Vor ein paar Wochen war das SQLskills-Team in Tampa für unser Performance Tuning Immersion Event (IE2) und ich habe Grundlagen behandelt. Baselines ist ein Thema, das mir sehr am Herzen liegt, weil es aus vielen Gründen so wertvoll ist. Zwei dieser Gründe, die ich immer anspreche, egal ob ich unterrichte oder mit Kunden arbeite, sind die Verwendung von Baselines zur Fehlerbehebung bei der Leistung und dann auch die Trendnutzung und die Bereitstellung von Kapazitätsplanungsschätzungen. Aber sie sind auch wichtig, wenn Sie die Leistung optimieren oder testen – unabhängig davon, ob Sie Ihre vorhandenen Leistungsmetriken als Basiswerte betrachten oder nicht.
Während des Moduls überprüfte ich verschiedene Datenquellen wie Performance Monitor, die DMVs und Ablaufverfolgungs- oder XE-Daten, und es tauchte eine Frage in Bezug auf das Laden von Daten auf. Die Frage war insbesondere, ob es besser ist, Daten in eine Tabelle ohne Indizes zu laden und sie dann zu erstellen, wenn sie fertig sind, als die Indizes während des Ladens der Daten an Ort und Stelle zu lassen. Meine Antwort war:„Normalerweise ja“. Meine persönliche Erfahrung war, dass dies immer der Fall ist, aber man weiß nie, auf welchen Vorbehalt oder ein einmaliges Szenario jemand stoßen könnte, in dem die Leistungsänderung nicht den Erwartungen entspricht, und wie bei Bei allen Leistungsfragen weiß man es erst, wenn man sie testet. Bis man einen Ausgangswert für eine Methode festlegt und dann sieht, ob sich die andere Methode gegenüber diesem Ausgangswert verbessert, kann man nur raten. Ich dachte, das Testen würde Spaß machen dieses Szenario nicht nur, um zu beweisen, was ich für wahr erwarte, sondern auch, um zu zeigen, welche Messwerte ich untersuchen würde, warum und wie man sie erfasst. Wenn Sie zuvor Leistungstests durchgeführt haben, ist dies wahrscheinlich ein alter Hut. Aber für diese von Ihnen, die neu in der Praxis sind, werde ich den Prozess Schritt für Schritt durchgehen, dem ich folge, um Ihnen den Einstieg zu erleichtern. Machen Sie sich bewusst, dass es viele Möglichkeiten gibt, die Antwort auf die Frage „Welche Methode ist besser?“ abzuleiten. Ich erwarte, dass Sie diesen Prozess übernehmen, optimieren und ihn im Laufe der Zeit zu Ihrem eigenen machen.
Was versuchen Sie zu beweisen?
Der erste Schritt besteht darin, genau zu entscheiden, was Sie testen. In unserem Fall ist es einfach:Ist es schneller, Daten in eine leere Tabelle zu laden und dann die Indizes hinzuzufügen, oder ist es schneller, die Indizes während des Ladens der Daten in der Tabelle zu haben? Aber wir können hier etwas Variation hinzufügen, wenn wir wollen. Berücksichtigen Sie die Zeit, die benötigt wird, um Daten in einen Heap zu laden und dann die gruppierten und nicht gruppierten Indizes zu erstellen, im Vergleich zu der Zeit, die benötigt wird, um Daten in einen gruppierten Index zu laden und dann die nicht gruppierten Indizes zu erstellen. Gibt es einen Leistungsunterschied? Wäre der Clustering-Schlüssel ein Faktor? Ich gehe davon aus, dass die Datenlast zur Fragmentierung vorhandener Nonclustered-Indizes führen wird. Daher möchte ich vielleicht sehen, welche Auswirkungen die Neuerstellung der Indizes nach dem Laden auf die Gesamtdauer hat. Es ist wichtig, diesen Schritt so weit wie möglich einzugrenzen und sehr genau zu bestimmen, was Sie messen möchten, da dies bestimmt, welche Daten Sie erfassen. In unserem Beispiel lauten unsere vier Tests:
Test 1: Laden Sie Daten in einen Heap, erstellen Sie den Clustered-Index, erstellen Sie die Nonclustered-Indizes
Test 2: Laden Sie Daten in einen gruppierten Index, erstellen Sie die nicht gruppierten Indizes
Test 3: Erstellen Sie den gruppierten Index und die nicht gruppierten Indizes, laden Sie die Daten
Test 4: Clustered-Index und Nonclustered-Indizes erstellen, Daten laden, Nonclustered-Indizes neu erstellen
Was müssen Sie wissen?
In unserem Szenario lautet unsere primäre Frage:„Welche Methode ist am schnellsten?“ Daher möchten wir die Dauer messen und dazu müssen wir eine Startzeit und eine Endzeit erfassen. Wir könnten es dabei belassen, möchten aber vielleicht verstehen, wie die Ressourcennutzung für jede Methode aussieht, oder vielleicht möchten wir die höchsten Wartezeiten oder die Anzahl der Transaktionen oder die Anzahl der Deadlocks kennen. Welche Daten am interessantesten und relevantesten sind, hängt davon ab, welche Prozesse Sie vergleichen. Die Erfassung der Anzahl der Transaktionen ist für unsere Datenlast nicht so interessant; aber für eine Codeänderung könnte es sein. Da wir Indizes erstellen und neu erstellen, interessiert mich, wie viel IO jede Methode generiert. Während die Gesamtdauer am Ende wahrscheinlich der entscheidende Faktor ist, kann ein Blick auf IO hilfreich sein, um nicht nur zu verstehen, welche Option die meisten IO generiert, sondern auch, ob der Datenbankspeicher wie erwartet funktioniert.
Wo sind die Daten, die Sie benötigen?
Sobald Sie festgelegt haben, welche Daten Sie benötigen, entscheiden Sie, woher sie erfasst werden sollen. Wir sind an der Dauer interessiert, daher möchten wir die Zeit aufzeichnen, zu der jeder Datenladetest beginnt und wann er endet. Wir interessieren uns auch für IO, und wir können diese Daten von mehreren Orten abrufen – Performance Monitor-Zähler und die sys.dm_io_virtual_file_stats DMV kommen mir in den Sinn.
Verstehen Sie, dass wir diese Daten manuell abrufen könnten. Bevor wir einen Test durchführen, können wir gegen sys.dm_io_virtual_file_stats auswählen und die aktuellen Werte in einer Datei speichern. Wir können die Zeit notieren und dann den Test starten. Wenn es fertig ist, notieren wir die Zeit erneut, fragen sys.dm_io_virtual_file_stats erneut ab und berechnen die Unterschiede zwischen den Werten, um IO zu messen.
Diese Methodik weist zahlreiche Mängel auf, nämlich dass sie erheblichen Spielraum für Fehler lässt; Was ist, wenn Sie vergessen, die Startzeit zu notieren oder Dateistatistiken zu erfassen, bevor Sie beginnen? Eine viel bessere Lösung besteht darin, nicht nur die Ausführung des Skripts, sondern auch die Datenerfassung zu automatisieren. Beispielsweise können wir eine Tabelle erstellen, die unsere Testinformationen enthält – eine Beschreibung, was der Test ist, wann er begonnen hat und wann er abgeschlossen wurde. Wir können die Dateistatistiken in dieselbe Tabelle aufnehmen. Wenn wir andere Metriken erfassen, können wir diese der Tabelle hinzufügen. Oder es kann einfacher sein, eine separate Tabelle für jeden Datensatz zu erstellen, den wir erfassen. Wenn wir beispielsweise Dateistatistikdaten in einer anderen Tabelle speichern, müssen wir jedem Test eine eindeutige ID zuweisen, damit wir unseren Test mit den richtigen Dateistatistikdaten abgleichen können. Bei der Erfassung von Dateistatistiken müssen wir die Werte für unsere Datenbank vor und nach dem Start erfassen und die Differenz berechnen. Wir können diese Informationen dann zusammen mit der eindeutigen Test-ID in einer eigenen Tabelle speichern.
Eine Beispielübung
Für diesen Test habe ich eine leere Kopie der Tabelle „Sales.SalesOrderHeader“ mit dem Namen „Sales.Big_SalesOrderHeader“ erstellt und eine Variation eines Skripts verwendet, das ich in meinem Post zur Partitionierung verwendet habe, um Daten in Stapeln von etwa 25.000 Zeilen in die Tabelle zu laden. Das Skript zum Laden der Daten können Sie hier herunterladen. Ich habe es für jede Variation viermal ausgeführt und auch die Gesamtzahl der eingefügten Zeilen variiert. Für den ersten Satz von Tests habe ich 20 Millionen Zeilen eingefügt, und für den zweiten Satz habe ich 60 Millionen Zeilen eingefügt. Die Dauerdaten sind nicht überraschend:
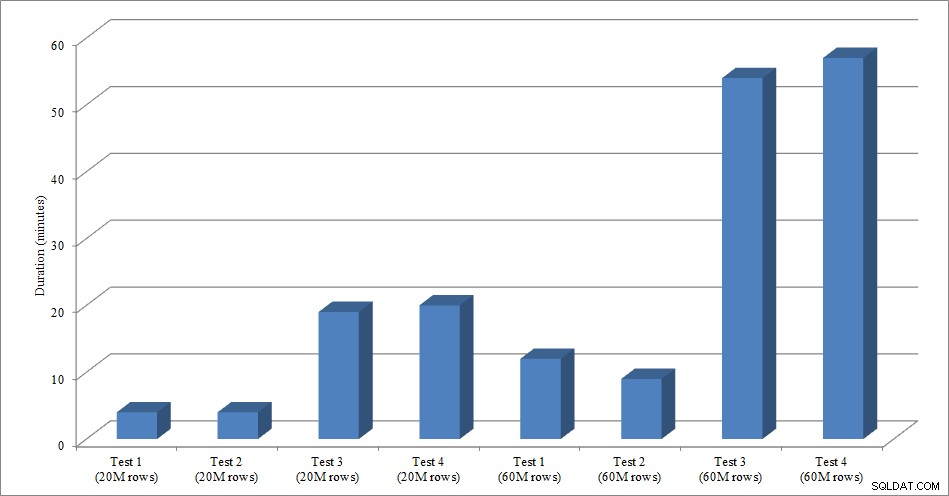
Datenladedauer
Das Laden von Daten ohne die Nonclustered-Indizes ist viel schneller als das Laden mit den bereits vorhandenen Nonclustered-Indizes. Was ich interessant fand, war, dass für das Laden von 20 Millionen Zeilen die Gesamtdauer zwischen Test 1 und Test 2 ungefähr gleich war, aber Test 2 beim Laden von 60 Millionen Zeilen schneller war. In unserem Test war unser Clustering-Schlüssel SalesOrderID, was eine Identität und daher ein guter Clustering-Schlüssel für unsere Last ist, da sie aufsteigend ist. Wenn wir stattdessen einen Clustering-Schlüssel hätten, der eine GUID wäre, könnte die Ladezeit aufgrund zufälliger Einfügungen und Seitenaufteilungen höher sein (eine weitere Variante, die wir testen könnten).
Bilden die IO-Daten den Trend der Dauerdaten nach? Ja, mit den Unterschieden, ob die Indizes bereits vorhanden sind oder nicht, noch übertriebener:
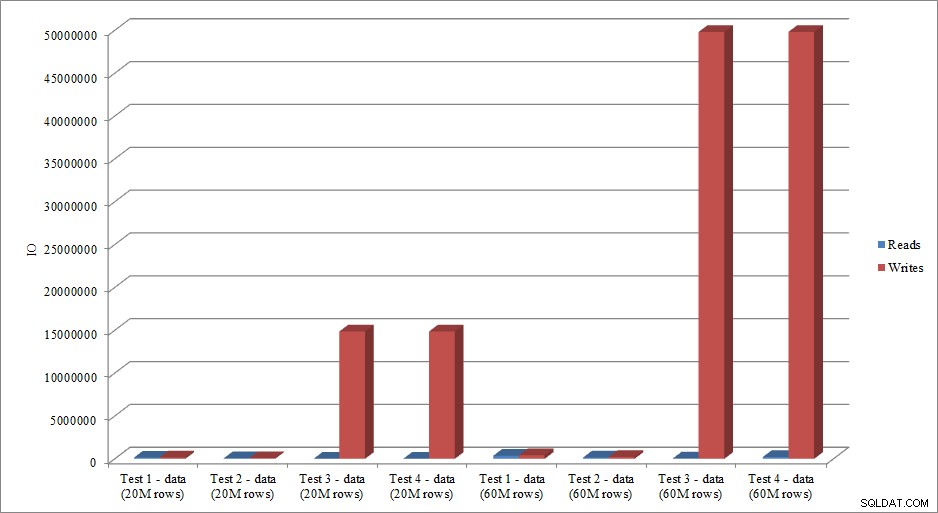
Lesen und Schreiben von Daten laden
Die Methode, die ich hier für Leistungstests oder das Messen von Leistungsänderungen basierend auf Änderungen an Code, Design usw. vorgestellt habe, ist nur eine Option zum Erfassen von Basisinformationen. In einigen Szenarien kann dies übertrieben sein. Wenn Sie eine Abfrage optimieren möchten, kann das Einrichten dieses Prozesses zum Erfassen von Daten länger dauern als das Vornehmen von Optimierungen an der Abfrage! Wenn Sie Abfrageoptimierungen durchgeführt haben, sind Sie wahrscheinlich daran gewöhnt, STATISTICS IO- und STATISTICS TIME-Daten zusammen mit dem Abfrageplan zu erfassen und dann die Ausgabe zu vergleichen, während Sie Änderungen vornehmen. Ich mache das seit Jahren, aber ich habe kürzlich einen besseren Weg entdeckt … SQL Sentry Plan Explorer PRO. Tatsächlich habe ich, nachdem ich alle oben beschriebenen Lasttests abgeschlossen hatte, meine Tests durch PE durchlaufen und erneut ausgeführt und festgestellt, dass ich die gewünschten Informationen erfassen konnte, ohne meine Datenerfassungstabellen einrichten zu müssen.
Innerhalb von Plan Explorer PRO haben Sie die Möglichkeit, den tatsächlichen Plan abzurufen – PE führt die Abfrage für die ausgewählte Instanz und Datenbank aus und gibt den Plan zurück. Und damit erhalten Sie all die anderen großartigen Daten, die PE bereitstellt (Zeitstatistiken, Lese- und Schreibvorgänge, IO nach Tabelle), sowie die Wartestatistik, was ein netter Vorteil ist. In unserem Beispiel habe ich mit dem ersten Test begonnen – Heap erstellen, Daten laden und dann Clustered-Index und Nonclustered-Indizes hinzufügen – und dann die Option Get Actual Plan ausgeführt. Als es fertig war, habe ich meinen Skripttest 2 geändert und die Option Get Actual Plan erneut ausgeführt. Ich wiederholte dies für den dritten und vierten Test, und als ich fertig war, hatte ich Folgendes:
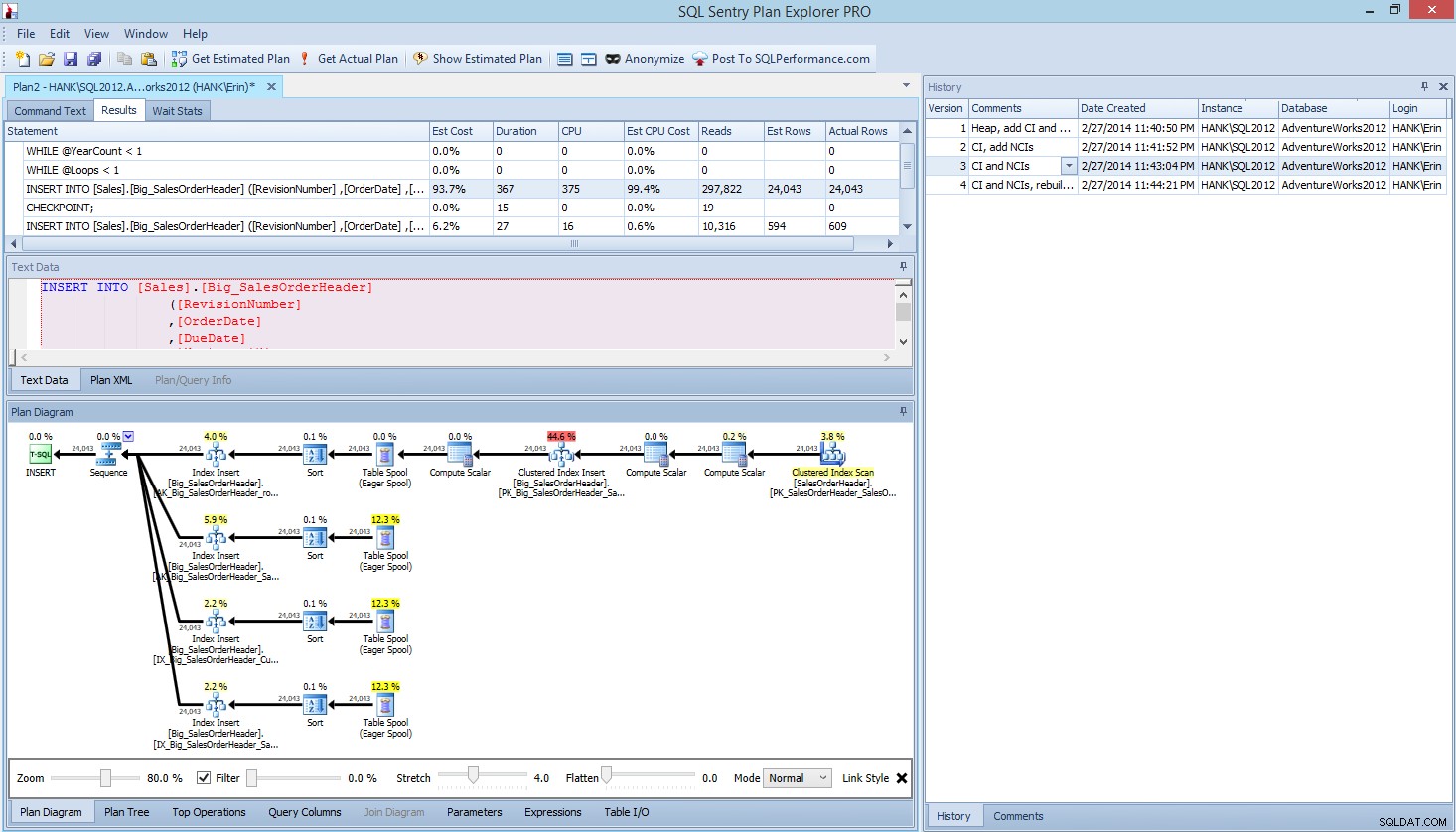
Explorer PRO-Ansicht nach Ausführung von 4 Tests planen
Beachten Sie das Verlaufsfenster auf der rechten Seite? Jedes Mal, wenn ich meinen Code geändert und den eigentlichen Plan neu erfasst habe, wurden neue Informationen gespeichert. Ich habe die Möglichkeit, diese Daten als .pesession-Datei zu speichern, um sie mit einem anderen Mitglied meines Teams zu teilen, oder später zurückzugehen und durch die verschiedenen Tests zu blättern und bei Bedarf verschiedene Aussagen innerhalb des Stapels zu untersuchen und verschiedene Metriken wie z als Dauer, CPU und IO. Im obigen Screenshot habe ich das INSERT aus Test 3 hervorgehoben, und der Abfrageplan zeigt die Aktualisierungen aller vier Nonclustered-Indizes.
Zusammenfassung
Wie bei so vielen Aufgaben in SQL Server gibt es viele Möglichkeiten, Daten zu erfassen und zu überprüfen, wenn Sie Leistungstests ausführen oder Optimierungen durchführen. Je weniger manueller Aufwand Sie betreiben müssen, desto besser, da mehr Zeit bleibt, um tatsächlich Änderungen vorzunehmen, die Auswirkungen zu verstehen und dann mit Ihrer nächsten Aufgabe fortzufahren. Unabhängig davon, ob Sie ein Skript zum Erfassen von Daten anpassen oder dies einem Dienstprogramm eines Drittanbieters überlassen, die von mir skizzierten Schritte sind immer noch gültig:
- Definieren Sie, was Sie verbessern möchten
- Umfang Ihrer Tests
- Bestimmen Sie, welche Daten zur Messung der Verbesserung verwendet werden können
- Entscheiden Sie, wie die Daten erfasst werden sollen
- Richten Sie wann immer möglich eine automatisierte Methode zum Testen und Erfassen ein
- Testen, bewerten und bei Bedarf wiederholen
Viel Spaß beim Testen!