
AND (RTRIM(l.LicenseNumber) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
OR (RTRIM(l.LicenseNumber+1) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
)
INSERT dbo.SpeedingTickets(LicenseNumber,IncidentDate,TicketAmount)
SELECT t.LicenseNumber, t.[day], ta.Value
FROM Tickets AS t
INNER JOIN TicketAmounts AS ta
ON ta.ID = CONVERT(INT,RIGHT(t.s,1))-CONVERT(INT,LEFT(RIGHT(t.s,2),1))
ORDER BY t.[day], t.LicenseNumber; Dies mag ein wenig zu kompliziert erscheinen, aber eine der größten Herausforderungen, die ich beim Verfassen dieser Blog-Posts oft habe, ist das Erstellen einer angemessenen Menge realistischer "zufälliger" / willkürlicher Daten. Wenn Sie eine bessere Methode für die willkürliche Datenbestückung haben, verwenden Sie auf keinen Fall mein Gemurmel als Beispiel – es ist für diesen Beitrag nebensächlich.
Ansätze
Es gibt verschiedene Möglichkeiten, dieses Problem in T-SQL zu lösen. Hier sind sieben Ansätze mit den dazugehörigen Plänen. Ich habe Techniken wie Cursor (weil sie unbestreitbar langsamer sind) und datumsbasierte rekursive CTEs (weil sie von zusammenhängenden Tagen abhängen) weggelassen.
Unterabfrage #1
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND s.IncidentDate < o.IncidentDate
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate;
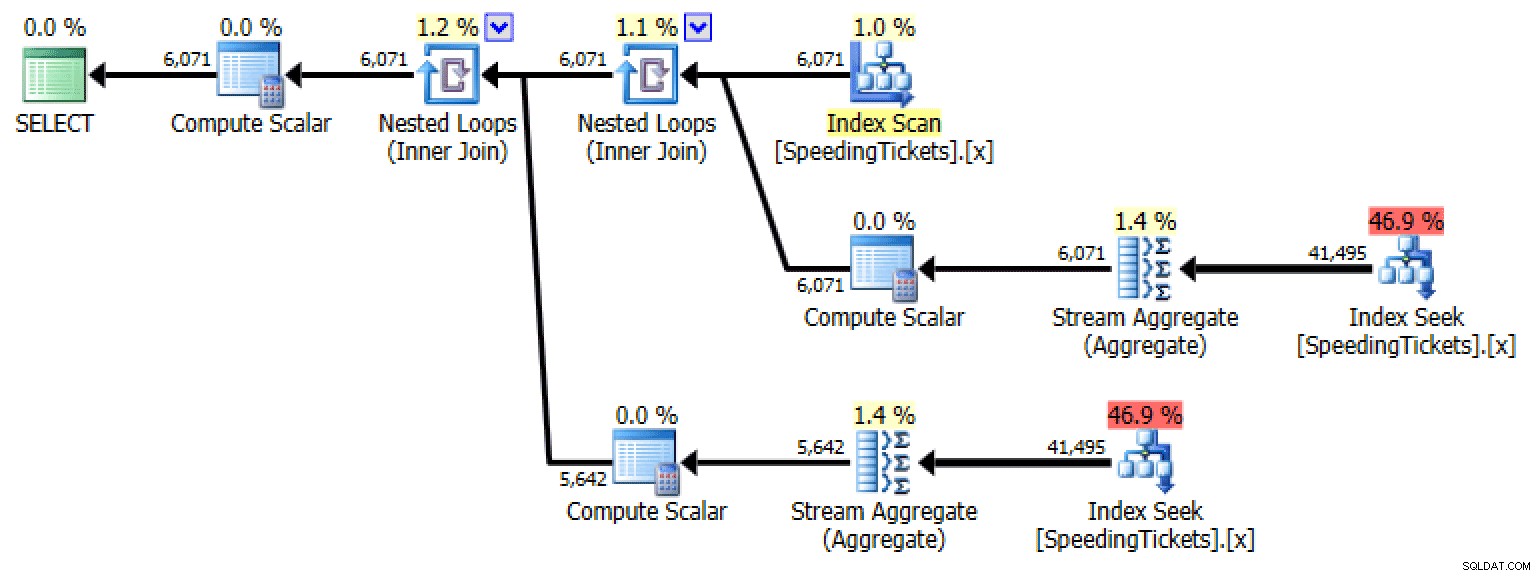
Planen Sie Unterabfrage Nr. 1
Unterabfrage #2
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate;
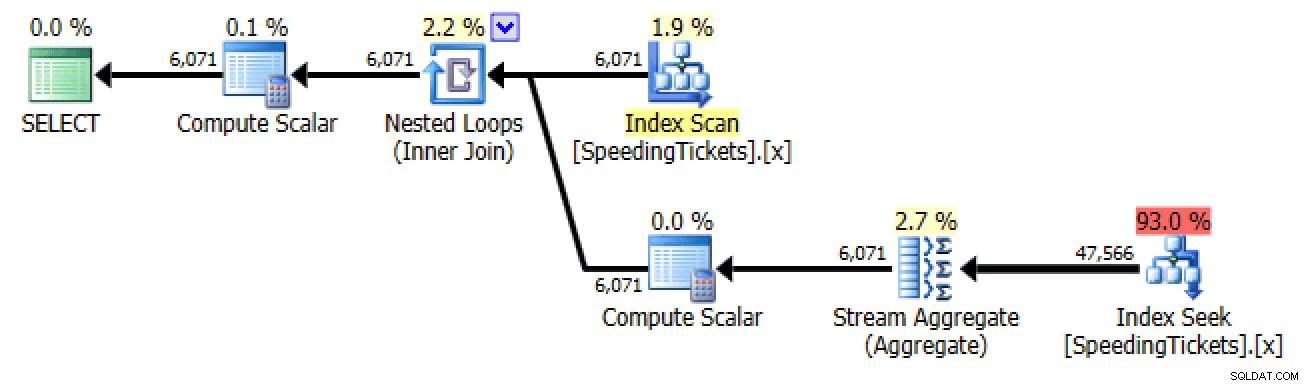
Planen Sie Unterabfrage #2
Selbst beitreten
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal = SUM(t2.TicketAmount) FROM dbo.SpeedingTickets AS t1 INNER JOIN dbo.SpeedingTickets AS t2 ON t1.LicenseNumber = t2.LicenseNumber AND t1.IncidentDate >= t2.IncidentDate GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount ORDER BY t1.LicenseNumber, t1.IncidentDate;
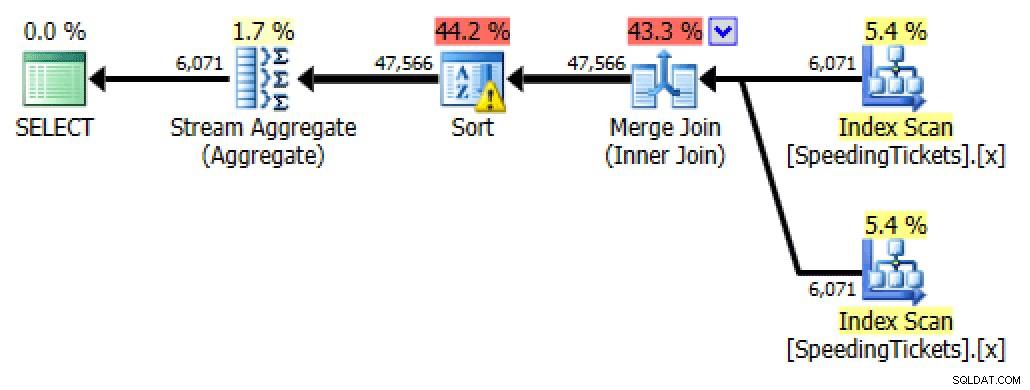
Selbstbeitritt planen
Äußere Anwendung
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
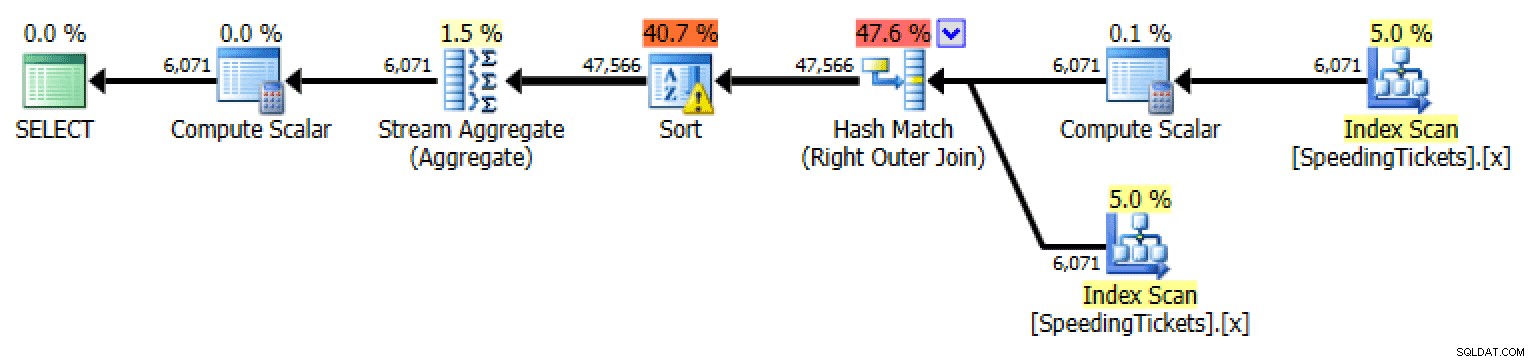
Plan für äußere Anwendung
SUM OVER() mit RANGE (nur 2012+)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate RANGE UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;

Planen Sie SUM OVER() mit RANGE
SUM OVER() mit ROWS (nur 2012+)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate ROWS UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;

Planen Sie SUM OVER() mit ROWS
Satzbasierte Iteration
Mit Anerkennung von Hugo Kornelis (@Hugo_Kornelis) für Kapitel Nr. 4 in SQL Server MVP Deep Dives Band Nr. 1 kombiniert dieser Ansatz einen satzbasierten Ansatz und einen Cursor-Ansatz.
DECLARE @x TABLE
(
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL,
PRIMARY KEY(LicenseNumber, IncidentDate)
);
INSERT @x(LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate)
FROM dbo.SpeedingTickets;
DECLARE @rn INT = 1, @rc INT = 1;
WHILE @rc > 0
BEGIN
SET @rn += 1;
UPDATE [current]
SET RunningTotal = [last].RunningTotal + [current].TicketAmount
FROM @x AS [current]
INNER JOIN @x AS [last]
ON [current].LicenseNumber = [last].LicenseNumber
AND [last].rn = @rn - 1
WHERE [current].rn = @rn;
SET @rc = @@ROWCOUNT;
END
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal
FROM @x
ORDER BY LicenseNumber, IncidentDate; Aufgrund seiner Natur erzeugt dieser Ansatz viele identische Pläne im Prozess der Aktualisierung der Tabellenvariablen, die alle den Plänen Self-Join und Outer Apply ähneln, aber in der Lage sind, eine Suche zu verwenden:
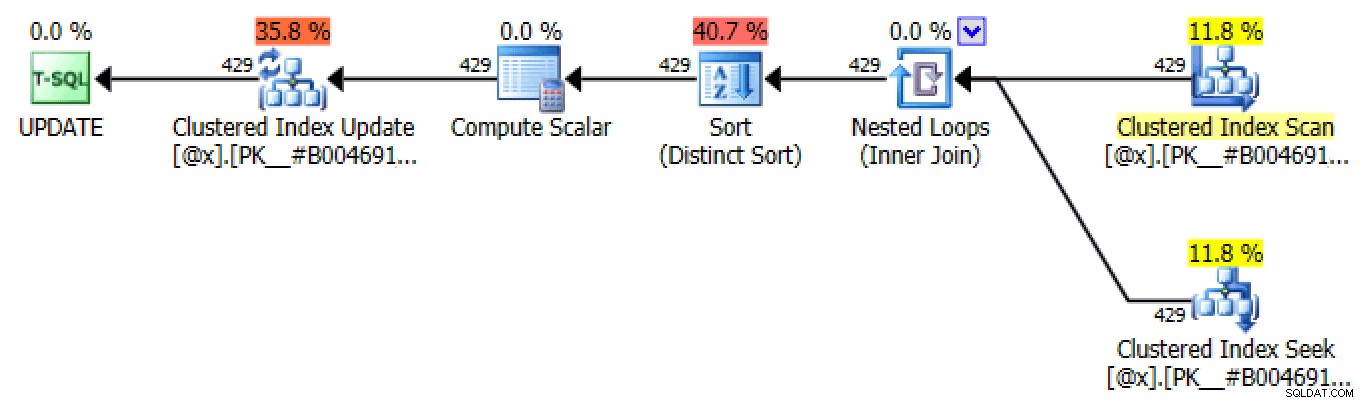
Einer von vielen UPDATE-Plänen, die durch satzbasierte Iteration erstellt wurden
Der einzige Unterschied zwischen jedem Plan in jeder Iteration ist die Zeilenanzahl. Bei jeder aufeinanderfolgenden Iteration sollte die Anzahl der betroffenen Zeilen gleich bleiben oder abnehmen, da die Anzahl der betroffenen Zeilen bei jeder Iteration die Anzahl der Fahrer mit Tickets an dieser Anzahl von Tagen (oder genauer gesagt der Anzahl von Tagen an) darstellt dieser "Rang").
Leistungsergebnisse
Hier sehen Sie, wie sich die Ansätze stapeln, wie vom SQL Sentry Plan Explorer gezeigt, mit Ausnahme des satzbasierten Iterationsansatzes, der, da er aus vielen einzelnen Anweisungen besteht, im Vergleich zu den anderen nicht gut dargestellt wird.
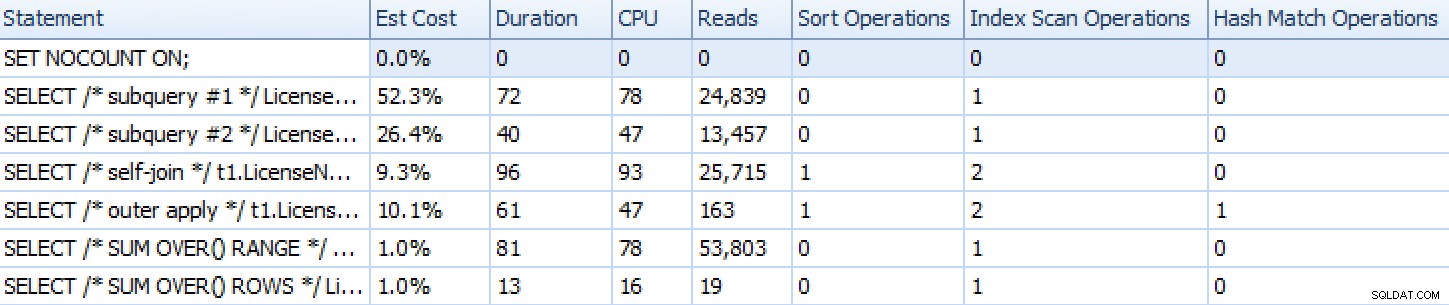
Planen Sie Explorer-Laufzeitmetriken für sechs der sieben Ansätze
Neben der Überprüfung der Pläne und dem Vergleich der Laufzeitmetriken im Plan-Explorer habe ich auch die reine Laufzeit in Management Studio gemessen. Hier sind die Ergebnisse der 10-maligen Ausführung jeder Abfrage, wobei zu beachten ist, dass dies auch die Renderzeit in SSMS umfasst:
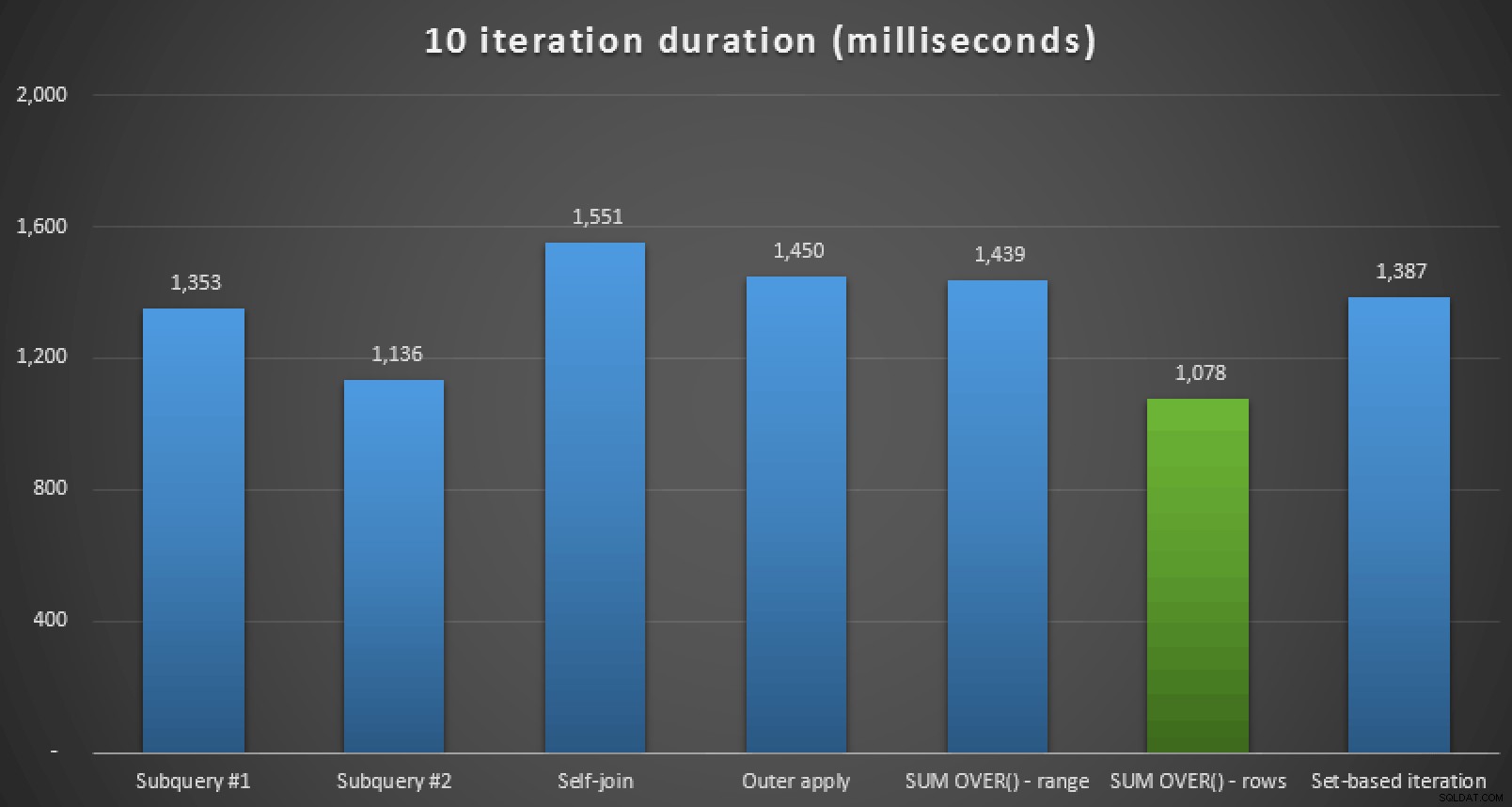
Laufzeitdauer in Millisekunden für alle sieben Ansätze (10 Iterationen )
Wenn Sie also SQL Server 2012 oder besser verwenden, scheint der beste Ansatz SUM OVER() zu sein mit ROWS UNBOUNDED PRECEDING . Wenn Sie nicht auf SQL Server 2012 unterwegs sind, schien der zweite Subquery-Ansatz trotz der hohen Anzahl von Lesevorgängen im Vergleich zu beispielsweise OUTER APPLY hinsichtlich der Laufzeit optimal zu sein Anfrage. In jedem Fall sollten Sie diese an Ihr Schema angepassten Ansätze natürlich gegen Ihr eigenes System testen. Ihre Daten, Indizes und andere Faktoren können dazu führen, dass eine andere Lösung für Ihre Umgebung am besten geeignet ist.
Andere Komplexitäten
Nun bedeutet der eindeutige Index, dass jede Kombination von LicenseNumber + IncidentDate eine einzige kumulative Summe enthält, falls ein bestimmter Fahrer an einem bestimmten Tag mehrere Tickets erhält. Diese Geschäftsregel vereinfacht unsere Logik ein wenig und vermeidet die Notwendigkeit eines Tie-Breakers, um deterministische laufende Summen zu erstellen.
Wenn Sie Fälle haben, in denen Sie möglicherweise mehrere Zeilen für eine bestimmte Kombination aus LicenseNumber + IncidentDate haben, können Sie die Bindung aufheben, indem Sie eine andere Spalte verwenden, die dazu beiträgt, die Kombination eindeutig zu machen (offensichtlich hätte die Quelltabelle keine Eindeutigkeitsbeschränkung mehr für diese beiden Spalten). . Beachten Sie, dass dies auch in Fällen möglich ist, in denen DATE Spalte ist eigentlich DATETIME – Viele Leute gehen davon aus, dass Datums-/Uhrzeitwerte eindeutig sind, aber dies ist sicherlich nicht immer garantiert, unabhängig von der Granularität.
In meinem Fall könnte ich den IDENTITY verwenden Spalte, IncidentID; Hier ist, wie ich jede Lösung anpassen würde (wobei ich anerkenne, dass es möglicherweise bessere Möglichkeiten gibt; nur Ideen verwerfen):
/* --------- subquery #1 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND (s.IncidentDate < o.IncidentDate
-- added this line:
OR (s.IncidentDate = o.IncidentDate AND s.IncidentID < o.IncidentID))
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate;
/* --------- subquery #2 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
-- added this line:
AND IncidentID <= t.IncidentID
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate;
/* --------- self-join --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
INNER JOIN dbo.SpeedingTickets AS t2
ON t1.LicenseNumber = t2.LicenseNumber
AND t1.IncidentDate >= t2.IncidentDate
-- added this line:
AND t1.IncidentID >= t2.IncidentID
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- outer apply --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
-- added this line:
AND IncidentID <= t1.IncidentID
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- SUM() OVER using RANGE --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID RANGE UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- SUM() OVER using ROWS --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID ROWS UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- set-based iteration --------- */
DECLARE @x TABLE
(
-- added this column, and made it the PK:
IncidentID INT PRIMARY KEY,
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL
);
-- added the additional column to the INSERT/SELECT:
INSERT @x(IncidentID, LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT IncidentID, LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate, IncidentID)
-- and added this tie-breaker column ------------------------------^^^^^^^^^^^^
FROM dbo.SpeedingTickets;
-- the rest of the set-based iteration solution remained unchanged
Eine weitere Komplikation, auf die Sie stoßen können, ist, wenn Sie nicht hinter der ganzen Tabelle her sind, sondern eher einer Teilmenge (sagen wir in diesem Fall der ersten Januarwoche). Sie müssen Anpassungen vornehmen, indem Sie WHERE hinzufügen Klauseln, und denken Sie auch an diese Prädikate, wenn Sie korrelierte Unterabfragen haben.